搜索到
20
篇与
的结果
-
 AI专题二十一:AI专业术语汇总(1) 今天这篇文章,我用最人话的类比,零门槛讲透AI圈最核心的8个概念:LLM、Prompt、Context、RAG、Skills、MCP、Harness、Agent。不仅让你懂「是什么」,更让你懂「怎么用」「怎么组合」「怎么落地」,看完这篇,你对AI的理解,会超过90%的碎片化学习者。一、底层核心:所有AI应用的根,都是LLMLLM(Large Language Model,大语言模型),是整个AI世界的大脑核心。你可以把它理解成一个读了万亿页人类文本、精通语言逻辑、推理、创作的超级学霸。它天生就能听懂人话、写文案、写代码、做逻辑推导,是所有AI功能的基础底座——我们后面讲的所有概念,都是围绕这个大脑做的增强、扩展和管控。但必须先讲透它的天生短板,这也是后面所有概念存在的意义:知识有截止日期,不知道训练完成之后的新信息;容易出现「幻觉」,一本正经地编造不存在的内容;没有专属知识,不懂你公司的内部制度、你的产品详情、你的个人数据;没法直接操作外部工具,不能帮你查数据库、拉取后台数据、操作电脑文件;短期记忆有限,聊多了就会忘记前面的内容,答非所问。新手避坑:别把LLM等同于AI的全部。它只是核心零件,不是完整的解决方案。就像汽车发动机再强,没有方向盘、轮胎、刹车,也没法上路。二、和AI对话的基本功:Prompt & Context,90%的人都用错了这两个是和LLM大脑交互的基础,也是AI学习者的第一门必修课,更是最容易被轻视、用错的环节。Prompt(提示词):和AI对话的「精准指令语言」你可以把它理解成:给超级学霸的提问方式。同样一个需求,你问「帮我写个文案」,和「帮我写一篇面向30岁职场女性的抗老护肤品种草文案,小红书风格,800字以内,要有痛点、成分解析、真实使用感受,结尾加互动话题」,得到的结果天差地别。Prompt的核心,不是网上传的「玄学咒语」,也不是越长越好,而是把你的需求,拆成LLM能精准理解、严格执行的指令,核心四要素:明确需求、限定边界、给出范式、对齐预期。新手避坑:别沉迷于收藏各种Prompt模板,模板只能解决单一问题。真正的核心能力,是学会拆解需求,用精准的语言对齐AI的输出,这是所有AI操作的基本功。Context(上下文):LLM的「短期记忆」你可以把它理解成:学霸和你对话时,能同时记住的内容上限。你跟AI说「我是做ToB软件销售的」,后面问「怎么给客户做产品演示」,AI会结合你销售的身份给出答案,这就是Context在起作用。但如果你们连续聊了几百句,超出了它的记忆上限,它就会忘记你最开始说的身份,给出泛泛的回答。Context的核心价值,是决定了AI能不能连贯对话、基于长文本完成任务——比如你给它100页的合同让它审核,给它几十万字的小说让它写续写,前提都是它的Context窗口能装下这些内容。新手避坑:不是Context窗口越大越好。窗口太大,会导致AI推理变慢、注意力分散,甚至抓不住核心信息。真正的高阶能力,是学会管理Context,只给AI传递最关键的信息,过滤无效内容,这也是解决AI答非所问的核心方法。三、给AI装外挂:RAG,解决LLM的天生短板RAG(Retrieval Augmented Generation,检索增强生成),是给LLM大脑装的专属知识库+外挂硬盘,也是新手最容易落地的进阶技能。前面我们说过,LLM的核心痛点是知识过时、容易幻觉、没有专属数据。而RAG,就是专门解决这个问题的。你可以这么理解:学霸虽然读书多,但不知道你公司的内部制度、你家店铺的产品详情、你最新的项目文档、你个人的笔记资料。这时候你给它装一个RAG,就相当于给它配了一个专属私人图书馆。你提问的时候,它会先去这个图书馆里,检索和你问题相关的精准资料,再结合自己的语言能力和推理能力回答问题,从根源上避免幻觉,同时能用上你的专属数据。它的核心逻辑非常简单,只有四步:把你的文档、资料、笔记,拆成AI能处理的小片段;把这些片段转换成向量,存储到向量数据库里;你提问时,AI先去数据库里,检索和问题最相关的内容;把检索到的内容和你的问题一起,交给LLM生成精准答案。新手避坑:RAG不是简单的「把文档复制粘贴给AI」。直接丢长文档给AI,会超出Context上限,也会让AI抓不住重点。RAG的核心是「精准检索」,只给AI传递和问题相关的内容,这也是它和直接喂文档的本质区别。不管是做个人专属AI笔记助手、企业内部知识库,还是行业客服AI,RAG都是必备的核心技术,也是新手从「用AI」到「做AI工具」的第一步。四、让AI变专业:Skills,把重复工作变成一键搞定的技能包Skills(技能),是给LLM提前练好的专项本领包,是把AI从「聊天工具」变成「效率工具」的关键。你可以这么理解:学霸虽然全能,但你每次都让它从零开始写SQL、算Excel函数、审核合同、写固定格式的周报,不仅效率低,还容易每次输出的标准不统一。而Skills,就是你提前给学霸封装好的、可复用的、带完整流程的专项技能。比如「SQL生成与查询技能」,你把「用户需求→生成SQL→语法校验→执行查询→结果整理」整个流程,提前封装成一个固定的技能包,以后用户只要说一句话,AI就能自动走完整个流程,不用你每次都重新教。Skills和Prompt的核心区别:• Prompt是单次指令,解决一个具体问题;• Skills是封装好的、带逻辑、带流程、可复用的专项能力,解决一类重复问题。比如你是电商运营,你可以把「竞品标题分析」「直播话术生成」「订单数据对账」这些每天都要做的重复工作,分别封装成不同的Skills,以后只要一键调用,AI就能按固定标准、固定流程完成,效率直接拉满。五、给AI接手脚:MCP,让AI操控整个数字世界的通用桥梁MCP(Model Context Protocol,模型上下文协议),是2024年爆火的AI基础设施,也是让AI从「只能聊天」变成「能做事」的核心桥梁。先讲一个痛点:LLM本身是个纯语言模型,它没法直接操作你的电脑文件、查你的本地数据库、调用企业微信API、拉取直播后台数据、控制你的办公软件。之前要实现这些功能,你必须给每个工具、每个软件,单独写定制化的对接代码,10个工具就要写10套对接逻辑,非常麻烦,新手根本搞不定。而MCP,就是一套通用的翻译协议。你可以把它理解成:给所有软件、工具、系统、API,都装了一个统一的翻译器。只要支持MCP协议,LLM不用单独写代码对接,就能直接调用这些工具,就像人长了手脚,能直接操控整个数字世界。举个例子:之前你要让AI帮你查数据库里的销售数据,还要发到企业微信群里,你需要分别写数据库对接代码、企业微信API对接代码,还要写逻辑让AI调用。现在只要数据库和企业微信都支持MCP,AI一句话就能自动完成,不用写一行代码。新手避坑:不用深究MCP的底层协议细节,你只要知道,它是一套通用的工具对接标准,能让你零代码给AI加上各种工具能力,是AI Agent落地的核心基础设施。现在主流的AI框架都已经支持MCP,新手直接用就好。六、给AI装刹车:Harness,让AI敢用在生产环境的安全中枢Harness(大模型管控框架),是给AI装的安全刹车+管理中枢,是AI能从「玩具」变成「企业级生产工具」的核心前提。你可以这么理解:你让一个学霸帮你管公司的业务、处理客户敏感数据、操作财务系统、执行数据库指令,你肯定要给它定死规矩:什么能做、什么绝对不能做、数据不能泄露、操作不能越权、出了问题要能追溯、有风险的操作要提前拦截。Harness,就是专门干这个的。它是一套完整的管控框架,核心负责这几件事:权限管控:谁能调用AI、能调用什么功能、能访问什么数据,都由它说了算;安全审计:所有AI的操作、对话、调用记录,全程留痕,可追溯、可审计;合规校验:自动拦截违规提问、敏感内容输出,符合数据安全、行业合规要求;风险兜底:对高风险操作(比如删除数据库数据、批量发送消息)进行二次校验,不符合规则直接拦截;流量管控:控制AI的调用频率、成本上限,避免超量调用产生高额费用。新手避坑:很多人做AI应用,只关注功能好不好用,完全忽略了管控和安全。尤其是企业级应用,没有Harness的AI,就像一辆没有刹车的汽车,跑得越快,风险越大。哪怕是个人用的AI工具,也要有基础的管控逻辑,避免误操作导致数据丢失、泄露。七、最终形态:Agent,把所有零件拼成一个真正的智能机器人Agent(智能体),不是一个单一的技术,而是把上面所有概念,整合起来的完整AI机器人,也是当前AI应用的最终形态。我们来做一个完整的类比,你瞬间就能懂:• LLM是大脑,负责思考、推理、决策;• Prompt是沟通语言,负责精准传递指令;• Context是短期记忆,负责记住当前的任务和对话;• RAG是长期记忆/专属知识库,负责存储专属数据和资料;• Skills是专项本领,负责高效完成固定类型的任务;• MCP是手脚,负责调用外部工具、操作系统、软件;• Harness是安全中枢,负责全程管控、规避风险。把这些所有的零件,完整地组装起来,就是一个Agent。它能听懂你的最终目标,自主拆解任务,自主规划执行步骤,自己调用知识库找资料,自己用技能完成子任务,自己调用工具操作外部系统,全程自己纠错、自己优化,直到完成你的目标。举个最直观的例子,你跟电商运营Agent说:「帮我整理一下上周的直播带货数据,生成复盘报告,同步给运营团队」,它会自动完成这一整套流程:理解你的目标,拆解成「拉取数据→数据分析→生成报告→同步团队」4个子任务;通过MCP协议,调用直播后台的API,拉取上周的全量直播数据;调用「直播数据分析」Skill,对数据进行清洗、计算、分析,找出亮点和问题;从RAG知识库中,调取公司的复盘报告模板和过往优秀案例;基于Context里的你的需求,生成符合公司标准的复盘报告;再通过MCP调用企业微信API,把报告发到运营团队群里;全程由Harness管控,校验数据权限、操作合规性,避免敏感数据泄露,确保不会出现误操作。整个过程,完全不用你插手,这就是Agent的真正魅力——它不是一个只会聊天的机器人,而是一个能帮你自主完成完整任务的「数字员工」。八、新手必看:从入门到落地的正确路径,别再瞎学了看到这里,你已经搞懂了8个核心概念的逻辑和关系,最后给所有AI学习者,一个绝对不会踩坑的入门路径,小步快跑,快速落地:第一步:打牢基本功,别上来就搞Agent先把LLM的基础逻辑搞懂,花1-2周时间,练熟Prompt编写和Context管理。这是所有AI操作的基本功,基本功不牢,后面全是白搭。第二步:小步快跑,从RAG入手快速落地先做一个自己的专属知识库AI,比如个人笔记助手、行业资料知识库、电子书问答助手。这是最容易落地、最容易出成果的进阶项目,能快速建立你的信心,也能真正解决你自己的痛点。第三步:逐步进阶,封装自己的Skills把你日常工作中,重复度最高的工作,比如写周报、查数据、审核文档、写固定格式的文案,封装成可复用的AI Skills,实现工作自动化,真正用AI提升自己的效率。第四步:整合落地,做一个属于自己的Agent学习MCP和基础的管控逻辑,把前面的RAG、Skills、工具调用整合起来,做一个属于自己的Agent,比如个人办公助理、私域运营助手、客服机器人,真正从「用AI」,变成「造AI工具」。
AI专题二十一:AI专业术语汇总(1) 今天这篇文章,我用最人话的类比,零门槛讲透AI圈最核心的8个概念:LLM、Prompt、Context、RAG、Skills、MCP、Harness、Agent。不仅让你懂「是什么」,更让你懂「怎么用」「怎么组合」「怎么落地」,看完这篇,你对AI的理解,会超过90%的碎片化学习者。一、底层核心:所有AI应用的根,都是LLMLLM(Large Language Model,大语言模型),是整个AI世界的大脑核心。你可以把它理解成一个读了万亿页人类文本、精通语言逻辑、推理、创作的超级学霸。它天生就能听懂人话、写文案、写代码、做逻辑推导,是所有AI功能的基础底座——我们后面讲的所有概念,都是围绕这个大脑做的增强、扩展和管控。但必须先讲透它的天生短板,这也是后面所有概念存在的意义:知识有截止日期,不知道训练完成之后的新信息;容易出现「幻觉」,一本正经地编造不存在的内容;没有专属知识,不懂你公司的内部制度、你的产品详情、你的个人数据;没法直接操作外部工具,不能帮你查数据库、拉取后台数据、操作电脑文件;短期记忆有限,聊多了就会忘记前面的内容,答非所问。新手避坑:别把LLM等同于AI的全部。它只是核心零件,不是完整的解决方案。就像汽车发动机再强,没有方向盘、轮胎、刹车,也没法上路。二、和AI对话的基本功:Prompt & Context,90%的人都用错了这两个是和LLM大脑交互的基础,也是AI学习者的第一门必修课,更是最容易被轻视、用错的环节。Prompt(提示词):和AI对话的「精准指令语言」你可以把它理解成:给超级学霸的提问方式。同样一个需求,你问「帮我写个文案」,和「帮我写一篇面向30岁职场女性的抗老护肤品种草文案,小红书风格,800字以内,要有痛点、成分解析、真实使用感受,结尾加互动话题」,得到的结果天差地别。Prompt的核心,不是网上传的「玄学咒语」,也不是越长越好,而是把你的需求,拆成LLM能精准理解、严格执行的指令,核心四要素:明确需求、限定边界、给出范式、对齐预期。新手避坑:别沉迷于收藏各种Prompt模板,模板只能解决单一问题。真正的核心能力,是学会拆解需求,用精准的语言对齐AI的输出,这是所有AI操作的基本功。Context(上下文):LLM的「短期记忆」你可以把它理解成:学霸和你对话时,能同时记住的内容上限。你跟AI说「我是做ToB软件销售的」,后面问「怎么给客户做产品演示」,AI会结合你销售的身份给出答案,这就是Context在起作用。但如果你们连续聊了几百句,超出了它的记忆上限,它就会忘记你最开始说的身份,给出泛泛的回答。Context的核心价值,是决定了AI能不能连贯对话、基于长文本完成任务——比如你给它100页的合同让它审核,给它几十万字的小说让它写续写,前提都是它的Context窗口能装下这些内容。新手避坑:不是Context窗口越大越好。窗口太大,会导致AI推理变慢、注意力分散,甚至抓不住核心信息。真正的高阶能力,是学会管理Context,只给AI传递最关键的信息,过滤无效内容,这也是解决AI答非所问的核心方法。