搜索到
20
篇与
的结果
-
 AI专题十一:AI系统全景概述 部分内容来自:https://www.cnblogs.com/ZOMI/articles/18555010AI 系统:AI 时代连接硬件和上层应用的中间层软硬件基础设施。因此在部分语境中,又有人称为 AI Infra 人工智能的基础设施,但是因为基础设施更偏向于底层硬件、集群等内容,而 AI 系统是多的是强调让 AI 执行起来的系统体系结构,因此更愿意称包括软硬件的内容为 AI 系统。传统本地部署时代,三大基础软件(数据库、操作系统、中间件)实现控制硬件交互、存储管理数据、网络通信调度等共性功能,抽象并隔绝底层硬件系统的复杂性,让上层应用开发者能够专注于业务逻辑和应用功能本身的创新实现。云时代同理,形成了 IaaS、PaaS、SaaS 三层架构,其中 PaaS 层提供应用开发环境和基础的数据分析管理服务。类比来看,我们认为,进入 AI 时代也有承担类似功能的、连接算力和应用的基础设施中间层即 AI 系统,提供基础模型服务、赋能模型微调和应用开发。包括了如下图几个方面:大模型(算法应用)-AI训练和推理框架-AI编译和计算架构-AI硬件体系这四大体系的主要技术栈:下面分开简述这四大体系:AI 大模型AI 大模型框架实现解析:以 DeepSeek 系列为例目前主流 AI 大模型(包括 DeepSeek 系列)的底层实现主要依托于 PyTorch 生态,但在此基础上构建了高度定制化的训练与推理基础设施。具体的技术栈通常不对外完全公开,但通过开源模型结构与行业惯例可以推断其核心架构。以下是关于 AI 大模型实现框架的核心要点分析:.基础深度学习框架:PyTorch 主导 绝大多数现代大模型(包括 DeepSeek、Llama 系列)均使用 PyTorch 作为基础开发框架。PyTorch 的动态图机制便于模型调试与研究,其丰富的生态库(如 torch.nn、torch.distributed)为构建复杂的 Transformer 架构提供了标准接口。..分布式训练基础设施:定制化加速 为了支撑千亿参数规模的训练,团队通常会在 PyTorch 之上集成 DeepSpeed 或 Megatron-LM 等分布式库,甚至开发内部专有系统。针对 DeepSeek 特有的 MoE(混合专家)架构,训练框架需专门优化专家路由与负载均衡算法,以实现高效的稀疏计算。..推理引擎与部署优化:高性能运行时 模型部署阶段通常不再直接使用原生 PyTorch,而是转换为高性能推理引擎。常见的方案包括 vLLM、TensorRT-LLM 或自研推理后端,通过算子融合、量化(INT8/FP8)及显存优化技术,显著降低延迟并提升吞吐率。..模型互操作性与开源生态 为了兼容不同硬件与框架,大模型权重常支持导出为 ONNX 或 Safetensors 格式。DeepSeek 等开源模型允许社区在 Hugging Face 等平台直接加载,这意味着其结构定义遵循通用的 Transformers 库规范,便于跨框架迁移与二次开发。.综上所述,虽然具体的内部工程细节属于企业机密,但基于 PyTorch 的开源生态配合定制化分布式训练与推理引擎,是目前包括 DeepSeek 在内的大模型行业通用技术路径。这种架构既保证了研发的灵活性,又满足了生产环境对性能与稳定性的严苛要求。AI 训练与推理框架AI 训练和推理框架是深度学习生态系统中的基础设施,主要用于简化模型的开发、优化及部署流程。PyTorch 和 TensorFlow 确实属于这类框架,它们不仅支持模型的训练过程,也提供了推理能力,但在实际生产环境中,二者往往配合专用的推理引擎使用。框架的核心职能:从算法到算力的桥梁AI 框架的核心价值在于屏蔽底层硬件差异,让开发者专注于算法逻辑。它们通过自动微分机制计算梯度,利用计算图优化技术调度资源,从而实现高效的模型迭代。训练阶段:负责数据加载、前向传播、损失计算、反向传播及参数更新,支持分布式训练以加速大规模模型收敛。推理阶段:加载训练好的权重,对新数据进行预测计算,注重低延迟、高吞吐及内存占用优化。PyTorch 与 TensorFlow 的定位与差异这两款主流框架均覆盖了训练与推理的全链路,但设计哲学略有不同。PyTorch 以其动态图机制和灵活的 Python 接口著称,深受学术界和研发人员喜爱;TensorFlow 则拥有成熟的静态图优化能力和强大的服务端部署生态(如 TF Serving),在企业级生产中应用广泛。通用性:两者均支持构建复杂的神经网络结构,并提供丰富的预训练模型库。部署能力:虽然都支持直接推理,但为了极致性能,通常会将模型导出为中间格式(如 ONNX)或使用专用编译器(如 TorchScript、TFLite)进行加速。训练框架与推理引擎的生态协同在实际工程落地中,"训练框架"与"推理引擎"常有分工。训练框架侧重灵活性与易用性,而推理引擎侧重性能与资源管控。模型导出:训练完成后,模型常被转换为特定格式(如 .pt、.pb、.onnx),以便在不同硬件上运行。专用加速:生产环境常使用 TensorRT、OpenVINO 等推理引擎加载框架导出的模型,以充分发挥 GPU 或 NPU 的算力,实现比原生框架推理更高的效率。核心能力总结为了更清晰地理解这两类框架的功能边界,以下列举其关键能力:自动微分系统:自动计算梯度,免除手动推导公式的繁琐,是训练深度学习模型的基础。计算图优化:通过算子融合、内存复用等技术,减少计算开销并提升执行效率。硬件抽象层:统一接口支持 CPU、GPU 及各类 AI 加速芯片,实现代码的跨平台运行。生态工具链:提供数据预处理、模型可视化、调试及部署服务的一站式解决方案。动态与静态模式:支持动态图便于调试研发,支持静态图便于生产部署优化。综上所述,PyTorch 和 TensorFlow 是典型的 AI 训练与推理框架,它们构成了现代人工智能开发的主干。但在高性能部署场景下,通常会结合专用的推理引擎或编译器,以实现从算法研发到终端落地的最佳性能平衡。类似验证中的UVM、OVMAI编译器概述编译器可以将整个程序转换为目标代码(object code),这些目标代码通常存储在文件中。目标代码也被称为二进制代码,在进行链接后可以被机器直接执行。典型的编译型程序语言有 C 和 C++。当前,AI 编译器的发展阶段似乎回到了 GCC 出现之前的时代。每家 AI 芯片公司都在推出自己的 AI 编译器、框架 甚至软件栈,市场上出现了极度碎片化的现象。这种理解抓住了 AI 编译器的核心流向,但在具体的技术实现细节上存在简化。AI 编译器的工作流程比“直接编译 Python 到二进制”更为复杂,涉及多层抽象与优化。以下是对其输入输出机制的详细解析:输入层面:计算图与中间表示(IR)而非纯 Python 代码AI 编译器的直接输入通常不是原始的 Python 脚本,而是由深度学习框架(如 PyTorch、TensorFlow)生成的计算图(Computational Graph)或中间表示(IR)。技术细节:Python 在此过程中主要充当“宿主语言”,用于定义模型结构。编译器前端会通过追踪(Tracing)或图捕获(Graph Capture)技术,将 Python 代码转换为与语言无关的中间表示(如 ONNX、TorchScript、HLO 等)。原因:直接编译动态类型的 Python 代码效率极低,转换为静态 IR 后,编译器才能进行算子融合、内存优化等高级变换。输出层面:运行时引擎与集成库而非单一 Kernel 文件编译后的产出物通常不是一个独立的 GPU Kernel 二进制文件,而是一个包含多个优化算子、内存管理逻辑及调度策略的运行时库或模型引擎。技术细节:最终产物可能是动态链接库(.so/.dll)、序列化模型文件(如 TensorRT 的 .engine 或 TVM 的 .tar),其中封装了多个针对特定硬件优化的 Kernel 代码(如 CUDA PTX 或机器码)。原因:深度学习模型由成百上千个算子组成,编译器需要生成完整的执行计划,处理数据搬运、内核启动及同步,单一二进制文件无法承载完整的推理逻辑。Python 的角色:接口调度而非计算主体在整个编译与部署链路中,Python 主要承担接口调用与数据调度的角色,而非实际计算负载的承担者。技术细节:在推理阶段,Python 脚本负责加载编译好的二进制引擎,将输入数据张量传递给底层运行时,由编译后的 native 代码在 GPU 上执行密集计算。补充信息:这种架构设计实现了“开发效率”与“运行性能”的解耦,开发者使用友好的 Python 生态,而机器执行高效的底层二进制指令。综上所述,AI 编译器实质上是一个将高层模型描述转换为硬件专属高效指令集的翻译与优化系统,其核心价值在于屏蔽硬件差异并最大化算力利用率。AI硬件架构AI硬件架构主要包括CPU、GPU、TPU、NPU和LPU五大类型,并通过系统级协同和混合部署实现高效算力支撑。核心硬件类型与特点CPU(中央处理器)CPU专为通用计算设计,适合处理复杂逻辑、分支和系统级任务,严格遵循冯·诺依曼结构,核心包括控制单元和算术逻辑单元(ALU)。在AI系统中,CPU负责任务调度、队列管理、资源分配以及强化学习(RL)环境的仿真和多智能体控制。 GPU(图形处理器)GPU擅长大规模并行浮点运算,适合深度学习训练和推理。现代GPU通过CUDA、Tensor Core等技术支持通用计算,成为AI计算的核心加速器。 TPU(张量处理单元)TPU是Google开发的专用AI加速器,针对矩阵运算和深度学习优化,提供高吞吐量和低延迟,适合大规模模型训练和推理。NPU(神经网络处理器)NPU面向边缘设备和移动端AI应用,优化低功耗、高效推理,支持语音识别、图像处理等任务。LPU(逻辑处理单元)LPU用于特定逻辑加速场景,如AI推理中的规则计算和控制逻辑,通常与NPU或GPU协同工作。来源系统级协同与混合部署CPU-GPU协同:在多智能体、强化学习和复杂仿真场景中,CPU负责环境步进、控制逻辑和数据管理,GPU负责梯度计算和模型训练。提高CPU:GPU比值可优化GPU利用率,降低空转和延迟。 混合算力架构:结合本地GPU与云端租用GPU,形成“本地核心算力池+云端弹性算力池”,既保证数据安全和低延迟,又能应对突发峰值需求,实现成本和效率的平衡。 AI应用解决方案中的硬件架构成熟的AI应用通常由三大模块构成:智能硬件终端:支持多模态交互,如语音、人脸、触觉等。AI技术中台:提供核心算力和模块化能力,快速响应定制化需求。数据服务体系:收集用户行为数据,进行分析和策略输出,实现全链路闭环的智能决策。 发展趋势AI芯片市场持续增长,专用推理芯片和系统级性能优化成为核心竞争力。CPU与GPU的协同效率将成为数据中心设计重点,系统级优化取代单芯片性能。混合部署和垂直整合将加速,满足大模型训练、实时推理和多任务并发需求。 通过理解这些硬件架构及其协同方式,开发者可以根据应用场景选择合适的算力方案,实现AI系统的高效运行。
AI专题十一:AI系统全景概述 部分内容来自:https://www.cnblogs.com/ZOMI/articles/18555010AI 系统:AI 时代连接硬件和上层应用的中间层软硬件基础设施。因此在部分语境中,又有人称为 AI Infra 人工智能的基础设施,但是因为基础设施更偏向于底层硬件、集群等内容,而 AI 系统是多的是强调让 AI 执行起来的系统体系结构,因此更愿意称包括软硬件的内容为 AI 系统。传统本地部署时代,三大基础软件(数据库、操作系统、中间件)实现控制硬件交互、存储管理数据、网络通信调度等共性功能,抽象并隔绝底层硬件系统的复杂性,让上层应用开发者能够专注于业务逻辑和应用功能本身的创新实现。云时代同理,形成了 IaaS、PaaS、SaaS 三层架构,其中 PaaS 层提供应用开发环境和基础的数据分析管理服务。类比来看,我们认为,进入 AI 时代也有承担类似功能的、连接算力和应用的基础设施中间层即 AI 系统,提供基础模型服务、赋能模型微调和应用开发。包括了如下图几个方面:大模型(算法应用)-AI训练和推理框架-AI编译和计算架构-AI硬件体系这四大体系的主要技术栈:下面分开简述这四大体系:AI 大模型AI 大模型框架实现解析:以 DeepSeek 系列为例目前主流 AI 大模型(包括 DeepSeek 系列)的底层实现主要依托于 PyTorch 生态,但在此基础上构建了高度定制化的训练与推理基础设施。具体的技术栈通常不对外完全公开,但通过开源模型结构与行业惯例可以推断其核心架构。以下是关于 AI 大模型实现框架的核心要点分析:.基础深度学习框架:PyTorch 主导 绝大多数现代大模型(包括 DeepSeek、Llama 系列)均使用 PyTorch 作为基础开发框架。PyTorch 的动态图机制便于模型调试与研究,其丰富的生态库(如 torch.nn、torch.distributed)为构建复杂的 Transformer 架构提供了标准接口。..分布式训练基础设施:定制化加速 为了支撑千亿参数规模的训练,团队通常会在 PyTorch 之上集成 DeepSpeed 或 Megatron-LM 等分布式库,甚至开发内部专有系统。针对 DeepSeek 特有的 MoE(混合专家)架构,训练框架需专门优化专家路由与负载均衡算法,以实现高效的稀疏计算。..推理引擎与部署优化:高性能运行时 模型部署阶段通常不再直接使用原生 PyTorch,而是转换为高性能推理引擎。常见的方案包括 vLLM、TensorRT-LLM 或自研推理后端,通过算子融合、量化(INT8/FP8)及显存优化技术,显著降低延迟并提升吞吐率。..模型互操作性与开源生态 为了兼容不同硬件与框架,大模型权重常支持导出为 ONNX 或 Safetensors 格式。DeepSeek 等开源模型允许社区在 Hugging Face 等平台直接加载,这意味着其结构定义遵循通用的 Transformers 库规范,便于跨框架迁移与二次开发。.综上所述,虽然具体的内部工程细节属于企业机密,但基于 PyTorch 的开源生态配合定制化分布式训练与推理引擎,是目前包括 DeepSeek 在内的大模型行业通用技术路径。这种架构既保证了研发的灵活性,又满足了生产环境对性能与稳定性的严苛要求。AI 训练与推理框架AI 训练和推理框架是深度学习生态系统中的基础设施,主要用于简化模型的开发、优化及部署流程。PyTorch 和 TensorFlow 确实属于这类框架,它们不仅支持模型的训练过程,也提供了推理能力,但在实际生产环境中,二者往往配合专用的推理引擎使用。框架的核心职能:从算法到算力的桥梁AI 框架的核心价值在于屏蔽底层硬件差异,让开发者专注于算法逻辑。它们通过自动微分机制计算梯度,利用计算图优化技术调度资源,从而实现高效的模型迭代。训练阶段:负责数据加载、前向传播、损失计算、反向传播及参数更新,支持分布式训练以加速大规模模型收敛。推理阶段:加载训练好的权重,对新数据进行预测计算,注重低延迟、高吞吐及内存占用优化。PyTorch 与 TensorFlow 的定位与差异这两款主流框架均覆盖了训练与推理的全链路,但设计哲学略有不同。PyTorch 以其动态图机制和灵活的 Python 接口著称,深受学术界和研发人员喜爱;TensorFlow 则拥有成熟的静态图优化能力和强大的服务端部署生态(如 TF Serving),在企业级生产中应用广泛。通用性:两者均支持构建复杂的神经网络结构,并提供丰富的预训练模型库。部署能力:虽然都支持直接推理,但为了极致性能,通常会将模型导出为中间格式(如 ONNX)或使用专用编译器(如 TorchScript、TFLite)进行加速。训练框架与推理引擎的生态协同在实际工程落地中,"训练框架"与"推理引擎"常有分工。训练框架侧重灵活性与易用性,而推理引擎侧重性能与资源管控。模型导出:训练完成后,模型常被转换为特定格式(如 .pt、.pb、.onnx),以便在不同硬件上运行。专用加速:生产环境常使用 TensorRT、OpenVINO 等推理引擎加载框架导出的模型,以充分发挥 GPU 或 NPU 的算力,实现比原生框架推理更高的效率。核心能力总结为了更清晰地理解这两类框架的功能边界,以下列举其关键能力:自动微分系统:自动计算梯度,免除手动推导公式的繁琐,是训练深度学习模型的基础。计算图优化:通过算子融合、内存复用等技术,减少计算开销并提升执行效率。硬件抽象层:统一接口支持 CPU、GPU 及各类 AI 加速芯片,实现代码的跨平台运行。生态工具链:提供数据预处理、模型可视化、调试及部署服务的一站式解决方案。动态与静态模式:支持动态图便于调试研发,支持静态图便于生产部署优化。综上所述,PyTorch 和 TensorFlow 是典型的 AI 训练与推理框架,它们构成了现代人工智能开发的主干。但在高性能部署场景下,通常会结合专用的推理引擎或编译器,以实现从算法研发到终端落地的最佳性能平衡。类似验证中的UVM、OVMAI编译器概述编译器可以将整个程序转换为目标代码(object code),这些目标代码通常存储在文件中。目标代码也被称为二进制代码,在进行链接后可以被机器直接执行。典型的编译型程序语言有 C 和 C++。当前,AI 编译器的发展阶段似乎回到了 GCC 出现之前的时代。