搜索到
378
篇与
的结果
-
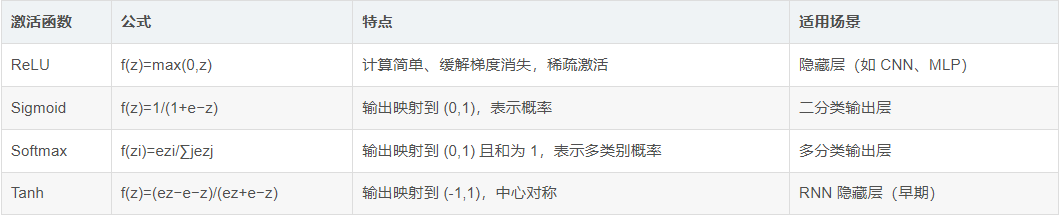
 AI专题三:深度学习概述 深度学习是机器学习的重要分支,核心是通过多层神经网络(深度神经网络) 模拟人类大脑的层级化信息处理方式,从数据中自动学习特征表示,最终实现分类、回归、生成等任务。与传统机器学习依赖人工设计特征不同,深度学习的 “深度” 带来了端到端学习的能力,能处理图像、文本、语音等复杂高维数据,是当前人工智能 领域的核心技术基石。一、深度学习的核心基础从 “浅层学习” 到 “深度学习”:核心差异传统机器学习(如 SVM、决策树)属于 “浅层学习”,模型通常只有 “输入层 + 输出层”(或 1 层隐藏层),无法处理复杂数据的层级特征(如从图像的 “像素→边缘→纹理→语义”)。而深度学习通过堆叠多层隐藏层,实现特征的 “自动抽象”:浅层学习:需人工设计特征(如用 HOG 提取图像边缘)→ 模型学习映射关系;深度学习:输入原始数据(如图像像素)→ 浅层隐藏层学习低级特征(边缘、颜色)→ 深层隐藏层学习高级特征(纹理、物体部件)→ 输出层完成任务(分类、生成)。类比:如同识别一只猫 —— 人类先看到 “线条(低级特征)”,再组合成 “耳朵、眼睛(中级特征)”,最终判断为 “猫(高级特征)”,深度学习的多层网络正是模拟这一过程。深度神经网络的基本构成所有深度学习模型的基础是 “神经网络”,其核心单元是神经元(Neuron),多层神经元堆叠形成 “网络结构”,主要包括三部分:(1)神经元:网络的 “最小计算单元”神经元模拟生物神经元的 “接收 - 处理 - 输出” 逻辑,结构如下:输入:接收来自上一层的信号(如前一层神经元的输出 x1,x2,...,xn);权重与偏置:每个输入对应一个可学习的权重 w1,w2,...,wn(表示输入的重要性),另有一个偏置 b(调整输出基线);激活函数:对 “加权和 z=w1x1+w2x2+...+wnxn+b” 做非线性变换,输出 a=f(z)(引入非线性,让网络能拟合复杂函数)。关键:激活函数是神经网络能学习复杂模式的核心,若无激活函数,多层网络等价于单层线性模型(无法处理非线性问题)。常用激活函数包括:(2)网络层级:特征的 “抽象流水线”多层神经元按功能分为三类层级,协同完成特征学习:输入层(Input Layer):接收原始数据,不做计算(如图像任务输入 “像素矩阵”,文本任务输入 “词向量”);隐藏层(Hidden Layer):核心特征抽象层,层数≥1(“深度” 即指隐藏层数量),层数越多,能学习的特征越复杂(如 10 层网络可学习 “物体语义”,100 层网络可学习 “场景逻辑”);输出层(Output Layer):输出任务结果,维度由任务决定(如二分类输出 1 个值,10 分类输出 10 个值)。(3)参数与超参数:网络的 “调控旋钮”参数:网络自动学习的变量,即所有神经元的权重 w 和偏置 b,参数数量决定模型复杂度(如 ResNet-50 约有 2500 万参数);超参数:人工设定的变量,需通过 “调优” 确定,如隐藏层数量、每层神经元数、学习率、 batch size 等,直接影响模型性能。深度学习的 “核心三要素”任何深度学习模型的训练与推理,都依赖以下三个核心机制,缺一不可:(1)损失函数(Loss Function):“判断模型好坏的标尺”损失函数量化 “模型预测值” 与 “真实标签” 的差异,是模型优化的目标(最小化损失函数)。不同任务对应不同损失函数:分类任务:交叉熵损失(Cross-Entropy Loss):衡量概率分布差异,适用于二分类(Binary Cross-Entropy)和多分类(Categorical Cross-Entropy);回归任务:均方误差(MSE):MSE=N1∑i=1N(yi−y^i)2,衡量连续值预测的误差(如房价预测、温度预测);生成任务:对抗损失(Adversarial Loss):GAN 中用于让生成器生成 “逼真数据” 的损失,通过生成器与判别器的对抗优化。(2)优化器(Optimizer):“模型学习的‘导航仪’”优化器的作用是 “调整参数 w 和 b,以最小化损失函数”,核心是通过梯度下降(Gradient Descent) 实现 —— 计算损失函数对参数的梯度(方向),沿梯度反方向更新参数。传统梯度下降(全量梯度下降)计算量大,实际中常用改进版:(3)反向传播(Backpropagation):“模型学习的‘反馈机制’”反向传播是 “计算梯度、更新参数” 的核心算法,遵循 “链式法则”—— 从输出层到输入层,逐层计算损失函数对每个参数的梯度,再通过优化器更新参数。流程:前向传播(Forward Pass):输入数据通过网络,计算各层输出和最终损失 L;反向传播(Backward Pass):从输出层开始,计算 L 对输出层参数的梯度 → 隐藏层参数的梯度 → 输入层参数的梯度(链式法则);参数更新(Parameter Update):用优化器根据梯度调整参数(如 w=w−η⋅∂w∂L,η 为学习率)。关键:反向传播是深度学习能 “自主学习” 的核心 —— 没有反向传播,参数无法根据误差调整,模型无法优化。二、深度学习的核心模型家族深度学习并非单一模型,而是由多个 “模型家族” 组成,每个家族针对特定数据类型(图像、文本、序列)设计,以下是最核心的 5 类模型:卷积神经网络(CNN :Convolutional Neural Network)——“图像任务的‘王者’”CNN 是为处理 “网格结构数据”(如图像:2D 像素网格、视频:3D 时空网格)设计的模型,核心创新是卷积操作和池化操作,解决了传统 MLP 处理图像时 “参数爆炸” 和 “缺乏空间关联性” 的问题。(1)核心机制:卷积操作:用 “卷积核” 在图像上滑动,提取局部空间特征(如边缘、纹理),通过 “参数共享”(同一卷积核在全图共享参数)大幅减少参数量;池化操作:对卷积输出做 “下采样”(如最大池化、平均池化),降低特征图尺寸,减少计算量,同时增强模型对图像平移、缩放的鲁棒性;层级结构:浅层(卷积 + 池化)学习低级特征(边缘、颜色)→ 深层(卷积 + 全连接)学习高级特征(物体部件、语义)。(2)经典模型与应用:经典模型:LeNet-5(1998):首个 CNN,用于手写数字识别;AlexNet(2012):CNN 爆发的标志,用 ReLU 和 GPU 加速,ImageNet 分类准确率大幅提升;ResNet(2015):引入 “残差连接”,解决深层网络的 “梯度消失” 问题,可训练 1000 层以上网络;YOLO、Faster R-CNN:基于 CNN 的目标检测模型,实现 “实时识别图像中的物体位置”。应用场景:图像分类(如人脸识别)、目标检测(如自动驾驶识别车辆行人)、图像分割(如医学影像分割肿瘤)、图像生成(如 GAN 生成人脸)。循环神经网络(RNN:Recurrent Neural Network)——“序列数据的‘专属模型’”RNN 是为处理 “序列数据”(如文本:单词序列、语音:音频帧序列、时间序列:股票价格)设计的模型,核心创新是隐藏状态的 “记忆性”—— 当前输出不仅依赖当前输入,还依赖上一时刻的隐藏状态,能捕捉序列的 “时序关联性”。(1)核心机制:循环结构:RNN 的隐藏层包含 “循环单元”,假设时刻 t 的输入为 xt,隐藏状态为 ht,则:ht=f(Wxhxt+Whhht−1+bh)yt=Whyht+by其中 Whh 是 “循环权重”,使 ht 携带上一时刻 ht−1 的信息(记忆);局限性:传统 RNN 存在 “长期依赖问题”—— 当序列过长(如 100 个单词的句子),梯度在反向传播时会 “消失或爆炸”,无法捕捉长距离时序关联。(2)改进模型:LSTM 与 GRU为解决长期依赖问题,研究者提出了 “门控循环单元”,最常用的是 LSTM(长短期记忆网络)和 GRU(门控循环单元):LSTM:通过 “输入门、遗忘门、输出门” 控制信息的 “存入、遗忘、输出”,能有效保存长序列的关键信息(如理解 “上下文很长的句子”);GRU:简化 LSTM 的门结构(合并为 “更新门、重置门”),在保持性能的同时减少计算量。(3)应用场景:文本处理:机器翻译(如 Google 翻译的核心模型)、情感分析(判断 “这篇影评是好评还是差评”)、文本生成(自动写小说);语音处理:语音识别(将音频转为文字)、语音合成(将文字转为语音);时间序列预测:股票价格预测、天气预报、设备故障预测。Transformer 模型 ——“当前 AI 的‘核心架构’”Transformer 是 2017 年提出的模型,基于 “自注意力机制(Self-Attention)”,彻底摆脱了 RNN 的 “循环依赖”,能并行处理序列数据(RNN 需逐时刻处理,Transformer 可同时处理所有位置),且能捕捉序列的 “长距离关联”,目前已成为 NLP、CV、多模态任务的 “统一架构”。(1)核心机制:自注意力机制:让序列中每个位置的元素 “关注” 其他所有位置的元素,计算它们的相关性(权重),再加权求和得到该位置的 “注意力特征”。例如处理句子 “猫坐在垫子上”,“猫” 会关注 “垫子”(相关性高),关注 “上”(相关性低);多头注意力(Multi-Head Attention):并行执行多个自注意力,捕捉不同维度的关联(如一个头关注 “语法关联”,另一个头关注 “语义关联”),再拼接结果;编码器 - 解码器结构:Transformer 通常由 “编码器(Encoder)” 和 “解码器(Decoder)” 组成,编码器负责 “提取序列特征”,解码器负责 “生成目标序列”(如机器翻译中,编码器处理英文,解码器生成中文)。(2)经典模型与应用:BERT:基于 Transformer 编码器的预训练模型,通过 “掩码语言模型” 预训练(随机掩盖部分单词,让模型预测),在文本分类、问答等任务中刷新精度;GPT 系列:基于 Transformer 解码器的生成式模型(GPT-3、GPT-4),通过 “自回归生成”(逐词生成文本),实现对话、代码生成、逻辑推理等复杂任务;Vision Transformer(ViT):将 Transformer 应用于图像任务,把图像分割为 “图像块”(类似文本的单词),用自注意力捕捉块间关联,在图像分类任务中超越 CNN;多模态模型:如 CLIP(跨模态匹配)、DALL・E(文本生成图像),用 Transformer 统一处理文本和图像,实现 “跨模态理解与生成”。生成对抗网络(GAN :Generative Adversarial Network)——“数据生成的‘魔术师’”GAN 是一类 “生成式模型”,核心思想是 “对抗训练”—— 通过 “生成器(Generator)” 和 “判别器(Discriminator)” 的相互对抗,让生成器学会生成 “逼真的数据”(如假人脸、假图像、假文本)。