三、给AI装外挂:RAG,解决LLM的天生短板RAG(Retrieval Augmented Generation,检索增强生成),是给LLM大脑装的专属知识库+外挂硬盘,也是新手最容易落地的进阶技能。前面我们说过,LLM的核心痛点是知识过时、容易幻觉、没有专属数据。而RAG,就是专门解决这个问题的。你可以这么理解:学霸虽然读书多,但不知道你公司的内部制度、你家店铺的产品详情、你最新的项目文档、你个人的笔记资料。这时候你给它装一个RAG,就相当于给它配了一个专属私人图书馆。你提问的时候,它会先去这个图书馆里,检索和你问题相关的精准资料,再结合自己的语言能力和推理能力回答问题,从根源上避免幻觉,同时能用上你的专属数据。它的核心逻辑非常简单,只有四步:把你的文档、资料、笔记,拆成AI能处理的小片段;把这些片段转换成向量,存储到向量数据库里;你提问时,AI先去数据库里,检索和问题最相关的内容;把检索到的内容和你的问题一起,交给LLM生成精准答案。新手避坑:RAG不是简单的「把文档复制粘贴给AI」。直接丢长文档给AI,会超出Context上限,也会让AI抓不住重点。RAG的核心是「精准检索」,只给AI传递和问题相关的内容,这也是它和直接喂文档的本质区别。不管是做个人专属AI笔记助手、企业内部知识库,还是行业客服AI,RAG都是必备的核心技术,也是新手从「用AI」到「做AI工具」的第一步。四、让AI变专业:Skills,把重复工作变成一键搞定的技能包Skills(技能),是给LLM提前练好的专项本领包,是把AI从「聊天工具」变成「效率工具」的关键。你可以这么理解:学霸虽然全能,但你每次都让它从零开始写SQL、算Excel函数、审核合同、写固定格式的周报,不仅效率低,还容易每次输出的标准不统一。而Skills,就是你提前给学霸封装好的、可复用的、带完整流程的专项技能。比如「SQL生成与查询技能」,你把「用户需求→生成SQL→语法校验→执行查询→结果整理」整个流程,提前封装成一个固定的技能包,以后用户只要说一句话,AI就能自动走完整个流程,不用你每次都重新教。Skills和Prompt的核心区别:• Prompt是单次指令,解决一个具体问题;• Skills是封装好的、带逻辑、带流程、可复用的专项能力,解决一类重复问题。比如你是电商运营,你可以把「竞品标题分析」「直播话术生成」「订单数据对账」这些每天都要做的重复工作,分别封装成不同的Skills,以后只要一键调用,AI就能按固定标准、固定流程完成,效率直接拉满。五、给AI接手脚:MCP,让AI操控整个数字世界的通用桥梁MCP(Model Context Protocol,模型上下文协议),是2024年爆火的AI基础设施,也是让AI从「只能聊天」变成「能做事」的核心桥梁。先讲一个痛点:LLM本身是个纯语言模型,它没法直接操作你的电脑文件、查你的本地数据库、调用企业微信API、拉取直播后台数据、控制你的办公软件。之前要实现这些功能,你必须给每个工具、每个软件,单独写定制化的对接代码,10个工具就要写10套对接逻辑,非常麻烦,新手根本搞不定。而MCP,就是一套通用的翻译协议。你可以把它理解成:给所有软件、工具、系统、API,都装了一个统一的翻译器。只要支持MCP协议,LLM不用单独写代码对接,就能直接调用这些工具,就像人长了手脚,能直接操控整个数字世界。举个例子:之前你要让AI帮你查数据库里的销售数据,还要发到企业微信群里,你需要分别写数据库对接代码、企业微信API对接代码,还要写逻辑让AI调用。现在只要数据库和企业微信都支持MCP,AI一句话就能自动完成,不用写一行代码。新手避坑:不用深究MCP的底层协议细节,你只要知道,它是一套通用的工具对接标准,能让你零代码给AI加上各种工具能力,是AI Agent落地的核心基础设施。现在主流的AI框架都已经支持MCP,新手直接用就好。六、给AI装刹车:Harness,让AI敢用在生产环境的安全中枢Harness(大模型管控框架),是给AI装的安全刹车+管理中枢,是AI能从「玩具」变成「企业级生产工具」的核心前提。你可以这么理解:你让一个学霸帮你管公司的业务、处理客户敏感数据、操作财务系统、执行数据库指令,你肯定要给它定死规矩:什么能做、什么绝对不能做、数据不能泄露、操作不能越权、出了问题要能追溯、有风险的操作要提前拦截。Harness,就是专门干这个的。它是一套完整的管控框架,核心负责这几件事:权限管控:谁能调用AI、能调用什么功能、能访问什么数据,都由它说了算;安全审计:所有AI的操作、对话、调用记录,全程留痕,可追溯、可审计;合规校验:自动拦截违规提问、敏感内容输出,符合数据安全、行业合规要求;风险兜底:对高风险操作(比如删除数据库数据、批量发送消息)进行二次校验,不符合规则直接拦截;流量管控:控制AI的调用频率、成本上限,避免超量调用产生高额费用。新手避坑:很多人做AI应用,只关注功能好不好用,完全忽略了管控和安全。尤其是企业级应用,没有Harness的AI,就像一辆没有刹车的汽车,跑得越快,风险越大。哪怕是个人用的AI工具,也要有基础的管控逻辑,避免误操作导致数据丢失、泄露。七、最终形态:Agent,把所有零件拼成一个真正的智能机器人Agent(智能体),不是一个单一的技术,而是把上面所有概念,整合起来的完整AI机器人,也是当前AI应用的最终形态。我们来做一个完整的类比,你瞬间就能懂:• LLM是大脑,负责思考、推理、决策;• Prompt是沟通语言,负责精准传递指令;• Context是短期记忆,负责记住当前的任务和对话;• RAG是长期记忆/专属知识库,负责存储专属数据和资料;• Skills是专项本领,负责高效完成固定类型的任务;• MCP是手脚,负责调用外部工具、操作系统、软件;• Harness是安全中枢,负责全程管控、规避风险。把这些所有的零件,完整地组装起来,就是一个Agent。它能听懂你的最终目标,自主拆解任务,自主规划执行步骤,自己调用知识库找资料,自己用技能完成子任务,自己调用工具操作外部系统,全程自己纠错、自己优化,直到完成你的目标。举个最直观的例子,你跟电商运营Agent说:「帮我整理一下上周的直播带货数据,生成复盘报告,同步给运营团队」,它会自动完成这一整套流程:理解你的目标,拆解成「拉取数据→数据分析→生成报告→同步团队」4个子任务;通过MCP协议,调用直播后台的API,拉取上周的全量直播数据;调用「直播数据分析」Skill,对数据进行清洗、计算、分析,找出亮点和问题;从RAG知识库中,调取公司的复盘报告模板和过往优秀案例;基于Context里的你的需求,生成符合公司标准的复盘报告;再通过MCP调用企业微信API,把报告发到运营团队群里;全程由Harness管控,校验数据权限、操作合规性,避免敏感数据泄露,确保不会出现误操作。整个过程,完全不用你插手,这就是Agent的真正魅力——它不是一个只会聊天的机器人,而是一个能帮你自主完成完整任务的「数字员工」。八、新手必看:从入门到落地的正确路径,别再瞎学了看到这里,你已经搞懂了8个核心概念的逻辑和关系,最后给所有AI学习者,一个绝对不会踩坑的入门路径,小步快跑,快速落地:第一步:打牢基本功,别上来就搞Agent先把LLM的基础逻辑搞懂,花1-2周时间,练熟Prompt编写和Context管理。这是所有AI操作的基本功,基本功不牢,后面全是白搭。第二步:小步快跑,从RAG入手快速落地先做一个自己的专属知识库AI,比如个人笔记助手、行业资料知识库、电子书问答助手。这是最容易落地、最容易出成果的进阶项目,能快速建立你的信心,也能真正解决你自己的痛点。第三步:逐步进阶,封装自己的Skills把你日常工作中,重复度最高的工作,比如写周报、查数据、审核文档、写固定格式的文案,封装成可复用的AI Skills,实现工作自动化,真正用AI提升自己的效率。第四步:整合落地,做一个属于自己的Agent学习MCP和基础的管控逻辑,把前面的RAG、Skills、工具调用整合起来,做一个属于自己的Agent,比如个人办公助理、私域运营助手、客服机器人,真正从「用AI」,变成「造AI工具」。 -
AI专题二十:大模型本地部署工具 1. ollamaOllama 是一款开源的大模型本地部署工具,GitHub Star 数超过 80K。它提供了简单的命令行界面来下载、运行和管理大模型,同时支持通过 API 调用模型。Ollama 的核心特点:简单易用:一行命令即可运行模型模型库丰富:支持 Llama 2、Mistral、DeepSeek、Gemma 等跨平台:支持 macOS、Windows、LinuxAPI 支持:提供 RESTful API 集成GPU 加速:自动利用 GPU 加速推理轻量高效:资源占用优化Ollama 模型库涵盖多种类型的模型:硬件架构amd64:适用于 Intel/AMD x86_64 架构的 CPU(普通台式机、服务器)。arm64:适用于 ARM 架构的 CPU(如树莓派、苹果 M 系列芯片、高通骁龙)。显卡加速支持无后缀(如 ollama-linux-amd64.tgz):仅支持 CPU 推理,无 GPU 加速。-rocm后缀(如 ollama-linux-amd64-rocm.tgz):支持 AMD 显卡加速(需兼容 ROCm 驱动)。-jetpack后缀(如 ollama-linux-arm64-jetpack6.tgz):专为 NVIDIA Jetson 嵌入式设备优化(如 Jetson Nano/Orin)。操作系统.tgz:Linux/macOS 系统压缩包(需手动解压安装)。.zip:Windows 系统压缩包(需解压后运行)2. LM studioLM Studio 是一款支持在本地运行 AI 大模型的工具,支持 Mac、Linux 和 Windows 全平台。和 Ollama 不同,LM Studio 自带一个漂亮的图形界面,入门门槛极低——下载、搜索模型、点击运行,三步搞定。目前支持的主流模型相当多:gpt-oss、Qwen3、Gemma 3、DeepSeek 等等,基本上 Hugging Face 上热门的 GGUF 和 MLX 模型都能跑。1). 本地模型管理一键下载:内置 Hugging Face 模型库浏览器,可直接搜索并下载数千种开源模型(如 Llama、Mistral、Qwen、DeepSeek 等)多格式支持:兼容 GGUF、Safetensors 等主流格式版本管理:轻松切换不同模型版本和量化精度(Q4、Q5、Q8 等)2). 聊天与推理界面可视化聊天:提供类似 ChatGPT 的对话界面,支持多轮对话参数调节:实时调整 Temperature、Top-p、上下文长度等推理参数系统提示词:可自定义 System 来设定 AI 角色和行为3). 开发者工具本地 API 服务器:提供 OpenAI 兼容的 REST API(http://localhost:1234/v1),方便集成到第三方应用模型信息查看:详细展示模型架构、词汇表大小、上下文窗口等元数据4). 硬件优化自动硬件检测:智能识别 NVIDIA/AMD/Intel 显卡,自动启用 GPU 加速CPU 回退:无独显时自动使用 CPU 推理,支持 AVX2 等指令集优化LM studio有哪些技术优势?LM Studio 底层基于 llama.cpp 高性能运行时,并针对 NVIDIA RTX GPU 做了深度优化。通过 CUDA 12.8 集成,支持 CUDA Graph 和 Flash Attention,可在 RTX GPU 上实现最高 35% 的吞吐量提升。软件自动检测并启用 GPU 加速(CUDA/Metal),用户也可手动调整 GPU 卸载比例和 CPU 线程数以平衡性能。3.AnythingLLMAnythingLLM 是开源免费且支持多模态交互的全栈 AI 客户端。AnythingLLM支持文本、图像和音频等多种输入方式,将任何文档或内容转化为上下文,供各种语言模型(LLM)在对话中使用。AnythingLLM支持本地运行和远程部署,提供多用户管理、工作区隔离、丰富的文档格式支持以及强大的 API 集成。所有数据默认存储在本地,确保隐私安全。AnythingLLM支持多种流行的 LLM 和向量数据库,适合个人用户、开发者和企业使用。AnythingLLMAnythingLLM的主要功能多模态交互:支持文本、图像和音频等多种输入方式,提供更丰富的交互体验。文档处理与上下文管理:将文档划分为独立的“工作区”,支持多种格式(如PDF、TXT、DOCX等),保持上下文隔离,确保对话的清晰性。多用户支持与权限管理:Docker版本支持多用户实例,管理员能控制用户权限,适合团队协作。AI代理与工具集成:支持在工作区内运行AI代理,执行网页浏览、代码运行等任务,扩展应用的功能。本地部署与隐私保护:默认情况下,所有数据(包括模型、文档和聊天记录)存储在本地,确保隐私和数据安全。强大的API支持:提供完整的开发者API,方便用户进行自定义开发和集成。云部署就绪:支持多种云平台(如AWS、GCP等),方便用户根据需求进行远程部署。AnythingLLM的项目地址项目官网:https://anythingllm.com/GitHub仓库:https://github.com/Mintplex-Labs/anything-llmAI工具集获取AnythingLLM安装包,扫码关注回复:AnythingLLMAnythingLLM的技术原理前端:用ViteJS和React构建,提供简洁易用的用户界面,支持拖拽上传文档等功能。后端:基于NodeJS和Express,负责处理用户交互、文档解析、向量数据库管理及与LLM的通信。文档处理:基于NodeJS服务器解析和处理上传的文档,将其转化为向量嵌入,存储在向量数据库中。向量数据库:用LanceDB等向量数据库,将文档内容转化为向量嵌入,便于在对话中快速检索相关上下文。LLM集成:支持多种开源和商业LLM(如OpenAI、Hugging Face等),用户根据需求选择合适的模型。AI代理:在工作区内运行AI代理,代理能执行各种任务(如网页浏览、代码执行等),扩展应用的功能。AnythingLLM支持的模型和数据库大型语言模型(LLMs):支持多种开源和闭源模型,如 OpenAI、Google Gemini Pro、Hugging Face 等。嵌入模型:支持 AnythingLLM 原生嵌入器、OpenAI 等。