每家 AI 芯片公司都在推出自己的 AI 编译器、框架 甚至软件栈,市场上出现了极度碎片化的现象。这种理解抓住了 AI 编译器的核心流向,但在具体的技术实现细节上存在简化。AI 编译器的工作流程比“直接编译 Python 到二进制”更为复杂,涉及多层抽象与优化。以下是对其输入输出机制的详细解析:输入层面:计算图与中间表示(IR)而非纯 Python 代码AI 编译器的直接输入通常不是原始的 Python 脚本,而是由深度学习框架(如 PyTorch、TensorFlow)生成的计算图(Computational Graph)或中间表示(IR)。技术细节:Python 在此过程中主要充当“宿主语言”,用于定义模型结构。编译器前端会通过追踪(Tracing)或图捕获(Graph Capture)技术,将 Python 代码转换为与语言无关的中间表示(如 ONNX、TorchScript、HLO 等)。原因:直接编译动态类型的 Python 代码效率极低,转换为静态 IR 后,编译器才能进行算子融合、内存优化等高级变换。输出层面:运行时引擎与集成库而非单一 Kernel 文件编译后的产出物通常不是一个独立的 GPU Kernel 二进制文件,而是一个包含多个优化算子、内存管理逻辑及调度策略的运行时库或模型引擎。技术细节:最终产物可能是动态链接库(.so/.dll)、序列化模型文件(如 TensorRT 的 .engine 或 TVM 的 .tar),其中封装了多个针对特定硬件优化的 Kernel 代码(如 CUDA PTX 或机器码)。原因:深度学习模型由成百上千个算子组成,编译器需要生成完整的执行计划,处理数据搬运、内核启动及同步,单一二进制文件无法承载完整的推理逻辑。Python 的角色:接口调度而非计算主体在整个编译与部署链路中,Python 主要承担接口调用与数据调度的角色,而非实际计算负载的承担者。技术细节:在推理阶段,Python 脚本负责加载编译好的二进制引擎,将输入数据张量传递给底层运行时,由编译后的 native 代码在 GPU 上执行密集计算。补充信息:这种架构设计实现了“开发效率”与“运行性能”的解耦,开发者使用友好的 Python 生态,而机器执行高效的底层二进制指令。综上所述,AI 编译器实质上是一个将高层模型描述转换为硬件专属高效指令集的翻译与优化系统,其核心价值在于屏蔽硬件差异并最大化算力利用率。AI硬件架构AI硬件架构主要包括CPU、GPU、TPU、NPU和LPU五大类型,并通过系统级协同和混合部署实现高效算力支撑。核心硬件类型与特点CPU(中央处理器)CPU专为通用计算设计,适合处理复杂逻辑、分支和系统级任务,严格遵循冯·诺依曼结构,核心包括控制单元和算术逻辑单元(ALU)。在AI系统中,CPU负责任务调度、队列管理、资源分配以及强化学习(RL)环境的仿真和多智能体控制。 GPU(图形处理器)GPU擅长大规模并行浮点运算,适合深度学习训练和推理。现代GPU通过CUDA、Tensor Core等技术支持通用计算,成为AI计算的核心加速器。 TPU(张量处理单元)TPU是Google开发的专用AI加速器,针对矩阵运算和深度学习优化,提供高吞吐量和低延迟,适合大规模模型训练和推理。NPU(神经网络处理器)NPU面向边缘设备和移动端AI应用,优化低功耗、高效推理,支持语音识别、图像处理等任务。LPU(逻辑处理单元)LPU用于特定逻辑加速场景,如AI推理中的规则计算和控制逻辑,通常与NPU或GPU协同工作。来源系统级协同与混合部署CPU-GPU协同:在多智能体、强化学习和复杂仿真场景中,CPU负责环境步进、控制逻辑和数据管理,GPU负责梯度计算和模型训练。提高CPU:GPU比值可优化GPU利用率,降低空转和延迟。 混合算力架构:结合本地GPU与云端租用GPU,形成“本地核心算力池+云端弹性算力池”,既保证数据安全和低延迟,又能应对突发峰值需求,实现成本和效率的平衡。 AI应用解决方案中的硬件架构成熟的AI应用通常由三大模块构成:智能硬件终端:支持多模态交互,如语音、人脸、触觉等。AI技术中台:提供核心算力和模块化能力,快速响应定制化需求。数据服务体系:收集用户行为数据,进行分析和策略输出,实现全链路闭环的智能决策。 发展趋势AI芯片市场持续增长,专用推理芯片和系统级性能优化成为核心竞争力。CPU与GPU的协同效率将成为数据中心设计重点,系统级优化取代单芯片性能。混合部署和垂直整合将加速,满足大模型训练、实时推理和多任务并发需求。 通过理解这些硬件架构及其协同方式,开发者可以根据应用场景选择合适的算力方案,实现AI系统的高效运行。 -
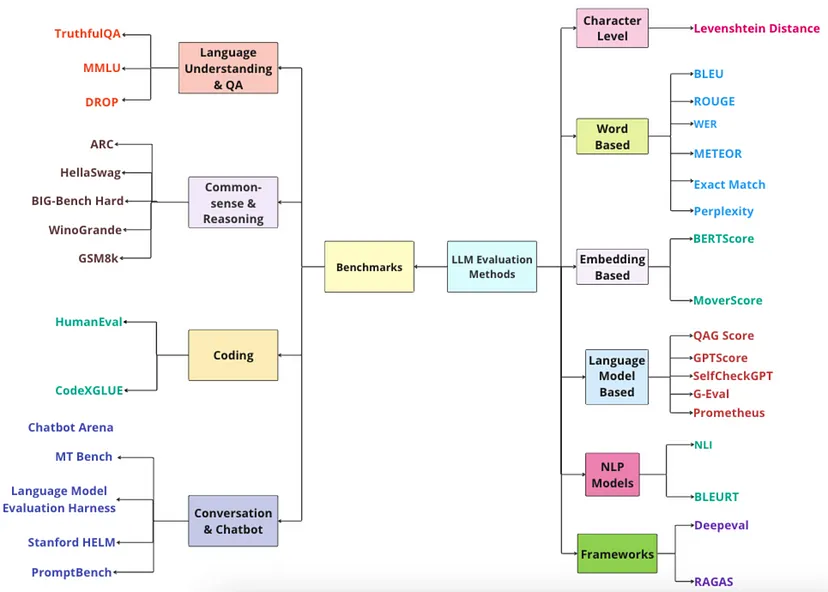
AI专题八:大模型的指标与评估方法 来自:https://zhuanlan.zhihu.com/p/26098146564首先,通过下面的表格来了解传统机器学习、深度学习和大语言模型之间的区别。大语言模型的出现为解决以往被认为不可能的问题开辟了新途径。但有一个问题仍待解答:如何有效地评估基于大模型的应用程序呢?在本文中,我们将试图揭开这个谜题,了解用于基准测试大语言模型的方法,讨论最前沿(SOTA)的方法、可用的框架,以及评估基于大语言模型的应用程序时面临的挑战。评估大语言模型的基本思路从哪里开始评估大语言模型?模型选择至关重要,因为它会影响项目的最终结果。在选定模型后,下一步就是思考如何评估它。许多从业者最初会依赖提示工程来评估模型的选择,但这不足以全面评估大语言模型的有效性,我们需要一个更全面的评估策略。模型评估是复杂的,涉及各种指标,这些指标因优先事项而异,无论是优先考虑准确性、成本效益还是性能。你选择的方向应与特定需求保持一致,确保所选模型不仅适用,还能优化你的应用场景。在为应用选择最佳大语言模型时,可参考以下简化方法(上图中有更多详细信息):是否有标准答案?是:如果模型提供离散输出,可使用传统的准确率指标。若不是,则考虑其他相似性指标,如ROUGE。否:进入步骤2。是否需要自动化评估?是:使用大语言模型评判器或评估器。否:进入步骤3。是否面临时间限制?是:选择独立指标,如文本质量、可读性或困惑度。否:黄金标准是人工评估。虽然它速度较慢且成本较高,但由于需要大量人力投入,能提供最可靠的反馈。接下来,我们将详细讨论这些技术。大语言模型基准测试与评估的差异虽然大语言模型的基准测试和评估紧密相关,但它们的目的存在细微差别:基准测试主要是标准化测试。它使用预定义的数据集和指标,评估大语言模型在特定任务上的表现。可以把它想象成给语言模型进行阅读、写作和数学测试(只不过是针对语言的测试!)。基准测试的优势如下:便于比较:研究人员可以通过基准测试,比较不同大语言模型在相同任务上的性能,有助于确定哪些模型在特定领域表现出色。量化结果:基准测试提供数值分数,清晰展示大语言模型的优势和劣势。评估的范围则更为广泛。它不仅仅是运行测试,还包括对大语言模型能力更全面的评估。在评估时,研究人员会考虑以下方面:实际适用性:大语言模型在模拟现实应用场景中的表现如何?公平性和偏差:大语言模型的输出是否存在偏差?可解释性:研究人员能否理解大语言模型得出答案的过程?评估通常以基准测试为基础。研究人员可能会将基准测试分数作为起点,但也会深入探究基准测试未涵盖的方面。简单来说,基准测试通过标准化测试进行定量评估,而评估则能让我们更定性地了解大语言模型的整体优势、劣势以及对现实应用的适用性。大语言模型基准测试大语言模型基准测试框架大语言模型基准测试是一组标准化测试,旨在评估大语言模型在各种技能(如推理和理解能力)上的表现,并使用特定的评分器或指标来衡量这些能力。根据不同的基准测试,指标范围可以从基于统计的度量(如精确匹配的比例),到由其他大语言模型评估的更复杂的指标。不同的基准测试评估模型能力的不同方面,包括:推理和常识:这些基准测试大语言模型运用逻辑和日常知识解决问题的能力。语言理解和问答(QA):评估模型解释文本和准确回答问题的能力。编码:该类别基准测试评估大语言模型解释和生成代码的能力。对话和聊天机器人:测试大语言模型参与对话并提供连贯、相关回复的能力。翻译:评估模型将文本从一种语言准确翻译成另一种语言的能力。数学:聚焦于模型解决数学问题的能力,从基础算术到微积分等更复杂的领域。逻辑:逻辑基准测试评估模型应用逻辑推理技能(如归纳和演绎推理)的能力。标准化测试:学术水平测试(如SAT、ACT)或其他教育评估也用于评估和基准测试模型的性能。有些基准测试可能只有几十项测试,而其他的可能包含数百甚至数千个任务。重要的是,大语言模型基准测试为跨不同领域和任务评估大语言模型的性能提供了标准化框架。为项目选择合适的基准测试意味着:• 目标一致:确保基准测试与大语言模型需要出色完成的特定任务相匹配。• 任务多样:选择具有广泛任务的基准测试,能全面评估大语言模型。• 贴合领域:选择与应用相关领域的基准测试,无论是理解语言、生成文本还是编码。可以把它们想象成高中生的学术水平测试,只不过是针对大语言模型的。虽然它们无法评估模型能力的方方面面,但确实能提供有价值的见解。下面是Claude 3在多个基准测试中与其他最前沿模型的性能对比。在接下来的部分,我们将讨论4个关键领域(语言理解、推理、编码和对话)的主要大语言模型基准测试。这些基准测试在行业应用中广泛使用,并经常在技术报告中被引用,包括:语言理解和问答基准测试3.1.1 TruthfulQA发布时间:2022年论文代码数据集点击可查看,或者文末在参考文献中查找目标:基于模型提供准确和真实答案的能力对其进行评估。这对于打击错误信息和促进人工智能的道德使用至关重要。• 数据集:原始数据集包含38个类别的817个问题,涵盖健康、法律、金融和政治等类别。问题聚焦于人类可能因错误信念或误解而给出错误答案的领域。• 性能:原始论文中表现最佳的模型GPT-3,成功率仅为58%,而人类基线为94%。• 评分:最终分数基于模型生成的真实输出的比例计算。经过微调的GPT-3(称为“GPT-Judge”)用于判断答案的真实性。3.1.2 MMLU(大规模多任务语言理解)• 发布时间:2021年• 论文代码数据集点击可查看,或者文末在参考文献中查找目标:基于模型的预训练知识评估模型,专注于零样本和少样本设置。基准测试:综合基准测试,通过涵盖57个学科(包括STEM、人文、社会科学等)的选择题评估模型,难度级别从基础到高级不等。该基准测试能很好地识别模型在特定领域的知识差距。评分:MMLU根据正确答案的比例对大语言模型进行评分。输出必须完全匹配才被视为正确(如上述示例中的“D”)。如果觉得MMLU难以使用,有个好消息。有人在开源大语言模型评估框架DeepEval中实现了几个关键基准测试,这样我们只需几行代码就能轻松对任何选定的大语言模型进行基准测试。首先,安装DeepEval:pip install deepeval然后,运行基准测试:from deepeval.benchmarks import MMLU from deepeval.benchmarks.tasks import MMLUTask benchmark = MMLU( tasks=[MMLUTask.HIGH_SCHOOL_COMPUTER_SCIENCE, MMLUTask.ASTRONOMY], n_shots=3 ) benchmark.evaluate(model=mistral_7b) print(benchmark.overall_score)更多实现细节,请访问DeepEval MMLU文档。3.1.3 DROP描述:DROP要求大语言模型对段落进行离散推理。这涉及解析问题中的引用,并执行加法、计数或排序等操作,需要对段落内容有全面的理解。评估设置:3次示例指标:在9536个段落理解问题上的F1分数论文:DROP: A Reading Comprehension Benchmark Requiring Discrete Reasoning Over Paragraphs以上就是开源大语言模型排行榜的七个主要基准测试任务。这些测试不仅评估大语言模型的知识,还评估它们的推理、理解和解决问题的能力。其他值得注意的语言理解和问答基准测试:GLUE、SuperGLUE、SQuAD和GPT任务、CoQA、QuAC、TriviaQA。常识和推理基准测试3.2.1 ARC(AI2推理挑战)发布时间:2018年论文代码点击可查看,或者文末在参考文献中查找描述:AI2推理挑战(ARC)使用小学水平的选择题科学问题测试大语言模型,问题难度从简单到复杂不等。例如,“光合作用产生什么帮助植物生长?”,选项为(a)水 (b)氧气 ©蛋白质 (d)糖。评估设置:25次示例指标:在3548个问题上的准确率,其中33%被指定为具有挑战性的问题。论文:Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge数据集:数据集大小为681MB,分为两组问题:ARC-Easy和ARC-Challenge。3.2.2 HellaSwag• 发布时间:2019年• 论文代码数据集描述:HellaSwag通过句子补全评估大语言模型的常识推理能力。它测试大语言模型是否能从10,000个句子的4个选项中选择合适的结尾。在预训练阶段,当时的最前沿模型得分很难超过50%,而2023年GPT-4通过10次示例提示达到了创纪录的95.3%。与MMLU类似,HellaSwag根据模型给出的完全正确答案的比例进行评分。使用方法:通过DeepEval使用HellaSwag基准测试的方法如下:from deepeval.benchmarks import HellaSwagfrom deepeval.benchmarks.tasks import HellaSwagTaskbenchmark = HellaSwag(tasks=[HellaSwagTask.TRIMMING_BRANCHES_OR_HEDGES, HellaSwagTask.BATON_TWIRLING], n_shots=5)benchmark.evaluate(model=mistral_7b)print(benchmark.overall_score)更多信息,请访问DeepEval的HellaSwag文档页面。3.2.3 BIG-Bench Hard(超越模仿游戏基准测试)发布时间:2022年、代码、数据集:论文代码数据集描述:BIG-Bench Hard(BBH)从最初的BIG-Bench套件中选择了23个具有挑战性的任务,该套件包含204个任务,这些任务在当时超出了大多数语言模型的能力范围。评估方式对比:标准(少样本)提示与思维链(CoT)提示(Wei等人)。在BIG-Bench发布时,没有一个最前沿的语言模型能够在这23个任务中的任何一个上超过平均人类评估者的表现。有趣的是,BBH的作者使用思维链提示,在其中17个任务上超越了人类表现。评分方式:虽然BBH的预期输出比其他基于选择题的基准测试更加多样化,但它同样基于精确匹配的比例对模型进行评分。思维链提示有助于使模型输出符合预期格式。使用方法:使用BBH基准测试的方法如下:from deepeval.benchmarks import BigBenchHard from deepeval.benchmarks.tasks import BigBenchHardTask benchmark = BigBenchHard( tasks=[BigBenchHardTask.BOOLEAN_EXPRESSIONS, BigBenchHardTask.CAUSAL_JUDGEMENT], n_shots=3, enable_cot=True ) benchmark.evaluate(model=mistral_7b) print(benchmark.overall_score)3.2.4 WinoGrande描述:WinoGrande测试人工智能的常识推理能力,要求模型解决Winograd Schema Challenge(WSC)。例如,完成句子:“门打开的声音比窗户大,因为___(选项:门或窗户)的铰链上有更多油脂。”评估设置:5次示例指标:在1267个问题上的准确率论文:WinoGrande: An Adversarial Winograd Schema Challenge at Scale3.2.5 GSM8k描述:GSM8K提供小学数学应用题,测试大语言模型的多步数学推理能力。例如:“一件长袍需要2卷蓝色纤维和蓝色纤维数量一半的白色纤维。总共需要多少卷纤维?”答案是3卷。评估设置:5次示例指标:在1319个问题上的准确率论文:Training Verifiers to Solve Math Word Problems其他值得注意的常识和推理基准测试:CommonsenseQA、COPA、SNLI、MultiNLI、RACE、ANLI、PIQA、COSMOS QA。编码基准测试3.3.1 HumanEval发布时间:2021年论文代码数据集描述:HumanEval由164个独特的编程任务组成,旨在评估模型的代码生成能力。这些任务涵盖从算法到编程语言理解的广泛领域。3.3.2 CodeXGLUE发布时间:2021年论文代码数据集![mnsif8描述:CodeXGLUE提供10个不同任务的14个数据集,用于在各种编码场景(如代码补全、代码翻译、代码摘要和代码搜索)中直接测试和比较模型。