(1)核心机制:生成器(G):输入随机噪声(如 100 维向量),输出 “伪造数据”(如 64×64 的人脸图像),目标是让伪造数据 “骗过判别器”;判别器(D):输入 “真实数据”(如真实人脸)或 “伪造数据”(生成器输出),输出 “数据为真实的概率”(0~1),目标是 “正确区分真实与伪造数据”;对抗过程:G 和 D 如同 “小偷与警察”——G 不断优化以骗过 D,D 不断优化以识别 G,最终达到 “纳什均衡”:G 生成的假数据与真实数据难以区分,D 的判断准确率接近 50%(随机猜测)。(2)经典模型与应用:DCGAN:用 CNN 作为 G 和 D,首次实现高质量图像生成(如生成清晰的人脸、风景);StyleGAN:能控制生成图像的 “风格”(如人脸的发型、表情、光照),可生成 “超逼真的人脸”;CycleGAN:实现 “无监督图像风格迁移”(如将 “照片转为油画”“马转为斑马”,无需配对数据);应用场景:数据增强(生成训练数据,解决数据稀缺问题)、图像修复(填补图像中的缺失区域)、超分辨率重建(将低清图像转为高清)、文本生成图像(如 DALL・E 根据文字 “一只穿着西装的猫” 生成图像)。深度强化学习(DRL:Deep Reinforcement Learning)——“决策任务的‘智能体’”DRL 是 “深度学习” 与 “强化学习(RL)” 的结合,核心是让 “智能体(Agent)” 在 “环境(Environment)” 中通过 “试错” 学习 “最优决策策略”,以最大化 “累积奖励”(如游戏得分、任务完成度)。(1)核心机制:强化学习框架:Agent 在环境中执行动作 at,环境反馈 “奖励 rt” 和 “下一状态 st+1”,Agent 的目标是学习 “策略 π(a∣s)”(给定状态 s 时选择动作 a 的概率),使累积奖励最大;深度学习的作用:用深度神经网络(如 CNN、MLP)近似 “策略 π” 或 “价值函数 V(s)”(状态 s 的未来累积奖励),解决传统 RL 无法处理的 “高维状态空间” 问题(如 Atari 游戏的 210×160 像素图像状态)。(2)经典算法与应用DQN(深度 Q 网络):用 CNN 近似 Q 函数(Q(s,a) 表示在状态 s 执行动作 a 后的未来累积奖励),首次将深度学习与强化学习结合,成功解决 Atari 26 款游戏的决策问题(如《Breakout》打砖块游戏,AI 能自主学习 “反弹球击碎砖块” 的策略)。其核心改进是 “经验回放(Experience Replay)”—— 将智能体的交互经验(s,a,r,s′)存储在回放池,随机采样训练,避免样本相关性导致的训练不稳定。PPO(近端策略优化):当前工业界最常用的 DRL 算法,通过 “clip(裁剪)” 机制限制策略更新的幅度(避免策略突变导致训练崩溃),在保持性能的同时简化实现。PPO 广泛用于机器人控制(如机械臂抓取物体)、自动驾驶(如车道保持、避障决策)、游戏 AI(如《DOTA2》《星际争霸 2》的 AI 对战)。DDPG(深度确定性策略梯度):针对 “连续动作空间”(如机器人关节角度、无人机飞行速度)设计的算法,用 “确定性策略”(给定状态输出确定动作,而非概率分布)替代传统 RL 的 “随机策略”,适用于需要精细控制的场景(如机械臂精准抓取易碎物品)。应用场景:游戏 AI:训练 AI 击败人类职业选手(如 AlphaGo 击败李世石、DeepMind 的《星际争霸 2》AI 击败职业玩家);机器人控制:工业机械臂自动化装配、服务机器人自主导航避障、仿生机器人模拟人类动作;自动驾驶:决策层(如是否变道、超车、避让行人)、控制层(如油门、刹车、方向盘角度调节);资源调度:数据中心服务器负载调度(最大化资源利用率)、电网能源分配(平衡供需与成本)。三、深度学习的训练流程与关键挑战完整训练流程:从数据到模型部署深度学习模型的训练是 “数据驱动 + 迭代优化” 的过程,通常分为以下 6 个步骤,环环相扣:(1)数据准备:“模型的‘粮食’”数据收集:根据任务场景获取原始数据(如图像分类需收集万级以上带标签的图像,NLP 任务需收集大规模文本语料),数据质量直接决定模型上限(“垃圾数据训练不出好模型”)。数据预处理:清洗噪声(如删除模糊图像、修正错误标签)、标准化 / 归一化(如将图像像素值从 [0,255] 转为 [0,1],避免数值差异影响梯度更新)、数据增强(如图像任务的旋转 / 翻转 / 裁剪、文本任务的同义词替换,扩大数据量,提升模型泛化能力)。数据划分:将数据集分为训练集(70%~80%,用于模型学习)、验证集(10%~15%,用于调优超参数、监控过拟合)、测试集(10%~15%,用于评估模型最终性能,不可用于训练)。(2)模型构建:“设计‘学习框架’”选择基础架构:根据任务类型选择合适的模型家族(如图像任务选 CNN/ViT,序列任务选 Transformer/LSTM,决策任务选 DRL)。定义网络结构:设计隐藏层数量、每层神经元 / 通道数、激活函数、正则化方式(如 Dropout、BatchNorm)。例如图像分类任务的简单 CNN 结构:“卷积层(3×3)→ BatchNorm → ReLU → 最大池化 → 卷积层 → BatchNorm → ReLU → 全连接层 → Softmax 输出”。初始化参数:对网络权重 w 和偏置 b 进行初始化(如 Xavier 初始化、He 初始化),避免初始值过大 / 过小导致梯度消失或爆炸。(3)配置训练参数:“设定‘学习规则’”选择损失函数:匹配任务类型(如分类用交叉熵损失,回归用 MSE,生成用对抗损失)。选择优化器:默认优先选 Adam(收敛快、稳定性高),大规模任务可选 SGD(配合动量,泛化性更好),序列任务可选 RMSprop。设定超参数:学习率(通常从 0.001 开始调试,过小训练慢,过大不收敛)、batch size(内存允许下越大越好,提升训练稳定性)、训练轮次(Epoch,直到验证集损失不再下降)。(4)模型训练:“迭代优化参数”前向传播:将训练集 batch 输入模型,计算各层输出和损失值 L。反向传播:通过链式法则计算损失对所有参数的梯度,用优化器更新参数(如 w=w−η⋅∇wL)。监控与调整:每训练 1 个 Epoch,用验证集评估模型性能(如准确率、MSE),若验证集性能下降(过拟合),则调整超参数(如减小学习率、增加 Dropout 比例)或停止训练(早停法)。(5)模型评估:“检验‘学习成果’”测试集评估:用测试集计算模型的关键指标(如图像分类的 Top-1/Top-5 准确率、NLP 任务的 BLEU 值、DRL 任务的平均累积奖励),评估模型泛化能力(能否处理未见过的数据)。错误分析:分析模型预测错误的样本(如分类任务中 “将猫误判为狗” 的图像),定位问题(如特征提取不足、数据分布不均),指导模型改进。(6)模型部署:“落地‘实际应用’”模型压缩:训练好的模型通常较大(如 ResNet-50 约 100MB),需通过量化(将 32 位浮点数转为 16 位 / 8 位整数)、剪枝(删除冗余参数)、蒸馏(用大模型教小模型)等方式减小体积,适配移动端 / 嵌入式设备(如手机、智能摄像头)。部署方式:通过 TensorFlow Lite、PyTorch Mobile 等框架将模型部署到终端设备(本地推理,低延迟),或部署到云端(提供 API 服务,支持大规模调用)。例如人脸识别模型部署到手机,实现 “解锁” 功能;目标检测模型部署到自动驾驶汽车,实时识别路况。深度学习的关键挑战:从理论到实践的 “拦路虎”尽管深度学习已取得巨大成功,但仍面临多个核心挑战,限制其在部分场景的应用:(1)数据依赖:“无数据,难学习”问题:深度学习是 “数据密集型” 技术,优秀模型通常需要海量标注数据(如 ImageNet 有 120 万标注图像,GPT-3 训练用了 45TB 文本数据)。对于小众领域(如罕见病医学影像、特定行业的工业检测),标注数据稀缺,模型性能难以提升。解决方向:半监督学习(用少量标注数据 + 大量无标注数据训练)、无监督学习(完全依赖无标注数据,如 GAN 的对抗训练)、迁移学习(将通用数据集上预训练的模型迁移到小众任务,减少数据需求)。(2)过拟合:“学‘死’了,不会灵活应用”问题:模型在训练集上表现优异,但在测试集上性能大幅下降,即 “死记硬背训练数据,无法泛化到新数据”。常见原因包括模型过于复杂(参数过多)、训练数据量不足、数据增强不够。解决方向:正则化(如 L1/L2 正则化惩罚大权重、Dropout 随机关闭部分神经元)、早停法(验证集损失上升时停止训练)、数据增强(扩大数据多样性)、简化模型结构(减少隐藏层 / 神经元数量)。(3)可解释性差:“黑盒子,不知道为什么对 / 错”问题:深度学习模型的决策过程难以解释(如 CNN 判断 “这是猫”,但无法说明是 “耳朵” 还是 “毛发” 起了关键作用;GPT 生成文本,无法解释逻辑链)。在医疗(如疾病诊断)、司法(如风险评估)等对 “可解释性” 要求高的领域,应用受限。解决方向:可解释 AI(XAI)技术,如特征可视化(展示 CNN 各层学习的特征)、注意力分析(如 Transformer 的注意力热力图,显示模型关注的文本 / 图像区域)、模型蒸馏(用简单模型(如决策树)解释复杂模型的决策)。(4)计算成本高:“训练一次,烧钱又耗时”问题:深层模型(如 GPT-4、大参数 ViT)的训练需要大规模 GPU/TPU 集群,计算成本极高(如 GPT-3 训练成本约 4600 万美元),且训练周期长(通常需要数周甚至数月),普通研究者和企业难以承担。解决方向:模型压缩(减少参数和计算量)、高效训练框架(如 Megatron-LM、DeepSpeed,支持模型并行和混合精度训练)、硬件优化(如专用 AI 芯片,提升计算效率)。(5)鲁棒性差:“微小干扰,就能‘骗’错模型”问题:深度学习模型对 “对抗样本”(在原始数据中添加人眼不可见的微小噪声)极为敏感。例如在 “猫” 的图像上添加细微噪声,模型会误判为 “飞机”;在自动驾驶的路况图像中添加干扰,模型会忽略行人。解决方向:对抗训练(在训练中加入对抗样本,提升模型抗干扰能力)、鲁棒性正则化(约束模型对微小扰动不敏感)、输入验证(检测并过滤对抗样本)。四、深度学习的前沿趋势与未来方向随着技术不断迭代,深度学习正从 “单一任务” 向 “通用智能” 演进,以下是当前最值得关注的 4 个前沿趋势:大语言模型(LLM)与通用人工智能(AGI)核心进展:以 GPT 系列、LLaMA、文心一言、通义千问为代表的大语言模型,通过万亿级参数和海量文本训练,具备了上下文理解、逻辑推理、多轮对话、代码生成、跨领域知识问答等能力,成为 “通用智能” 的重要载体。例如 GPT-4 能理解图像内容、解决复杂数学题、撰写专业论文,甚至参与创意设计。