语音转文字和文字转语音:支持多种语音模型,包括 OpenAI 和 ElevenLabs。向量数据库:支持 LanceDB、Pinecone、Chroma 等。AnythingLLM的使用和部署桌面版:系统要求:操作系统:支持 Windows、MacOS 和 Linux。硬件要求:建议至少 8GB 内存,推荐 16GB 或更高。下载和安装:访问 AnythingLLM 官方网站。根据操作系统选择对应的安装包。安装程序:Windows:双击安装程序并按照提示完成安装。MacOS:双击 DMG 文件,将应用程序拖入“应用程序”文件夹。Linux:基于包管理器安装 DEB 或 RPM 文件。启动应用:安装完成后,打开 AnythingLLM 应用。初始化设置:选择模型:首次启动时,选择一个语言模型(LLM)。配置向量数据库:选择默认的向量数据库(如 LanceDB)或配置其他支持的数据库。创建工作区:点击“新建工作区”,为项目或文档创建一个独立的工作区。上传文档(如 PDF、TXT、DOCX 等),应用自动解析并生成向量嵌入,存储在向量数据库中。开始对话:在工作区内输入问题或指令,应用根据上传的文档内容生成智能回答。支持多模态交互,上传图片或音频文件,应用根据内容进行处理。Docker 版:系统要求:操作系统:支持 Linux、Windows(WSL2)和 MacOS。硬件要求:建议至少 8GB 内存,推荐 16GB 或更高。Docker 环境:需要安装 Docker 和 Docker Compose。部署步骤:访问 GitHub 仓库:前往 AnythingLLM GitHub 仓库。4 DifyDify 是一个 开源 LLM 应用开发平台(Low-code/No-code),目标是让开发者和团队更快地构建和运营基于大语言模型(LLM)的应用。它的名字来自 “Do It For You”。特点:🛠️ 低代码/可视化:支持在 Web 界面拖拽配置工作流。🧩 即插即用:支持各种大模型(OpenAI、Claude、DeepSeek、Llama、Ollama 等)。🖥️ 开发者友好:支持 Python/JS SDK,API 接口调用。📊 监控 & 调优:提供日志、评测、向量库管理、数据观测等功能。Dify 可以做什么?AI 助手:客服机器人、个人助理。知识库问答:上传 PDF、文档,接入企业知识库。多模型编排:结合不同大模型完成复杂任务。Agent 工作流:让 AI 具备工具调用、Web 搜索、数据库查询能力。RAG 应用:Retrieval-Augmented Generation,结合向量库问答。对NVIDIA GPU的支持AnythingLLM对NVIDIA GPU的支持最为成熟和全面。这主要得益于其底层依赖的Ollama框架和CUDA生态系统的完善支持。NVIDIA GPU可以通过CUDA Toolkit实现硬件加速,并且AnythingLLM的开发者针对NVIDIA的Tensor Core进行了专门优化,能够显著提升本地大语言模型和RAG工作流的响应速度。在实际部署中,用户只需确保已安装正确的NVIDIA驱动和CUDA工具包,AnythingLLM便可自动利用GPU进行加速。1[10]对AMD GPU的支持AnythingLLM理论上支持AMD GPU,但其支持程度和易用性通常不如NVIDIA。实现支持的关键在于AMD GPU需要安装ROCm(Radeon Open Compute)平台,这是一个对标CUDA的开源计算平台。用户必须确保其AMD显卡型号在ROCm的支持列表内,并正确安装相应的驱动程序。与NVIDIA的“开箱即用”体验相比,使用AMD GPU可能需要更多的手动配置和环境调优,且在不同操作系统下的支持状态可能存在差异Dify 的核心功能Dify 核心组件概览Dify 的架构主要由 Web Frontend、API Backend、Worker 以及多个核心子系统构成,这些组件通过数据库、缓存和消息队列进行连接与协作。Web Frontend作用: 提供用户与 Dify 平台交互的图形化界面。开发者在这里创建、管理、调试和部署他们的 AI 应用(如聊天机器人、自动化工作流等)。所有操作,包括编排 Workflow、上传文件构建知识库、查看对话历史等,都通过它完成。技术: 通常基于现代框架如 Next.js 和 React 构建。API Backend作用: 这是 Dify 的核心大脑和交通枢纽。它承担了以下关键职责:请求处理: 接收来自 Web Frontend 或第三方集成的所有 RESTful API 请求。业务逻辑: 执行应用程序的核心逻辑,例如管理对话、协调工作流执行、处理检索增强生成(RAG)请求等。系统协调: 它本身不处理所有任务,而是作为协调者,调用其他子系统(如 Model Provider System, RAG System)并与其他基础设施(数据库、缓存)交互来完成请求。身份验证与授权: 验证用户身份和权限。技术: 通常使用 Python 框架(如 Flask 或 Django)构建。Celery Worker作用: 专门处理异步和耗时任务的后台进程。它的存在是为了避免长时间运行的任务阻塞 API Backend 的即时响应。典型任务: 为上传的文档构建索引。这个过程涉及读取文件、文本分块、生成向量嵌入(Embeddings)并写入向量数据库,非常消耗资源和时间,必须异步处理。关系: 通过消息队列(如 Redis)从 API Backend 接收任务。处理完成后,会更新数据库中的任务状态。核心子系统 (Core Subsystems)这些子系统是 API Backend 内部的逻辑模块,是实现不同功能的核心。Conversation System作用: 管理用户与 AI 应用之间的所有对话交互。负责创建对话会话(Session)、保存和检索对话历史消息、维护对话的上下文状态。这是实现连贯多轮对话的基础。Workflow System作用: 提供一个可视化工具(基于 ReactFlow 等库),允许用户通过拖放节点(Node)的方式,编排复杂、多步骤的 AI 任务流水线。节点类型包括 LLM 调用、工具调用、条件判断、知识检索等。关系: 在执行时,它会调用 Model Provider System 来获取 LLM 响应,也可以调用 RAG Knowledge System 来检索信息,或执行代码、调用外部 API 工具。RAG Knowledge System (或 Dataset System)作用: 实现检索增强生成(RAG)全流程的系统。处理知识库: 管理数据集的创建、文档上传、解析、分块。生成与存储索引: 协调文本的向量化过程,并将向量嵌入(Embeddings)存储到向量数据库(VectorDB)中。检索: 在查询时,根据用户问题从向量数据库中快速检索出最相关的文本片段,作为上下文提供给 LLM。关系: 严重依赖 VectorDB 和 Celery Worker(用于异步索引文档)。Model Provider System作用: 作为 LLM 的抽象层和统一网关。它集成了众多模型提供商(如 OpenAI, Anthropic, Azure OpenAI, 本地部署模型等),并对上层应用提供一致的调用接口。开发者在这里配置和管理不同模型的 API 密钥和参数。关系: 被 API Backend(处理直接聊天请求时)和 Workflow System(执行 LLM 节点时)调用,是平台与外部 AI 模型连接的桥梁。数据存储与基础设施 (Data Storage & Infrastructure)PostgreSQL:作用: 主数据库。存储所有结构化数据,包括但不限于:用户账户和权限设置AI 应用的配置信息对话记录(Conversation history)Workflow 的编排定义数据集(Dataset)元数据信息VectorDB (e.g., Qdrant, Weaviate, Milvus):作用: 向量数据库。专门用于存储和高效查询由文本生成的向量嵌入(Embeddings)。是 RAG 知识系统的核心存储,通过相似性搜索实现语义检索。Redis:作用: 多功能用途。缓存(Cache): 缓存频繁访问的数据(如会话状态、应用配置),减轻数据库压力,提升响应速度。消息代理(Message Broker): 作为 Celery 的任务队列,在 API Backend 和 Worker 之间传递异步任务消息。File Storage (e.g., S3, MinIO, Local Storage):作用: 存储用户上传的原始文件(如 PDF、Word 文档、图片等)。组件间如何协作Dify 的各个组件并非孤立工作,而是紧密协作的:用户通过 Web 前端 发起请求,例如创建一个新的聊天应用或启动一个工作流。请求到达 API 后端 (Flask),后端根据请求类型协调相应的核心子系统。子系统处理:如果是聊天请求,会话系统 会管理对话状态,并可能调用 模型供应系统 来获取LLM的响应,必要时通过 RAG 知识系统 从知识库检索信息增强上下文。如果是工作流执行,工作流系统 会解析流程定义,按顺序执行各个节点。节点可能调用 模型供应系统 中的LLM、通过 工具集成 访问外部服务,或使用 RAG 知识系统 进行检索。数据存储与访问:在整个过程中,PostgreSQL 用于存储结构化数据(如用户信息、应用配置),向量数据库 为 RAG 提供支撑,Redis 用于缓存和任务队列,文件存储 系统保存用户上传的文档。异步任务处理:对于耗时操作(如文档索引),API 后端会将任务发送到 消息队列 (Redis),由 Celery 工作节点 在后台异步处理。最终响应 通过 API 后端返回给 Web 前端,呈现给用户。安装 Dify 系统设备最低要求:CPU >= 2 CoreRAM >= 4 GiB安装 Dify 前,要先确保你的电脑上已经安装了 Docker 和 Docker Compose,使用 Docker Compose 启动 Dify 服务器是最简便的方式。git clone https://github.com/langgenius/dify.gitcd difycd dockercp .env.example .envdocker compose up -d5 GPT4AllGPT4All是一个强大的生态系统,它允许用户在本地计算机上运行自定义的大型语言模型(LLMs)。本文将详细介绍GPT4All的安装、使用方法以及案例应用,帮助用户全面理解和有效利用这一工具。GPT4All概述什么是GPT4AllGPT4All是一个开源项目,旨在提供一种在通用硬件上运行大型语言模型的方式。该项目由Nomic AI支持和维护,确保软件的质量和安全。GPT4All能在CPU和GPU上运行,支持多种操作系统,包括Windows、MacOS和Linux。GPT4All官网GPT4All的新功能GPT4All持续更新,引入了多项新功能,如GGUF格式的支持、Nomic Vulkan、LocalDocs功能和基于Docker的API服务器。这些功能进一步增强了GPT4All的灵活性和可用性。GPT4All的安装从官网下载GPT4All用户可以直接从GPT4All官网下载软件。下载后,用户需要更改安装目录以适配自己的计算机环境。更改安装目录创建模型文件夹安装GPT4All后,用户需要在软件目录中创建一个名为models的文件夹,用于存放下载的模型文件。创建模型文件夹启动GPT4All启动GPT4All后,用户需要在软件中修改目录,指向之前创建的models文件夹。修改目录GPT4All的使用方法加载模型用户可以通过GPT4All下载或从浏览器直接下载所需的模型文件,并将其移动到models目录下。GPT4All目前仅支持.gguf格式的文件。下载模型开始测试选择模型后,用户可以开始测试GPT4All的功能,如对话生成等。开始测试GPT4All的案例应用个人对话助手GPT4All可以作为个人对话助手,帮助解答日常问题。团队内知识库在团队中,GPT4All可以作为知识库,用于文档索引和搜索。网站客服智能对话GPT4All还可以作为网站客服,提供在线问题支持。教育培训辅助系统在教育培训领域,GPT4All可以作为辅助系统,提供学习问答帮助。LLMs之LLaMA3:基于GPT4All框架的模型部署通过GPT4All框架,用户可以实现LLaMA-3模型的部署和推理。用户可以加载训练后的LLaMA-3的.gguf模型文件,并在GUI界面中实现对话聊天。GPT4All Python SDK安装要开始使用,请在你的 python 环境中通过 pip 安装 gpt4all 包。pip install gpt4all我们建议使用 venv 或 conda 将 gpt4all 安装到其自己的虚拟环境中。加载 LLM模型通过 GPT4All 类按名称加载。如果这是你第一次加载模型,它将被下载到你的设备并保存,以便下次创建同名 GPT4All 模型时可以快速重新加载。GPT4All 经过优化,可在消费级硬件上运行参数范围为 30 亿至 130 亿的大型语言模型(LLMs)。LLMs 会被下载到您的设备上,因此您可以在本地私密地运行它们。借助我们的后端,任何人都可以在自己的硬件上高效安全地与 LLMs 进行交互。下载模型GPT4All 最便捷的部署方式是下载其官方桌面客户端(支持windows、linux(ubuntu)、macos)。这是一个可以直接安装和运行的应用程序,用户无需配置复杂的编程环境。安装后,用户可以在客户端内直接下载所需的模型文件(如 gguf 格式的模型),随后即可开始在本地与模型进行对话。这种方式极大地简化了部署流程,适合非技术背景或希望快速体验的用户,真正实现了“开箱即用”。2通过 Python 库进行部署对于开发者或希望进行深度集成的用户,GPT4All 支持通过 Python 环境进行部署。用户需要在本地安装 Python,并通过安装依赖包来运行模型。主要的步骤通常包括:配置 Python 环境并安装必要的依赖包。在代码中下载或指定模型文件路径。调用 GPT4All 的接口加载模型并进行推理对话。这种方式提供了更高的灵活性和控制权,例如可以集成到自定义的应用流程中。