它是由微软开发部门和必应合作开发的。评估指标:CodeXGLUE的评估指标因编码任务而异,从精确匹配到BLEU分数不等。其他值得注意的编码基准测试:CodeBLEU、MBPP、Py150、MathQA、Spider、DeepFix、Clone Detection、CodeSearchNet。生成式人工智能模型根据其在4个数据集上的平均性能进行排名:ARC(25次示例)HellaSwag(10次示例)MMLU(5次示例)TruthfulQA(零样本)25次示例意味着在每个问题的提示中插入数据集中的25对(问题,解决方案)。3.4对话和聊天机器人基准测试3.4.1 Chatbot Arena(由LMSys开发)发布时间:2024年论文 代码Chatbot Arena是一个使用超过20万个人类投票对语言模型进行排名的开放平台。用户可以匿名向ChatGPT或Claude等人工智能模型提问并进行评判,且只有在模型身份保持隐藏的情况下,投票才会计入排名。所以它不是一个使用指标客观评分的传统基准测试!分数本质上就是 “点赞” 的数量。3.4.2 MT Bench发布时间:2021年论文 代码 数据集MT-bench通过向聊天助手提出一系列多轮开放式问题来评估其质量,并利用大语言模型作为评判者。这种方法测试了聊天助手处理复杂交互的能力。MT-Bench使用GPT-4对对话进行10分制评分,并计算所有轮次的平均分数以得到最终得分。所有这些基准测试在评估特定技能方面都非常有用,但是如果现有的基准测试与我们项目的独特需求不太匹配呢?3.4.3 语言模型评估工具包(由EleutherAI开发)语言模型评估工具包(Language Model Evaluation Harness)提供了一个统一的框架,用于在大量评估任务上对大语言模型进行基准测试。我特意强调 “任务” 这个词,因为在Harness(我将用Harness代替语言模型评估工具包)中没有 “场景” 这个概念。在Harness中,我们可以看到许多任务,每个任务包含不同的子任务。每个任务或一组子任务在不同领域评估大语言模型,比如生成能力、在不同领域的推理能力等。每个任务下的子任务(甚至有时任务本身)都有一个基准数据集,并且这些任务通常与一些在评估方面的重要研究相关。Harness致力于将所有这些数据集、配置和评估策略(比如与评估基准数据集相关的指标)统一并整合在一个地方。不仅如此,Harness还支持不同类型的大语言模型后端(例如:VLLM、GGUF等)。它在更改提示和进行实验方面具有很大的可定制性。下面是一个如何在HellaSwag任务(一个判断大语言模型常识能力的任务)上轻松评估Mistral模型的小例子:lm_eval --model hf \ --model_args pretrained=mistralai/Mistral-7B-v0.1 \ --tasks hellaswag \ --device cuda:0 \ --batch_size 8受语言模型评估工具包的启发,BigCode项目开发了另一个框架,名为BigCode Evaluation Harness,它试图提供类似的API和命令行界面方法,专门用于评估代码生成任务的大语言模型。3.4.4 斯坦福HELMHELM(语言模型整体评估,Holistic Evaluation of Language Model)使用 “场景” 来概述大语言模型的应用场景,并使用 “指标” 来明确在基准测试中我们希望大语言模型完成的任务。一个场景包括:• 一个任务(与场景相关)• 一个领域(包括文本的类型、作者以及创作时间)• 语言(即任务所使用的语言)然后,HELM会根据社会相关性(例如,考虑面向用户应用程序的可靠性的场景)、覆盖范围(多语言)和可行性(即选择任务的计算最优重要子集进行评估,而不是逐一运行所有数据点)来优先选择场景和指标的子集。HELM的评估分类结构不仅如此,HELM试图为几乎所有场景涵盖7个指标(准确性、校准度、稳健性、公平性、偏差、毒性和效率),因为仅仅依靠准确性并不能完全保证大语言模型性能的可靠性。3.4.5 PromptBench(微软开发)微软Prompt BenchPromptBench是另一个用于大语言模型基准测试的统一库。它与HELM和语言模型评估工具包(Harness)非常相似,支持不同的大语言模型框架(例如:Hugging Face、VLLM等)。它与其他框架的不同之处在于,除了评估任务之外,它还支持评估不同的提示工程方法,并在不同的提示级对抗攻击下评估大语言模型。我们还可以构建不同评估的管道,这使得生产级用例更易于实现。大语言模型基准测试的局限性虽然基准测试对于评估大语言模型的能力至关重要,但它们也有自身的局限性:• 领域相关性:基准测试往往难以与大语言模型应用的独特领域和上下文相匹配,缺乏法律分析或医学解读等任务所需的特定性。这一差距凸显了创建能够准确评估大语言模型在广泛专业应用中性能的基准测试所面临的挑战。• 生命周期短:在基准测试刚推出时,通常模型的表现都不太能达到人类基线水平。但过一段时间,比如1 - 3年,先进的模型会让最初的挑战变得轻而易举(就是例证)。当这些指标不再具有挑战性时,就有必要开发新的、有用的基准测试。不过,也并非毫无希望。通过合成数据生成等创新方法,克服这些局限性是有可能的。大语言模型评估指标大语言模型评估指标根据我们关心的标准对大语言模型的输出进行评分。例如,如果我们的大语言模型应用旨在总结新闻文章页面,我们就需要一个基于以下方面进行评分的评估指标:总结是否包含了原文中足够的信息。总结是否包含与原文相矛盾或凭空虚构的内容。此外,如果我们的大语言模型应用采用基于检索增强生成(RAG)的架构,我们可能还需要对检索上下文的质量进行评分。关键在于,大语言模型评估指标是根据其设计要完成的任务来评估大语言模型应用的(注意,大语言模型应用可以仅仅就是大语言模型本身!)。优秀的评估指标具有以下特点:可量化:指标在评估手头任务时,应该始终计算出一个分数。这种方法使我们能够设定一个最低通过阈值,以确定我们的大语言模型应用是否 “足够好”,并且让我们能够在迭代和改进实现的过程中,监测这些分数随时间的变化。可靠:鉴于大语言模型的输出可能不可预测,我们最不希望的就是评估指标同样不稳定。因此,尽管使用大语言模型评估的指标(如G-Eval)比传统评分方法更准确,但它们往往不一致,这也是大多数基于大语言模型评估指标的不足之处。准确:如果可靠的分数不能真正代表我们大语言模型应用的性能,那么它们就毫无意义。要使一个好的大语言模型评估指标变得更出色,秘诀在于尽可能使其符合人类的预期。那么问题来了,大语言模型评估指标如何计算出可靠且准确的分数呢?计算指标分数的不同方法有许多成熟的方法可用于计算指标分数,其中一些方法利用包括嵌入模型和大语言模型在内的神经网络,而另一些则完全基于统计分析。6.1 统计评分器6.1.1 词错误率(WER)词错误率(WER)是一类基于WER的指标,用于测量编辑距离 ,即把候选文本转换为参考文本所需的插入、删除、替换以及可能的换位操作的数量。6.1.2 精确匹配它通过将生成的文本与参考文本进行匹配来衡量候选文本的准确性。与参考文本的任何偏差都会被视为错误。这只适用于抽取式和短格式答案的情况,因为这种情况下期望生成的文本与参考文本的偏差最小或没有偏差。6.1.3 困惑度困惑度(PPL)是评估语言模型最常用的指标之一。在深入了解之前,我们应该注意,这个指标特别适用于经典语言模型(有时称为自回归或因果语言模型),对于像BERT这样的掩码语言模型并不适用。这也等同于数据和模型预测之间交叉熵的指数化。想要深入理解困惑度及其与每字符比特数(BPC)和数据压缩的关系,可以查看The Gradient上的这篇精彩博客文章。6.1.4 BLEUBLEU(双语评估替补,BiLingual Evaluation Understudy)分数是一种广泛用于评估机器翻译文本(候选文本)与参考译文(参考文本)质量的指标。由IBM研究人员开发,BLEU通过测量机器生成的文本与一组高质量参考译文之间的n元语法重叠来评估翻译的准确性,它主要侧重于精确率。BLEU以其简单性和有效性而闻名,是机器翻译领域的标准基准。然而,它主要评估的是表面层次的词汇相似性,常常忽略语言更深层次的语义和上下文细微差别。候选文本:这是我们想要评估的翻译系统的输出。参考文本:这些是高质量的翻译(通常由人工完成),我们将候选文本与之进行比较。为了保证稳健性,参考译文可以不止一个。计算方法from nltk.translate.bleu_score import sentence_bleu reference = [["A", "fast", "brown", "fox", "jumps", "over", "a", "lazy", "dog", "."]] generated = [["The", "quick", "brown", "fox", "jumps", "over", "the", "lazy", "dog", "."]] bleu_score = sentence_bleu(reference, generated) print('BLEU Score:', bleu_score)6.1.5 ROUGEROUGE(面向摘要评估的召回率替代指标,Recall-Oriented Understudy for Gisting Evaluation)是一组用于评估自动摘要和机器翻译的指标。它将自动生成的摘要或翻译与一组参考摘要(通常是人工撰写的)进行比较。ROUGE通过计算模型生成的文本与参考文本之间重叠的单元数量(如n元语法、单词序列和单词对)来衡量摘要的质量。ROUGE最常见的变体有:ROUGE-N:侧重于n元语法(N个单词的短语)。ROUGE-1和ROUGE-2(分别是一元语法和二元语法)最为常用。ROUGE-L:基于最长公共子序列(LCS),它自然地考虑了句子级别的结构相似性,并自动识别最长的共同出现的连续n元语法。ROUGE通常报告三个指标:精确率:模型生成的摘要中的n元语法在参考摘要中也出现的比例。召回率:参考摘要中的n元语法在模型生成的摘要中也出现的比例。F分数(F1分数):精确率和召回率的调和平均数,平衡了这两个指标。ROUGE分数的范围是从0到1,0表示机器生成的文本与参考文本没有重叠,1表示与参考文本完全匹配。from nltk.translate.bleu_score import corpus_rouge reference_summaries = [['A fast brown fox jumps over a lazy dog.']] generated_summaries = [['The quick brown fox jumps over the lazy dog.']] rouge_score = corpus_rouge(reference_summaries, generated_summaries) print('ROUGE Score:', rouge_score)6.1.6 METEORMETEOR(带显式排序的翻译评估指标,Metric for Evaluation of Translation with Explicit Ordering)是一种先进的机器翻译评估指标,旨在解决BLEU分数的一些局限性。与BLEU不同,METEOR不仅考虑精确的单词匹配,还纳入词干提取和同义词来评估翻译,从而捕捉更广泛的语言相似性。它在评估中独特地平衡了精确率和召回率,并引入了对词序差异的惩罚,以评估翻译的流畅性。METEOR与人类判断的相关性更高,尤其是在句子层面,使其成为一个细致全面的翻译质量评估指标。然而,它的复杂性也意味着它比BLEU等简单指标的计算成本更高。基于对齐:METEOR在候选翻译和参考翻译的单词之间创建对齐,关注精确匹配、词干匹配、同义词匹配和释义匹配。召回率和精确率:与仅考虑精确率的BLEU不同,METEOR同时计算精确率和召回率,这种双重关注有助于平衡评估。调和平均数:METEOR使用召回率和精确率的调和平均数,并且对召回率的权重更高(修改后的调和平均数,使召回率比精确率更重要),这与使用修改后的精确率的BLEU不同。词序差异惩罚:METEOR对错误的词序进行惩罚,这使得它对翻译的流畅性很敏感。语言无关:虽然METEOR最初是为英语开发的,但已经扩展到支持多种语言,并配备了特定语言的参数和资源。计算方法编辑距离(Levenshtein distance)评分器计算将一个单词或文本字符串转换为另一个所需的最少单字符编辑(插入、删除或替换)次数,这对于评估拼写纠正或其他对字符精确对齐至关重要的任务很有用。from meteor import meteor_score reference_sentence = 'A fast brown fox jumps over a lazy dog.' generated_sentence = 'The quick brown fox jumps over the lazy dog.' meteor_score = meteor_score.meteor_score([reference_sentence], generated_sentence) print('METEOR Score:', meteor_score)6.2 基于模型的评分器纯粹基于统计的评分器虽然可靠但不准确,因为它们难以考虑语义。在本节中,情况则恰恰相反,纯粹依赖自然语言处理(NLP)模型的评分器相对更准确,但由于其概率性质,也更不可靠。不出所料,非大语言模型的评分器比基于大语言模型评估(LLM-Evals)的评分器表现更差,原因与统计评分器相同。非大语言模型评分器包括:6.2.1 蕴含分数蕴含分数:这种方法利用语言模型的自然语言推理能力来评判自然语言生成(NLG)。这种方法有不同的变体,但基本概念是使用自然语言推理(NLI)模型针对参考文本生成蕴含分数,以此对生成的内容进行评分。这种方法对于确保像文本摘要这样基于文本的生成任务的忠实度非常有用。6.2.2 BLEURTBLEURT(基于Transformer表示的双语评估替补,Bilingual Evaluation Understudy with Representations from Transformers)是一种新颖的、基于机器学习的自动评估指标,能够捕捉句子之间细微的语义相似性。它在公开的评分数据集(WMT Metrics Shared Task数据集)以及用户提供的额外评分上进行训练。创建一个基于机器学习的指标面临一个基本挑战:该指标应该在广泛的任务和领域中始终表现良好,并且要经得起时间的考验。然而,训练数据的数量是有限的。实际上,公开数据很稀少 —— 在撰写本文时,最大的人类评分数据集WMT Metrics Task数据集仅包含约26万个涵盖新闻领域的人类评分。这对于训练一个适合评估未来自然语言生成系统的指标来说太有限了。为了解决这个问题,我们采用迁移学习。首先,我们使用BERT的上下文单词表示,BERT是一种最先进的无监督表示学习方法,用于语言理解,并且已经成功应用于自然语言生成评估指标(例如,YiSi或BERTscore)。其次,我们引入一种新颖的预训练方案来提高BLEURT的稳健性。我们的实验表明,直接在公开可用的人类评分上训练回归模型是一种不稳定的方法,因为我们无法控制该指标将在什么领域以及跨多长时间范围内使用。在存在领域漂移的情况下,即当使用的文本来自与训练句子对不同的领域时,准确性可能会下降。当要预测的评分高于训练期间使用的评分时,准确性也可能下降 —— 这本该是个好消息,因为这表明机器学习研究正在取得进展。BLEURT的成功依赖于在对人类评分进行微调之前,使用数百万个合成句子对来 “预热” 模型。我们通过对维基百科中的句子进行随机扰动来生成训练数据。我们没有收集人类评分,而是使用文献中的一系列指标和模型(包括BLEU),这使得训练示例的数量能够以极低的成本进行扩展。6.2.3 QA-QG问答 - 问题生成(QA-QG)(Honovich等人):这种范式可用于衡量任何候选文本与参考文本的一致性。该方法的工作原理是首先从候选文本中形成(候选答案,问题)对,然后比较并验证针对参考文本中相同问题集生成的答案。除了评分不一致之外,这些方法实际上还存在一些缺点。例如,自然语言推理评分器在处理长文本时准确性也会受到影响,而BLEURT则受其训练数据的质量和代表性的限制。6.3.1 G-EvalG-Eval是一篇题为《使用与人类判断更一致的GPT-4进行自然语言生成评估》的论文中最近开发的一个框架,它使用大语言模型来评估大语言模型的输出(也就是LLM-Evals)。G-Eval首先使用思维链(CoTs)生成一系列评估步骤,然后通过填空范式使用生成的步骤来确定最终分数(这只是一种花哨的说法,意思是G-Eval需要几个信息才能工作)。例如,使用G-Eval评估大语言模型输出的连贯性时,需要构建一个包含评估标准和待评估文本的提示,以生成评估步骤,然后使用大语言模型根据这些步骤输出1到5分的分数。让我们通过这个例子来梳理一下G-Eval算法。首先,生成评估步骤:向你选择的大语言模型提出一个评估任务(例如,根据连贯性对这个输出从1到5分进行评分)。定义你的标准(例如,“连贯性——实际输出中所有句子的综合质量”)。