未来方向:提升模型的 “认知能力”(如因果推理、常识理解)、“多模态能力”(融合文本、图像、音频、视频)、“高效性”(降低大模型的训练和推理成本),推动 LLM 从 “专用工具” 向 “通用助手” 演进,逐步接近 AGI(具备人类级别的学习和适应能力)。多模态学习(Multimodal Learning)核心进展:传统深度学习模型多处理单一模态数据(如 CNN 处理图像、Transformer 处理文本),而多模态学习旨在让模型同时理解和处理多种模态数据(文本 + 图像 + 音频 + 视频),模拟人类 “多感官协同认知” 的方式。例如 CLIP(Contrastive Language-Image Pre-training)能实现 “文本 - 图像跨模态匹配”(输入 “红色的猫”,自动找到对应的图像);DALL・E、MidJourney 能通过文本生成高质量图像;GPT-4V 能分析图像内容并生成文字描述。未来方向:解决多模态数据的 “模态鸿沟”(不同模态数据的表示差异大,如文本是离散符号,图像是连续像素)、提升多模态模型的 “跨模态生成能力”(如根据音频生成视频、根据图像生成文本 + 音频)、探索多模态在机器人(融合视觉 + 触觉 + 听觉)、虚拟现实(VR/AR)中的应用。高效深度学习(Efficient Deep Learning)核心进展:针对 “大模型计算成本高” 的问题,高效深度学习聚焦于 “在保证性能的前提下,降低模型的参数规模、计算量和内存占用”,让深度学习能在终端设备(手机、手表、物联网设备)上高效运行。关键技术包括模型压缩(量化、剪枝、蒸馏)、高效网络架构设计(如 MobileNet、EfficientNet,用深度可分离卷积、神经架构搜索 NAS 优化结构)、低精度计算(用 FP16/FP8/INT8 替代 FP32,提升计算速度)。未来方向:研发 “极致高效” 的模型(如参数小于 100 万但性能接近大模型)、探索 “动态网络”(根据输入数据自适应调整网络结构和计算量,如简单样本用小网络,复杂样本用大网络)、结合硬件设计 “软硬协同优化” 的深度学习系统(如专用 AI 芯片 + 高效模型的端到端优化)。可信深度学习(Trustworthy Deep Learning)核心进展:随着深度学习在医疗、金融、司法等关键领域的应用,“可信性”(包括可解释性、公平性、安全性、隐私性)成为必须解决的问题。例如公平性要求模型不歧视特定群体(如招聘 AI 不因性别 / 种族给出偏见结果);隐私性要求模型训练不泄露用户数据(如联邦学习,多机构在不共享原始数据的情况下联合训练模型);安全性要求模型抵御对抗攻击、不生成有害内容(如虚假信息、暴力文本)。未来方向:建立 “可信深度学习的统一框架”(融合可解释性、公平性、安全性、隐私性)、研发 “可验证的深度学习模型”(能证明模型决策的正确性和安全性)、制定深度学习的 “伦理和监管标准”(规范模型的研发和应用,避免滥用)。五、总结:深度学习的价值与未来深度学习通过 “层级化特征学习” 和 “端到端优化”,彻底改变了人工智能的发展轨迹,从图像识别、语音助手到自动驾驶、大语言模型,深度学习已渗透到生产生活的方方面面,成为推动 “智能化革命” 的核心技术。然而,深度学习并非 “万能钥匙”,仍面临数据依赖、可解释性差、鲁棒性不足等挑战。未来,深度学习的发展将围绕 “更通用、更高效、更可信” 展开 —— 从 “处理单一任务” 到 “具备通用智能”,从 “依赖海量数据” 到 “小数据 / 零数据学习”,从 “黑盒子” 到 “可解释、可信任”,最终实现 “让人工智能安全、高效地服务于人类” 的目标。对于学习者而言,掌握深度学习的核心原理(神经网络、反向传播、损失函数、优化器)、熟悉主流模型家族(CNN、Transformer、GAN、DRL)、理解训练流程与挑战,是入门深度学习的关键。随着技术的快速演进,持续关注前沿趋势、结合实际任务实践,才能更好地利用深度学习解决真实世界的问题。————————————————版权声明:本文为CSDN博主「晟曦毅君(◦˙▽˙◦)」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。原文链接:https://blog.csdn.net/2403_89241132/article/details/151706234
AI专题三:深度学习概述 深度学习是机器学习的重要分支,核心是通过多层神经网络(深度神经网络) 模拟人类大脑的层级化信息处理方式,从数据中自动学习特征表示,最终实现分类、回归、生成等任务。与传统机器学习依赖人工设计特征不同,深度学习的 “深度” 带来了端到端学习的能力,能处理图像、文本、语音等复杂高维数据,是当前人工智能 领域的核心技术基石。一、深度学习的核心基础从 “浅层学习” 到 “深度学习”:核心差异传统机器学习(如 SVM、决策树)属于 “浅层学习”,模型通常只有 “输入层 + 输出层”(或 1 层隐藏层),无法处理复杂数据的层级特征(如从图像的 “像素→边缘→纹理→语义”)。而深度学习通过堆叠多层隐藏层,实现特征的 “自动抽象”:浅层学习:需人工设计特征(如用 HOG 提取图像边缘)→ 模型学习映射关系;深度学习:输入原始数据(如图像像素)→ 浅层隐藏层学习低级特征(边缘、颜色)→ 深层隐藏层学习高级特征(纹理、物体部件)→ 输出层完成任务(分类、生成)。类比:如同识别一只猫 —— 人类先看到 “线条(低级特征)”,再组合成 “耳朵、眼睛(中级特征)”,最终判断为 “猫(高级特征)”,深度学习的多层网络正是模拟这一过程。深度神经网络的基本构成所有深度学习模型的基础是 “神经网络”,其核心单元是神经元(Neuron),多层神经元堆叠形成 “网络结构”,主要包括三部分:(1)神经元:网络的 “最小计算单元”神经元模拟生物神经元的 “接收 - 处理 - 输出” 逻辑,结构如下:输入:接收来自上一层的信号(如前一层神经元的输出 x1,x2,...,xn);权重与偏置:每个输入对应一个可学习的权重 w1,w2,...,wn(表示输入的重要性),另有一个偏置 b(调整输出基线);激活函数:对 “加权和 z=w1x1+w2x2+...+wnxn+b” 做非线性变换,输出 a=f(z)(引入非线性,让网络能拟合复杂函数)。关键:激活函数是神经网络能学习复杂模式的核心,若无激活函数,多层网络等价于单层线性模型(无法处理非线性问题)。常用激活函数包括:(2)网络层级:特征的 “抽象流水线”多层神经元按功能分为三类层级,协同完成特征学习:输入层(Input Layer):接收原始数据,不做计算(如图像任务输入 “像素矩阵”,文本任务输入 “词向量”);隐藏层(Hidden Layer):核心特征抽象层,层数≥1(“深度” 即指隐藏层数量),层数越多,能学习的特征越复杂(如 10 层网络可学习 “物体语义”,100 层网络可学习 “场景逻辑”);输出层(Output Layer):输出任务结果,维度由任务决定(如二分类输出 1 个值,10 分类输出 10 个值)。(3)参数与超参数:网络的 “调控旋钮”参数:网络自动学习的变量,即所有神经元的权重 w 和偏置 b,参数数量决定模型复杂度(如 ResNet-50 约有 2500 万参数);超参数:人工设定的变量,需通过 “调优” 确定,如隐藏层数量、每层神经元数、学习率、 batch size 等,直接影响模型性能。深度学习的 “核心三要素”任何深度学习模型的训练与推理,都依赖以下三个核心机制,缺一不可:(1)损失函数(Loss Function):“判断模型好坏的标尺”损失函数量化 “模型预测值” 与 “真实标签” 的差异,是模型优化的目标(最小化损失函数)。不同任务对应不同损失函数:分类任务:交叉熵损失(Cross-Entropy Loss):衡量概率分布差异,适用于二分类(Binary Cross-Entropy)和多分类(Categorical Cross-Entropy);回归任务:均方误差(MSE):MSE=N1∑i=1N(yi−y^i)2,衡量连续值预测的误差(如房价预测、温度预测);生成任务:对抗损失(Adversarial Loss):GAN 中用于让生成器生成 “逼真数据” 的损失,通过生成器与判别器的对抗优化。(2)优化器(Optimizer):“模型学习的‘导航仪’”优化器的作用是 “调整参数 w 和 b,以最小化损失函数”,核心是通过梯度下降(Gradient Descent) 实现 —— 计算损失函数对参数的梯度(方向),沿梯度反方向更新参数。传统梯度下降(全量梯度下降)计算量大,实际中常用改进版:(3)反向传播(Backpropagation):“模型学习的‘反馈机制’”反向传播是 “计算梯度、更新参数” 的核心算法,遵循 “链式法则”—— 从输出层到输入层,逐层计算损失函数对每个参数的梯度,再通过优化器更新参数。流程:前向传播(Forward Pass):输入数据通过网络,计算各层输出和最终损失 L;反向传播(Backward Pass):从输出层开始,计算 L 对输出层参数的梯度 → 隐藏层参数的梯度 → 输入层参数的梯度(链式法则);参数更新(Parameter Update):用优化器根据梯度调整参数(如 w=w−η⋅∂w∂L,η 为学习率)。关键:反向传播是深度学习能 “自主学习” 的核心 —— 没有反向传播,参数无法根据误差调整,模型无法优化。二、深度学习的核心模型家族深度学习并非单一模型,而是由多个 “模型家族” 组成,每个家族针对特定数据类型(图像、文本、序列)设计,以下是最核心的 5 类模型:卷积神经网络(CNN :Convolutional Neural Network)——“图像任务的‘王者’”CNN 是为处理 “网格结构数据”(如图像:2D 像素网格、视频:3D 时空网格)设计的模型,核心创新是卷积操作和池化操作,解决了传统 MLP 处理图像时 “参数爆炸” 和 “缺乏空间关联性” 的问题。(1)核心机制:卷积操作:用 “卷积核” 在图像上滑动,提取局部空间特征(如边缘、纹理),通过 “参数共享”(同一卷积核在全图共享参数)大幅减少参数量;池化操作:对卷积输出做 “下采样”(如最大池化、平均池化),降低特征图尺寸,减少计算量,同时增强模型对图像平移、缩放的鲁棒性;层级结构:浅层(卷积 + 池化)学习低级特征(边缘、颜色)→ 深层(卷积 + 全连接)学习高级特征(物体部件、语义)。(2)经典模型与应用:经典模型:LeNet-5(1998):首个 CNN,用于手写数字识别;AlexNet(2012):CNN 爆发的标志,用 ReLU 和 GPU 加速,ImageNet 分类准确率大幅提升;ResNet(2015):引入 “残差连接”,解决深层网络的 “梯度消失” 问题,可训练 1000 层以上网络;YOLO、Faster R-CNN:基于 CNN 的目标检测模型,实现 “实时识别图像中的物体位置”。