需要注意,在网络配置不当时(如开启了某些代理设置),可能会在下载或加载模型时遇到连接错误,通常的解决方法是调整本地网络环境。6 LocalAIocalAI的终极目标是成为OpenAI API的1:1本地替代品。如果你现有的应用是针对OpenAI开发的(比如用了LangChain或AutoGPT),你只需把API地址指向LocalAI服务器,就能在不修改代码的情况下,将云端AI替换为本地运行的模型。核心优势全模态支持,远超文本生成LocalAI不仅能跑文本大模型,还能直接运行:音频转录(Whisper、WhisperX支持说话人分离)语音合成(Pocket-TTS、VoxCPM,支持流式输出)图像生成(Stable Diffusion,v3.10.0新增视频生成)实时语音对话(v3.11.0引入Realtime Audio功能)音乐生成(Ace-Step MusicGen界面)原生支持Agent和MCP协议这是LocalAI相较于前两者的最大差异化优势。LocalAI原生支持模型上下文协议(MCP),可以让AI模型连接外部工具和API,实现实时数据访问、文件检索、命令执行等能力。2026年3月发布的v4.0.0更将LocalAI升级为一个完整的AI编排平台,带来了:全新React UI:完整的前端重写,交互体验大幅提升Agenthub社区中心:可以分享和导入预制的智能体配置Canvas代码预览模式:在聊天界面中并排显示代码块MCP客户端全面支持:工具流式传输、多服务器配置MLX分布式实验性支持:利用Apple MLX框架运行分布式工作负载极低的硬件要求LocalAI的模块化架构采用”按需下载后端”的设计,可自动检测硬件并支持CPU、GPU、Metal、Jetson甚至分布式加速。即使没有GPU,也能在普通CPU上流畅运行大模型。适合谁深入研究Agent协同架构、MCP协议的技术探索者需要在单一项目中同时处理语音、图像、文本多模态任务的人希望完全本地替代云端API,具备后端工程能力的DevOps工程师硬件配置建议:入门级:8GB内存 + 4核CPU体验级:16GB内存 + 8核CPU专业级:32GB内存 + GPU加速🚀 三种部署方案任你选方案A:Docker一键部署(最适合新手)基础CPU版本(推荐首次尝试):docker run -d --name my-localai \ -p 8080:8080 \ -v ./models:/models \ localai/localai:latest-aio-cpubashGPU加速版本(性能追求者):docker run -d --name localai-gpu \ -p 8080:8080 \ --gpus all \ -v ./models:/models \ localai/localai:latest-aio-gpu-nvidiabash方案B:源码编译安装(定制化需求)适合需要深度定制或开发环境搭建的用户:git clone https://gitcode.com/gh_mirrors/loc/LocalAIcd LocalAImake buildbash方案C:二进制包直装(极速体验)追求最简单快捷的用户选择:下载并运行wget https://github.com/go-skynet/LocalAI/releases/latest/download/local-ai-linux-x86_64chmod +x local-ai-linux-x86_64./local-ai-linux-x86_647 XinferenceXinference 是由 Xorbits 团队开发的一套 本地大模型推理和服务框架,目标是让你像用数据库一样简单地使用 LLM (大语言模型) 和 Embedding 模型,支持 Chat / Completion / Embedding / TTS / STT 等多种任务。官网:http://xinference.io[1]GitHub:http://github.com/xorbitsai/i…[2]模型任务类型说明二、核心特性支持多模型和多任务Chat :Qwen, ChatGLM, LLaMA, Baichuan, MistralEmbedding :BGE, Nomic, E5, InstructorCompletion :GPT-J, Pythia, RWKVTTS/STT :Whisper, Bark, Coqui一行命令启动xinference-local2025-07-21 10 28 11.png提供 REST API + OpenAI 符合接口REST 接口可直接调用兼容 OpenAI SDKWeb UI简洁易用,支持模型添加、操作、清除支持自由添加 HuggingFace 模型2025-07-21 10 26 12.png分布式和 CPU/GPU 选择支持单机 CPU ,多 GPU ,简易分布式启动三、安装指南依赖Python >= 3.9pip / conda 环境pip 安装pip install "xinference[all]"如果只需基础 REST 接口:pip install xinference四、启动 Xinferencexinference-local --log-level=info启动后访问:http://127.0.0.1:9997如看到 Web UI 界面,表明启动成功。五、注册模型注册 Chat 模型curl -X POST http://127.0.0.1:9997/v1/models \ -H "Content-Type: application/json" \ -d '{ "model_name": "qwen:0.5b", "model_format": "xinference", "quantization": "q4", "task": "chat" }'注册 Embedding 模型(本地免费推荐)注册 Embedding 模型前要安装 sentence_transformers 引擎,否则会启动失败。pip install -U sentence-transformerscurl -X POST http://127.0.0.1:9997/v1/models \ -H "Content-Type: application/json" \ -d '{"model_name": "bge-base-zh", "model_format": "xinference", "model_type": "embedding", "model_engine": "sentence_transformers" }' 8 llamafile你还在为部署大语言模型(LLM)时的复杂流程烦恼吗? llama.cpp框架虽强大但配置繁琐,Docker容器又占用过多资源,云服务更是存在数据隐私风险。现在,llamafile彻底解决了这些问题——一个文件即可分发和运行LLM,无需安装依赖,本地执行保障数据安全。本文将带你通过3个简单步骤,从零基础到成功运行自己的AI助手,同时揭秘跨平台兼容的核心技术原理。准备工作:认识llamafilellamafile是一种革命性的LLM分发格式,它将模型权重、运行时和Web服务打包成单个可执行文件。这种技术基于Mozilla的APE(Application Portable Executable)格式,实现了"一次构建,到处运行"的跨平台能力。项目核心优势包括:零依赖部署:无需预装Python、CUDA或特定系统库跨平台兼容:支持Windows、macOS、Linux等主流操作系统数据本地处理:所有计算在本地完成,避免隐私泄露体积优化:采用GGUF格式压缩模型,平衡性能与存储需求官方文档提供了完整技术细节:技术规格说明步骤一:获取llamafile文件llamafile提供两种使用方式:内置模型权重的完整包或仅含运行时的轻量版。对于新手,推荐从官方示例开始:下载预打包模型访问HuggingFace获取LLaVA多模态模型(4.29GB):llava-v1.5-7b-q4.llamafile该模型支持图像理解,可直接上传图片提问。验证文件完整性下载完成后检查文件大小是否为4.29GB,避免因网络中断导致的文件损坏。⚠️ 注意:Windows系统存在4GB可执行文件限制,若使用超过此容量的模型(如13B参数版本),需采用外置权重模式:外置权重使用指南步骤二:系统配置与权限设置不同操作系统需要进行简单的权限配置,以确保llamafile能够正常执行:Windows系统将下载的文件重命名为llava-v1.5-7b-q4.llamafile.exe右键文件 → 属性 → 安全 → 编辑,确保当前用户拥有"读取和执行"权限macOS系统打开终端,导航至下载目录:cd ~/Downloads添加可执行权限:chmod +x llava-v1.5-7b-q4.llamafile解决开发者验证问题:系统设置 → 隐私与安全性 → 底部允许"llava-v1.5-7b-q4.llamafile"运行Linux系统终端执行权限命令:chmod +x llava-v1.5-7b-q4.llamafile对于部分发行版(如Ubuntu),可能需要安装APE格式支持:sudo wget -O /usr/bin/ape https://cosmo.zip/pub/cosmos/bin/ape-$(uname -m).elfsudo chmod +x /usr/bin/apesudo sh -c "echo ':APE:M::MZqFpD::/usr/bin/ape:' >/proc/sys/fs/binfmt_misc/register"bash详细的系统兼容性问题解决方案:故障排除指南步骤三:启动与使用AI助手完成上述准备后,只需一个命令即可启动完整的AI服务:基础启动方式在终端中执行:./llava-v1.5-7b-q4.llamafilebash首次运行会显示初始化进度,成功后将自动打开浏览器,展示Web界面。若浏览器未自动启动,手动访问:http://localhost:80809 llama.cpp什么是 llama.cpp?llama.cpp 是一个用 C/C++ 编写的大语言模型推理框架,目标是在消费级硬件上高效运行 LLM。它支持 macOS、Linux、Windows 以及各种 GPU 加速后端,是目前最流行的本地 AI 推理工具之一。安装指南方式一:包管理器(推荐新手)macOS (Homebrew)brew install llama.cppWindows (winget)winget install llama.cppNix/NixOSnix-env -iA nixpkgs.llama-cpp方式二:下载预编译二进制访问 Releases 页面 下载对应系统的预编译版本,解压即可使用。方式三:使用 Dockerdocker run -it --gpus all ghcr.io/ggml-org/llama.cpp:latest方式四:从源码编译克隆仓库git clone https://github.com/ggml-org/llama.cppcd llama.cppmacOS / LinuxmakeWindows (使用 CMake)cmake -B buildcmake --build build --config Release启用 GPU 加速(可选)NVIDIA CUDAmake LLAMA_CUDA=1Apple Metalmake LLAMA_METAL=1Vulkanmake LLAMA_VULKAN=1获取模型llama.cpp 使用 GGUF 格式的模型文件。获取模型有几种方式:方式一:直接从 Hugging Face 下载使用 llama-cli 直接下载并运行llama-cli -hf ggml-org/gemma-3-1b-it-GGUF方式二:手动下载访问 Hugging Face 搜索 GGUF 格式的模型,例如:https://huggingface.co/ggml-orghttps://huggingface.co/TheBloke (大量量化模型)下载 .gguf 文件到本地。方式三:自己转换如果有原始模型(如 Hugging Face 上的 PyTorch 模型),可以使用 convert-hf-to-gguf.py 脚本转换:python convert-hf-to-gguf.py path/to/model --outfile model.gguf基本使用命令行交互使用本地模型文件llama-cli -m path/to/model.gguf指定更多参数llama-cli -m model.gguf \ -p "你好,请介绍一下自己" \ -n 512 \ --temp 0.7常用参数:-m:模型文件路径-p:提示词(prompt)-n:生成最大 token 数--temp:温度(创造性,0-1)--ctx-size:上下文窗口大小启动 API 服务器llama.cpp 可以启动一个 OpenAI 兼容的 API 服务器:llama-server -m model.gguf --host 0.0.0.0 --port 8080启动后,可以用任何 OpenAI 客户端连接:from openai import OpenAIclient = OpenAI(base_url="http://localhost:8080/v1", api_key="not-needed")response = client.chat.completions.create(model="local-model", messages=[ {"role": "system", "content": "你是一个有帮助的助手"}, {"role": "user", "content": "你好!"} ])print(response.choices[0].message.content)多模态使用(图像 + 文本)llama-cli -m llava-model.gguf \ --mmproj mmproj-model.gguf \ -i image.jpg \ -p "描述这张图片"高级配置GPU 加速NVIDIA CUDAllama-cli -m model.gguf -ngl 99-ngl 指定卸载到 GPU 的层数,99 表示全部卸载。