(注意,在最初的G-Eval论文中,作者仅使用GPT-3.5和GPT-4进行实验,就我个人使用不同大语言模型进行G-Eval的经验而言,强烈建议使用这些模型。 )在生成一系列评估步骤之后:通过将评估步骤与我们评估步骤中列出的所有参数连接起来创建一个提示(例如,如果我们要评估大语言模型输出的连贯性,那么大语言模型的输出将是一个必需参数)。在提示的末尾,要求它生成一个1到5之间的分数,5分表示比1分更好。(可选)从大语言模型获取输出令牌的概率以标准化分数,并将它们的加权和作为最终结果。第3步是可选的,因为要获得输出令牌的概率,我们需要访问原始模型嵌入,截至2024年,通过OpenAI API仍无法实现。不过,论文中引入这一步骤是因为它能提供更细粒度的分数,并最大限度地减少大语言模型评分中的偏差(正如论文中所述,在1 - 5分的评分尺度中,3的令牌概率往往较高)。更高的斯皮尔曼(Spearman)和肯德尔等级相关系数(Kendall-Tau)代表与人类判断的更高一致性。G-Eval很棒,因为作为一种大语言模型评估方法,它可以充分考虑大语言模型输出的语义,从而更加准确。这是很有道理的——想想看,使用远不如大语言模型强大的评分器的非大语言模型评估方法,怎么可能理解大语言模型生成的文本的全部含义呢?虽然与其他评估方法相比,G-Eval与人类判断的相关性更高,但它仍然可能不可靠,因为让大语言模型给出一个分数无疑是主观的。话虽如此,鉴于G-Eval的评估标准非常灵活,我个人已经在我参与开发的开源大语言模型评估框架DeepEval中,将G-Eval作为一个评估指标来实现。pip install deepeval export OPENAI_API_KEY="..." from deepeval.test_case import LLMTestCase, LLMTestCaseParams from deepeval.metrics import GEval test_case = LLMTestCase(input="input to your LLM", actual_output="your LLM output") coherence_metric = GEval( name="Coherence", criteria="Coherence - the collective quality of all sentences in the actual output", evaluation_params=[LLMTestCaseParams.ACTUAL_OUTPUT], ) coherence_metric.measure(test_case) print(coherence_metric.score) print(coherence_metric.reason)使用大语言模型评估的另一个主要优点是,大语言模型能够为其评估分数给出理由。6.3.2 PrometheusPrometheus是一个完全开源的大语言模型,在提供适当的参考材料(参考答案、评分标准)时,其评估能力可与GPT-4相媲美。它也与G-Eval类似,不依赖于具体的应用场景。Prometheus以Llama-2-Chat为基础模型,并在反馈收集中基于10万个由GPT-4生成的反馈进行了微调。以下是Prometheus研究论文中的简要结果:未选择GPT-4或Prometheus的反馈的原因。Prometheus生成的反馈不太抽象和笼统,但往往过于严苛。Prometheus遵循与G-Eval相同的原则。然而,它们之间也有几个区别:G-Eval是一个使用GPT-3.5/4的框架,而Prometheus是一个为评估而微调的大语言模型。G-Eval通过思维链生成评分标准/评估步骤,而Prometheus的评分标准是在提示中提供的。Prometheus需要参考/示例评估结果 。虽然我个人还没有尝试过,但Prometheus在Hugging Face上可以使用。我没有尝试实现它的原因是,Prometheus旨在实现评估的开源化,而不是依赖OpenAI的GPT等专有模型。对于那些旨在构建最优秀的大语言模型评估方法的人来说,它不太合适。6.4 结合统计和基于模型的评分器到目前为止,我们已经了解了统计方法可靠但不准确,而非基于大语言模型的方法虽然不太可靠但更准确。与上一节类似,也有一些非大语言模型评分器,例如:6.4.1 BERTScoreBERTScore(Zhang等人,2019年):这是一种基于双编码的方法,即候选文本和参考文本分别输入到深度学习模型中以获得嵌入。然后,使用令牌级的嵌入来计算成对的余弦相似度矩阵。接着,选择参考文本中与候选文本中最相似令牌的相似度分数,并用于计算精确率、召回率和F1分数。6.4.2 MoverScoreMoverScore(Zhao等人,2019年):使用词移距离的概念,该概念认为嵌入的词向量之间的距离在某种程度上具有语义意义(例如vector(king) - vector(queen) = vector(man) ),并使用上下文嵌入来计算n元语法之间的欧几里得相似度。与允许单词一对一硬匹配的BERTScoreBERTScore和MoverScore评分器都容易受到上下文感知和偏差的影响,这是由于它们依赖于像BERT这样的预训练模型的上下文嵌入。那么大语言模型评估(LLM-Evals)呢?6.4.3 GPTScore与使用填空范式直接执行评估任务的G-Eval不同,GPTScore使用生成目标文本的条件概率作为评估指标。6.4.4 SelfCheckGPTSelfCheckGPT比较独特,它是一种基于简单采样的方法,用于对大语言模型的输出进行事实验证。它假设虚构的输出是不可重现的,而如果大语言模型知道某个给定概念,那么采样得到的回复可能会相似,并且包含一致的事实。SelfCheckGPT是一种有趣的方法,因为它使检测虚构内容的过程无需参考,这在实际生产环境中非常有用。然而,尽管我们会注意到G-Eval和Prometheus不依赖于具体应用场景,但SelfCheckGPT并非如此。它仅适用于检测虚构内容,而不适用于评估其他场景,如总结、连贯性等。6.4.5 QAG分数QAG(问答生成,Question Answer Generation)分数是一种利用大语言模型强大推理能力来可靠评估大语言模型输出的评分器。它通过对封闭式问题(可以生成或预设)的回答(通常为“是”或“否”)来计算最终的指标分数。它之所以可靠,是因为它并不直接使用大语言模型来生成分数。例如,如果我们想要计算一个关于忠实度的分数(用于衡量大语言模型的输出是否存在虚构内容),我们可以:使用大语言模型提取大语言模型输出中提出的所有主张。对于每个主张,询问事实依据是否同意(“是”)或不同意(“否”)该主张。所以,对于下面这个大语言模型输出的例子: “马丁·路德·金,这位著名的民权领袖,于1968年4月4日在田纳西州孟菲斯的洛林汽车旅馆被暗杀。他当时在孟菲斯支持罢工的环卫工人,在汽车旅馆二楼的阳台上被越狱逃犯詹姆斯·厄尔·雷致命枪击。”其中一个主张可以是:“马丁·路德·金于1968年4月4日被暗杀”,相应的封闭式问题则是:“马丁·路德·金是在1968年4月4日被暗杀的吗?”然后,我们会拿这个问题去询问事实依据是否同意该主张。最后,我们会得到一些“是”和“否”的答案,我们可以使用自己选择的数学公式来计算分数。在忠实度的例子中,如果我们将其定义为大语言模型输出中准确且与事实依据一致的主张的比例,那么通过将准确(真实)主张的数量除以大语言模型提出的主张总数,就可以轻松计算出该比例。由于我们不是使用大语言模型直接生成评估分数,而是仍然利用它们卓越的推理能力,因此我们得到的分数既准确又可靠。评估基于大语言模型的应用7.1. 选择评估指标大语言模型应用的评估指标是根据交互模式和预期答案的类型来选择的。与大语言模型的交互主要有三种形式:知识寻求:向大语言模型提出一个问题或指令,并期望得到一个真实的答案。例如,印度的人口是多少?文本关联:给大语言模型提供一段文本和指令,并期望答案完全基于给定的文本。例如,总结给定的文本。创造力:向大语言模型提出一个问题或指令,并期望得到一个有创意的答案。例如,写一个关于阿育王王子的故事。对于这些交互或任务中的每一个,预期的答案类型可以是提取式、摘要式、短格式、长格式或选择题。例如,对于大语言模型在科学论文总结(文本关联+摘要式)中的应用,结果与原始文档的忠实度和一致性至关重要。7.2. 评估评估方法!一旦我们制定了适合我们应用的评估策略,在使用它来量化实验性能之前,我们应该先对该策略进行评估。评估策略是通过量化其与人类判断的相关性来进行评估的。获取或标注一个包含人工标注的“黄金标准”分数的测试集。使用我们的方法对测试集中的生成内容进行评分。使用肯德尔等级相关系数等相关度量方法,衡量人工标注分数与自动评分之间的相关性。一般来说,分数达到0.7或以上就被认为足够好了。这也可以用来提高我们评估策略的有效性。7.3. 构建评估集在为任何机器学习问题构建评估集时,需要确保两个基本标准:数据集应该足够大,以产生具有统计意义的结果。它应该尽可能代表生产环境中预期的数据。基于大语言模型的应用的评估集可以逐步构建。还可以利用大语言模型通过少样本提示为评估集生成查询,像自动评估器这样的工具可以帮助完成这项工作。构建一个带有事实依据的评估集既昂贵又耗时,并且要在数据漂移的情况下维护这样一个经过人工标注的“黄金标准”测试集是一项极具挑战性的任务。如果无监督的大语言模型辅助方法与我们的目标相关性不好,那么可以尝试这种方法。参考答案的存在可以在诸如事实性等某些方面提高评估的有效性。大语言模型评估框架评估大语言模型以衡量它们在各种应用中的质量和效果至关重要。人们专门设计了许多框架来评估大语言模型。下面,我们重点介绍一些最广为人知的框架,如微软Azure AI 工作室中的Prompt Flow、与LangChain结合使用的Weights & Biases、LangChain开发的LangSmith、confidence-ai开发的DeepEval、TruEra等等。8.1. DeepEvalDeepEval是一个用于大语言模型的开源评估框架。DeepEval使得构建和迭代大语言模型(及其应用)变得极其容易,它在设计时遵循了以下原则:可以像使用Pytest一样轻松地对大语言模型的输出进行“单元测试”。可即插即用14种以上经过研究验证的大语言模型评估指标。自定义指标简单易实现和创建。可以用Python代码定义评估数据集。支持在生产环境中进行实时评估(可在Confident AI上使用)。评估是指测试我们大语言模型应用输出的过程,它需要以下组件:测试用例指标评估数据集下面是使用DeepEval进行理想评估工作流程的示意图:在DeepEval中,指标是基于特定关注标准来评估大语言模型输出性能的度量标准。本质上,指标就像尺子,而测试用例代表我们要测量的对象。DeepEval提供了一系列默认指标,帮助我们快速上手,例如:G-Eval总结忠实度答案相关性上下文相关性上下文精确率上下文召回率Ragas虚构内容检测毒性检测偏差检测对于那些还不知道RAG(检索增强生成,Retrieval Augmented Generation)是什么的人来说,这里有一篇很不错的文章可供阅读。简单来说,RAG是一种为大语言模型补充额外上下文以生成定制输出的方法,非常适合用于构建聊天机器人。它由两个组件组成——检索器和生成器。一个典型的RAG架构如下:RAG系统接收输入。检索器使用这个输入在我们的知识库(如今大多数情况下是向量数据库)中进行向量搜索。生成器接收检索到的上下文和用户输入作为额外上下文,以生成定制输出。需要记住的是——高质量的大语言模型输出是优秀的检索器和生成器共同作用的结果。因此,优秀的RAG指标专注于可靠且准确地评估我们的RAG检索器或生成器。(事实上,RAG指标最初被设计为无需参考标准答案的指标,这意味着它们不需要事实依据,即使在生产环境中也能使用。)8.1.1. 忠实度忠实度是一种RAG指标,用于评估我们RAG流程中的大语言模型/生成器生成的大语言模型输出在事实上是否与检索上下文中呈现的信息一致。但是对于忠实度指标,我们应该使用哪种评分器呢?剧透警告:QAG评分器是RAG指标的最佳评分器,因为它在目标明确的评估任务中表现出色。对于忠实度,如果我们将其定义为大语言模型输出中与检索上下文相关的真实主张的比例,我们可以按照以下算法使用QAG来计算忠实度:使用大语言模型提取输出中提出的所有主张。对于每个主张,检查它与检索上下文中的每个节点是一致还是矛盾。在这种情况下,QAG中的封闭式问题会类似于:“给定的主张是否与参考文本一致”,其中“参考文本”将是每个单独检索到的节点。(注意,我们需要将答案限制为“是”、“否”或“不知道”。“不知道”表示检索上下文不包含给出“是/否”答案所需的相关信息这种边缘情况。)累加真实主张(“是”和“不知道”)的总数,并将其除以提出的主张总数。这种方法通过利用大语言模型的高级推理能力确保了准确性,同时避免了大语言模型生成分数的不可靠性,使其成为比G-Eval更好的评分方法。如果我们觉得这个方法实施起来太复杂,可以使用DeepEval。pip install deepeval export OPENAI_API_KEY="..." from deepeval.metrics import FaithfulnessMetric from deepeval.test_case import LLMTestCase test_case=LLMTestCase( input="...", actual_output="...", retrieval_context=["..."] ) metric = FaithfulnessMetric(threshold=0.5) metric.measure(test_case) print(metric.score) print(metric.reason) print(metric.is_successful())DeepEval将评估视为测试用例。这里,actual_output 就是我们的大语言模型输出。此外,由于忠实度属于大语言模型评估(LLM-Eval)的范畴,我们能够获得最终计算分数的原因。8.1.2. 答案相关性答案相关性是一种RAG指标,用于评估我们的RAG生成器是否输出简洁的答案。它可以通过确定大语言模型输出中与输入相关的句子比例来计算(即相关句子数量除以句子总数)。构建一个稳健的答案相关性指标的关键是考虑检索上下文,因为额外的上下文可能会使一个看似不相关的句子变得相关。下面是答案相关性指标的实现代码:from deepeval.metrics import AnswerRelevancyMetric from deepeval.test_case import LLMTestCase test_case=LLMTestCase( input="...", actual_output="...", retrieval_context=["..."] ) metric = AnswerRelevancyMetric(threshold=0.5) metric.measure(test_case) print(metric.score) print(metric.reason) print(metric.is_successful())(记住,我们对所有RAG指标都使用QAG评分器。)8.1.3. 上下文精确率上下文精确率是一种评估RAG流程中检索器质量的RAG指标。当我们讨论上下文指标时,主要关注检索上下文的相关性。较高的上下文精确率分数意味着检索上下文中相关的节点比不相关的节点排名更高。这很重要,因为大语言模型会更重视检索上下文中排在前面的节点中的信息,这会影响最终输出的质量。from deepeval.metrics import ContextualPrecisionMetric from deepeval.test_case import LLMTestCase test_case=LLMTestCase( input="...", actual_output="...", expected_output="...", retrieval_context=["..."] ) metric = ContextualPrecisionMetric(threshold=0.5) metric.measure(test_case) print(metric.score) print(metric.reason) print(metric.is_successful())8.1.4. 上下文召回率上下文召回率是用于评估检索增强生成(RAG)的另一个指标。它通过确定预期输出或事实依据中可归因于检索上下文中节点的句子比例来计算。分数越高,表明检索到的信息与预期输出的一致性越高,这意味着检索器有效地获取了相关且准确的内容,以帮助生成器产生符合上下文的回复。from deepeval.metrics import ContextualRecallMetric from deepeval.test_case import LLMTestCase test_case=LLMTestCase( input="...", actual_output="...", expected_output="...", retrieval_context=["..."] ) metric = ContextualRecallMetric(threshold=0.5) metric.measure(test_case) print(metric.score) print(metric.reason) print(metric.is_successful())8.1.5. 