应用场景:图像分类(如人脸识别)、目标检测(如自动驾驶识别车辆行人)、图像分割(如医学影像分割肿瘤)、图像生成(如 GAN 生成人脸)。循环神经网络(RNN:Recurrent Neural Network)——“序列数据的‘专属模型’”RNN 是为处理 “序列数据”(如文本:单词序列、语音:音频帧序列、时间序列:股票价格)设计的模型,核心创新是隐藏状态的 “记忆性”—— 当前输出不仅依赖当前输入,还依赖上一时刻的隐藏状态,能捕捉序列的 “时序关联性”。(1)核心机制:循环结构:RNN 的隐藏层包含 “循环单元”,假设时刻 t 的输入为 xt,隐藏状态为 ht,则:ht=f(Wxhxt+Whhht−1+bh)yt=Whyht+by其中 Whh 是 “循环权重”,使 ht 携带上一时刻 ht−1 的信息(记忆);局限性:传统 RNN 存在 “长期依赖问题”—— 当序列过长(如 100 个单词的句子),梯度在反向传播时会 “消失或爆炸”,无法捕捉长距离时序关联。(2)改进模型:LSTM 与 GRU为解决长期依赖问题,研究者提出了 “门控循环单元”,最常用的是 LSTM(长短期记忆网络)和 GRU(门控循环单元):LSTM:通过 “输入门、遗忘门、输出门” 控制信息的 “存入、遗忘、输出”,能有效保存长序列的关键信息(如理解 “上下文很长的句子”);GRU:简化 LSTM 的门结构(合并为 “更新门、重置门”),在保持性能的同时减少计算量。(3)应用场景:文本处理:机器翻译(如 Google 翻译的核心模型)、情感分析(判断 “这篇影评是好评还是差评”)、文本生成(自动写小说);语音处理:语音识别(将音频转为文字)、语音合成(将文字转为语音);时间序列预测:股票价格预测、天气预报、设备故障预测。Transformer 模型 ——“当前 AI 的‘核心架构’”Transformer 是 2017 年提出的模型,基于 “自注意力机制(Self-Attention)”,彻底摆脱了 RNN 的 “循环依赖”,能并行处理序列数据(RNN 需逐时刻处理,Transformer 可同时处理所有位置),且能捕捉序列的 “长距离关联”,目前已成为 NLP、CV、多模态任务的 “统一架构”。(1)核心机制:自注意力机制:让序列中每个位置的元素 “关注” 其他所有位置的元素,计算它们的相关性(权重),再加权求和得到该位置的 “注意力特征”。例如处理句子 “猫坐在垫子上”,“猫” 会关注 “垫子”(相关性高),关注 “上”(相关性低);多头注意力(Multi-Head Attention):并行执行多个自注意力,捕捉不同维度的关联(如一个头关注 “语法关联”,另一个头关注 “语义关联”),再拼接结果;编码器 - 解码器结构:Transformer 通常由 “编码器(Encoder)” 和 “解码器(Decoder)” 组成,编码器负责 “提取序列特征”,解码器负责 “生成目标序列”(如机器翻译中,编码器处理英文,解码器生成中文)。(2)经典模型与应用:BERT:基于 Transformer 编码器的预训练模型,通过 “掩码语言模型” 预训练(随机掩盖部分单词,让模型预测),在文本分类、问答等任务中刷新精度;GPT 系列:基于 Transformer 解码器的生成式模型(GPT-3、GPT-4),通过 “自回归生成”(逐词生成文本),实现对话、代码生成、逻辑推理等复杂任务;Vision Transformer(ViT):将 Transformer 应用于图像任务,把图像分割为 “图像块”(类似文本的单词),用自注意力捕捉块间关联,在图像分类任务中超越 CNN;多模态模型:如 CLIP(跨模态匹配)、DALL・E(文本生成图像),用 Transformer 统一处理文本和图像,实现 “跨模态理解与生成”。生成对抗网络(GAN :Generative Adversarial Network)——“数据生成的‘魔术师’”GAN 是一类 “生成式模型”,核心思想是 “对抗训练”—— 通过 “生成器(Generator)” 和 “判别器(Discriminator)” 的相互对抗,让生成器学会生成 “逼真的数据”(如假人脸、假图像、假文本)。(1)核心机制:生成器(G):输入随机噪声(如 100 维向量),输出 “伪造数据”(如 64×64 的人脸图像),目标是让伪造数据 “骗过判别器”;判别器(D):输入 “真实数据”(如真实人脸)或 “伪造数据”(生成器输出),输出 “数据为真实的概率”(0~1),目标是 “正确区分真实与伪造数据”;对抗过程:G 和 D 如同 “小偷与警察”——G 不断优化以骗过 D,D 不断优化以识别 G,最终达到 “纳什均衡”:G 生成的假数据与真实数据难以区分,D 的判断准确率接近 50%(随机猜测)。(2)经典模型与应用:DCGAN:用 CNN 作为 G 和 D,首次实现高质量图像生成(如生成清晰的人脸、风景);StyleGAN:能控制生成图像的 “风格”(如人脸的发型、表情、光照),可生成 “超逼真的人脸”;CycleGAN:实现 “无监督图像风格迁移”(如将 “照片转为油画”“马转为斑马”,无需配对数据);应用场景:数据增强(生成训练数据,解决数据稀缺问题)、图像修复(填补图像中的缺失区域)、超分辨率重建(将低清图像转为高清)、文本生成图像(如 DALL・E 根据文字 “一只穿着西装的猫” 生成图像)。深度强化学习(DRL:Deep Reinforcement Learning)——“决策任务的‘智能体’”DRL 是 “深度学习” 与 “强化学习(RL)” 的结合,核心是让 “智能体(Agent)” 在 “环境(Environment)” 中通过 “试错” 学习 “最优决策策略”,以最大化 “累积奖励”(如游戏得分、任务完成度)。(1)核心机制:强化学习框架:Agent 在环境中执行动作 at,环境反馈 “奖励 rt” 和 “下一状态 st+1”,Agent 的目标是学习 “策略 π(a∣s)”(给定状态 s 时选择动作 a 的概率),使累积奖励最大;深度学习的作用:用深度神经网络(如 CNN、MLP)近似 “策略 π” 或 “价值函数 V(s)”(状态 s 的未来累积奖励),解决传统 RL 无法处理的 “高维状态空间” 问题(如 Atari 游戏的 210×160 像素图像状态)。(2)经典算法与应用DQN(深度 Q 网络):用 CNN 近似 Q 函数(Q(s,a) 表示在状态 s 执行动作 a 后的未来累积奖励),首次将深度学习与强化学习结合,成功解决 Atari 26 款游戏的决策问题(如《Breakout》打砖块游戏,AI 能自主学习 “反弹球击碎砖块” 的策略)。其核心改进是 “经验回放(Experience Replay)”—— 将智能体的交互经验(s,a,r,s′)存储在回放池,随机采样训练,避免样本相关性导致的训练不稳定。PPO(近端策略优化):当前工业界最常用的 DRL 算法,通过 “clip(裁剪)” 机制限制策略更新的幅度(避免策略突变导致训练崩溃),在保持性能的同时简化实现。PPO 广泛用于机器人控制(如机械臂抓取物体)、自动驾驶(如车道保持、避障决策)、游戏 AI(如《DOTA2》《星际争霸 2》的 AI 对战)。DDPG(深度确定性策略梯度):针对 “连续动作空间”(如机器人关节角度、无人机飞行速度)设计的算法,用 “确定性策略”(给定状态输出确定动作,而非概率分布)替代传统 RL 的 “随机策略”,适用于需要精细控制的场景(如机械臂精准抓取易碎物品)。应用场景:游戏 AI:训练 AI 击败人类职业选手(如 AlphaGo 击败李世石、DeepMind 的《星际争霸 2》AI 击败职业玩家);机器人控制:工业机械臂自动化装配、服务机器人自主导航避障、仿生机器人模拟人类动作;自动驾驶:决策层(如是否变道、超车、避让行人)、控制层(如油门、刹车、方向盘角度调节);资源调度:数据中心服务器负载调度(最大化资源利用率)、电网能源分配(平衡供需与成本)。三、深度学习的训练流程与关键挑战完整训练流程:从数据到模型部署深度学习模型的训练是 “数据驱动 + 迭代优化” 的过程,通常分为以下 6 个步骤,环环相扣:(1)数据准备:“模型的‘粮食’”数据收集:根据任务场景获取原始数据(如图像分类需收集万级以上带标签的图像,NLP 任务需收集大规模文本语料),数据质量直接决定模型上限(“垃圾数据训练不出好模型”)。数据预处理:清洗噪声(如删除模糊图像、修正错误标签)、标准化 / 归一化(如将图像像素值从 [0,255] 转为 [0,1],避免数值差异影响梯度更新)、数据增强(如图像任务的旋转 / 翻转 / 裁剪、文本任务的同义词替换,扩大数据量,提升模型泛化能力)。数据划分:将数据集分为训练集(70%~80%,用于模型学习)、验证集(10%~15%,用于调优超参数、监控过拟合)、测试集(10%~15%,用于评估模型最终性能,不可用于训练)。(2)模型构建:“设计‘学习框架’”选择基础架构:根据任务类型选择合适的模型家族(如图像任务选 CNN/ViT,序列任务选 Transformer/LSTM,决策任务选 DRL)。定义网络结构:设计隐藏层数量、每层神经元 / 通道数、激活函数、正则化方式(如 Dropout、BatchNorm)。例如图像分类任务的简单 CNN 结构:“卷积层(3×3)→ BatchNorm → ReLU → 最大池化 → 卷积层 → BatchNorm → ReLU → 全连接层 → Softmax 输出”。初始化参数:对网络权重 w 和偏置 b 进行初始化(如 Xavier 初始化、He 初始化),避免初始值过大 / 过小导致梯度消失或爆炸。(3)配置训练参数:“设定‘学习规则’”选择损失函数:匹配任务类型(如分类用交叉熵损失,回归用 MSE,生成用对抗损失)。选择优化器:默认优先选 Adam(收敛快、稳定性高),大规模任务可选 SGD(配合动量,泛化性更好),序列任务可选 RMSprop。设定超参数:学习率(通常从 0.001 开始调试,过小训练慢,过大不收敛)、batch size(内存允许下越大越好,提升训练稳定性)、训练轮次(Epoch,直到验证集损失不再下降)。(4)模型训练:“迭代优化参数”前向传播:将训练集 batch 输入模型,计算各层输出和损失值 L。反向传播:通过链式法则计算损失对所有参数的梯度,用优化器更新参数(如 w=w−η⋅∇wL)。监控与调整:每训练 1 个 Epoch,用验证集评估模型性能(如准确率、MSE),若验证集性能下降(过拟合),则调整超参数(如减小学习率、增加 Dropout 比例)或停止训练(早停法)。(5)模型评估:“检验‘学习成果’”测试集评估:用测试集计算模型的关键指标(如图像分类的 Top-1/Top-5 准确率、NLP 任务的 BLEU 值、DRL 任务的平均累积奖励),评估模型泛化能力(能否处理未见过的数据)。