Apple Metalllama-cli -m model.gguf -ngl 99Vulkanllama-cli -m model.gguf -ngl 99 -vgpu 0量化模型选择量化可以在几乎不影响质量的情况下大幅降低显存占用:上下文窗口调整llama-cli -m model.gguf --ctx-size 8192更大的上下文窗口可以处理更长的文档,但会增加内存占用。常见问题显存不足怎么办?使用量化程度更高的模型(如 Q4 instead of Q8)减少 -ngl 参数,让部分层在 CPU 上运行选择更小的模型(7B instead of 70B)推理速度太慢?确保启用了 GPU 加速(-ngl 99)使用量化模型减少 --ctx-size关闭不必要的后台程序如何保存对话历史?使用 --conversation 参数或自行管理对话历史:llama-cli -m model.gguf \ --conversation \ --conversation-file chat.json生态系统工具桌面应用LM Studio:图形界面,适合新手Jan:开源的本地 AI 平台Ollama:简化的模型管理工具编辑器插件VS Code: llama.vscodeVim/Neovim: llama.vim编程语言绑定Python: pip install llama-cpp-pythonNode.js: npm install node-llama-cppRust: cargo add llama-cpp-rs推荐的入门模型新手推荐(显存 8GB 以下)Gemma 3 1B/4BPhi-3 Mini (3.8B)Qwen2.5 3B/7B (量化版)中端配置(显存 12-16GB)LLaMA 3 8BMistral 7BGemma 2 9B高端配置(显存 24GB+)LLaMA 3 70B (量化版)Mixtral 8x7BQwen2.5 72B (量化版)总结llama.cpp 让本地运行大模型变得简单。无论你是想保护隐私、节省成本,还是单纯想学习 AI 技术,它都是一个优秀的起点。快速开始三步:安装 llama.cpp下载一个 GGUF 模型运行 llama-cli -m model.gguf开始你的本地 AI 之旅吧!9 JanJan 的主要功能之一是支持本地运行 AI 模型,如 Llama 或 Mistral,这样可以提高隐私性,不需要互联网连接。如果你需要讨论敏感内容,本地运行模型更为安全。例如,在需要保密的项目中,Jan 的本地模型功能可以确保对话的私密性和安全性。如果你不需要本地模型,Jan 也可以连接到远程模型,如 OpenAI、Gro 或 Mistral API,这样你就不需要高级硬件来访问这些模型的功能。这种灵活性特别有用,当你需要在线模型的能力但仍希望在必要时切换到本地模型。所有对话内容都存储在本地。此外,Jan 跨平台支持 Mac、Linux 和 Windows,极大地提升了可访问性。Jan 还提供了 API 端点,方便你在自定义应用程序或其他 AI 应用中使用,这些 API 端点与 OpenAI 兼容,所以你可以与任何支持 OpenAI 模型的应用程序一起使用。你还可以通过扩展选项设置其他功能,例如添加自定义插件以增强 Jan 的功能或将其与其他工具和服务集成。它支持处理 PDF、文档等任何可以解析的文本文件。Jan 有两个内置引擎用于推理:Llama CPP 和 Tensor RT LM,默认使用 Llama CPP。双引擎的设计为模型推理提供了更多的灵活性和选择。你还可以将 Jan 连接到 LM Studio 或 AMA 的端点。现在让我们安装并试用一下。首先,访问 Jan 的网站并点击下载按钮,选择你的操作系统并下载安装文件。10 本地大模型运行原理:以ollama 为例子简单来说,Ollama的工作流程确实是:将模型权重从硬盘加载至内存(或GPU显存),然后通过优化的推理后端进行计算。 但其中包含几个关键细节:模型存储与格式:GGUFOllama使用 GGUF (GPT-Generated Unified Format) 格式的模型文件。这种格式的特点是:已量化:您从Ollama库下载的模型,如 deepseek-r1:7b,已经是经过量化(例如Q4_K_M)的版本,文件大小比原始FP16模型小得多(如7B模型约3.8GB)。分层加载友好:GGUF格式允许系统只将当前计算需要的部分模型层加载到最快的内存(如GPU显存),其余部分可以留在系统内存或硬盘,这在资源有限的设备上至关重要。加载过程:动态且分层当您运行 ollama run deepseek-r1:7b 时,发生以下步骤:检查与准备:Ollama检查本地是否已有该模型文件。如果没有,则从服务器下载到硬盘(默认位置如 ~/.ollama/models)。分配计算设备:Ollama自动检测您的硬件环境。如果检测到性能足够的NVIDIA/AMD GPU,它会优先将模型权重加载到GPU显存中以获得最快速度。如果GPU显存不足或无GPU,它会自动回退到使用CPU和系统内存进行推理。智能加载:它不会一次性将整个模型文件“笨拙”地全部塞进显存。对于非常大的模型或显存不足的情况,Ollama的后端(通常是llama.cpp)可以执行分层卸载,只将最关键的层(如前20层)放在GPU显存,其余层留在内存甚至需要时从硬盘动态读取,以平衡速度与资源限制。推理计算:不直接调用CUDA后端引擎:Ollama本身不直接编写CUDA内核。它依赖一个名为 llama.cpp 的高效推理库作为其核心计算引擎。llama.cpp 是用C++编写的,它针对CPU和GPU(通过CUDA for NVIDIA,Metal for Apple Silicon)进行了深度优化。跨平台支持:在Mac上,llama.cpp 会调用 Metal Performance Shaders;在Windows/Linux的NVIDIA显卡上,它会调用 CUDA;在AMD显卡或纯CPU环境下,它使用高度优化的AVX指令集进行计算。简化操作:Ollama的价值在于,它为您封装了所有这些底层细节。您无需手动安装CUDA驱动、配置PyTorch或编译llama.cpp,一个简单的 ollama run 命令就完成了从下载、加载到运行的全部过程。总结流程整个流程可以概括为:硬盘(GGUF模型文件)↓ (按需、分层加载)系统内存 / GPU显存 (根据硬件自动选择)↓ (通过封装好的 llama.cpp 引擎)计算推理(在CPU/GPU上进行)↓ 生成回答 Ollama的魔力在于它通过GGUF格式、智能资源管理和封装的llama.cpp后端,让这个过程变得极其简单、自动化和高效,使得在消费级硬件上运行大模型成为可能
-
AI专题十九: AI 应用从低级到高级分类 山姆·奥特曼提出的官方框架:AI发展的“五个级别”奥特曼在多次访谈中(如2024年的一次闭门分享)清晰地提出了AI能力演进的五个级别,其核心是AI的自主性和解决问题的能力,而非单纯的应用形态。这五个级别是:级别1:对话式AI(Chatbot):能够进行开放域对话,但仅限于对话本身。代表:ChatGPT的对话模式。级别2:推理者(Reasoner):能够解决与人类博士水平相当的复杂问题。代表:OpenAI的o1模型。级别3:执行者/智能体(Agent):能够代表用户主动执行多步骤任务,例如“帮我预定下周的整个行程”。级别4:创新者(Innovator):能够自主进行研究和创造,提出新的想法和解决方案。级别5:组织者(Organizer):能够管理一个组织或大型项目,承担类似CEO的职能。结论:奥特曼的框架是 “能力等级”。从AI 应用场景从低级到高级:业界对这类 AI 应用没有一个完全统一的官方标准命名,但目前比较常见的分法,通常会按“能力层级 / 行为方式 / 所在环境”来命名。你提到的四类,可以大致对应成下面这样:1) 对话式 AI常见命名:Conversational AIChatbots / AI ChatbotsLLM assistantsCopilots(偏“辅助型”产品语境)特点:主要在文本/语音对话中完成问答、生成、总结、检索等任务不直接执行复杂动作,更多是“说”和“写”2) 智能体工作流 AI常见命名:AI AgentsAgentic WorkflowsWorkflow AgentsTask AgentsTool-using Agents / Tool-augmented Agents特点:不只是聊天,而是能调用工具、拆解任务、按步骤执行常见于:自动写邮件、查资料、生成报告、调用 API、触发业务流程“Workflow”一词强调人设计流程,AI 执行流程“Agentic”一词强调AI 自主性更强3) 操作电脑的 AI常见命名:Computer-Using Agents (CUA)Computer Use AIDesktop AgentsGUI AgentsBrowser Agents / Web AgentsRPA + AI(在企业场景里常和 RPA 融合提法)特点:AI 直接操作鼠标、键盘、浏览器、桌面软件不依赖 API 接口,而是像人一样看屏幕、点按钮、输入内容典型场景:自动填写表单、跨系统搬运信息、网页操作、后台流程执行这个方向近两年业界很常见的关键词就是 Computer Use 或 Computer-Using Agent。4) 进入物理世界的 AI 机器常见命名:Embodied AIRobotics / AI RoboticsPhysical AIRobot AgentsAutonomous RobotsGeneralist Robots(更偏前沿叙事)特点:AI 不再只在数字世界行动,而是驱动机器人、机械臂、无人设备等需要感知、规划、控制、与真实环境交互典型场景:仓储机器人、工业机械臂、家庭机器人、自动驾驶、无人机等其中:Embodied AI 更强调“具身智能”Physical AI 是近年 NVIDIA 等厂商带火的说法,强调 AI 进入现实物理环境Robotics 则是最通用、最传统的总称一个更常见的业界分层说法如果按“从低到高”或“从虚拟到物理”来概括,常会这样写:Conversational AIAI Agents / Agentic WorkflowsComputer-Using Agents / GUI AgentsEmbodied AI / Physical AI / RoboticsAI 智能等级L0~L5 定义根据搜索结果,目前全球范围内尚未形成像自动驾驶SAE标准那样唯一、权威且被强制遵循的AI智能程度分级标准。但借鉴自动驾驶分级思想,业界已涌现出多个从不同维度对AI智能化程度进行划分的分类框架,这些框架旨在为AI技术的发展路径提供评估坐标。自动驾驶分级标准作为参考基准自动驾驶的分级为AI智能化分级提供了直接的灵感来源。根据国际自动机工程师学会(SAE)的定义,驾驶自动化分为L0至L5六个等级,核心在于明确系统与驾驶员在动态驾驶任务中的角色分配。L0-L2级为辅助驾驶,驾驶员需持续监控;从L3级开始进入自动驾驶范畴,系统可在特定条件下执行全部驾驶任务;L5级为在任何环境下都能实现的完全自动驾驶。这一分级清晰地量化了机器替代人类驾驶的程度1121516。AI智能分级同样希望量化机器在认知、决策和行动任务上替代或辅助人类的程度。AI智能体与Agent能力分级的主要提案业界借鉴自动驾驶分级逻辑,提出了多个AI智能分级方案,其核心在于评估AI的自主决策和执行能力。360创始人周鸿祎提出了五级分类法:L1是仅有对话能力的聊天助手;L2是需人类设置流程的低代码工作流智能体;L3是能自主规划完成任务的推理型智能体(领域专家);L4是多智能体蜂群协作系统;L5则是具备完全自主意识的超级AI系统26。学术研究领域,有论文将AI智能体分为五个能力级别:从L0的无AI工具,到基于规则的L1,再到应用模仿/强化学习的L2,进而发展到基于大语言模型并具备记忆反思的L3,以及能自主学习和泛化的L4,最高级的L5则引入个性情感与多智能体协作35。OpenAI也建立了内部五级标准,从当前的ChatGPT(接近L2)到能够代表用户行动的L3、能创造新事物的L4,直至能执行组织工作的L5。这些分级框架都将关注点从单一的对话能力,扩展到了AI的任务规划、工具调用、自主执行及多智能体协作能力48。其他领域的智能等级评估标准智能化分级的思想已扩展到更广泛的终端领域。在AI手机领域,中国信息通信研究院联合厂商发布的《终端智能化分级研究报告》定义了L1至L5五个等级,从仅响应指令的L1,到能识别简单意图的L2,再到能处理复杂意图并自主规划的L3,最终发展到能预测意图并基于全场景自主规划的L59。在人形机器人领域,业界也发布了全球首个《人形机器人智能化分级》团体标准,围绕感知认知、决策学习、执行表现和协作交互四大维度,将智能化划分为L1至L5级10。这些标准表明,针对特定应用场景的智能化水平评估正在走向标准化。总结:概念框架而非统一标准综上所述,尽管汽车自动驾驶的L1-L5分级已被国际标准化,但AI智能程度目前尚未形成与之对应的全球统一官方标准。现有的多种分级方案均为企业、学术界或行业组织提出的概念性框架或团体标准,其目的在于为技术演进、产品定位和产业讨论提供参考坐标8。这些分级共同揭示了AI从被动工具到自主智能体的发展路径,有助于公众和业界理解AI技术的发展阶段与未来方向
-
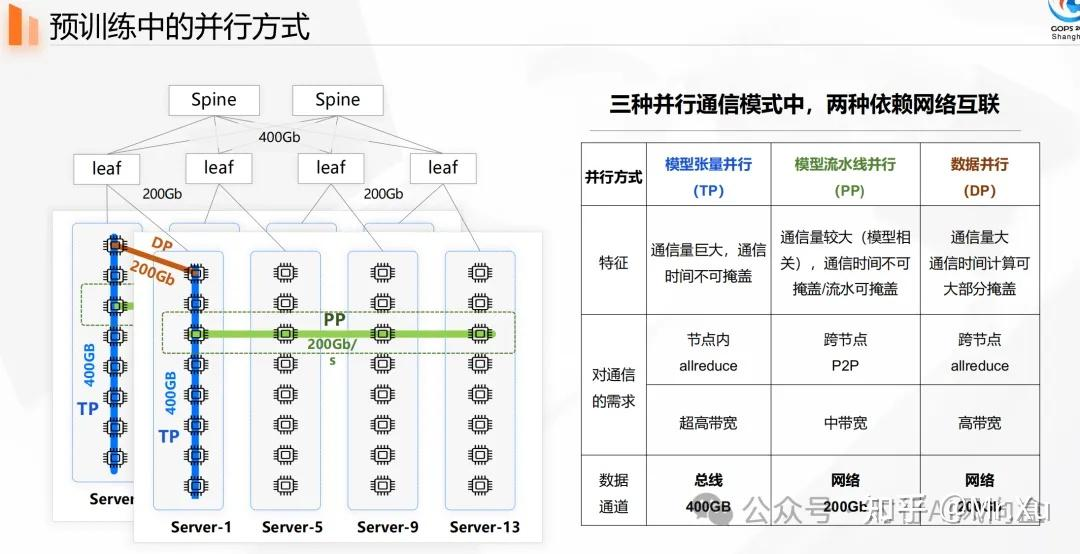