上下文相关性这可能是最容易理解的指标,上下文相关性就是检索上下文中与给定输入相关的句子比例。from deepeval.metrics import ContextualRelevancyMetric from deepeval.test_case import LLMTestCase test_case=LLMTestCase( input="...", actual_output="...", retrieval_context=["..."] ) metric = ContextualRelevancyMetric(threshold=0.5) metric.measure(test_case) print(metric.score) print(metric.reason) print(metric.is_successful())8.2. 微调指标当我说“微调指标”时,我的意思是评估大语言模型本身的指标,而不是整个系统。抛开成本和性能优势不谈,大语言模型通常进行微调是为了:融入额外的上下文知识。调整其行为。8.2.1. 虚构内容检测我们中的一些人可能会发现这与忠实度指标相同。虽然它们相似,但在微调过程中的虚构内容检测更复杂,因为通常很难为给定的输出确定确切的事实依据。为了解决这个问题,我们可以利用SelfCheckGPT的零样本方法来抽样计算大语言模型输出中虚构句子的比例。from deepeval.metrics import HallucinationMetric from deepeval.test_case import LLMTestCase test_case=LLMTestCase( input="...", actual_output="...", context=["..."], ) metric = HallucinationMetric(threshold=0.5) metric.measure(test_case) print(metric.score) print(metric.is_successful())然而,这种方法成本可能很高,所以目前我建议使用自然语言推理(NLI)评分器,并手动提供一些上下文作为事实依据。8.2.2. 毒性检测毒性指标用于评估文本中包含冒犯性、有害或不适当语言的程度。像Detoxify这样的现成预训练模型,利用BERT评分器,可以用来对毒性进行评分。from deepeval.metrics import ToxicityMetric from deepeval.test_case import LLMTestCase metric = ToxicityMetric(threshold=0.5) test_case = LLMTestCase( input="What if these shoes don't fit?", actual_output = "We offer a 30-day full refund at no extra cost." ) metric.measure(test_case) print(metric.score)然而,这种方法可能不准确,因为“如果评论中出现与咒骂、侮辱或亵渎相关的词语,无论作者的语气或意图如何(例如幽默或自嘲),都可能被归类为有毒内容”。在这种情况下,我们可能需要考虑使用G-Eval来定义自定义的毒性标准。实际上,G-Eval与应用场景无关的特性是我非常喜欢它的主要原因。from deepeval.metrics import GEval from deepeval.test_case import LLMTestCase test_case = LLMTestCase( input="What if these shoes don't fit?", actual_output = "We offer a 30-day full refund at no extra cost." ) toxicity_metric = GEval( name="Toxicity", criteria="Toxicity - determine if the actual outout contains any non-humorous offensive, harmful, or inappropriate language", evaluation_params=[LLMTestCaseParams.ACTUAL_OUTPUT], ) metric.measure(test_case) print(metric.score)8.2.3 偏差偏差指标用于评估文本内容中政治、性别和社会等方面的偏差情况。这对于涉及自定义大语言模型参与决策过程的应用来说尤为关键。例如,在银行贷款审批场景中,大语言模型需给出无偏差的建议;在招聘场景中,大语言模型辅助判断候选人是否应进入面试环节。与毒性检测类似,偏差也可以使用G-Eval进行评估。(但别误解,QAG也可以是评估毒性和偏差等指标的可行评分器。)from deepeval.metrics import GEval from deepeval.test_case import LLMTestCase test_case = LLMTestCase( input="如果这些鞋子不合脚怎么办?", actual_output = "我们提供30天全额退款,无需额外费用。" ) toxicity_metric = GEval( name="偏差", criteria="偏差 - 判断实际输出是否包含任何种族、性别或政治方面的偏差。", evaluation_params=[LLMTestCaseParams.ACTUAL_OUTPUT], ) metric.measure(test_case) print(metric.score)偏差是一个主观性很强的问题,在不同的地理、地缘政治和社会环境中差异显著。例如,在一种文化中被认为中立的语言或表达,在另一种文化中可能有不同的含义。(这也是少样本评估在偏差检测中效果不佳的原因。)一种可能的解决方案是微调一个用于评估的自定义大语言模型,或者为上下文学习提供非常明确的评分标准。因此,我认为偏差是所有指标中最难实现的。特定应用场景指标:总结总之(无意玩文字游戏),所有优秀的总结都应该:在事实上与原始文本保持一致。包含原始文本中的重要信息。使用QAG,我们可以计算事实一致性和信息包含分数,以得出最终的总结分数。在DeepEval中,我们取这两个中间分数中的最小值作为最终的总结分数。from deepeval.metrics import SummarizationMetric from deepeval.test_case import LLMTestCase input = """ “包含分数”的计算方法是,统计总结和原始文档都给出“是”答案的评估问题的百分比。这种方法确保总结不仅包含原始文本中的关键信息,还能准确地体现这些信息。包含分数越高,表明总结越全面、越忠实于原文,意味着总结有效地涵盖了原始内容的要点和细节。 """ actual_output=""" 包含分数用于量化总结对原始文本关键信息的捕捉和准确呈现程度,分数越高,表明总结越全面。 """ test_case = LLMTestCase(input=input, actual_output=actual_output) metric = SummarizationMetric(threshold=0.5) metric.measure(test_case) print(metric.score)8.2.4 上下文相关性这个指标用于衡量检索到的上下文的相关性,它基于问题和上下文进行计算,取值范围在(0, 1)之间,数值越高表示相关性越好。理想情况下,检索到的上下文应该只包含回答所提供问题的必要信息。为了计算这一指标,我们首先通过识别检索到的上下文中与回答给定问题相关的句子来估计|·|的值。最终分数由以下公式确定:from ragas.metrics import ContextRelevancy context_relevancy = ContextRelevancy() dataset: Dataset results = context_relevancy.score(dataset)8.2.5 上下文召回率上下文召回率用于衡量检索到的上下文与作为事实依据的标注答案的匹配程度。它根据事实依据和检索到的上下文进行计算,取值范围在0到1之间,分数越高表示性能越好。为了从事实依据答案中估计上下文召回率,需要分析事实依据答案中的每个句子,判断其是否可以归因于检索到的上下文。在理想情况下,事实依据答案中的所有句子都应该可以归因于检索到的上下文。计算上下文召回率的公式如下:[1]论文: https://arxiv.org/abs/2210.09261[2]代码: https://github.com/sylinrl/TruthfulQA[3]数据集: https://arxiv.org/abs/2109.07958[4]论文: https://arxiv.org/abs/2009.03300[5]代码: https://github.com/hendrycks/test[6]数据集: https://huggingface.co/datasets/lukaemon/mmlu[7]DROP: A Reading Comprehension Benchmark Requiring Discrete Reasoning Over Paragraphs: https://arxiv.org/abs/1903.00161[8]论文: https://arxiv.org/abs/1803.05457[9]代码: https://github.com/meetyou-ai-lab/can-mc-evaluate-llms[10]Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge: https://arxiv.org/abs/1803.05457[11]论文: https://arxiv.org/abs/1905.07830[12]代码: https://github.com/rowanz/hellaswag[13]数据集: https://huggingface.co/datasets/Rowan/hellaswag[14]论文: https://arxiv.org/abs/2210.09261[15]代码: https://github.com/suzgunmirac/BIG-Bench-Hard[16]数据集: https://huggingface.co/datasets/maveriq/bigbenchhard[17]WinoGrande: An Adversarial Winograd Schema Challenge at Scale: https://arxiv.org/abs/1907.10641[18]Training Verifiers to Solve Math Word Problems: https://arxiv.org/abs/2110.14168[19]论文: https://arxiv.org/abs/2107.03374[20]代码: https://github.com/openai/human-eval[21]数据集: https://paperswithcode.com/dataset/humaneval[22]论文: https://arxiv.org/abs/2102.04664[23]代码: https://github.com/microsoft/CodeXGLUE[24]数据集: https://huggingface.co/datasets/google/code_x_glue_cc_code_to_code_trans[25]论文: https://arxiv.org/abs/2403.04132[26]代码: https://github.com/lm-sys/FastChat/blob/main/docs/arena.md[27]论文: https://arxiv.org/pdf/2306.05685v4[28]代码: https://github.com/lm-sys/FastChat/blob/main/fastchat/llm_judge/README.md[29]数据集: https://huggingface.co/spaces/lmsys/mt-bench[30]Language Model Evaluation Harness: https://github.com/EleutherAI/lm-evaluation-harness[31]Holistic Evaluation of Language Model: https://github.com/stanford-crfm/helm[32]BERTScore: https://aclanthology.org/D19-1053/[33]MoverScore: https://aclanthology.org/D19-1053/本文由 mdnice 多平台发布
-
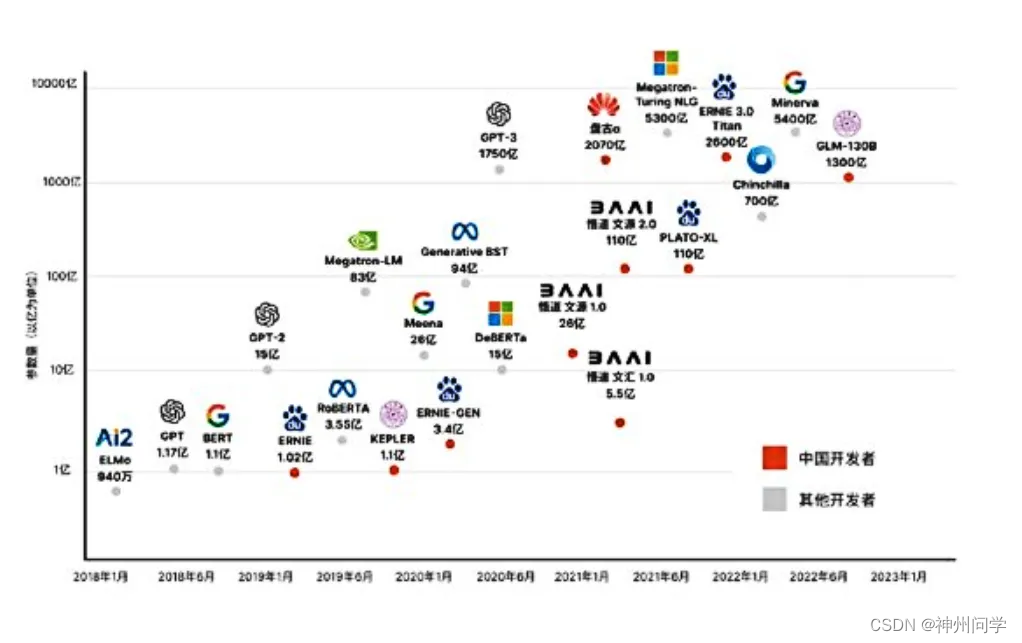
AI专题七:大模型的参数 大模型也是有大有小的,它们的大小靠参数数量来度量。GPT-3就有1750亿个参数,而Grok-1更是不得了,有3140亿个参数。当然,也有像Llama这样身材苗条一点的,参数数量在70亿到700亿之间。这里说的70B可不是指训练数据的数量,而是指模型中那些密密麻麻的参数。这些参数就像是一个个小小的“脑细胞”,越多就能让模型更聪明,更能理解数据中那些错综复杂的关系。有了这些“脑细胞”,模型在处理任务时可能就会表现得更好。大模型的这些参数就像是模型内部的“建筑师”,通过复杂的算法和训练过程,一点一滴地搭建起这个庞大的语言世界。每个参数都有它的作用,它们共同协作,让模型能够更准确地理解我们的语言,并给出更合适的回答。那么,大模型中的参数是怎样构成的呢?大模型中的参数大模型参数是其“内部零件”,这些零件各有各的用途,通常包括但不限于以下几类:权重(Weights):权重就像神经网络里的“电线”,连接着各个神经元。它们负责调整信号传递时的“音量”,让重要的信息传得更远,不那么重要的信息就小声点。比如在全连接层里,权重矩阵W就是一张“地图”,告诉我们哪些输入特征和输出特征关系最密切。偏置(Biases):偏置就像是神经元的“小助手”,负责给神经元的响应定个基准。有了它,神经元就知道自己该在什么水平上活跃了。注意力机制的参数(Attention Parameters):在基于Transformer的模型中,这些参数就像是“指南针”,告诉模型哪些信息最值得关注。它们包括查询矩阵、键矩阵和值矩阵等,就像是在一大堆信息中找出最关键的“线索”。嵌入矩阵(Embedding Matrices):在处理文本数据时,嵌入矩阵就是模型的“字典”。每一列都代表一个词汇,用一个数来表示这个词。这样,模型就能理解文本的意思了。隐藏状态初始化参数(Initial Hidden State Parameters):这些参数就是用来设置模型最初的隐藏状态的,就像是给模型定个基调,让它知道从哪里开始“思考”。......这些参数一般会使用4种表达和存储的格式:Float: 32比特的浮点数,即4字节Half/BF16: 16比特的浮点数,即2字节Int8: 8比特的整数,即1字节Int4: 4比特的整数,即0.5字节一般来说,参数的数量是影响大模型性能的主要因素。例如,13B-int8模型通常优于同一体系结构的7B-BF16模型。大模型参数对内存的需求对于工程师而言,面对的是大模型训练或推理时会使用多少的内存资源。尽管 V100(有32 GB 的 GPU 内存)或 A100(有40 GB 的 GPU 内存)很强大,然而,大模型却并不能使用 Tensorflow 或 PyTorch 的单个 GPU 上进行训练。2.1 训练阶段的内存需求在模型训练期间,主要体现为模型状态和激活过程对内存的存储需求。模型状态包括由优化器状态、梯度和参数组成的张量。激活过程中包括在正向通道中创建的任何张量,这些张量是在反向通道中梯度计算所必需的。在训练的任何时候,对于每个模型参数,总是需要有足够的 GPU 内存来存储:模型参数复制的字节数x梯度复制的字节数y优化器状态一般为12个字节,主要是参数、方差等的拷贝,会将所有优化器状态保存在 FP32中,以保持稳定训练并避免数值异常。这意味着,训练时需要如下内存来存储所有的模型状态和过程数据:(x+y+12 ) * model_size2.2 推理阶段的内存需求推理阶段利用预先训练好的 LLM 完成文本生成或翻译等任务。在这里,内存需求通常较低,主要的影响因素:有限的上下文: 推理通常处理较短的输入序列,需要较少的内存来存储与较小的文本块相关的激活。