错误分析:分析模型预测错误的样本(如分类任务中 “将猫误判为狗” 的图像),定位问题(如特征提取不足、数据分布不均),指导模型改进。(6)模型部署:“落地‘实际应用’”模型压缩:训练好的模型通常较大(如 ResNet-50 约 100MB),需通过量化(将 32 位浮点数转为 16 位 / 8 位整数)、剪枝(删除冗余参数)、蒸馏(用大模型教小模型)等方式减小体积,适配移动端 / 嵌入式设备(如手机、智能摄像头)。部署方式:通过 TensorFlow Lite、PyTorch Mobile 等框架将模型部署到终端设备(本地推理,低延迟),或部署到云端(提供 API 服务,支持大规模调用)。例如人脸识别模型部署到手机,实现 “解锁” 功能;目标检测模型部署到自动驾驶汽车,实时识别路况。深度学习的关键挑战:从理论到实践的 “拦路虎”尽管深度学习已取得巨大成功,但仍面临多个核心挑战,限制其在部分场景的应用:(1)数据依赖:“无数据,难学习”问题:深度学习是 “数据密集型” 技术,优秀模型通常需要海量标注数据(如 ImageNet 有 120 万标注图像,GPT-3 训练用了 45TB 文本数据)。对于小众领域(如罕见病医学影像、特定行业的工业检测),标注数据稀缺,模型性能难以提升。解决方向:半监督学习(用少量标注数据 + 大量无标注数据训练)、无监督学习(完全依赖无标注数据,如 GAN 的对抗训练)、迁移学习(将通用数据集上预训练的模型迁移到小众任务,减少数据需求)。(2)过拟合:“学‘死’了,不会灵活应用”问题:模型在训练集上表现优异,但在测试集上性能大幅下降,即 “死记硬背训练数据,无法泛化到新数据”。常见原因包括模型过于复杂(参数过多)、训练数据量不足、数据增强不够。解决方向:正则化(如 L1/L2 正则化惩罚大权重、Dropout 随机关闭部分神经元)、早停法(验证集损失上升时停止训练)、数据增强(扩大数据多样性)、简化模型结构(减少隐藏层 / 神经元数量)。(3)可解释性差:“黑盒子,不知道为什么对 / 错”问题:深度学习模型的决策过程难以解释(如 CNN 判断 “这是猫”,但无法说明是 “耳朵” 还是 “毛发” 起了关键作用;GPT 生成文本,无法解释逻辑链)。在医疗(如疾病诊断)、司法(如风险评估)等对 “可解释性” 要求高的领域,应用受限。解决方向:可解释 AI(XAI)技术,如特征可视化(展示 CNN 各层学习的特征)、注意力分析(如 Transformer 的注意力热力图,显示模型关注的文本 / 图像区域)、模型蒸馏(用简单模型(如决策树)解释复杂模型的决策)。(4)计算成本高:“训练一次,烧钱又耗时”问题:深层模型(如 GPT-4、大参数 ViT)的训练需要大规模 GPU/TPU 集群,计算成本极高(如 GPT-3 训练成本约 4600 万美元),且训练周期长(通常需要数周甚至数月),普通研究者和企业难以承担。解决方向:模型压缩(减少参数和计算量)、高效训练框架(如 Megatron-LM、DeepSpeed,支持模型并行和混合精度训练)、硬件优化(如专用 AI 芯片,提升计算效率)。(5)鲁棒性差:“微小干扰,就能‘骗’错模型”问题:深度学习模型对 “对抗样本”(在原始数据中添加人眼不可见的微小噪声)极为敏感。例如在 “猫” 的图像上添加细微噪声,模型会误判为 “飞机”;在自动驾驶的路况图像中添加干扰,模型会忽略行人。解决方向:对抗训练(在训练中加入对抗样本,提升模型抗干扰能力)、鲁棒性正则化(约束模型对微小扰动不敏感)、输入验证(检测并过滤对抗样本)。四、深度学习的前沿趋势与未来方向随着技术不断迭代,深度学习正从 “单一任务” 向 “通用智能” 演进,以下是当前最值得关注的 4 个前沿趋势:大语言模型(LLM)与通用人工智能(AGI)核心进展:以 GPT 系列、LLaMA、文心一言、通义千问为代表的大语言模型,通过万亿级参数和海量文本训练,具备了上下文理解、逻辑推理、多轮对话、代码生成、跨领域知识问答等能力,成为 “通用智能” 的重要载体。例如 GPT-4 能理解图像内容、解决复杂数学题、撰写专业论文,甚至参与创意设计。未来方向:提升模型的 “认知能力”(如因果推理、常识理解)、“多模态能力”(融合文本、图像、音频、视频)、“高效性”(降低大模型的训练和推理成本),推动 LLM 从 “专用工具” 向 “通用助手” 演进,逐步接近 AGI(具备人类级别的学习和适应能力)。多模态学习(Multimodal Learning)核心进展:传统深度学习模型多处理单一模态数据(如 CNN 处理图像、Transformer 处理文本),而多模态学习旨在让模型同时理解和处理多种模态数据(文本 + 图像 + 音频 + 视频),模拟人类 “多感官协同认知” 的方式。例如 CLIP(Contrastive Language-Image Pre-training)能实现 “文本 - 图像跨模态匹配”(输入 “红色的猫”,自动找到对应的图像);DALL・E、MidJourney 能通过文本生成高质量图像;GPT-4V 能分析图像内容并生成文字描述。未来方向:解决多模态数据的 “模态鸿沟”(不同模态数据的表示差异大,如文本是离散符号,图像是连续像素)、提升多模态模型的 “跨模态生成能力”(如根据音频生成视频、根据图像生成文本 + 音频)、探索多模态在机器人(融合视觉 + 触觉 + 听觉)、虚拟现实(VR/AR)中的应用。高效深度学习(Efficient Deep Learning)核心进展:针对 “大模型计算成本高” 的问题,高效深度学习聚焦于 “在保证性能的前提下,降低模型的参数规模、计算量和内存占用”,让深度学习能在终端设备(手机、手表、物联网设备)上高效运行。关键技术包括模型压缩(量化、剪枝、蒸馏)、高效网络架构设计(如 MobileNet、EfficientNet,用深度可分离卷积、神经架构搜索 NAS 优化结构)、低精度计算(用 FP16/FP8/INT8 替代 FP32,提升计算速度)。未来方向:研发 “极致高效” 的模型(如参数小于 100 万但性能接近大模型)、探索 “动态网络”(根据输入数据自适应调整网络结构和计算量,如简单样本用小网络,复杂样本用大网络)、结合硬件设计 “软硬协同优化” 的深度学习系统(如专用 AI 芯片 + 高效模型的端到端优化)。可信深度学习(Trustworthy Deep Learning)核心进展:随着深度学习在医疗、金融、司法等关键领域的应用,“可信性”(包括可解释性、公平性、安全性、隐私性)成为必须解决的问题。例如公平性要求模型不歧视特定群体(如招聘 AI 不因性别 / 种族给出偏见结果);隐私性要求模型训练不泄露用户数据(如联邦学习,多机构在不共享原始数据的情况下联合训练模型);安全性要求模型抵御对抗攻击、不生成有害内容(如虚假信息、暴力文本)。未来方向:建立 “可信深度学习的统一框架”(融合可解释性、公平性、安全性、隐私性)、研发 “可验证的深度学习模型”(能证明模型决策的正确性和安全性)、制定深度学习的 “伦理和监管标准”(规范模型的研发和应用,避免滥用)。五、总结:深度学习的价值与未来深度学习通过 “层级化特征学习” 和 “端到端优化”,彻底改变了人工智能的发展轨迹,从图像识别、语音助手到自动驾驶、大语言模型,深度学习已渗透到生产生活的方方面面,成为推动 “智能化革命” 的核心技术。然而,深度学习并非 “万能钥匙”,仍面临数据依赖、可解释性差、鲁棒性不足等挑战。未来,深度学习的发展将围绕 “更通用、更高效、更可信” 展开 —— 从 “处理单一任务” 到 “具备通用智能”,从 “依赖海量数据” 到 “小数据 / 零数据学习”,从 “黑盒子” 到 “可解释、可信任”,最终实现 “让人工智能安全、高效地服务于人类” 的目标。对于学习者而言,掌握深度学习的核心原理(神经网络、反向传播、损失函数、优化器)、熟悉主流模型家族(CNN、Transformer、GAN、DRL)、理解训练流程与挑战,是入门深度学习的关键。随着技术的快速演进,持续关注前沿趋势、结合实际任务实践,才能更好地利用深度学习解决真实世界的问题。————————————————版权声明:本文为CSDN博主「晟曦毅君(◦˙▽˙◦)」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。原文链接:https://blog.csdn.net/2403_89241132/article/details/151706234 -
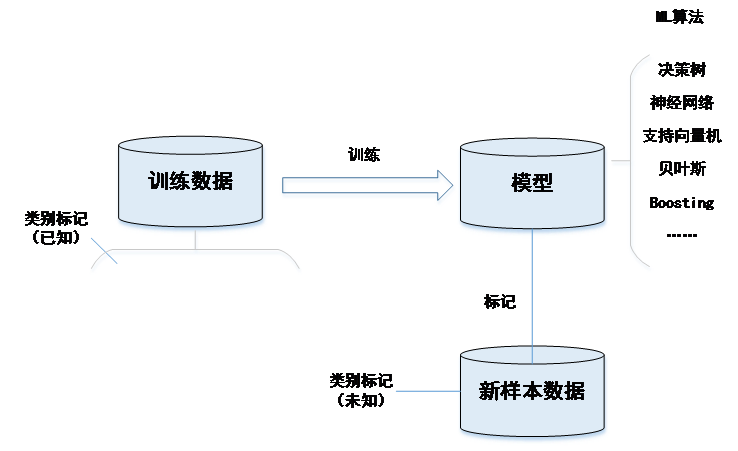
AI专题二:机器学习概述 01 机器学习概述随着大数据的发展,机器学习进入了最美好的时代,通过“涟漪效应”逐步迭代,大数据推动机器学习真正实现落地。接下来,我们从大数据讲起,扩展到机器学习的发展和大数据生态。理解大数据数据源越多越精确,越能无限逼近事实和真相,越能获得更深邃的智慧和洞察,这就是大数据的价值。总之,大数据的存储、处理需要云计算基础设施的支撑,云计算需要海量数据的处理能力证明自身的价值;人工智能技术的进步离不开云计算能力的不断增长,云计算让人工智能服务无处不在、触手可及;大数据的价值发现需要高效的人工智能方法,人工智能的自我学习需要海量数据的输入。随着大数据和人工智能的深度融合,高度数据化的AI(人工智能)和高度智能化的DT(大数据技术)并存将是时代新常态。机器学习发展过程机器学习(Machine Learning,ML)是人工智能的核心,涉及统计学、系统辨识、逼近理论、神经网络、优化理论、计算机科学、脑科学等诸多领域,研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构从而不断改善自身的性能。相对于传统机器学习利用经验改善系统自身的性能,现在的机器学习更多是利用数据改善系统自身的性能。基于数据的机器学习是现代智能技术中的重要方法之一,它从观测数据(样本)出发寻找规律,利用这些规律对未来数据或无法观测的数据进行预测。机器学习的发展过程分为三个阶段。第一阶段,逻辑推理期(1956年—1960年),以自动定理证明系统为代表,如西蒙与纽厄尔的Logic Theorist系统,但是逻辑推理存在局限性。第二阶段,知识期(1970年—1980年),以专家系统为代表,如费根·鲍姆等人的DENDRAL系统,存在要总结出知识、很难“教”给系统的问题。第三阶段,学习期(1990年至今),机器学习是作为“突破知识工程瓶颈”之利器出现的。在20世纪90年代中后期,人类发现自己淹没在数据的海洋中,机器学习也从利用经验改善性能转变为利用数据改善性能。这阶段,人们对机器学习的需求也日益迫切。典型的机器学习过程是以算法、数据的形式,利用已知数据标注未知数据的过程。如图1-3所示,首先需要将数据分为训练集和样本集(训练集的类别标记已知),通过选择合适的机器学习算法,将训练数据训练成模型,通过模型对新样本集进行类别标记。