AI专题十五:AI算力卡互联 备注:未来主要是看Nvlink、UAlink、Unified Bus在 AI 训练和推理中,单卡性能固然重要,但当模型规模、数据量持续膨胀时,模型参数到达几十亿甚至上千亿参数,单张 GPU 的显存与算力已无法独立承载训练、推理任务,多卡并行成为唯一选择。这时候,卡与卡之间的互联带宽、延迟、拓扑结构 就成了制约整体性能的关键瓶颈。(图源:GOPS 全球运维大会暨研运数智化技术峰会 2024 · 上海站)本文主要介绍节点内部的GPU互联,节点间的GPU互联涉及网络部分,后面开新篇详细讲解。大模型训练时,模型的权重矩阵被切分到不同 GPU,每次前向/反向传播都要交换激活或梯度。这种通信量大但延迟敏感的场景,放在节点内更高效,因此单节点内,会经常有张量并行的场景。这种高带宽、低延迟的互联需求,也催生了GPU互联技术的发展。1、PCIe最初,大家都使用PCIe 进行互联,GPU 插卡通过 PCIe 接入主板,生态成熟、通用性强、设备即插即用。(图源:《电子发烧友》)但随着模型规模不断增大,PCIe 的带宽逐渐显得不足。以某PCIE GPU服务器为例,每个CPU下连接一个PCIe Switch芯片,每个PCIe Switch芯片连接5张GPU。GPU0-GPU3、GPU4-GPU7的两组GPU,内部可以通过PCIe switch通信,但如果需要跨组通信,只能通过CPU之间UPI来进行(GPU 1 -> PCIe 总线 -> CPU -> PCIe 总线 -> GPU 8)。(图源:元脑®服务器 NF5468G7 系列技术白皮书)不过,即使是最新的PCIe 技术,提供的带宽也有限。PCIe 4.0 x16 单向带宽约 32 GB/s,PCIe 5.0 64 GB/s。相比 GPU 内部早已上TB/s的显存带宽,这显然成了“木桶效应”中的短板,成了拉低通信效率的瓶颈。为了解决这一瓶颈,GPU 厂商开始探索专门的GPU互联通道。2、英伟达NVLinkNVLink首次作为GPU互联技术随NVIDIA P100 GPU推出,此后与每一代新的NVIDIA GPU架构同步发展。从最初的简单GPU-GPU连接,到如今的全系统互联解决方案,NVLink已经成为高性能GPU互联的代名词。2016年,NVLink 1.0 与 P100 GPU 一同发布(顺便说一句,Tesla P100也是全球首个支持高带宽 HBM2 内存技术的 GPU 架构),一张 GPU 支持最多 4 条 NVLink,每条链路双带宽约 40 GB/s ,整个芯片的总双向带宽达到了 160GB/s,大大突破了PCIe 3.0 带宽限制(PCIe 3.0 x16 双向仅 ~32 GB/s)。2017 年,NVLink 2.0 随 V100 (Volta 架构) 推出,每条链路双向带宽提升至 50 GB/s,单卡支持 6 条链路,总带宽最高 300 GB/s。NVLink2.0 技术虽然大大提高了带宽,但是单服务器中 8 个 GPU仍然无法做到全连接,为解决该问题,NVIDIA 在V100发布同年,发布了 NVSwitch,实现了 NVLink 的全连接。GPU所有的端口都用于与SW互联,数据在所有NVLink通道上交错传输,支持任意两块 GPU 之间的全带宽,NVLinks 的总带宽未超,对单个 GPU 的传输就不会阻塞。到如今,NVLink已经发展到了第五代,几乎每一代的带宽都是翻倍增长,最新的第五代性能已经高达1.8T/s。第五代NVIDIA NVSwitch更是配备144 个NVLink 端口,无阻塞交换能力达到了14.4 TB/s。备注:NVLink 和 NVSwitch 是英伟达(NVIDIA)为解决高性能计算和人工智能(AI)场景下多 GPU 间通信瓶颈而设计的两项核心技术。它们虽然紧密相关,但角色和功能有本质区别。下面从基础概念、功能定位、技术演进、工作原理和实际应用等方面进行详细分析。NVLink:点对点连接最初设计用于替代带宽受限的 PCIe 接口。支持两个设备(如 GPU-GPU 或 GPU-CPU)之间直接通信,提供远高于 PCIe 的带宽和更低的延迟。例如:两张 A100 GPU 通过 NVLink 直连,可实现高达 600 GB/s 的双向带宽(A100 SXM4)。NVSwitch:全互连拓扑构建者解决多 GPU 系统中“无法全互联”的问题。在一个服务器内(如 DGX 系统),NVSwitch 芯片允许多个 GPU(如 8 个或 16 个)通过 NVLink 连接到同一个交换矩阵上,实现“每个 GPU 都能直接与其它所有 GPU 通信”。消除了传统 PCIe Switch 或树状拓扑中的通信瓶颈。3、AMD Infinity FabricAMD 2017年随Ryzen/EPYC 首次提出Infinity Fabric,是一种专有的系统互联架构,用于促进所有连接组件之间的数据和控制传输。目前,Infinity Fabric已经进入了第四代,每条 Infinity Fabric 链路支持高达 32 Gbps 的传输速率,提供 128 GB/s 的双向带宽(跟PCIe 5.0很像呢)。 主要为环形或者网状拓扑。4、国产厂商互联技术国产芯片厂商的资料一般不公开,以下内容也是基于互联网资料整理的。华为昇腾HCCS昇腾 910B(尤其是 910B2)使用的是 HCCS 高速缓存一致性系统,相当于华为版本的 NVLink,专门用于芯片间高速通信与缓存一致性,卡间互连带宽为约 392 GB/s。华为unified bus衢定义为面向超节点(SuperPoD) 的统一互联协议,旨在将 I/O、内存访问、异构计算单元(CPU/NPU/GPU等)之间的通信融合到同一技术体系中,实现高性能、高协同、高弹性的计算基础设施。寒武纪 MLU-Link™多芯互联技术(公开资料比较老)MLU370-X8智能加速卡支持MLU-Link™多芯互联技术,提供卡内及卡间互联功能。寒武纪为多卡系统专门设计了MLU-Link桥接卡,可实现4张加速卡为一组的8颗思元370芯片全互联,每张加速卡可获得200GB/s的通讯吞吐性能,带宽为PCIe 4.0 的3.1倍,可高效执行多芯多卡训练和分布式推理任务。沐曦 MetaXLink采用自研MetaXLink高速接口,支持单机8卡全互联,显著提升多卡协同效率壁仞BLink原创BLink™高速GPU互连技术,单卡互连带宽最高达448 GB/s,并支持单节点8卡全互连燧原 GCU-LAREGCU-LARE全域互联技术是燧原专为AI训练集群研发的互联技术,提供双向300 GB/s互联带宽,支持数千张云燧CloudBlazer加速卡互联,可实现优异的线性加速比。Gen-ZGen-Z 其实是一堆行业巨头不满意 Intel 技术垄断和演进的情况下,合作搞出的新型高速互连标准,AMD、ARM、博通、Cray、戴尔 EMC、HPE、华为、IBM、联想、Mellanox (NVIDIA)、美光、红帽、三星、希捷、SK 海力士、西数、赛灵思等等都在其中,CPU,模组,网络,服务器,存储,连接器,操作系统,硬盘,FPGA的龙头老大都已经齐聚一堂,好像也看到无处不在的大陆连接器线缆龙头大哥,立迅精密.Gen-Z架构专注于提供高效率、高带宽和低延迟.Gen-Z 面向数据中心和服务器市场,是一种以内存为中心的总线结构式协议,具备高带宽、低延迟、先进工作负载、良好兼容性和经济性等优点.通过利用经过验证的装载/存储模型实现高效率。简化了Gen-Z硬件接口层,从而最大限度地减少了对软件层的需求。消除这种复杂性、开销和诱导系统延迟可以显着提高系统性能。高带宽以两种方式实现。Gen-Z支持非对称通信路径,这意味着可以将更多通道专用于读取路径而不是写入路径,反之亦然。此外,Gen-Z支持多种信令速率,包括16,25,32,56和112 GT / s,总而言之,这些功能将使Gen-Z能够跟上行业不断增长的速度需求,同时还允许将Gen-Z通信路径调整为特定的工作负载流量模式.通过减少软件堆栈来实现低延迟,与传统的服务器存储和大量分层的网络堆栈不同,Gen-Z采用轻量级软件接口,直接对硬件进行内存读写操作.Gen-Z 1.0 标准采用 PCIe 物理层和修改的 IEEE 802.3 以太网电气层标准,但在物理层上只定义了 PCIe 4.0,因此每通道速度最快只有 25GT/s,要想充分利用标准的全部性能,也必须满足 PHY 物理层面的所有规定.Gen-Z 1.1 则引入了 PCIe 5.0,每通道速度提高到 32GT/s,同时在比较宽松的技术限制下,就可以实现 Gen-Z-E-PAM4-50G-Fabric 链接,原始数据率 53.125GT/s,一切都以达到更高的传输速度、更低的延迟为目标,毕竟这也是该标准的初衷目前主流的AI算力芯片板卡(如NVIDIA、AMD、Intel的GPU/AI加速卡)均未采用Gen-Z接口。它们主要使用PCIe和厂商私有的高速互联协议(如NVLink、Infinity Fabric)。这背后是技术路线、生态锁定和成本效益等多重因素共同作用的结果。以下是详细分析:一、当前主流AI算力卡的互联接口PCI Express:行业标准与“基线”作用:这是所有AI加速卡与主机CPU、系统内存及其他设备通信的标准、必需的接口。目前主流是PCIe 5.0,正在向PCIe 6.0过渡。原因:PCIe是服务器和PC行业的通用标准,提供了必不可少的系统兼容性、枚举和基础I/O功能。任何加速卡都必须通过PCIe与主机连接。厂商私有高速互联协议:性能的“核心”NVIDIA NVLink:用于H100、B200等卡间的直接高速互联。其带宽远超PCIe(例如,H100的NVLink 4.0带宽达900GB/s),是构建多卡统一内存域、实现高效模型并行(如张量并行)的关键。它通过SXM形态或NVLink Bridge实现。AMD Infinity Fabric:在AMD Instinct MI300系列等加速卡上,用于GPU to GPU的直接高速连接,功能与NVLink类似,是AMD生态内构建多卡系统的核心。为什么用私有协议? 因为这些协议由芯片设计方深度定制,可以与自家GPU的架构(如内存控制器、缓存一致性协议)实现最优协同,达到极低的延迟和极高的带宽,这是通用标准短期内难以匹敌的。二、为什么Gen-Z未被AI算力卡采用?Gen-Z是一种以内存语义为中心的开放互连标准,旨在实现CPU、内存、加速器和存储之间的高效数据共享。它未能成为AI算力卡主流接口的主要原因如下:生态锁定与先发优势NVIDIA的统治地位:其NVLink + CUDA 生态已成为AI训练和高端推理的事实标准。客户购买H100不仅买硬件,更是购买整个软件栈和优化过的多卡通信库(如NCCL)。切换到Gen-Z意味着打破这个封闭但高效的生态,对NVIDIA和客户都无益处。AMD的路径依赖:AMD同样选择了发展自己的Infinity Fabric,并在其CPU(EPYC)和GPU(Instinct)之间通过 Infinity Architecture 进行深度集成,形成了自己的协同生态。技术定位与需求错配Gen-Z的核心优势在于内存池化和解耦,让各种设备可以像访问本地内存一样访问共享内存池。这对于某些数据中心架构(如分解式存储、内存池)很有吸引力。AI算力卡的核心需求是极致的点对点通信带宽和低延迟,以支持大规模模型并行训练。NVLink/Infinity Fabric作为紧耦合的专用互联,在为特定芯片对优化这方面,比通用的Gen-Z更有优势。成本与复杂性在主芯片(GPU)上集成额外的Gen-Z控制器会增加芯片面积、功耗和设计复杂性。在板卡和主板层面,需要增加Gen-Z所需的物理接口和线缆,这会增加系统成本和设计难度,而性能收益对于AI工作负载而言并不明确。标准竞争的结局近年来,另一个标准 CXL 在内存语义互连的竞争中逐渐占据了上风,得到了Intel、AMD、ARM及整个服务器生态链的更广泛支持。CXL基于PCIe物理层,兼容性更好,发展路径更清晰。行业焦点已从Gen-Z转向了CXL。三、未来趋势:CXL与UCIe虽然Gen-Z未成为主流,但解决内存墙和异构计算通信问题的需求依然存在,新的接口标准正在崛起:CXL:目前最受瞩目的行业标准。它运行在PCIe物理层之上,专注于实现缓存一致性的内存共享。未来,AI加速卡可能会集成CXL接口,目的不是为了卡间直连,而是为了让GPU能够更高效、更一致地访问CPU内存甚至池化内存,从而突破单卡显存容量限制。UCIe:这是一个芯片级的裸片互连标准。未来,AI算力芯片可能通过UCIe在封装内部直接与其他芯片(如CPU、专用加速器、HBM)连接,实现比板级互联更高的带宽和能效。这可以看作是“更近一步”的NVLink5.桥接器、SXM、OAM : 高速互联GPU的硬件实现这么多GPU高速互联的技术,最终都要落到实际的服务器硬件实现。第一种就是桥接器,最开始是NVIDIA 专为 PCIe GPU 而设计的物理桥接设备。它能让两个 GPU 建立直接高速连接,绕开主板的 PCIe 主干,总带宽远高于单纯依赖 PCIe 通道的多卡互联方式。后面很多其他厂商也学过去了。桥接器的好处就是,只用PCIe 服务器,就能获得高速互联,但是相对而言限制比较大,大部分可以做到2卡高速互联。要想做到单节点所有GPU全互联,就需要改变服务器的硬件形态了。以H100为例,板卡有两种形态,一种是PCIe板,一种是SXM板。SXM板集成了 H100 GPU 和 HBM3 内存堆栈,并支持第四代 NVLink 以及 PCIe Gen 5 连接,提供最优的应用性能。这种SXM卡用于英伟达的DGX/HGX平台,就是我们常说的GPU模组,这个模组里面集成了GPU、NVLink、NVIDIA 网络以及全面优化的 AI 和高性能计算 (HPC) 软件堆栈的全部功能。各家服务器厂商就根据英伟达的这个模组来开发服务器的硬件平台,大部分就是专供英伟达使用了。但是英伟达的模组都是自己私有化的,其他GPU厂商怎么办呢?2019年OCP全球峰会期间,百度宣布与Facebook、微软展开合作,联合制定OAM (OCP Accelerator Module)标准。该标准用于指导AI硬件加速模块和系统设计。2019年在美国丹佛举行的SC19全球超算大会上,浪潮正式发布全新的AI开放加速系统MX1,可在一个AI服务器支持多种符合OAM(OCP Accelerator Module)规范的AI芯片,这也是全球首个可支持多家不同型号的AI芯片直接更换的AI开放加速系统。OAM标准定义了AI加速器的统一接口,支持ASIC、GPU和FPGA等多种架构,并在物理形态、电源、连接器、引脚定义和系统架构方面提供创新设计。6. 未来演进UAlinkUALink 是 Alibaba、AMD、Apple、Astera Labs、AWS、Cisco、Google、HPE、Intel、Meta、Microsoft和Synopsys 发起。国内的一些AI 芯片厂商大概率会放弃自研的link 方式,切换到UAlink,因为实力和市场不容许。通用的UAlinkUltra Accelerator Link™ (UALink™)联盟于2024年10月注册成立,是致力于制定UALink规范的开放行业标准组织。