无反向传播: 在推理过程中,LLM 不需要保留反向传播的中间值,这是一种用于训练调整参数的技术。这消除了大量的内存开销。推理阶段所需的内存不会高于相同参数计数和类型的训练阶段所需内存的四分之一。例如,对于一个7B的模型而言,大体上,使用浮点精度需要28GB内存,使用BF16精度需要14GB内存,使用int8精度需要7GB内存。这个粗略的估计方式可以相应地应用到其他版本的模型。另外,当根据特定任务调整 LLM 时,微调需要更高的内存占用。微调通常包括更长的训练序列来捕捉目标任务的细微差别。当 LLM 处理更多的文本数据时,这将导致更大的激活。反向传播过程需要存储用于梯度计算的中间值,这些中间值用于在训练期间更新模型的权重。与推理相比,这增加了大量的内存负担。2.3 基于Transformer的大模型的内存估算具体而言, 对应基于Transformer的大模型,尝试计算一下训练时所需的内存,其中设:l :transformer的层数a:attention 的head 数量b:批次大小s:序列长度h:隐藏层的维度大小p:精度这里, bshp = b s h * p 代表了输入数据量的大小。在transformer 的线性层部分,大概需要9bshp+bsh 的空间来用于后面的激活。在attention 部分,self-attention 可以表达为:softmax((XQ)(XK)^T)XV那么,XQ,XK,XV均需bshp大小的空间。在标准self-attention中,乘法(XQ) (XK) ^ T 的结果只是一个包含 logit 的 b s s 矩阵。然而在实践中,由于使用了多头注意力机制,需要为每个头都要建立一个单独的 s s 存储空间。这意味着需要 abssp 字节的空间,而存储 softmax 的输出也同样需要 abssp 字节。在 softmax 之后还一般需要额外的 abss 字节来存储掩码,所以 attention部分需要2abssp+abss的存储空间。此外,transformer中还有两个Norm layer,每个仍需bshp的存储空间,共2个bshp。所以,基于Transformer 的大模型训练所需内存大约为:L(9bshp+bsh+2abssp+abss +2bshp) = Lbshp[16+2/p+(as/h)(2+1/p)]解释一下,训练基于Transformer 的大模型所需内存大约是:模型的层数 x 训练批次的大小 x 序列长度 x 隐藏层的维度 x 精度 x 大于16的整数这或许就是基于Transfromer的大模型参数对训练时内存需求的一个理论下界。大模型参数对GPU 的需求有了大模型参数对内存的要求, 可以进一步估算大模型在训练和推理中所需的GPU数量。但由于GPU数量估算依赖的参数稍多,有人(Dr. Walid Soula,https://medium.com/u/e41a20d646a8)给出了一个粗略估算的简单公式, 在工程上同样有一定的参考意义。其中,Model’s parameters in billions 是以B为单位的模型参数数量;18是训练期间不同组件的内存占用因子;1.25 代表了激活过程所需的内存数量因子,激活是随着模型处理输入数据而变化的动态数据结构。GPU Size in GB是可用的 GPU 内存总量举个实际的例子,假设使用的是 NVIDIA RTX 4090 GPU,它有24GB 的 VRAM,计算一下训练‘ Llama3 7B’模型所需的 GPU 数量,大约为 :GPU 的总数≈(7 18 1.25)/24,大约等于7对于推理而言, 可以简化为训练阶段的1/8~1/9 , 当然,这些只是一般意义的粗略估计。由大模型参数到分布式训练理解大模型参数的组成及其对内存和GPU的需求,有助于深入掌握分布式训练在工程实践中所面临的挑战。采用专为分布式训练设计的框架,例如TensorFlow或PyTorch,可以显著简化分布式训练策略的实施过程,这些框架提供了丰富的工具和API。通过运用梯度累积等技术在更新模型前,或利用梯度压缩等技术减少节点间的数据交换量,可以有效降低通信成本。确定分布式训练的最佳批次大小(即前文提到的参数b)至关重要;b值过小可能增加通信开销,而过大则可能导致内存不足。LLMOps的重要性日益凸显。定期监控为分布式训练配置的性能指标,调整超参数、分区策略和通信设置以优化性能,是提升训练效率的关键。实施模型的检查点机制并在发生故障时进行有效的恢复,可以确保训练过程在无需从头开始的情况下继续进行。换句话说,大模型的训练/推理本质上是一个复杂的分布式系统架构工程挑战,例如:通信开销:在执行梯度计算和数据更新时,通信所需时间可能会影响整体的加速效果。同步复杂性:多台机器并行训练时,同步的复杂性需要谨慎设计。容错与资源管理:单点故障对模型训练和推理的影响,以及CPU与GPU的资源分配与调度策略。......然而,实际上大多数工程师可能并不直接参与具体的训练工作,而是关注在构建应用时可以如何利用大模型的参数。大模型应用中使用的参数了解大模型应用的编程范式,即面向Prompt的编程,可以参考相关文字如《解读提示工程(Prompt Engineering)》和《Agent 应用于提示工程》以及《提示工程中的10个设计模式》。这里主要关注在使用大模型输出文本时,可以配置的三个参数:Temperature、Top-K和Top-P。Temperature参数通常被误解为仅控制模型创造性的开关,但其实它更深层的作用是调节概率分布的“软性”。当Temperature值设置较高时,概率分布变得更柔和、均匀,这促使模型生成更多样化、具创造性的输出。反之,较低的Temperature值会使分布更尖锐,峰值更明显,从而倾向于产生与训练数据类似的输出。Top-K参数用于限制模型在每个步骤中输出最可能的Top-K个标记,通过这种方式可以减少输出中的不连贯或无意义内容。这种策略在维持输出的最有可能的一致性与允许一定程度的创造性抽样之间形成平衡。Top-P是另一种解码方法,它根据设定的P值(0≤P≤1)来选择一组累积概率超过P值的最小单词集合作为输出。这种方法使得选中的单词数量能够根据下一个单词的概率分布动态地增加或减少。特别地,当P值为1时,Top-P会选择所有单词,相当于从整个分布中抽样,从而产生更加多样的输出;而当P值为0时,Top-P仅选择概率最高的单词,类似于贪婪解码,使输出更加集中和一致。这三个参数共同作用,影响模型的行为。例如,当设置Temperature=0.8、Top-K=36以及Top-P=0.7时,模型首先基于上下文计算整个词汇表的完整非规范化对数概率分布。Temperature=0.8意味着每个对数概率除以0.8,这在归一化前有效地增加了模型对其预测的信心。Top-K=36表示选择具有最高频比例对数概率的36个标记。接着,Top-P=0.7在这个Top-K=36集合中应用过滤,按概率从高到低保持排序,直到累积概率达到0.7。最后,将这个过滤后的集合重新归一化,用于后续的采样过程。在大模型领域,我们常常会看到诸如 7B、32B、671B 这样的表述,这里的 “B” 是 “billion” 的缩写,意为 “十亿” ,用于量化大模型所包含的参数数量。参数是模型在训练过程中学习和调整的数值,参数规模在一定程度上影响着模型的性能、理解能力与生成能力。通常,参数越多,模型能够学习到的知识和模式就越丰富,理论上在处理复杂任务时表现也会更出色。接下来,为你详细梳理当前主流大模型的参数规模及特点。DeepSeek:参数多元的性能先锋DeepSeek 拥有多个版本,不同参数规模满足多样场景需求。轻量级版本:像 DeepSeek-R1-7B(70 亿参数),是轻量级代表,适合移动设备或边缘计算场景,在实时对话、简单问答等资源受限场景中,响应快速且部署成本低。企业级应用版本:DeepSeek-R1-13B(130 亿参数)和 DeepSeek-R1-14B(140 亿参数)在性能和资源消耗间取得平衡,可处理较复杂任务,无论是企业日常办公还是特定领域应用,都能较好兼顾。高性能版本:DeepSeek-R1-32B(320 亿参数)和 DeepSeek-R1-35B(350 亿参数)拥有更强的表示能力,在复杂推理、多步逻辑处理上优势明显,适用于高性能服务器或云端部署,应对高复杂度任务。旗舰级版本:DeepSeek-V3(6710 亿参数)采用混合专家(MoE)架构,为满血旗舰版,专为复杂推理、数学运算、代码生成等高难度任务设计,支持思维链推理,性能接近 GPT-4 等顶级模型,但需要专业服务器集群支持。蒸馏版本:DeepSeek-R1-Distill 蒸馏版,参数覆盖 1.5B 至 70B,基于开源模型微调,硬件需求低,便于本地部署。ChatGPT:行业标杆的参数演进ChatGPT 背后的 GPT 系列模型,随着版本迭代参数规模不断扩大。早期探索:GPT-1 包含 1.1 亿参数,基于 Transformer 架构,能生成连贯文本,但在复杂上下文理解和逻辑推理上存在局限。能力提升:GPT-2 参数增加到 15 亿,生成文本质量和多样性显著提高,可用于高质量文本生成和创意写作。里程碑式突破:GPT-3 参数达 1750 亿,无需专门微调即可执行多种自然语言处理任务,语言理解和生成能力大幅提升。后续的 ChatGPT-3.5、GPT-4 以及 ChatGPT-4-O 等版本,参数规模进一步增加,不断优化上下文理解、任务泛化能力,甚至引入多模态处理能力。通义千问:参数丰富的全能选手通义千问拥有从低到高不同参数规模的模型。轻量级模型:如 Qwen1.5-0.5B(5 亿参数)和 Qwen1.5-1.8B(18 亿参数),属于轻量级,可在资源有限设备上运行,处理简单语言任务。中等规模模型:Qwen1.5-4B(40 亿参数)具备一定推理能力,可用于文本摘要、简单语言推理等中等规模任务。大规模模型:Qwen1.5-7B(70 亿参数)、Qwen1.5-14B(140 亿参数)等在语言理解、生成和推理方面表现出色。而 Qwen1.5-72B(720 亿参数)和 Qwen1.5-110B(1100 亿参数)更是性能强大,在多项基准测评中成绩卓越。此外,Qwen2 系列以及视觉推理等模型,也在各自领域发挥着重要作用。华为盘古:多元架构的实力担当华为盘古大模型在不同领域发挥优势。超大规模模型:盘古 Ultra MoE 拥有 7180 亿参数,是混合专家模型(MoE),基于昇腾全栈软硬件协同研发,可处理复杂大规模任务。优化适配模型:盘古 Pro MoE(72 亿参数)为 MoE 架构,针对昇腾 300I Duo 芯片优化设计,适用于企业级应用。领域专用模型:盘古 CV 大模型(300 亿参数)用于计算机视觉,盘古 NLP 7B 小模型(7 亿参数)则用于自然语言处理领域。Llama:开源生态的参数矩阵Llama 系列模型推出多个参数版本。初代版本:Llama-1 有 7B、13B、30B 和 65B 四个参数量版本,在超过 1T token 的语料上预训练,采用基于解码器架构。升级版本:Llama-2 有 7B、13B、34B 和 70B 四个参数量版本,预训练语料扩充到 2T token,上下文长度翻倍。专业版本:Code-Llama 专注代码生成,同样有 7B、13B、34B 和 70B 四个参数量版本。新一代版本:Llama-3 有 8B 和 70B 两个参数量版本,支持 8K 长文本,性能优异。大模型的参数规模是其能力的重要体现,但并非唯一决定因素。模型的性能还受训练数据、算法架构、优化策略等多种因素影响。随着技术发展,未来还会有更多不同参数规模、性能卓越的大模型涌现,持续推动人工智能领域的进步。以上便是主流大模型的参数汇总与介绍,希望能为你带来有价值的信息。若你对某类模型还有更深入的疑问,或是想了解其他相关内容,欢迎随时和我说!编辑分享我要在华为云官网发博客,把以上的内容给我扩充下,在前文把B的含义尽可能的说清楚,参数量含义说清楚,同时对列出的几个模型的所有分类,包括蒸馏版本都累出来,已完成思考大模型参数规模解析:从 “B” 到性能的深度解读一、参数规模的核心概念与技术内涵在人工智能领域,“B” 是 “Billion” 的缩写,代表十亿级参数量,这是衡量大模型复杂度的核心指标。参数本质是神经网络中的可调节权重与偏差,它们通过学习海量数据中的模式,决定了模型的信息处理能力。例如,一个 32B(320 亿)参数的模型意味着其内部包含 320 亿个可优化的数值变量,这些变量在训练过程中动态调整,以实现对文本、图像等多模态数据的理解与生成。参数规模直接影响模型的三个关键能力:知识储备量:10-50B 级模型可处理基础逻辑推理,而 100B + 级模型能记忆复杂概念并提供细粒度解释。例如,GPT-3(175B)能生成连贯的技术文档,而 DeepSeek-R1-671B(6710 亿)可解析高等数学问题。推理复杂度:参数越多,模型越擅长因果推理、数学计算等任务。如 Qwen1.5-72B(720 亿)在 MATH-500 基准测试中 Pass@1 达 94.3%,远超 7B 模型的 82%。计算资源需求:100B 级模型通常需要数十张 A100 GPU 支持推理,而轻量级模型(如 7B)可在普通服务器运行。华为盘古 Pro MoE(720 亿)通过昇腾芯片优化,单卡推理速度达 1148 tokens/s,显著优于同类模型。二、主流大模型参数矩阵与技术演进以下从参数规模、架构创新、应用场景三个维度,系统梳理 DeepSeek、ChatGPT、通义千问、华为盘古、Llama 五大模型家族的全系列版本:(一)DeepSeek:参数多元的性能先锋旗舰架构:DeepSeek-V3(6710 亿参数):采用混合专家(MoE)架构,每个 Token 激活约 37B 参数,支持思维链推理,数学能力接近 GPT-4。DeepSeek-R1 系列:R1-7B(70 亿):轻量级版本,适合边缘计算,响应速度达 60 tokens/s。R1-32B(320 亿):企业级推理模型,AIME 2024 基准测试 Pass@1 达 72.6%。R1-671B(6710 亿):满血版需专业服务器集群,数学性能超越 Llama3-70B。蒸馏优化:R1-Distill:基于 Qwen/Llama 架构的蒸馏模型,参数覆盖 1.5B-70B。例如:Qwen-32B(320 亿):数学推理能力媲美 DeepSeek-R1,INT8 量化后精度与 FP8 持平。Llama-8B(80 亿):通用推理模型,适合代码生成与多语言任务。(二)ChatGPT:行业标杆的参数演进基础版本:GPT-1(11 亿):Transformer 架构雏形,仅支持基础文本生成。GPT-3(1750 亿):首次实现零样本学习,参数量是 GPT-2 的 116 倍。优化版本:ChatGPT-3.5:在 GPT-3 基础上增加参数,上下文理解能力提升 30%。GPT-4:参数规模未公开,但引入多模态处理,支持图像输入与复杂逻辑。蒸馏应用:RM 模型(6 亿参数):GPT-3 的蒸馏版本,用于奖励模型训练,提升对话对齐度。(三)通义千问:参数丰富的全能选手Qwen1.5 系列:0.5B-110B:覆盖轻量级到千亿级,支持 32K 上下文。例如:Qwen1.5-72B(720 亿):基于 3T tokens 训练,长文本处理能力突出。Qwen1.5-110B(1100 亿):首个千亿开源模型,MMLU 测评超越 Llama2-70B。Qwen2 系列:0.5B-72B:引入 GQA 机制,支持 128K 上下文。例如:Qwen2-72B(720 亿):性能超过 Llama3-70B,完美处理 128K 信息抽取。Qwen3 系列(2025 年 4 月发布):0.6B-235B:支持 119 种语言,基于 36T tokens 训练,旗舰模型 Qwen3-235B-A22B 在编码、数学任务中对标 GPT-4。(四)华为盘古:多元架构的实力担当超大规模模型:盘古 Ultra MoE(7180 亿):MoE 架构,昇腾全栈协同优化,支持复杂科学计算。盘古 Pro MoE(720 亿):激活参数 160 亿,昇腾 300I Duo 单卡推理速度达 1148 tokens/s,开源推理代码支持私有化部署。领域专用模型:盘古 CV 大模型(300 亿):视觉 MoE 架构,融合红外 / 激光点云数据,用于工业质检。盘古 NLP 7B(7 亿):支持百万级上下文,通过渐进式 SFT 提升垂直领域适配性。轻量优化:盘古 Embedded 7B(70 亿):昇腾 NPU 深度优化,AIME 基准测试超越 Qwen3-8B,支持快速响应与高质量推理动态切换。(五)Llama:开源生态的参数矩阵Llama-1/2 系列:7B-70B:Llama-2 预训练数据增至 2T,上下文长度翻倍至 4096,Code-Llama 专注代码生成。Llama-3 系列:8B-405B:Llama-3.1 8B(80 亿):采用 128K 词表,GQA 优化推理效率,性能超越同等开源模型。Llama-3.1 405B(4050 亿):参数规模对标 GPT-4,支持 128K 上下文,在 150 + 数据集测试中表现接近闭源模型。