▲图1-3 典型的机器学习过程使用机器学习解决实际问题需要具体问题具体分析,根据场景进行算法设计。大数据生态环境在大数据生态环境中,包括数据采集、数据存储、数据预处理、特征处理、模型构建、数据可视化等,通过分类、聚类、回归、协同过滤、关联规则等机器学习方法,深入挖掘数据价值,并实现数据生态的良性循环。如同海量数据存储在云计算设备中,水存储在江河湖海之中;数据采集可以理解为从各种渠道聚集水进入江河湖海;数据预处理可以理解为水之蒸发、过滤、提取形成天上云的过程;云进行特征的自我变化和重组,最终形成可以转变的状态;基于机器学习的模型构建,即可以理解为不同天气状况下的云转变成雨水、雪花、冰雹、寒霜、雾气的变化过程。水存储在江河湖海中,经过蒸发、过滤、提取形成云,云自我变化、重组,而在不同天气下转变成雨水、雪花、冰雹、寒霜、雾气过程的可视化观察,可以理解为人对自然把握和发现的过程。数据流转生态如图1-4所示。▲图1-4 数据流转生态可以简单抽象一下,云转换成雨水、雪花、冰雹、寒霜、雾气的过程就是分类的过程,云按照任何一种变化(如雨水)汇集的过程就是聚类的过程。根据历史雨水的情况,预测即将降雨的情况就是回归过程。在某种气候条件下,雨水和雪花会并存,产生“雨夹雪”的天气情况,这就是关联过程。根据对雨水、雪花、冰雹、寒霜、雾气的喜好程度,选择观察自己喜好的天气,就是协同过滤的过程。导致天气变化的因素很多(很多和雾霾有关),处理起来有难度,在不丧失主要特征的情况,去掉部分特征,这个过程就是特征降维的过程。通过模拟人类大脑的神经连接结构,将各种和雾霾相关的天气特征转换到具有语义特征的新特征空间,自动学习得到层次化的特征表示,从而提高雾霾的预报性能,这就是深度学习过程。02 机器学习算法根据学习方法不同可以将机器学习分为传统机器学习、深度学习、其他机器学习。参考Kaggle机器学习大调查,数据科学中更常见的还是传统经典的机器学习算法,简单的线性与非线性分类器是数据科学中最常见的算法,功能强大的集成方法也十分受欢迎。最常用的数据科学方法是逻辑回归,而国家安全领域则更为频繁使用神经网络。总的来说,目前神经网络模型的使用频率要高于支持向量机,这可能是因为近来多层感知机要比使用带核函数的SVM有更加广泛的表现。传统机器学习传统机器学习从一些观测(训练)样本出发,试图发现不能通过原理分析获得的规律,实现对未来数据行为或趋势的准确预测。传统机器学习平衡了学习结果的有效性与学习模型的可解释性,为解决有限样本的学习问题提供了一种框架,主要用于有限样本情况下的模式分类、回归分析、概率密度估计等。传统机器学习方法的重要理论基础之一是统计学,在自然语言处理、语音识别、图像识别、信息检索和生物信息等许多计算机领域获得了广泛应用。相关算法包括逻辑回归、隐马尔可夫方法、支持向量机方法、K近邻方法、三层人工神经网络方法、Adaboost算法、贝叶斯方法以及决策树方法等。(1)分类方法分类方法是机器学习领域使用最广泛的技术之一。分类是依据历史数据形成刻画事物特征的类标识,进而预测未来数据的归类情况。目的是学会一个分类函数或分类模型(也称作分类器),该模型能把数据集中的事物映射到给定类别中的某一个类。在分类模型中,我们期望根据一组特征来判断类别,这些特征代表了物体、事件或上下文相关的属性。(2)聚类方法聚类是指将物理或抽象的集合分组成为由类似的对象组成的多个类的过程。由聚类生成的簇是一组数据对象的集合,这些对象与同一个簇中的对象彼此相似,与其他簇中的对象相异。在许多应用中,一个簇中的数据对象可作为一个整体来对待。在机器学习中,聚类是一种无监督的学习,在事先不知道数据分类的情况下,根据数据之间的相似程度进行划分,目的是使同类别的数据对象之间的差别尽量小,不同类别的数据对象之间的差别尽量大。通常使用KMeans进行聚类,聚类算法LDA是一个在文本建模中很著名的模型,类似于SVD、PLSA等模型,可以用于浅层语义分析,在文本语义分析中是一个很有用的模型。(3)回归方法回归是根据已有数值(行为)预测未知数值(行为)的过程,与分类模式分析不同,预测分析更侧重于“量化”。一般认为,使用分类方法预测分类标号(或离散值),使用回归方法预测连续或有序值。如用户对这个电影的评分是多少?用户明天使用某个产品(手机)的概率有多大?常见的预测模型基于输入的用户信息,通过模型的训练学习,找出数据的规律和趋势,以确定未来目标数据的预测值。(4)关联规则关联规则是指发现数据中大量项集之间有趣的关联或相关联系。挖掘关联规则的步骤包括:① 找出所有频繁项集,这些项集出现的频繁性至少和预定义的最小支持计数一样;② 由频繁项集产生强关联规则,这些规则必须满足最小支持度和最小置信度。随着大量数据不停地收集和存储,许多业界人士对从数据集中挖掘关联规则越来越感兴趣。从大量商务事务记录中发现有趣的关联关系,可以帮助制定许多商务决策。通过关联分析发现经常出现的事物、行为、现象,挖掘场景(时间、地点、用户性别等)与用户使用业务的关联关系,从而实现因时、因地、因人的个性化推送。(5)协同过滤随着互联网上的内容逐渐增多,人们每天接收的信息远远超出人类的信息处理能力,信息过载日益严重,因此信息过滤系统应运而生。信息过滤系统基于关键词,过滤掉用户不想看的内容,只给用户展示感兴趣的内容,大大地减少了用户筛选信息的成本。协同过滤起源于信息过滤,与信息过滤不同,协同过滤分析用户的兴趣并构建用户兴趣模型,在用户群中找到指定用户的相似兴趣用户,综合这些相似用户对某一信息的评价,系统预测该指定用户对此信息的喜好程度,再根据用户的喜好程度给用户展示内容。(6)特征降维特征降维自20世纪70年代以来获得了广泛的研究,尤其是近几年以来,在文本分析、图像检索、消费者关系管理等应用中,数据的实例数目和特征数据都急剧增加,这种数据的海量性使得大量机器学习算法在可测量性和学习性能方面产生严重问题。例如,具有成百上千特征的高维数据集,会包含大量的无关信息和冗余信息,这些信息可能极大地降低学习算法的性能。因此,当面临高维数据时,特征降维对于机器学习任务显得十分重要。特征降维从初始高维特征集中选出低维特征集合,以便根据一定的评估准则最优化、缩小特征空间的过程,通常作为机器学习的预处理步骤。大量研究实践证明,特征降维能有效地消除无关和冗余特征,提高挖掘任务的效率,改善预测精确性等学习性能,增强学习结果的易理解性。’深度学习深度学习又称为深度神经网络(指层数超过3层的神经网络),是建立深层结构模型的学习方法。深度学习作为机器学习研究中的一个新兴领域,由Hinton等人于2006年提出。深度学习源于多层神经网络,其实质是给出了一种将特征表示和学习合二为一的方式。深度学习的特点是放弃了可解释性,单纯追求学习的有效性。经过多年的摸索尝试和研究,已经产生了诸多深度神经网络的模型,包括深度置信网络、卷积神经网络、受限玻尔兹曼机和循环神经网络等。其中卷积神经网络、循环神经网络是两类典型的模型。卷积神经网络常应用于空间性分布数据;循环神经网络在神经网络中引入了记忆和反馈,常应用于时间性分布数据。深度学习框架一般包含主流的神经网络算法模型,提供稳定的深度学习API,支持训练模型在服务器和GPU、TPU间的分布式学习,部分框架还具备在包括移动设备、云平台在内的多种平台上运行的移植能力,从而为深度学习算法带来了前所未有的运行速度和实用性。目前主流的开源算法框架有TensorFlow、Caffe/Caffe2、CNTK、MXNet、PaddlePaddle、Torch/PyTorch、Theano等。深度学习是机器学习研究中的一个分支领域,其动机在于建立、模拟人脑进行分析学习的神经网络,它模仿人脑的机制来解释数据,例如图像、声音和文本。从技术上来看,深度学习就是“很多层”的神经网络,神经网络实质上是多层函数嵌套形成的数据模型。伴随着云计算、大数据时代的到来,计算能力的大幅提升,深度学习模型在计算机视觉、自然语言处理、语音识别等众多领域都取得了较大的成功其他机器学习此外,机器学习的常见算法还包括迁移学习、主动学习和演化学习等。(1)迁移学习迁移学习是指当在某些领域无法取得足够多的数据进行模型训练时,利用另一领域的数据获得的关系进行学习。迁移学习可以把已训练好的模型参数迁移到新的模型,指导新模型训练,更有效地学习底层规则、减少数据量。目前的迁移学习技术主要在变量有限的小规模应用中使用,如基于传感器网络的定位、文字分类和图像分类等。未来迁移学习将被广泛应用于解决更有挑战性的问题,如视频分类、社交网络分析、逻辑推理等。(2)主动学习主动学习通过一定的算法查询最有用的未标记样本,并交由专家进行标记,然后用查询到的样本训练分类模型来提高模型的精度。主动学习能够选择性地获取知识,通过较少的训练样本获得高性能的模型,最常用的策略是通过不确定性准则和差异性准则选取有效的样本。(3)演化学习演化学习基于演化算法提供的优化工具设计机器学习算法,针对机器学习任务中存在大量的复杂优化问题,应用于分类、聚类、规则发现、特征选择等机器学习与数据挖掘问题。演化算法通常维护一个解的集合,并通过启发式算子来从现有的解产生新解,并通过挑选更好的解进入下一次循环,不断提高解的质量。演化算法包括粒子群优化算法、多目标演化算法等。03 机器学习分类机器学习按照学习形式进行分类,可分为监督学习、无监督学习、半监督学习、强化学习等。区别在于,监督学习需要提供标注的样本集,无监督学习不需要提供标注的样本集,半监督学习需要提供少量标注的样本,而强化学习需要反馈机制。监督学习监督学习是利用已标记的有限训练数据集,通过某种学习策略/方法建立一个模型,实现对新数据/实例的标记(分类)/映射。监督学习要求训练样本的分类标签已知,分类标签的精确度越高,样本越具有代表性,学习模型的准确度越高。监督学习在自然语言处理、信息检索、文本挖掘、手写体辨识、垃圾邮件侦测等领域获得了广泛应用。监督学习的输入是标注分类标签的样本集,通俗地说,就是给定了一组标准答案。监督学习从这样给定了分类标签的样本集中学习出一个函数,当新的数据到来时,就可以根据这个函数预测新数据的分类标签。监督学习过程如图1-5所示。▲图1-5 监督学习流程图在监督学习下,输入数据被称为“训练数据”,每组训练数据有一个明确的标识或结果,如对反垃圾邮件系统中的“垃圾邮件”“非垃圾邮件”分类等。在建立预测模型的时候,监督学习建立一个学习过程,将预测结果与“训练数据”的实际结果进行比较,不断调整预测模型,直到模型的预测结果达到一个预期的准确率。最典型的监督学习算法包括回归和分类等。无监督学习无监督学习是利用无标记的有限数据描述隐藏在未标记数据中的结构/规律。无监督学习不需要训练样本和人工标注数据,便于压缩数据存储、减少计算量、提升算法速度,还可以避免正负样本偏移引起的分类错误问题,主要用于经济预测、异常检测、数据挖掘、图像处理、模式识别等领域,例如组织大型计算机集群、社交网络分析、市场分割、天文数据分析等。无监督学习与监督学习相比,样本集中没有预先标注好的分类标签,即没有预先给定的标准答案。