该规范作为高速、可扩展的加速器互联技术,可提升下一代AI和高性能计算集群性能。联盟由行业领军企业组成的董事会领导,包括:Alibaba、AMD、Apple、Astera Labs、AWS、Cisco、Google、HPE、Intel、Meta、Microsoft和Synopsys。联盟制定的技术规范为新兴AI应用模式实现突破性性能提供便利,同时支持构建数据中心加速器的开放生态系统。UALink通用规范2.0为UALink技术引入网内计算,促进加速器之间的计算和通信。降低延迟、节省带宽,提升UALink系统在复杂和多工作负载环境下的AI解决方案分布式训练和推理的扩展效率。UALink 200G数据链路和物理层(DL/PL)规范2.0将DL/PL规范从UALink通用规范中拆分,使UALink能够根据行业对新型物理层和速率的需求快速迭代,无需修改其他规范。引入UALink作为具备集中控制平面和管理平面的系统。采用gNMI、Yang、SAI和Redfish等标准化协议、模型和应用程序接口。定义将UALink技术集成至基于芯粒的片上系统所需的关键信息,包括接口、外形规格、流量控制和芯粒管理标准化。完全兼容UCIe® 3.0规范,简化与现有芯粒生态系统的集成。UALink可管理性规范1.0UALink芯粒规范1.0随着UALink技术持续发展,联盟计划推出互操作性与合规项目,以支撑稳健的多厂商生态系统。欢迎有意推动UALink技术发展并参与相关项目建设的企业加入联盟,共同制定未来UALink规范。AMD 是为放弃Infinity Fabric 还是全面拥抱UAlink,AMD有这个实力。根据当前公开的技术信息和行业趋势,AMD在未来很可能会采取“双轨制”策略,即继续发展和使用Infinity Fabric作为其自家产品内部的核心互联技术,同时积极参与并推广UAlink作为跨厂商、开放生态的外部互联标准。两者并非替代关系,而是互补共存。Infinity Fabric将继续作为AMD产品架构基石Infinity Fabric是AMD自Zen架构以来为其处理器和加速器设计的专有、高性能内部互连总线。它深度集成于AMD的芯片设计中,用于连接CPU核心、CCD、IO芯片以及GPU,是实现其模块化设计和高性能的关键。放弃这一成熟且不断演进的技术(如发展到IFOP 3.0)对AMD而言既不现实也无必要。它将继续在EPYC CPU与Instinct GPU的紧耦合计算单元(如MI300X的8卡互联)中发挥核心作用。410AMD积极主导UAlink以构建开放生态对抗NVLinkUAlink的定位与Infinity Fabric不同。它是由AMD、英特尔、谷歌、微软等巨头联盟推动的开放式加速器互联行业标准,旨在为AI服务器集群中的任意品牌加速器(AMD、Intel等)提供高速、低延迟的互连方案,直接目标是打破英伟达NVLink的封闭生态壁垒。AMD是UAlink联盟的核心发起者和主推者之一,其动机在于通过开放标准吸引更多客户和合作伙伴,扩大其AI加速器的市场渗透率。因此,AMD必将大力支持并推广UAlink。2612两种技术将并存于不同场景未来AMD的产品路线图很可能呈现以下分工:内部紧密集成场景:在单机或机架内纯AMD硬件(如EPYC + Instinct MI系列GPU)构成的计算单元中,将继续优化并使用Infinity Fabric以实现最高效的內部通信。这是其性能优势所在。外部异构集群场景:在需要大规模扩展、或与其他厂商硬件(如英特尔GPU、第三方交换机)混合组网的AI数据中心集群中,AMD的加速器将支持并首选UAlink标准进行互联。这符合其开放生态战略。AMD已明确表示,其下一代机架级解决方案“Helios”将同时支持Infinity Fabric和UAlink。58结论:互补而非切换AMD不会“全面切换”到UAlink而放弃Infinity Fabric。相反,它将:对内巩固:持续投资Infinity Fabric,作为其芯片内部及自家产品组合间的高性能私有通道。对外开放:全力推动UAlink成为行业事实标准,确保其AI硬件能在多供应商环境中无缝互联,增强市场竞争力。这种策略使AMD既能保持核心技术优势,又能参与定义开放生态,是最符合其商业和技术利益的路径。对于用户而言,未来的AMDAI解决方案将根据部署环境(纯AMD栈或异构集群)灵活启用这两种互联技术。英特尔将采取“两手准备、优先自研、拥抱开放”的战略,最终会以自研技术为核心,同时积极兼容并影响开放标准(如UALink)。一、核心判断:英特尔的选择逻辑作为追赶者,必须打造差异化核心竞争力 英特尔深知,若只在通用GPU领域跟随英伟达,难以超越。其真正的差异化路线是 “XPU”异构计算,即将CPU、GPU、AI专用加速器(如Gaudi)、FPGA等通过高速互连集成。为此,自研的互联技术是其异构战略的“骨架”和核心技术壁垒,不可能完全放弃。生态建设的现实需求:必须加入开放阵营 作为市场挑战者,英特尔没有英伟达CUDA生态那样的统治力。要吸引客户(尤其是微软、谷歌等云巨头),就必须证明其产品能与现有基础设施(通常包含多厂商硬件)良好互通。加入并支持UALink这样的开放标准,是降低客户采用门槛、融入多云生态的必经之路。对于英特尔而言,自研互联技术(Xe Link, Foveros)与拥抱开放标准(UALink, CXL)不是非此即彼的选择,而是同时进行的双重战略:对内/底层:用顶尖的自研封装和互连技术(Foveros/EMIB/Xe Link)来保证其AI芯片产品的绝对性能和能效竞争力,这是与英伟达H100、AMD MI300系列正面竞争的硬实力。对外/上层:积极参与并领导CXL、UALink等开放标准,打造开放的、以CPU和通用标准为中心的异构计算生态。这既是团结盟友对抗英伟达的需要,也是其作为系统平台厂商和潜在代工厂商的长期利益所在。Unified BusUB协议在设计上旨在分层支持这四种互联场景,但其在不同层级的物理实现和性能目标有所不同。关于UB是否会全面替换华为原有的HCCS(High-Performance Computing and Communication Switching) 协议,答案是:UB是HCCS在架构上的演进和升级,预计将逐步成为华为未来全场景互联的单一协议栈,但替代过程是渐进的。技术演进关系:HCCS的定位:HCCS是华为早期自研的高速片上互联网络协议,主要用于鲲鹏CPU多核之间以及升腾NPU之间的高速互联18。它类似于AMD的Infinity Fabric或Intel的UPI,实现了多核间的一致性互联,为华为突破单芯片性能瓶颈提供了基础。UB的超越:UB不仅仅是芯片内或板级互联协议,其愿景更宏大——它旨在成为从芯片内到数据中心级别的统一互联架构。UB在协议层抽象了物理介质,可以运行在从封装内裸片链路到长距离光缆的不同物理层上10。替代的必然性与路径:架构代差:UB提供的“对等架构”和“统一内存空间”理念,比HCCS所服务的主从架构更先进,能更好地支撑超大规模智算集群10。产品路线图驱动:华为已经发布了基于UB的Atlas 950/960 SuperPoD超节点和TaiShan 950 SuperPoD通算超节点,这些新一代产品的核心互联已明确采用UB协议2711。这表明在新一代硬件平台上,UB已成为首选。生态统一需求:华为推行“硬件开放、软件开源”策略,一个统一的互联协议栈(UB)有利于降低生态伙伴的开发复杂度和成本712。过渡期安排:短期并存:在现有已部署的基于HCCS的硬件(如某些型号的鲲鹏服务器、升腾910等)生命周期内,HCCS仍将被支持。长期收敛:在2026年及之后的新一代产品(如升腾950、鲲鹏950后续型号)和超节点集群中,UB将全面成为互联基础,HCCS的角色将逐渐弱化或被整合进UB协议栈中311。结论华为Unified Bus是一个雄心勃勃的跨层级统一互联协议,旨在用一套架构覆盖从芯片到数据中心的全场景。它将不仅是HCCS的功能性替代,更是一次互联范式的升级,以适应“数据中心即计算机”的未来算力需求。因此,在华为未来的技术蓝图中,UB将成为唯一的、贯穿各级的互联主干,而HCCS将作为前期技术积累融入并最终收敛到这一主干中。NVlink这个没啥好说,英伟达为继续使用演进根据提供的搜索结果,NVLink技术自诞生至今的演进路线清晰展现了英伟达从构建高速GPU间互联到打造超大规模AI集群网络的雄心。其核心路径是从机内点对点互联演变为跨机箱的网络化超级互联。以下是其主要的演进阶段与关键里程碑:第一阶段:奠基与内部互联 (2016-2017)这一阶段的核心目标是突破PCIe瓶颈,在单台服务器内实现GPU间的高带宽直接通信。首发:NVLink 1.0 - 随Pascal架构(P100 GPU)推出。每块GPU配备4个端口,每个端口由8个速率为20 Gbps的通道组成,单端口双向带宽40 GB/s,单卡总带宽160 GB/s,在当时达到PCIe 3.0带宽的5-10倍。它实现了GPU间的点对点直接内存访问。1389第二阶段:规模化与拥抱CPU (2017-2020)目标从单个连接扩展到多GPU系统全互联,并开始将CPU纳入高速互联生态。NVLink 2.0 / NVSwitch 1.0 - 随Volta架构(V100 GPU)推出。单卡端口数增至6个,单通道速率提升至25 Gbps,单卡总带宽翻倍至300 GB/s。关键的创新是引入了NVSwitch交换芯片(最初18端口),首次实现了8个GPU间的全连接(Full Mesh),并开始支持与IBM POWER CPU的缓存一致性连接。239NVLink 3.0 / NVSwitch 2.0 - 随Ampere架构(A100 GPU)推出。单卡端口数大幅增至12个,采用更高速的50 Gbps通道(每端口4通道),总带宽再次翻倍至600 GB/s。NVSwitch升级至36端口,并支持通过背对背连接组建16卡全互联系统(如DGX A100)。269第三阶段:迈向超级网络 (2022年至今)技术定位从“内部互联”升级为可与InfiniBand竞争的独立网络设备,支撑千卡级AI集群。NVLink 4.0 / NVSwitch 3.0 - 随Hopper架构(H100 GPU)推出。单卡端口数达18个,采用PAM4调制实现100 Gbps通道速率(每端口2通道),单卡总带宽高达900 GB/s。NVSwitch 3.0支持64个端口,并集成了用于集合通信优化的SHARP功能。更重要的是,NVLink Network开始支持通过OSFP光模块进行机箱间的连接,实现了“单一节点”概念的巨大扩展。12469未来:NVLink 5.0及生态系统开放 - 根据路线图,下一代预计采用200 Gbps通道速率,带宽将继续提升。更重大的趋势是英伟达推出NVLink Fusion项目,计划通过IP授权方式,允许第三方厂商(如Intel, Arm, SiFive RISC-V)的CPU或其他加速器接入NVLink网络,旨在构建一个以NVLink为核心、更开放的异构计算生态。1710演进规律总结性能跃进:单通道速率按“20G→25G→50G→100G→200G(预计)”翻倍提升,同时通过增加单卡端口数(4→6→12→18→24预计)实现总带宽的指数级增长。79架构变革:从点对点连接,到引入NVSwitch实现全互联,最终演变为支持光电混合的跨机箱网络。145生态扩张:从专为NVIDIA GPU设计,到逐步开放生态,试图成为未来高性能计算和AI集群的统一互联标准。1011总而言之,NVLink的演进路线清晰地反映了AI计算对互联带宽和规模的需求增长,其发展已超越了单纯的GPU互联技术,成为定义现代超大规模AI基础设施架构的关键基石。PCIePCIe互联在高性能训练场景中的劣势PCIe在算力卡互联中的劣势主要体现在带宽和延迟上,使其难以胜任大规模AI训练任务。在高性能计算场景,尤其是需要多卡紧密协同的大模型训练中,PCIe的共享总线架构与NVLink等专用互联技术存在本质差距。NVLink专为GPU间高速直连设计,提供高达数百GB/s的带宽和微秒级延迟,并支持全互联拓扑;而PCIe最初为外设互联设计,用于多卡通信时带宽有限且延迟较高。例如,RTX 4090集群通过PCIe 4.0互联时,有效P2P带宽仅为理论值的12.5%-18.75%,8卡分布式训练AI模型时通信延迟可达NVLink方案的3.6倍,导致GPU利用率暴跌和大量算力空转。因此,在追求极致效率的数据中心训练场景,纯PCIe互联的算力卡难以与配备NVLink的专业卡竞争。139PCIe在推理、边缘及灵活部署场景中的优势尽管在高性能训练中存在瓶颈,但PCIe凭借其通用性、灵活性和成熟的生态,在推理、边缘计算和企业级部署中仍有显著优势与前途。PCIe接口具有极强的通用兼容性,无需改造服务器架构即可便捷部署,大幅降低了AI算力导入的门槛与成本。这在推理、轻量级训练、工业自动化等场景中至关重要,因为此类任务对通信带宽的要求相对较低,更注重部署的灵活性与经济性。同时,PCIe提供灵活的链路宽度(×1到×16),带宽代际演进清晰(目前已至PCIe 5.0/6.0),能适配不同算力等级的需求。在汽车等新兴领域,PCIe的超低延迟、高可靠性和直接内存访问优势,使其成为实时性要求高的边缘互连方案的补充。因此,专注于推理市场或采用非GPU架构的AI加速卡,完全可以依赖PCIe获得成功。257市场多元化与国产化带来的新兴机会在全球算力市场多元化与供应链自主可控的趋势下,仅使用PCIe互联的算力卡正迎来新的发展机遇。随着美国对高端AI芯片的出口限制,中国市场加速推动国产算力发展。许多国产AI芯片企业,如平头哥、寒武纪、燧原科技等,其产品主要通过PCIe形态切入市场。这些芯片在性能上可能不及顶级国际产品,但凭借PCIe的通用接口,能快速适配现有服务器,满足企业级推理、工业计算等广泛需求。此外,PCIe交换芯片作为算力网络的神经枢纽,在国产化进程中地位关键,其发展支撑了全国一体化算力网的建设。这意味着,在特定市场区域和差异化应用场景中,纯PCIe互联的算力卡不仅具有前途,而且是实现供应链安全与成本控制的重要路径。6810未来演进:CXL融合与专用交换芯片提升潜力PCIe互联的未来前途与其技术演进紧密相关,尤其是通过与CXL协议的融合以及专用交换芯片的智能化发展,PCIe有望突破传统外设接口的局限。未来,PCIe加速卡将随异构计算架构普及和CXL协议成熟进入新发展阶段。CXL建立在PCIe物理层之上,支持缓存一致性与内存池化,这将使通过PCIe连接的加速卡从外设转变为对等计算单元,大幅降低数据搬运开销。同时,专为PCIe优化的交换芯片正朝着超低延迟、CXL融合及光电共封装方向发展,以解决大规模集群的内部通信瓶颈。这些演进将使PCIe互联不仅能继续服务边缘与推理市场,更有潜力参与更复杂的异构计算任务,保持其作为通用高速互连基石的长期价值。