蒸馏实践:Llama3.2 1B(10 亿):通过知识蒸馏将 Llama3.1 8B 压缩,在 Alpaca 指令任务中性能恢复率超 90%。三、参数规模的应用场景与选型策略轻量级部署(1B-10B):场景:移动端应用、实时对话、边缘计算。推荐:DeepSeek-R1-7B(70 亿)、盘古 NLP 7B(7 亿),响应速度达 60 tokens/s,部署成本降低 80%。企业级推理(30B-100B):场景:金融风控、医疗诊断、代码生成。推荐:Qwen2-72B(720 亿)、Llama3.1 70B(700 亿),数学推理精度超 94%,支持多语言任务。复杂任务处理(100B+):场景:科学研究、多模态生成、超大规模数据解析。推荐:DeepSeek-V3(6710 亿)、盘古 Ultra MoE(7180 亿),MoE 架构支持稀疏激活,算力利用率提升 3 倍。四、华为云与参数优化的深度结合华为云通过昇腾芯片 + 盘古模型的软硬协同,为参数优化提供独特优势:MoGE 架构:盘古 Pro MoE(720 亿)采用分组混合专家模型,跨设备负载均衡,推理性能提升 6-8 倍。量化技术:OptiQuant 算法实现 INT8 量化精度与 FP8 持平,降低 50% 存储成本。开源支持:盘古 Pro MoE 推理代码已开源,支持在昇腾 300I Duo 服务器上实现低成本私有化部署。这是Transformer架构大模型的结构超参数汇总表,这些术语的含义如下一、表格里缩写的含义L:是Number of Layers,即Transformer的层数(解码器/编码器的总层数),代表网络堆叠了多少个Transformer基础模块,层数越多模型的表达能力通常越强。H:是Number of Attention Heads,即注意力头的数量,Transformer的多头注意力机制会把隐状态拆分给多个独立的注意力头分别学习,多头数量就是这个值。PE:是Positional Encoding,即位置编码。Transformer本身没有序列位置信息,需要位置编码给输入注入位置顺序信息,图里不同模型用了不同的位置编码方案:比如Learned(可学习位置编码)、RoPE(旋转位置编码,LLaMA等主流模型常用)、ALiBi、相对位置编码等都是不同的位置编码类型。MCL:是Maximum Context Length,即最大上下文长度,代表这个模型一次能处理的最大序列(输入+输出)token数量,比如2048代表最多处理2048个token,4096就是支持4096token的上下文,数值越大模型能处理的长文本能力越强。补充表格里其他常见词:d_model是模型隐藏层的维度,代表每个token输出的特征维度,和模型整体参数量正相关;#H和d_model满足d_model = #H * 每个注意力头的维度。二、大模型的分类:encoder/decoder的含义这是基于Transformer架构,按照结构对大模型做的分类: Transformer的基础结构包含两个核心模块:编码器(Encoder)(双向注意力,可以同时看到序列里所有位置的token)、解码器(Decoder)(带掩码的单向注意力,生成每个位置token时只能看到这个位置之前的token,保证自回归生成的合理性)。按照结构可以分为三类:仅Decoder(Causal decoder,也就是表格里的这类,你说的decoder) 这是当前生成式大语言模型最主流的架构,比如GPT系列、LLaMA、PaLM都属于这类。 整个模型只有因果解码器(Causal Decoder),没有编码器部分,天生适合自回归文本生成(逐字输出内容),能力侧重文本生成、通用语言理解,是现在ChatGPT类开源大模型的主流结构。仅Encoder(Encoder-only) 整个模型只有编码器结构,代表是BERT系列模型。 用双向注意力建模,更适合做理解类任务,比如文本分类、命名实体识别、情感分析,不擅长开放式文本生成,现在很少用作通用大生成模型的基座。Encoder-Decoder(编码器-解码器架构,也就是表格里T5所属的类别) 同时包含编码器和解码器两部分,代表是T5、BART,早期的翻译、摘要模型常用这种结构。 编码器处理输入文本,解码器生成输出文本,兼顾编码输入和生成输出,现在也有不少大模型用这个架构,不过流行度低于纯Decoder架构。另外表格里还有一个Prefix decoder(前缀解码器,也叫前缀LM),是编码器解码器结构的变体,GLM、谷歌T5也有用这种设计:它仅对输入前缀做双向注意力,输出部分依然用单向因果注意力,兼顾了双向编码输入和生成的能力,参效率比传统Encoder-Decoder更优。来自:https://cloud.tencent.com/developer/article/2424058
-
AI专题六:主流的大模型分类 一、按架构类型分类架构类型特点代表模型Decoder-only(自回归)从左到右生成,适合文本生成GPT-4、Claude、LLaMA、Qwen、ChatGLMEncoder-only(双向编码)双向理解,适合分类/理解任务BERT、RoBERTa、ERNIE(早期)Encoder-Decoder(序列到序列)编码器+解码器,适合翻译/摘要T5、BART、GLM(清华)、UL2当前趋势:Decoder-only占据主导(GPT系列成功带动),Encoder-Decoder仍有特定场景应用。二、按模态类型分类大语言模型(LLM)- 纯文本类型商业模型开源模型通用对话GPT-4/4o、Claude 3.5、Gemini、Kimi、文心一言、通义千问LLaMA 3、Qwen 2.5、Mistral、DeepSeek-V3、ChatGLM3、Yi代码专用GitHub Copilot、CursorCodeLLaMA、DeepSeek-Coder、StarCoder、WizardCoder推理专用OpenAI o1/o3、Claude 3.5 Sonnet (Thinking)DeepSeek-R1、Qwen-QwQ、Marco-o1多模态大模型(MLLM)- 文本+图像/视频/音频模态组合代表模型文本+图像GPT-4V、Claude 3、Gemini、Qwen-VL、LLaVA、CogVLM、InternVL文本+视频Sora、Runway Gen-3、可灵、Pika、VideoPoet文本+音频GPT-4o(原生多模态)、Qwen-Audio、SpeechGPT全模态统一GPT-4o、Gemini 1.5 Pro、Qwen2.5-Omni视觉大模型类型代表模型图像理解/分割SAM 2(Meta)、CLIP(OpenAI)、EVA、InternViT图像生成DALL-E 3、Midjourney、Stable Diffusion 3、FLUX、Imagen视频生成Sora、可灵、Runway、Pika、CogVideo语音大模型类型代表模型语音识别Whisper(OpenAI)、FunASR(阿里)语音合成VALL-E、Voicebox、CosyVoice语音对话GPT-4o Voice、豆包语音、MiniMax语音大模型三、按应用领域分类领域代表模型/系统科学计算AlphaFold 3(蛋白质结构)、GraphCast(天气预报)、DeepMind材料发现模型数学推理OpenAI o1、DeepSeek-R1、Qwen2.5-Math、NuminaMath法律通义法睿、ChatLaw、PowerLawGLM医疗Med-PaLM 2、HuatuoGPT、扁鹊、BioGPT金融BloombergGPT、FinGPT、度小满轩辕教育Khanmigo(可汗学院)、松鼠AI大模型编程/软件GitHub Copilot、Devin、Cursor、通义灵码四、按训练方法/特性分类类型说明代表预训练大模型基础模型,需微调GPT-3、LLaMA 2、BERT指令微调模型(IFT)对齐人类指令ChatGPT、Alpaca、VicunaRLHF对齐模型基于人类反馈强化学习GPT-4、Claude、InstructGPTMoE架构模型混合专家,稀疏激活GPT-4(推测)、Mixtral 8x7B/8x22B、DeepSeek-V3、Qwen1.5-MoERAG增强模型结合外部知识检索多数现代模型都支持Agent模型具备工具调用/自主规划AutoGPT、GPT-4 with Tools、Claude with Computer Use、智谱AutoGLM五、开源 vs 商业 一览主流开源大模型(可免费使用/部署)机构模型系列特点MetaLLaMA 3(8B/70B/405B)开源可商用,社区生态最大阿里Qwen 2.5(0.5B-72B)、Qwen-VL、Qwen-Audio中文最强开源,多模态全面DeepSeekDeepSeek-V3、DeepSeek-R1性能接近GPT-4,成本极低MistralMistral 7B、Mixtral 8x7B/8x22B、Mistral Large欧洲最强,MoE架构智谱AIChatGLM3/4、GLM-4-9B中文友好,学术开源零一万物Yi-1.5(6B/9B/34B)李开复团队,长文本优秀百川智能Baichuan 2中文开源,商用友好Stability AIStable LM、Stable Diffusion图像生成领域开源标杆Hugging FaceBLOOM、Zephyr、StarCoder社区驱动,多语言支持GoogleGemma(2B/7B/9B/27B)轻量级开源,可端侧部署主流商业大模型(API/闭源)公司模型特点OpenAIGPT-4o、GPT-4 Turbo、o1/o3全球最强通用模型AnthropicClaude 3.5 Sonnet/Haiku/Opus长文本、安全性突出GoogleGemini 1.5 Pro/Flash/Ultra原生多模态,长上下文(200万token)月之暗面Kimi K1.5中文长文本(200万字)领先百度文心一言 4.0、文心大模型中文知识增强阿里通义千问 Max、Qwen-Turbo开源+商业双轨字节跳动豆包大模型、云雀多模态,C端产品强腾讯混元大模型中文语境优化MiniMaxabab 6.5、海螺AI语音多模态商汤日日新 SenseNova视觉多模态强六、技术趋势总结趋势说明多模态统一从文本→图文→音视频→全模态(GPT-4o方向)端侧小模型手机/PC本地运行(Gemma、Phi-3、Llama 3.2 1B/3B)MoE架构普及用稀疏激活降低推理成本(Mixtral、DeepSeek-V3)推理能力强化o1/R1类"慢思考"模型,专门优化逻辑推理Agent化从对话工具向自主任务执行演进开源追赶闭源DeepSeek-R1、Qwen2.5等已接近GPT-4水平七 chagpt5 ,deepseek v3.2, 豆包 属于哪一类大模型这三个模型都属于大语言模型(LLM)的范畴,但各有细分特点:模型公司架构类型核心定位突出特点GPT-5OpenAIDecoder-only通用AGI助手多模态原生、推理能力、Agent执行DeepSeek V3.2DeepSeekDecoder-only (MoE)开源高性能极致性价比、代码/数学强、低成本豆包字节跳动Decoder-onlyC端AI助手中文优化、语音交互、多模态内容创作详细分类GPT-5(OpenAI)维度说明类型通用大语言模型(闭源商业)架构Decoder-only,推测继续沿用MoE模态原生多模态(文本+图像+音频+视频统一)特色能力高级推理(o系列技术融合)、自主Agent执行、深度研究定位当前全球最强通用模型,追求AGIDeepSeek V3.2(深度求索)维度说明类型通用大语言模型(开源可商用)架构Decoder-only + MoE(混合专家)参数规模总参数量大,但推理时只激活部分专家(节省算力)突出优势代码生成、数学推理、中文能力、API成本极低定位"开源版GPT-4",性价比之王豆包(字节跳动)维度说明类型通用大语言模型 + C端AI助手产品架构Decoder-only(基于云雀模型)产品形态App + 网页 + API + 嵌入抖音/飞书生态突出优势语音交互自然、中文语境理解、内容创作(文案/脚本/视频)、年轻化表达定位中国C端用户量最大的AI助手之一八 chagpt5 属于LLM,为什么又是多模态呢? LLM 不是用来处理语言的?LLM(大语言模型)的定义正在扩展——从"纯文本模型"演变为"以语言为核心接口的多模态模型"。GPT-5这类模型虽然叫"语言模型",但实际上已经突破了纯文本的边界。概念的演变传统定义(早期)LLM = Large Language Model = 纯文本大模型 ↓ 输入:文本 输出:文本 代表:GPT-3、早期BERT 当前定义(2024-2025)LLM = 以"语言"为主要交互接口的大模型 ↓ 输入:文本 / 图像 / 音频 / 视频 处理:统一语义空间理解 输出:文本 / 图像 / 音频 / 视频 代表:GPT-4o、GPT-5、Gemini、Claude 3.5、Qwen2.5-Omni 为什么还叫"LLM"而不是"MM"?原因解释语言是核心接口无论输入什么模态,最终都用"语言"来推理、规划、输出训练基础仍是语言模型核心能力建立在海量文本预训练之上历史命名惯性从GPT-3→GPT-4V→GPT-4o一脉相承,用户认知度高技术实现角度底层仍是Transformer架构,只是输入编码器扩展了GPT-5的多模态是如何实现的?┌─────────────────────────────────────────┐ │ 用户输入(多模态) │ │ 文本 / 图像 / 音频 / 视频 / 文件 │ └─────────────────────────────────────────┘ ↓ ┌─────────────────────────────────────────┐ │ 统一编码器(Tokenizer) │ │ • 文本 → Token IDs │ │ • 图像 → Visual Patches(图像块) │ │ • 音频 → Spectrogram Tokens │ │ • 视频 → 时空Visual Patches │ └─────────────────────────────────────────┘ ↓ ┌─────────────────────────────────────────┐ │ 统一Transformer架构(核心LLM) │ │ 所有模态在同一个语义空间处理 │ └─────────────────────────────────────────┘ ↓ ┌─────────────────────────────────────────┐ │ 输出生成(多模态) │ │ 文本 / 图像 / 音频 / 视频 │ └─────────────────────────────────────────┘关键点:所有模态最终被编码为类似"token"的离散单元,用同一套LLM架构处理。更准确的分类术语为避免混淆,学术界/工业界出现了更精确的术语:术语全称含义代表LLMLarge Language Model纯文本或以文本为主的模型GPT-3、LLaMA 2VLMVision-Language Model视觉-语言模型LLaVA、CogVLMMLLMMultimodal Large Language Model多模态大语言模型GPT-4V、Qwen-VLLMMLarge Multimodal Model大型多模态模型(更通用)GPT-4o、GeminiFoundation Model基础模型泛指所有大规模预训练模型所有上述模型GPT-5的准确分类:MLLM(多模态大语言模型) 或 LMM(大型多模态模型)一句话总结问题答案LLM不是只处理语言吗?传统是,但现在LLM的概念已扩展,GPT-5这类模型本质是以语言为核心的多模态模型为什么还叫GPT(Generative Pre-trained Transformer)?品牌延续性 + 技术架构未变(仍是Transformer)+ 语言仍是核心交互方式更准确的叫法?MLLM(多模态大语言模型) 比纯 LLM 更准确
-
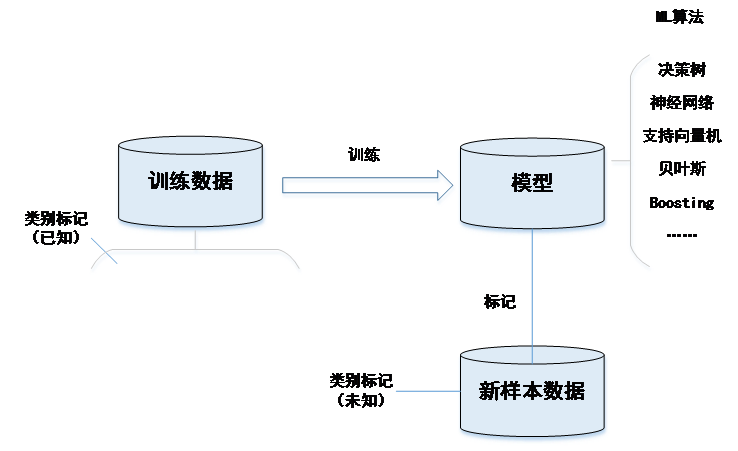