它没有告诉计算机怎么做,而是让计算机自己去学习如何对数据进行分类,然后对那些正确分类行为采取某种形式的激励。在无监督学习中,数据并不被特别标识,学习模型是为了推断出数据的一些内在结构。常见的应用场景包括关联规则的学习以及聚类等。常见算法包括Apriori算法、KMeans算法、随机森林(random forest)、主成分分析(principal component analysis)等。半监督学习半监督学习介于监督学习与无监督学习之间,其主要解决的问题是利用少量的标注样本和大量的未标注样本进行训练和分类,从而达到减少标注代价、提高学习能力的目的。在此学习方式下,输入数据部分被标识,部分没有被标识,这种学习模型可以用来进行预测,但是该模型首先需要学习数据的内在结构以便合理地组织数据进行预测。应用场景包括分类和回归,算法包括一些对常用监督学习算法的延伸,这些算法首先试图对未标识数据进行建模,在此基础上再对标识的数据进行预测。如图论推理(graph inference)算法或者拉普拉斯支持向量机(Laplacian SVM)等。强化学习强化学习是智能系统从环境到行为映射的学习,以使强化信号函数值最大。由于外部环境提供的信息很少,强化学习系统必须靠自身的经历进行学习。强化学习的目标是学习从环境状态到行为的映射,使得智能体选择的行为能够获得环境的最大奖赏,使得外部环境对学习系统在某种意义下的评价为最佳。其在机器人控制、无人驾驶、下棋、工业控制等领域获得成功应用。在这种学习模式下,输入数据作为对模型的反馈,不像监督模型那样,输入数据仅仅是作为一个检查模型对错的方式。在强化学习下,输入数据直接反馈到模型,模型必须对此立刻做出调整。常见的应用场景包括动态系统以及机器人控制等。常见算法包括Q-Learning以及时间差学习(temporal difference learning)。04 机器学习综合应用机器学习已经“无处不在”,应用遍及人工智能的各个领域,包括数据挖掘、计算机视觉、自然语言处理、语音和手写识别、生物特征识别、搜索引擎、医学诊断、信用卡欺诈检测、证券市场分析、汽车自动驾驶、军事决策等。下面我们从异常检测、用户画像、广告点击率预估、企业征信大数据应用、智慧交通大数据应用等方面介绍大数据的综合应用。异常检测异常是指某个数据对象由于测量、收集或自然变异等原因变得不同于正常的数据对象的场景,找出异常的过程,称为异常检测。根据异常的特征,可以将异常分为以下三类:点异常、上下文异常、集合异常。异常检测的训练样本都是非异常样本,假设这些样本的特征服从高斯分布,在此基础上估计出一个概率模型,用该模型估计待测样本属于非异常样本的可能性。异常检测步骤包括数据准备、数据分组、异常评估、异常输出等步骤。用户画像用户画像的核心工作就是给用户打标签,标签通常是人为规定的高度精炼的特征标识,如年龄、性别、地域、兴趣等。由这些标签集合能抽象出一个用户的信息全貌,每个标签分别描述了该用户的一个维度,各个维度相互联系,共同构成对用户的整体描述。在产品的运营和优化中,根据用户画像能够深入理解用户需求,从而设计出更适合用户的产品,提升用户体验。使用某新闻App用户行为数据构建用户画像的流程和一些常用的标签体系实践,详见干货请收好:终于有人把用户画像的流程、方法讲明白了。广告点击率预估互联网广告是互联网公司主要的盈利手段,互联网广告交易的双方是广告主和媒体。为自己的产品投放广告并为广告付费;媒体是有流量的公司,如各大门户网站、各种论坛,它们提供广告的展示平台,并收取广告费。广告点击率(Click Through Rate,CTR)是指广告的点击到达率,即广告的实际点击次数除以广告的展现量。在实际应用中,我们从广告的海量历史展现点击日志中提取训练样本,构建特征并训练CTR模型,评估各方面因素对点击率的影响。当有新的广告位请求到达时,就可以用训练好的模型,根据广告交易平台传过来的相关特征预估这次展示中各个广告的点击概率,结合广告出价计算得到的广告点击收益,从而选出收益最高的广告向广告交易平台出价。企业征信大数据应用征信是指为信用活动提供信用信息服务,通过依法采集、整理、保存、加工企业、事业单位等组织的信用信息和个人的信用信息,并提供给信息使用者。征信是由征信机构、信息提供方、信息使用方、信息主体四部分组成,综合起来,形成了一个整体的征信行业的产业链。征信机构向信息提供方采集征信相关数据,信息使用方获得信息主体的授权以后,可以向征信机构索取该信息主体的征信数据,从征信机构获得征信产品,针对企业来说,是由该企业的各种维度数据构成的征信报告。智慧交通大数据应用智慧交通大数据应用是以物联网、云计算、大数据等新一代信息技术,结合人工智能、机器学习、数据挖掘、交通科学等理论与工具,建立起的一套交通运输领域全面感知、深度融合、主动服务、科学决策的动态实时信息服务体系。基于人工智能和大数据技术的叠加效应,结合交通行业的专家知识库建立交通数据模型,解决城市交通问题,是交通大数据应用的首要任务。交通大数据模型主要分为城市人群时空图谱、交通运行状况感知与分析、交通专项数字化运营和监管、交通安全分析与预警等几大类https://cloud.tencent.com/developer/article/1417894
-
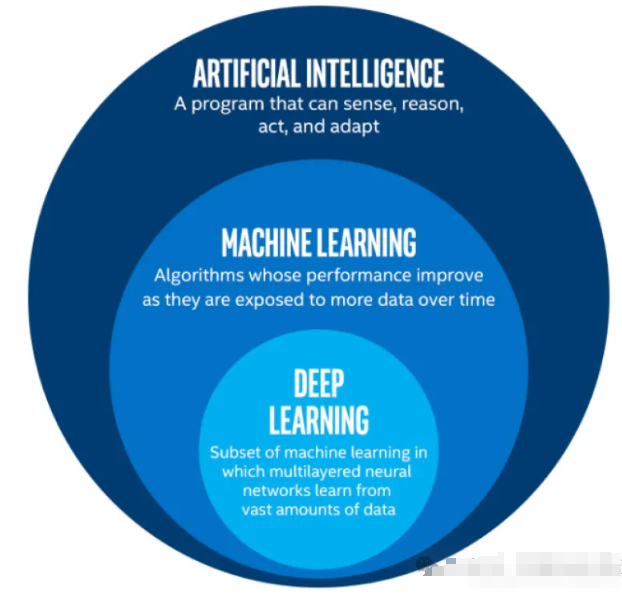
AI专题一:人工智能、机器学习、深度学习 一 概念及定义通俗来说,人工智能(AI)就是让计算机像人类一样思考、学习和做出决策。通过利用各种技术(如机器学习、深度学习、专家系统等),人工智能系统可以处理和分析大量数据,自主地学习和优化算法,从而完成各种复杂的任务。人工智能的应用非常广泛,包括但不限于语音识别、图像识别、自然语言处理、智能推荐、智能客服等。具体的,从技术层面来看(如下图),现在所说的人工智能技术基本上就是机器学习(含深度学习)方面的技术。机器学习、深度学习是人工智能的重要组成。机器学习(ML)是让计算机通过算法自动从数据中学习规律和模式,机器学习常见的任务有分类任务(如通过逻辑回归模型 判断邮件是否为垃圾邮件类)、回归预测任务(线性回归模型预测股价)等等。深度学习(DL)是机器学习的一个子方向,是当下的热门,它实现的功能和机器学习差不多,区别在于深度学习是通过搭建深层的神经网络模型 以处理任务,主要任务有如深度神经网络模型回归预测股价 、 CNN做图像分类的任务,以及最近特别火爆的大模型内容生成。人工智能(AI):目标是“智能”定义:让机器完成通常需要人类智能才能胜任的任务。根据AI的能力范围和智能化程度,可以将人工智能分为ANI、AGI和ASI三个等级。ANI(弱人工智能)主要被编程以执行单一任务,它通常只能针对特定领域或任务展现出类似人类智能的能力。例如,手机地图导航、网购产品推荐等都是ANI的典型应用。AGI(通用人工智能)则是在不特定编码知识与应用区域的情况下,应对多种甚至泛化问题的人工智能技术。它拥有推理、计划、解决问题、抽象思考、快速学习和从经验中学习的能力。AGI更像是无所不能的计算机,能够像人类一样应对多种任务和环境。ASI(超人工智能)相较AGI,不仅要求具备人类某些能力,还要能够独立思考并解决问题。ASI不仅在智能化程度上超越了AGI,还在应用范围上有所扩展,能够应对更加复杂和多样化的任务。人工智能包括自然语言处理(NLP)、计算机视觉(CV)、机器学习、深度学习、数据挖掘、机器人技术等分支。这些分支在处理不同类型的数据和任务时各有优势。例如,自然语言处理(NLP)主要关注于自然语言的理解和生成,计算机视觉(CV)则关注于图像和视频的识别和理解,机器学习和深度学习则通过训练数据来让计算机自主地进行决策和预测,数据挖掘则从大量数据中挖掘出有用的信息,机器人技术则利用AI技术来构建能够执行各种任务的自动化系统。实现方式不止一种:基于规则的系统(早期AI):程序员手动编写“如果…就…”的逻辑。例如:国际象棋程序通过预设策略下棋。机器学习(现代主流):让机器从大量例子中自己总结规律。进化算法、专家系统、模糊逻辑等:其他非主流但有效的AI方法。 📌 关键点:AI 是目标,不是技术。就像“飞行”是目标,而飞机、火箭、热气球是不同实现方式。机器学习(ML):让机器“从经验中学习”核心思想: 不直接告诉机器怎么做,而是给它一堆输入-输出示例(比如1000张猫狗照片及其标签),让它自动找出映射规律。常用算法:线性回归、决策树、支持向量机(SVM)、K均值聚类等。📌 关键点:ML 的本质是函数逼近——找到一个函数 f,使得 f(输入) ≈ 输出。深度学习(DL):用“深度神经网络”自动提取特征传统机器学习往往需要人工设计特征(比如“猫有尖耳朵、胡须”),而深度学习能自动从原始数据中逐层提取特征。核心技术:深度神经网络(DNN),尤其是:卷积神经网络(CNN):擅长处理图像循环神经网络(RNN)/Transformer:擅长处理文本和序列生成对抗网络(GAN):用于生成新内容(如AI绘画)为什么叫“深度”? 因为网络包含多个隐藏层(有时上百层),每一层都对数据进行一次抽象。例如:第1层识别边缘第2层组合成纹理第3层识别眼睛、鼻子最后层判断“这是一张人脸” 📌 关键点:DL 是 ML 的“自动化升级版”——连特征工程都省了,但需要海量数据和强大算力。二 AI和ML 区别机器学习(ML)是人工智能(AI)的一个特定分支。与 AI 相比,机器学习的范围和重点有限。AI 还包括一些机器学习范围之外的策略和技术。以下是两者之间的一些关键区别。目标任何 AI 系统的目标都是让机器高效地完成复杂的人类任务。此类任务可能涉及学习、解决问题和模式识别。另一方面,机器学习的目标是让机器分析大量数据。机器将使用统计模型来识别数据中的模式并生成结果。结果具有相关的正确概率或可信度。方法AI 领域包括用于解决各种问题的各种方法。这些方法包括遗传算法、神经网络、深度学习、搜索算法、基于规则的系统和机器学习本身。在机器学习中,方法分为两大类:有监督学习和无监督学习。有监督机器学习算法使用标有 input 和 output 的数据值来解决问题。无监督学习更具探索性,它试图在未标记的数据中发现隐藏的模式。 实施构建机器学习解决方案的过程通常涉及两项任务:选择并准备训练数据集选择先前存在的机器学习策略或模型,例如线性回归或决策树数据科学家选择重要的数据特征并将其输入到模型中进行训练。他们通过更新的数据和错误检查来不断完善数据集。数据的质量和多样性提高了机器学习模型的准确性。 构建 AI 产品通常是一个更为复杂的过程,因此许多人选择预先构建的 AI 解决方案来实现他们的目标。这些 AI 解决方案通常是经过多年研究后开发的,开发人员可以通过 API 将其与产品和服务集成。要求机器学习解决方案需要使用包含数百个数据点的数据集进行训练,还需要足够的计算能力才能运行。根据您的应用程序和用例,单个服务器实例或小型服务器集群可能就足够了。其他智能系统可能有不同的基础设施要求,这取决于您想要完成的任务和所使用的计算分析方法。