-
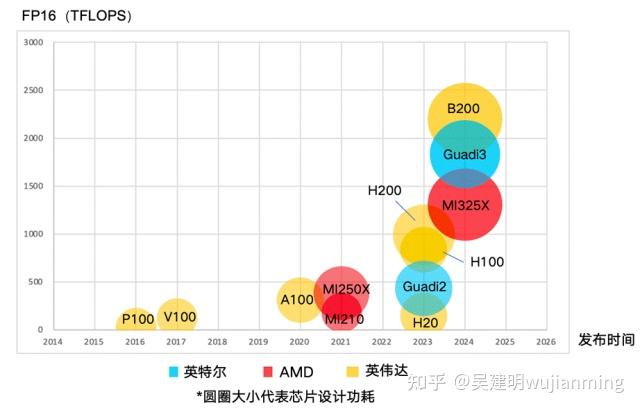
AI专题十三:地球上算力芯片参数汇总、整理、对比 摘自:https://zhuanlan.zhihu.com/p/1908027882829244313前言:AI大模型能力的快速提升(如Qwen3、Llama4的多模态升级与逻辑推理优化)正推动AI从辅助工具向核心生产力渗透。而算力芯片的性能对大模型的训练、推理至关重要。本文通过统计全球主要算力芯片的算力、显存和互联带宽指标,对比海外第三方设计公司、海外大厂自研和国产芯片的单卡性能。不考虑软件(如CUDA)、Scale out架构(如华为CloudMatrix超节点)和成本。华为芯片缺少官方公布数据,所有暂时没有收录。英伟达、英特尔、AMD英伟达的芯片覆盖最广,包括高性能的H100、H200和B200,以及较早的V100、P100等,其产品线在算力和迭代速度均占据领先地位。英特尔的AI芯片为Guadi系列(如Guadi3),而AMD是MI系列(如MI325X、MI250X)。从时间线看,英伟达迭代速度最快,2023年后密集发布新品;AMD的MI300系列和英特尔的Guadi3则瞄准了同期的英伟达B200竞争。功耗设计上,英伟达B200的圆圈显著更大,凸显其高功耗高性能定位。美国互联网大厂谷歌的TPU系列最为成熟,从v2到v7p逐步提升算力,其中v5p和v7p的能效比设计突出;亚马逊的Trainium3、Meta的MTIA v2和微软的Maia 100是较新的竞争者,发布时间集中在2023-2024年。这些芯片的算力普遍低于英伟达旗舰(如TPU v7p的FP16性能接近B200),但功耗更低(圆圈较小),反映其优化能效的特点。谷歌的TPU发布时间跨度大,显示其长期投入,而Meta、亚马逊和微软的布局更晚但速度迅猛。国产芯片寒武纪的思元590、海光信息的BW100和沐曦科技的曦云C500在算力和功耗上领先,发布时间集中于2023-2024年。整体来看,国产芯片的算力水平与英伟达中端产品(如A100)接近,但功耗控制更分散(圆圈大小差异大),反映技术路线多样性。发布时间显示2020年后中国AI芯片进入爆发期,但国际巨头仍保持性能代差。一、算力指标制程:海外:第三方设计公司:为后续产品制程的升级预留了空间。英伟达最新的Blackwell系列使用了TSMC 4NP,相当于4nm高性能版本。AMD、英特尔最新产品的制程都是5nm。Groq为了追求性价比,使用GlobalFoundries的14nm。大厂自研:谷歌最新的TPU Ironwood(TPU v7p)和亚马逊的Trainium3都使用了最先进的3nm,Meta和微软使用了5nm。中国大陆:国内厂商在受到制裁之前,旗舰产品绝大多数都是使用TSMC 7nm。目前正在转向中芯国际7nm。燧原科技的所有产品都采用GlobalFoundries 的12nm工艺。晶体管数量/芯片面积/晶体管密度:芯片面积:由于掩膜版的尺寸,单个芯片最大曝光区面积限制为858mm²,可以通过Chiplet构建更大的芯片。晶体管密度:更高的晶体管密度允许在相同芯片面积内集成更多计算核心,直接提升并行计算能力。海外:第三方设计公司:英伟达的B200首次使用了Chiplet技术,包含了两个B100 Die,两个Die通过NV-HBI互联,芯片面积达到1600mm²,晶体管密度达到130百万/mm²。AMD的芯片一直都采用Chiplet,由许多小芯粒组成大芯片,芯粒之间通过Infinity Fabric互联.大厂自研:谷歌最新的TPU Ironwood(TPU v7p)晶体管密度达到了308 百万/mm²,是英伟达Blackwell的两倍多。TPU v6e和微软的Maia 100分别达到110百万/mm²和128百万/mm²。中国大陆:国内厂商多使用Chiplet技术,增强算力、降低成本。燧原科技2021年发布的邃思2.0的芯片面积3306 mm²,采用GlobalFoundries 12nm工艺,号称中国最大AI单芯片,达到了日月光 2.5D 封装的极限。各浮点运算次数海外:第三方设计公司:英伟达Blackwell系列的推出,巩固了其在深度学习训练和推理的领导地位。GB200的FP16算力达到5000TFLOPS,相比于H200提升了5倍以上。AMD的MI325X为1300TFLOPS,英特尔Gaudi3为1835TFLOPS,谷歌TPU Ironwood(TPU v7p)为2307TFLOPS,与GB200都有明显差距。同时,Blackwell通过第二代Transformer引擎和定制Tensor Core,首次在硬件上实现了FP4数据类型的直接处理。H20/H800:H20基于H200进行性能裁剪,通过牺牲计算性能换取合规性。H20的FP16算力为148 TFLOPS,FP8算力为296 TFLOPS,仅为H200的15%左右。H800与H100算力指标保持一致,根据美国商务部2023年10月17日发布的出口管制新规,H800 被列入禁售名单。大厂自研:多数ASIC聚焦于低精度领域,除谷歌外都处于起步阶段。谷歌最新的TPU Ironwood(TPU v7p)是首款专为推理而设计的加速器,FP16算力达2307TFLOPS,比前代提升了两倍多。亚马逊的Trainium3预计FP16算力达1310TFLOPS,是Trainium2的两倍。中国大陆:除华为外,FP16算力能达到300TFLOPS以上的国产芯片,只有寒武纪的思元590和海光信息的BW100。壁仞科技在2022年推出的BR100的FP16算力能达到1024TFLOPS,但因受到制裁,无法量产落地。功耗/能效比能效比:FP16运算次数/功耗(TFLOPS/W)海外:第三方设计公司:英伟达Blackwell的能效比在所有架构里面最高,体现英伟达超强的硬件设计能力。尽管GB200的功耗达到了2700W,但能效比仍能达到1.9,在业内处于领先地位。大厂自研:多数ASIC的功耗在700W以下,达到降本目的。但能效比仍低于英伟达的GPGPU。中国大陆:根据不完全统计,国产芯片的功耗绝大多数都在500W以下,能效比低于1。二、显存指标显存/显存带宽/显存容量海外:绝大多数海外厂商最新产品都配备HBM3e,因堆叠层数、频率和HBM堆栈数量的配置不同,显存带宽和容量不同。英伟达从H200开始使用HBM3e。GB200的显存带宽达16TB/s,容量达384GB,是H200的三倍多。H20和H800的显存分别与H200和H100保持一致,远高于国产芯片。中国大陆:因受到制裁,绝大多数国产芯片最新产品使用HBM2e。除采用HBM外,还有国产芯片使用GDDR和LPDDR。如昆仑芯二代芯片和摩尔线程S4000、S3000均使用GDDR6,寒武纪MLU370系列均使用LPDDR5。算术强度算术强度:总浮点运算次数/内存带宽(FLOPS/Byte) 算术强度过高,说明内存带宽过低,芯片运行有内存瓶颈。海外:英伟达H100的算术强度较高,接近600FLOPS/Byte,随着HBM3e的使用,算术强度在H200和Blackwell系列逐渐降低。其他厂商因使用HBM3e且算力不高,算术强度都较低。中国大陆:国产芯片的算力水平较低,所以尽管显存带宽低,算术强度都较低,不存在带宽瓶颈。三、互联带宽双向互联带宽=每条链路单向带宽x链路数x 2海外:绝大多数厂商都开发了专有协议,带宽普遍在500GB/s以上。英伟达的NVLink5相比于NVLink4带宽翻倍,达到了1800GB/s。英伟达的NVLink依然有较强壁垒。AMD的Infinity Fabric4达到896GB/s。谷歌的ICI Links最高能达到672GB/s。H20使用NVLink4,带宽达到900GB/s,相较于国产芯片有较大优势。H800和A800都使用特供版NVLink,带宽只有400GB/s。中国大陆:国产芯片的互联能力普遍较弱,除华为外,带宽普遍在400GB/s以下。寒武纪思元270和思元590采用的MLU-Link,带宽分别达到600GB/s和372GB/s。海光信息BW100和沐曦科技的曦云C500的互联带宽能达到400GB/s。References:[1]英伟达:公司官网https://www.nvidia.cn/CSDN博客https://blog.csdn.net/qq_39815222/article/details/136897603墨天轮https://www.modb.pro/db/1830075219425452032[2]AMD:公司官网https://www.amd.com/zh-cn.html[3]英特尔:公司官网https://www.intel.cn/content/www/cn/zh/homepage.html[4]Groq:http://Sacra.comhttps://sacra.com/c/groq/[5]谷歌:The Next Platformhttps://www.nextplatform.com/2025/04/09/with-ironwood-tpu-google-pushes-the-ai-accelerator-to-the-floor/[6]亚马逊:Semianalysishttps://semianalysis.com/2024/12/03/amazons-ai-self-sufficiency-trainium2-architecture-networking/[7]Meta:公司官网https://ai.meta.com/blog/next-generation-meta-training-inference-accelerator-AI-MTIA/[8]微软:Semianalysishttps://semianalysis.com/2023/11/15/microsoft-infrastructure-ai-and-cpu/[9]寒武纪:公司官网https://www.cambricon.com/格隆汇https://finance.sina.com.cn/wm/2025-01-19/doc-inefpcsy0554481.shtml北方算网https://zhuanlan.zhihu.com/p/18044815862[10]昆仑芯:电子元件采购网https://www.ameya360.com/hangye/108036.html电子元器件采购网https://www.ameya360.com/hangye/108036.html知乎https://zhuanlan.zhihu.com/p/603925398捷睿星云http://www.jieruixingyun.com/busniess/intro/百度昆仑芯Product Briefhttps://paddlelite-demo.bj.bcebos.com/devices/baidu/K100_K200_spec.pdf[11]平头哥:公司官网https://img.102.alibaba.com/1622193035686/9898014ba4eb8adfd3f31db3b2cf26f3.pdf?spm=a2ouz.12987056.0.0.68229352l5LGSa&file=9898014ba4eb8adfd3f31db3b2cf26f3.pdf集微网https://www.sohu.com/a/374479009_166680[12]海光信息:鲸起Studiohttps://mp.weixin.qq.com/s/Oq3HZxFwOJuLTuwzj9RYQw北方算网https://zhuanlan.zhihu.com/p/18044815862华西证券研究所http://www.qdatis.com/files/20250207/447df7d38b08845b0b7fdf376030fd19.pdf格隆汇https://finance.sina.com.cn/wm/2025-01-19/doc-inefpcsy0554481.shtml[13]燧原科技: 美通社https://www.prnasia.com/story/296402-1.shtml与非网https://www.eefocus.com/article/498969.html智东西https://chedongxi.com/news/21214.htmlIT之家https://news.qq.com/rain/a/20211208A02G3B00[14]摩尔线程:公司官网https://www.mthreads.com/product/S3000TechPowerUphttps://www.techpowerup.com/316881/moore-threads-launches-mtt-s4000-48-gb-gpu-for-ai-training-inference-and-presents-1000-gpu-cluster[15]沐曦科技:CSDN博客https://blog.csdn.net/qq_23934063/article/details/132473834飞桨https://www.paddlepaddle.org.cn/support/news?action=detail&id=3334[16]壁仞科技:第一财经https://m.yicai.com/news/101501217.html电子工程专辑https://www.eet-china.com/mp/a152602.html[17]天数智芯:电子发烧友https://www.elecfans.com/d/2253998.html安信力http://www.anssionic.com/sgproducts_view.asp?main_id=20&small_id=71&id=244