AI专题二:机器学习概述 01 机器学习概述随着大数据的发展,机器学习进入了最美好的时代,通过“涟漪效应”逐步迭代,大数据推动机器学习真正实现落地。接下来,我们从大数据讲起,扩展到机器学习的发展和大数据生态。理解大数据数据源越多越精确,越能无限逼近事实和真相,越能获得更深邃的智慧和洞察,这就是大数据的价值。总之,大数据的存储、处理需要云计算基础设施的支撑,云计算需要海量数据的处理能力证明自身的价值;人工智能技术的进步离不开云计算能力的不断增长,云计算让人工智能服务无处不在、触手可及;大数据的价值发现需要高效的人工智能方法,人工智能的自我学习需要海量数据的输入。随着大数据和人工智能的深度融合,高度数据化的AI(人工智能)和高度智能化的DT(大数据技术)并存将是时代新常态。机器学习发展过程机器学习(Machine Learning,ML)是人工智能的核心,涉及统计学、系统辨识、逼近理论、神经网络、优化理论、计算机科学、脑科学等诸多领域,研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构从而不断改善自身的性能。相对于传统机器学习利用经验改善系统自身的性能,现在的机器学习更多是利用数据改善系统自身的性能。基于数据的机器学习是现代智能技术中的重要方法之一,它从观测数据(样本)出发寻找规律,利用这些规律对未来数据或无法观测的数据进行预测。机器学习的发展过程分为三个阶段。第一阶段,逻辑推理期(1956年—1960年),以自动定理证明系统为代表,如西蒙与纽厄尔的Logic Theorist系统,但是逻辑推理存在局限性。第二阶段,知识期(1970年—1980年),以专家系统为代表,如费根·鲍姆等人的DENDRAL系统,存在要总结出知识、很难“教”给系统的问题。第三阶段,学习期(1990年至今),机器学习是作为“突破知识工程瓶颈”之利器出现的。在20世纪90年代中后期,人类发现自己淹没在数据的海洋中,机器学习也从利用经验改善性能转变为利用数据改善性能。这阶段,人们对机器学习的需求也日益迫切。典型的机器学习过程是以算法、数据的形式,利用已知数据标注未知数据的过程。如图1-3所示,首先需要将数据分为训练集和样本集(训练集的类别标记已知),通过选择合适的机器学习算法,将训练数据训练成模型,通过模型对新样本集进行类别标记。▲图1-3 典型的机器学习过程使用机器学习解决实际问题需要具体问题具体分析,根据场景进行算法设计。大数据生态环境在大数据生态环境中,包括数据采集、数据存储、数据预处理、特征处理、模型构建、数据可视化等,通过分类、聚类、回归、协同过滤、关联规则等机器学习方法,深入挖掘数据价值,并实现数据生态的良性循环。如同海量数据存储在云计算设备中,水存储在江河湖海之中;数据采集可以理解为从各种渠道聚集水进入江河湖海;数据预处理可以理解为水之蒸发、过滤、提取形成天上云的过程;云进行特征的自我变化和重组,最终形成可以转变的状态;基于机器学习的模型构建,即可以理解为不同天气状况下的云转变成雨水、雪花、冰雹、寒霜、雾气的变化过程。水存储在江河湖海中,经过蒸发、过滤、提取形成云,云自我变化、重组,而在不同天气下转变成雨水、雪花、冰雹、寒霜、雾气过程的可视化观察,可以理解为人对自然把握和发现的过程。数据流转生态如图1-4所示。▲图1-4 数据流转生态可以简单抽象一下,云转换成雨水、雪花、冰雹、寒霜、雾气的过程就是分类的过程,云按照任何一种变化(如雨水)汇集的过程就是聚类的过程。根据历史雨水的情况,预测即将降雨的情况就是回归过程。在某种气候条件下,雨水和雪花会并存,产生“雨夹雪”的天气情况,这就是关联过程。根据对雨水、雪花、冰雹、寒霜、雾气的喜好程度,选择观察自己喜好的天气,就是协同过滤的过程。导致天气变化的因素很多(很多和雾霾有关),处理起来有难度,在不丧失主要特征的情况,去掉部分特征,这个过程就是特征降维的过程。通过模拟人类大脑的神经连接结构,将各种和雾霾相关的天气特征转换到具有语义特征的新特征空间,自动学习得到层次化的特征表示,从而提高雾霾的预报性能,这就是深度学习过程。02 机器学习算法根据学习方法不同可以将机器学习分为传统机器学习、深度学习、其他机器学习。参考Kaggle机器学习大调查,数据科学中更常见的还是传统经典的机器学习算法,简单的线性与非线性分类器是数据科学中最常见的算法,功能强大的集成方法也十分受欢迎。最常用的数据科学方法是逻辑回归,而国家安全领域则更为频繁使用神经网络。总的来说,目前神经网络模型的使用频率要高于支持向量机,这可能是因为近来多层感知机要比使用带核函数的SVM有更加广泛的表现。传统机器学习传统机器学习从一些观测(训练)样本出发,试图发现不能通过原理分析获得的规律,实现对未来数据行为或趋势的准确预测。传统机器学习平衡了学习结果的有效性与学习模型的可解释性,为解决有限样本的学习问题提供了一种框架,主要用于有限样本情况下的模式分类、回归分析、概率密度估计等。传统机器学习方法的重要理论基础之一是统计学,在自然语言处理、语音识别、图像识别、信息检索和生物信息等许多计算机领域获得了广泛应用。相关算法包括逻辑回归、隐马尔可夫方法、支持向量机方法、K近邻方法、三层人工神经网络方法、Adaboost算法、贝叶斯方法以及决策树方法等。(1)分类方法分类方法是机器学习领域使用最广泛的技术之一。分类是依据历史数据形成刻画事物特征的类标识,进而预测未来数据的归类情况。目的是学会一个分类函数或分类模型(也称作分类器),该模型能把数据集中的事物映射到给定类别中的某一个类。在分类模型中,我们期望根据一组特征来判断类别,这些特征代表了物体、事件或上下文相关的属性。(2)聚类方法聚类是指将物理或抽象的集合分组成为由类似的对象组成的多个类的过程。由聚类生成的簇是一组数据对象的集合,这些对象与同一个簇中的对象彼此相似,与其他簇中的对象相异。在许多应用中,一个簇中的数据对象可作为一个整体来对待。在机器学习中,聚类是一种无监督的学习,在事先不知道数据分类的情况下,根据数据之间的相似程度进行划分,目的是使同类别的数据对象之间的差别尽量小,不同类别的数据对象之间的差别尽量大。通常使用KMeans进行聚类,聚类算法LDA是一个在文本建模中很著名的模型,类似于SVD、PLSA等模型,可以用于浅层语义分析,在文本语义分析中是一个很有用的模型。(3)回归方法回归是根据已有数值(行为)预测未知数值(行为)的过程,与分类模式分析不同,预测分析更侧重于“量化”。一般认为,使用分类方法预测分类标号(或离散值),使用回归方法预测连续或有序值。如用户对这个电影的评分是多少?用户明天使用某个产品(手机)的概率有多大?常见的预测模型基于输入的用户信息,通过模型的训练学习,找出数据的规律和趋势,以确定未来目标数据的预测值。(4)关联规则关联规则是指发现数据中大量项集之间有趣的关联或相关联系。挖掘关联规则的步骤包括:① 找出所有频繁项集,这些项集出现的频繁性至少和预定义的最小支持计数一样;② 由频繁项集产生强关联规则,这些规则必须满足最小支持度和最小置信度。随着大量数据不停地收集和存储,许多业界人士对从数据集中挖掘关联规则越来越感兴趣。从大量商务事务记录中发现有趣的关联关系,可以帮助制定许多商务决策。通过关联分析发现经常出现的事物、行为、现象,挖掘场景(时间、地点、用户性别等)与用户使用业务的关联关系,从而实现因时、因地、因人的个性化推送。(5)协同过滤随着互联网上的内容逐渐增多,人们每天接收的信息远远超出人类的信息处理能力,信息过载日益严重,因此信息过滤系统应运而生。信息过滤系统基于关键词,过滤掉用户不想看的内容,只给用户展示感兴趣的内容,大大地减少了用户筛选信息的成本。协同过滤起源于信息过滤,与信息过滤不同,协同过滤分析用户的兴趣并构建用户兴趣模型,在用户群中找到指定用户的相似兴趣用户,综合这些相似用户对某一信息的评价,系统预测该指定用户对此信息的喜好程度,再根据用户的喜好程度给用户展示内容。(6)特征降维特征降维自20世纪70年代以来获得了广泛的研究,尤其是近几年以来,在文本分析、图像检索、消费者关系管理等应用中,数据的实例数目和特征数据都急剧增加,这种数据的海量性使得大量机器学习算法在可测量性和学习性能方面产生严重问题。例如,具有成百上千特征的高维数据集,会包含大量的无关信息和冗余信息,这些信息可能极大地降低学习算法的性能。因此,当面临高维数据时,特征降维对于机器学习任务显得十分重要。特征降维从初始高维特征集中选出低维特征集合,以便根据一定的评估准则最优化、缩小特征空间的过程,通常作为机器学习的预处理步骤。大量研究实践证明,特征降维能有效地消除无关和冗余特征,提高挖掘任务的效率,改善预测精确性等学习性能,增强学习结果的易理解性。’深度学习深度学习又称为深度神经网络(指层数超过3层的神经网络),是建立深层结构模型的学习方法。深度学习作为机器学习研究中的一个新兴领域,由Hinton等人于2006年提出。深度学习源于多层神经网络,其实质是给出了一种将特征表示和学习合二为一的方式。深度学习的特点是放弃了可解释性,单纯追求学习的有效性。经过多年的摸索尝试和研究,已经产生了诸多深度神经网络的模型,包括深度置信网络、卷积神经网络、受限玻尔兹曼机和循环神经网络等。其中卷积神经网络、循环神经网络是两类典型的模型。卷积神经网络常应用于空间性分布数据;循环神经网络在神经网络中引入了记忆和反馈,常应用于时间性分布数据。深度学习框架一般包含主流的神经网络算法模型,提供稳定的深度学习API,支持训练模型在服务器和GPU、TPU间的分布式学习,部分框架还具备在包括移动设备、云平台在内的多种平台上运行的移植能力,从而为深度学习算法带来了前所未有的运行速度和实用性。目前主流的开源算法框架有TensorFlow、Caffe/Caffe2、CNTK、MXNet、PaddlePaddle、Torch/PyTorch、Theano等。深度学习是机器学习研究中的一个分支领域,其动机在于建立、模拟人脑进行分析学习的神经网络,它模仿人脑的机制来解释数据,例如图像、声音和文本。从技术上来看,深度学习就是“很多层”的神经网络,神经网络实质上是多层函数嵌套形成的数据模型。伴随着云计算、大数据时代的到来,计算能力的大幅提升,深度学习模型在计算机视觉、自然语言处理、语音识别等众多领域都取得了较大的成功其他机器学习此外,机器学习的常见算法还包括迁移学习、主动学习和演化学习等。(1)迁移学习迁移学习是指当在某些领域无法取得足够多的数据进行模型训练时,利用另一领域的数据获得的关系进行学习。迁移学习可以把已训练好的模型参数迁移到新的模型,指导新模型训练,更有效地学习底层规则、减少数据量。目前的迁移学习技术主要在变量有限的小规模应用中使用,如基于传感器网络的定位、文字分类和图像分类等。未来迁移学习将被广泛应用于解决更有挑战性的问题,如视频分类、社交网络分析、逻辑推理等。(2)主动学习主动学习通过一定的算法查询最有用的未标记样本,并交由专家进行标记,然后用查询到的样本训练分类模型来提高模型的精度。主动学习能够选择性地获取知识,通过较少的训练样本获得高性能的模型,最常用的策略是通过不确定性准则和差异性准则选取有效的样本。(3)演化学习演化学习基于演化算法提供的优化工具设计机器学习算法,针对机器学习任务中存在大量的复杂优化问题,应用于分类、聚类、规则发现、特征选择等机器学习与数据挖掘问题。演化算法通常维护一个解的集合,并通过启发式算子来从现有的解产生新解,并通过挑选更好的解进入下一次循环,不断提高解的质量。演化算法包括粒子群优化算法、多目标演化算法等。03 机器学习分类机器学习按照学习形式进行分类,可分为监督学习、无监督学习、半监督学习、强化学习等。区别在于,监督学习需要提供标注的样本集,无监督学习不需要提供标注的样本集,半监督学习需要提供少量标注的样本,而强化学习需要反馈机制。监督学习监督学习是利用已标记的有限训练数据集,通过某种学习策略/方法建立一个模型,实现对新数据/实例的标记(分类)/映射。监督学习要求训练样本的分类标签已知,分类标签的精确度越高,样本越具有代表性,学习模型的准确度越高。监督学习在自然语言处理、信息检索、文本挖掘、手写体辨识、垃圾邮件侦测等领域获得了广泛应用。监督学习的输入是标注分类标签的样本集,通俗地说,就是给定了一组标准答案。监督学习从这样给定了分类标签的样本集中学习出一个函数,当新的数据到来时,就可以根据这个函数预测新数据的分类标签。监督学习过程如图1-5所示。▲图1-5 监督学习流程图在监督学习下,输入数据被称为“训练数据”,每组训练数据有一个明确的标识或结果,如对反垃圾邮件系统中的“垃圾邮件”“非垃圾邮件”分类等。在建立预测模型的时候,监督学习建立一个学习过程,将预测结果与“训练数据”的实际结果进行比较,不断调整预测模型,直到模型的预测结果达到一个预期的准确率。最典型的监督学习算法包括回归和分类等。无监督学习无监督学习是利用无标记的有限数据描述隐藏在未标记数据中的结构/规律。无监督学习不需要训练样本和人工标注数据,便于压缩数据存储、减少计算量、提升算法速度,还可以避免正负样本偏移引起的分类错误问题,主要用于经济预测、异常检测、数据挖掘、图像处理、模式识别等领域,例如组织大型计算机集群、社交网络分析、市场分割、天文数据分析等。无监督学习与监督学习相比,样本集中没有预先标注好的分类标签,即没有预先给定的标准答案。它没有告诉计算机怎么做,而是让计算机自己去学习如何对数据进行分类,然后对那些正确分类行为采取某种形式的激励。在无监督学习中,数据并不被特别标识,学习模型是为了推断出数据的一些内在结构。常见的应用场景包括关联规则的学习以及聚类等。常见算法包括Apriori算法、KMeans算法、随机森林(random forest)、主成分分析(principal component analysis)等。半监督学习半监督学习介于监督学习与无监督学习之间,其主要解决的问题是利用少量的标注样本和大量的未标注样本进行训练和分类,从而达到减少标注代价、提高学习能力的目的。在此学习方式下,输入数据部分被标识,部分没有被标识,这种学习模型可以用来进行预测,但是该模型首先需要学习数据的内在结构以便合理地组织数据进行预测。应用场景包括分类和回归,算法包括一些对常用监督学习算法的延伸,这些算法首先试图对未标识数据进行建模,在此基础上再对标识的数据进行预测。如图论推理(graph inference)算法或者拉普拉斯支持向量机(Laplacian SVM)等。强化学习强化学习是智能系统从环境到行为映射的学习,以使强化信号函数值最大。由于外部环境提供的信息很少,强化学习系统必须靠自身的经历进行学习。强化学习的目标是学习从环境状态到行为的映射,使得智能体选择的行为能够获得环境的最大奖赏,使得外部环境对学习系统在某种意义下的评价为最佳。其在机器人控制、无人驾驶、下棋、工业控制等领域获得成功应用。在这种学习模式下,输入数据作为对模型的反馈,不像监督模型那样,输入数据仅仅是作为一个检查模型对错的方式。在强化学习下,输入数据直接反馈到模型,模型必须对此立刻做出调整。常见的应用场景包括动态系统以及机器人控制等。常见算法包括Q-Learning以及时间差学习(temporal difference learning)。04 机器学习综合应用机器学习已经“无处不在”,应用遍及人工智能的各个领域,包括数据挖掘、计算机视觉、自然语言处理、语音和手写识别、生物特征识别、搜索引擎、医学诊断、信用卡欺诈检测、证券市场分析、汽车自动驾驶、军事决策等。下面我们从异常检测、用户画像、广告点击率预估、企业征信大数据应用、智慧交通大数据应用等方面介绍大数据的综合应用。异常检测异常是指某个数据对象由于测量、收集或自然变异等原因变得不同于正常的数据对象的场景,找出异常的过程,称为异常检测。根据异常的特征,可以将异常分为以下三类:点异常、上下文异常、集合异常。异常检测的训练样本都是非异常样本,假设这些样本的特征服从高斯分布,在此基础上估计出一个概率模型,用该模型估计待测样本属于非异常样本的可能性。异常检测步骤包括数据准备、数据分组、异常评估、异常输出等步骤。用户画像用户画像的核心工作就是给用户打标签,标签通常是人为规定的高度精炼的特征标识,如年龄、性别、地域、兴趣等。由这些标签集合能抽象出一个用户的信息全貌,每个标签分别描述了该用户的一个维度,各个维度相互联系,共同构成对用户的整体描述。在产品的运营和优化中,根据用户画像能够深入理解用户需求,从而设计出更适合用户的产品,提升用户体验。使用某新闻App用户行为数据构建用户画像的流程和一些常用的标签体系实践,详见干货请收好:终于有人把用户画像的流程、方法讲明白了。广告点击率预估互联网广告是互联网公司主要的盈利手段,互联网广告交易的双方是广告主和媒体。为自己的产品投放广告并为广告付费;媒体是有流量的公司,如各大门户网站、各种论坛,它们提供广告的展示平台,并收取广告费。广告点击率(Click Through Rate,CTR)是指广告的点击到达率,即广告的实际点击次数除以广告的展现量。在实际应用中,我们从广告的海量历史展现点击日志中提取训练样本,构建特征并训练CTR模型,评估各方面因素对点击率的影响。当有新的广告位请求到达时,就可以用训练好的模型,根据广告交易平台传过来的相关特征预估这次展示中各个广告的点击概率,结合广告出价计算得到的广告点击收益,从而选出收益最高的广告向广告交易平台出价。企业征信大数据应用征信是指为信用活动提供信用信息服务,通过依法采集、整理、保存、加工企业、事业单位等组织的信用信息和个人的信用信息,并提供给信息使用者。征信是由征信机构、信息提供方、信息使用方、信息主体四部分组成,综合起来,形成了一个整体的征信行业的产业链。征信机构向信息提供方采集征信相关数据,信息使用方获得信息主体的授权以后,可以向征信机构索取该信息主体的征信数据,从征信机构获得征信产品,针对企业来说,是由该企业的各种维度数据构成的征信报告。智慧交通大数据应用智慧交通大数据应用是以物联网、云计算、大数据等新一代信息技术,结合人工智能、机器学习、数据挖掘、交通科学等理论与工具,建立起的一套交通运输领域全面感知、深度融合、主动服务、科学决策的动态实时信息服务体系。基于人工智能和大数据技术的叠加效应,结合交通行业的专家知识库建立交通数据模型,解决城市交通问题,是交通大数据应用的首要任务。交通大数据模型主要分为城市人群时空图谱、交通运行状况感知与分析、交通专项数字化运营和监管、交通安全分析与预警等几大类https://cloud.tencent.com/developer/article/1417894