高计算用例需要数千台机器协同工作才能实现复杂的目标。但是,请务必注意,预先构建的 AI 和机器学习函数都可用。您可以通过 API 将它们集成到您的应用程序中,而无需额外资源。三 ML和DL 区别机器学习包括传统的机器学习与深度学习接下来我们具体介绍下机器学习(传统机器学习)与深度学习的区别及联系!学习方法机器学习:基于数据和算法,通过训练数据来调整模型参数,从而实现预测和分类等功能。常见的机器学习算法 包括线性回归、决策树、支持向量机等。深度学习:使用神经网络模型,通过反向传播算法和梯度下降优化技术来调整网络权重和参数。常见的深度学习模型 包括卷积神经网络(CNN)、循环神经网络(RNN)、Transformer等。数据需求机器学习:需要足够的数据来训练模型,但并不一定需要全部数据。可以通过特征选择、降维等技术来处理大规模数据集 。深度学习:需要大量的数据进行训练,尤其是对于复杂的任务和模型。通常需要使用无监督学习进行预训练,以减少对大规模数据集的需求。模型的复杂性机器学习:模型通常较为简单,主要是线性模型和统计模型等。模型的复杂度取决于所选择的算法和特征工程。深度学习:模型通常非常复杂,具有大量的神经元和层数。通过逐层传递信息,深度学习模型能够自动提取和抽象出有用的特征。优缺点机器学习:优点在于其预测准确度高,适用于各种类型的数据和任务;缺点是需要足够的数据和特征工程,对于复杂任务的建模能力有限。深度学习:优点在于其强大的表示能力和泛化能力,能够处理复杂的非线性问题;缺点是计算量大、训练时间长,对于大规模数据集的需求较高。应用领域机器学习:应用领域包括推荐系统、数据挖掘等。例如,使用支持向量机进行文本分类或使用决策树进行预测。深度学习:应用领域主要为图像识别、语音识别、自然语言处理等。例如,使用卷积神经网络进行图像分类或使用循环神经网络进行文本生成。两者区别(总结)模型层面:机器学习是基于传统模型(统计学习模型、KNN等等);深度学习则使用神经网络模型进行学习和预测。应用方面:机器学习适用于各种类型的数据和任务;深度学习则更适用于处理复杂的非线性问题。复杂度:深度学习的模型通常比机器学习模型更加复杂,需要更多的计算资源和训练时间。可解释性:机器学习:模型通常较为简单,因此具有一定的可解释性。例如,决策树和线性回归模型可以通过规则和系数来解释。深度学习:由于模型的复杂性和黑箱性质,通常难以解释。这使得深度学习在某些需要解释的场景中受到限制。鲁棒性:机器学习:一些传统的机器学习算法可能对噪声和异常值敏感。深度学习:通过强大的表示能力和鲁棒的网络结构,大数据加持的深度学习模型通常具有较好的鲁棒性,能够更好地处理噪声和异常值。数据标注需求:机器学习:许多传统的有监督机器学习算法需要一些标注数据,主要视模型复杂度具体来看,一些简单模型样本需求并不高,几百个也可以支持。深度学习:深度学习模型通常需要大量的标注数据,尤其是对于复杂的任务。然而,深度学习无监督学习和其他技术也可以减少对大量标注数据的需求。部分内容来源于:https://blog.csdn.net/python122_/article/details/138791308
-
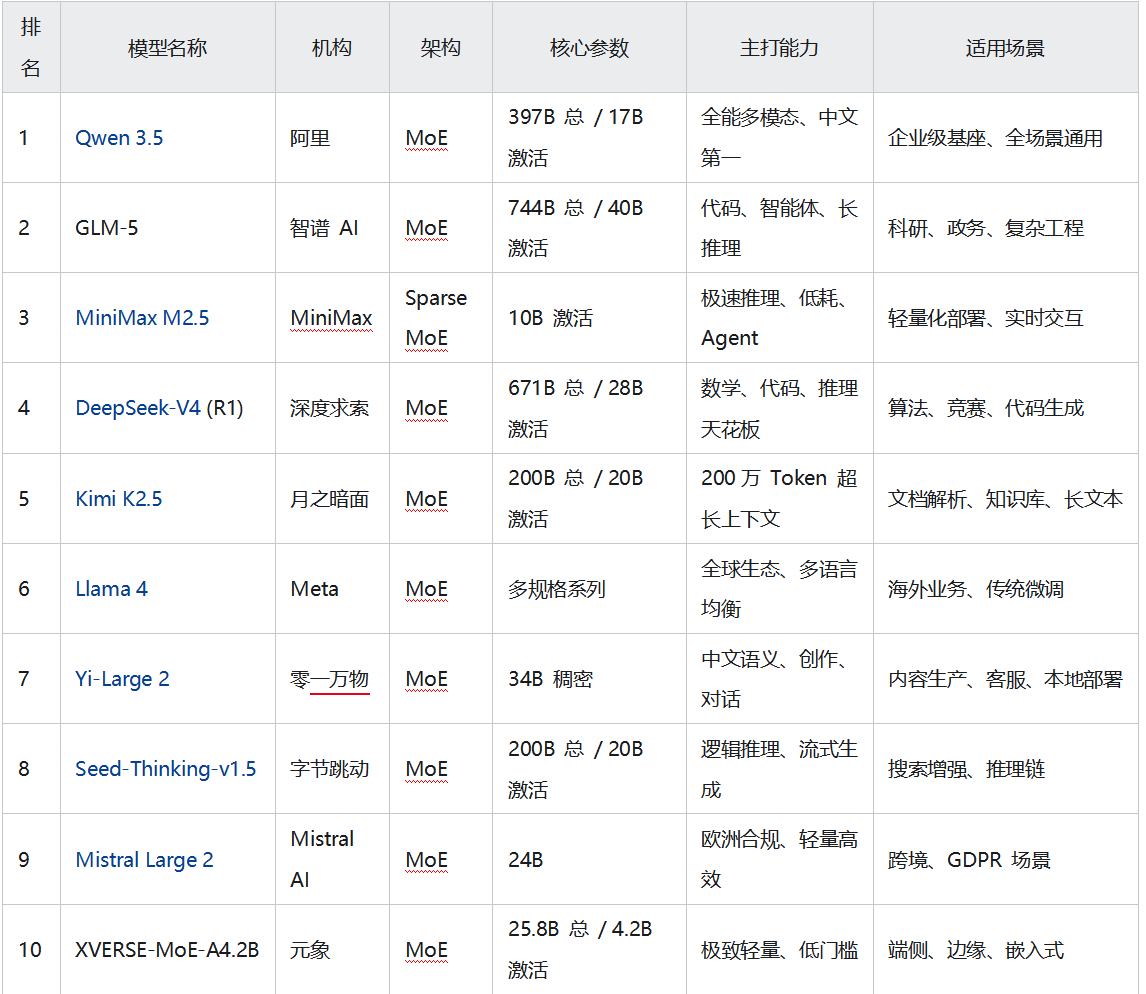
2026 年开源大模型 TOP10 2026 年,开源大模型彻底告别“参数内卷”,进入效率优先、场景为王、生态成熟的普惠时代。 本文基于 Hugging Face 下载量、LMSYS 盲测、工程化落地成本、商用友好度、社区活跃度 五大维度,发布 2026 全球开源大模型 TOP10 权威榜单。榜单呈现一个明确事实: 全球开源 TOP10 中,中国模型占 8 席;MoE 架构成为绝对主流;国产模型在中文、推理、代码、多模态全面领跑。一、2026 开源大模型 TOP10 完整榜单(权威版)二、TOP10 模型深度解读Qwen 3.5 —— 全球开源综合之王总参数 397B,仅激活 17B,性能直逼 Gemini 3、GPT-5.2原生多模态,支持 201 种语言Hugging Face 全球下载量、综合评分双第一商用友好、文档齐全、生态最完善定位:企业级通用基座首选GLM-5 —— 开源代码与智能体之王744B 总参数,激活 40BSWE-bench 开源第一,代码通过率 77.8%支持复杂智能体、多工具协同、长链思考政务、学术、金融工程首选定位:高端研发与系统工程基座MiniMax M2.5 —— 性价比与速度之王轻量 MoE,推理成本仅为旗舰模型 1%低延迟、高吞吐,适合实时交互原生支持 Agent 工作流定位:中小企业、快速落地、API 服务DeepSeek-V4 (R1) —— 数学推理之王MATH 准确率 61.6%,HumanEval 65.2%开源模型中推理能力最接近 GPT-4o长思考、自验证、代码调试极强定位:科研、竞赛、高逻辑需求场景Kimi K2.5 —— 长文本处理之王支持 200 万 Token 上下文文档摘要、表格解析、PDF/Excel/PPT 全链路处理C 端用户量最大的开源模型之一定位:知识管理、办公自动化、法律/医疗文档Llama 4 —— 欧美生态根基Meta 官方旗舰开源 MoE海外资源最多、教程最丰富多语言均衡,但中文弱于国产定位:出海业务、传统 LLM 迁移Yi-Large 2 —— 中文稠密模型标杆34B 稠密架构,部署简单、稳定性高中文理解、情感、文案生成顶尖消费级显卡可流畅运行定位:个人开发者、轻量化企业服务Seed-Thinking-v1.5 —— 推理链专项强者字节开源,专注深度逻辑与流式推理AIME、Codeforces 等难题平均准确率超 75%三级并行,吞吐量极高定位:搜索增强、逻辑问答、智能诊断Mistral Large 2 —— 欧洲合规首选轻量高效、GDPR 合规小参数、强泛化、低部署成本欧洲市场占有率第一定位:跨境业务、欧盟区企业服务XVERSE-MoE-A4.2B —— 端侧部署王者仅激活 4.2B 参数,性能媲美 13B 模型全开源、免费商用边缘设备、手机、IoT 可运行定位:端侧 AI、嵌入式、低成本硬件三、2026 开源大模型三大趋势MoE 架构彻底统治市场几乎所有 TOP 模型均采用 MoE:总参数大 → 能力强激活参数小 → 成本低、速度快 稠密模型仅在轻量场景保留。中国开源力量全球主导TOP10 中 8 个来自中国Hugging Face 中文模型下载占比超 60%中文理解、工程化、性价比全面领先从“通用”走向“场景专精”推理型代码型长文本型端侧轻量型多模态型 选模型 = 选场景,不再唯参数论四、2026 开发者实战选型指南企业通用基座 → Qwen 3.5代码/智能体 → GLM-5低成本/高并发 → MiniMax M2.5数学/推理 → DeepSeek-V4长文档/知识库 → Kimi K2.5端侧/边缘 → XVERSE-MoE-A4.2B出海/多语言 → Llama 4 / Mistralhttps://zhuanlan.zhihu.com/p/2009705203163752429
-
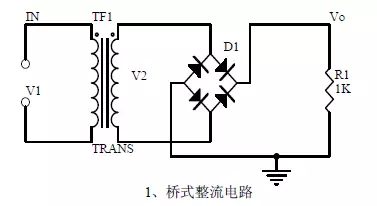
一文读懂20种模拟电路 https://zhuanlan.zhihu.com/p/385115795初级层次是熟练记住这二十个电路,清楚这二十个电路的作用。只要是学习自动化、电子等电控类专业的人士都应该且能够记住这二十个基本模拟电路。中级层次是能分析这二十个电路中的关键元器件的作用,每个元器件出现故障时电路的功能受到什么影响,测量时参数的变化规律,掌握对故障元器件的处理方法;定性分析电路信号的流向,相位变化;定性分析信号波形的变化过程;定性了解电路输入输出阻抗的大小,信号与阻抗的关系。有了这些电路知识,您极有可能成长为电子产品和工业控制设备的出色的维修维护技师。高级层次是能定量计算这二十个电路的输入输出阻抗、输出信号与输入信号的比值、电路中信号电流或电压与电路参数的关系、电路中信号的幅度与频率关系特性、相位与频率关系特性、电路中元器件参数的选择等。达到高级层次后,只要您愿意,受人尊敬的高薪职业——电子产品和工业控制设备的开发设计工程师将是您的首选职业。(文末有分享给大家的网盘资料,包含单片机、物联网开发、IoT-ARM的智能产品开发、全国电赛优秀作品等)01桥式整流电路注意要点:1、二极管的单向导电性:二极管的PN结加正向电压,处于导通状态;加反向电压,处于截止状态。伏安特性曲线:理想开关模型和恒压降模型:理想模型指的是在二极管正向偏置时,其管压降为0,而当其反向偏置时,认为它的电阻为无穷大,电流为零.就是截止。恒压降模型是说当二极管导通以后,其管压降为恒定值,硅管为0.7V,锗管0.5V。2、桥式整流电流流向过程:当u2是正半周期时,二极管Vd1和Vd2导通;而多极管Vd3和Vd4截止,负载RL是的电流是自上而下流过负载,负载上得到了与u 2正半周期相同的电压;在u 2的负半周,u 2的实际极性是下正上负,二极管Vd3和Vd4导通而Vd1和Vd2截止,负载RL上的电流仍是自上而下流过负载,负载上得到了与u 2正半周期相同的电压。3、计算:Vo, Io,二极管反向电压:Uo=0.9U2, Io=0.9U 2/RL,URM=√2 U 202电源滤波器注意要点:1、电源滤波的过程分析:电源滤波是在负载RL两端并联一只较大容量的电容器。由于电容两端电压不能突变,因而负载两端的电压也不会突变,使输出电压得以平滑,达到滤波的目的。波形形成过程:输出端接负载RL时,当电源供电时,向负载提供电流的同时也向电容C充电,充电时间常数为τ充=(Ri∥RLC)≈RiC,一般Ri〈〈RL,忽略Ri压降的影响,电容上电压将随u 2迅速上升,当ωt=ωt1时,有u 2=u 0,此后u 2低于u 0,所有二极管截止,这时电容C通过RL放电,放电时间常数为RLC,放电时间慢,u 0变化平缓。当ωt=ωt2时,u 2=u 0, ωt2后u 2又变化到比u 0大,又开始充电过程,u 0迅速上升。ωt=ωt3时有u 2=u 0,ωt3后,电容通过RL放电。如此反复,周期性充放电。由于电容C的储能作用,RL上的电压波动大大减小了。电容滤波适合于电流变化不大的场合。LC滤波电路适用于电流较大,要求电压脉动较小的场合。2、计算:滤波电容的容量和耐压值选择电容滤波整流电路输出电压Uo在√2U 2~0.9U 2之间,输出电压的平均值取决于放电时间常数的大小。电容容量RLC≧(3~5)T/2其中T为交流电源电压的周期。实际中,经常进一步近似为Uo≈1.2U2整流管的最大反向峰值电压URM=√2U 2,每个二极管的平均电流是负载电流的一半。03信号滤波器注意要点:1、信号滤波器的作用:把输入信号中不需要的信号成分衰减到足够小的程度,但同时必须让有用信号顺利通过。与电源滤波器的区别和相同点:两者区别为:信号滤波器用来过滤信号,其通带是一定的频率范围,而电源滤波器则是用来滤除交流成分,使直流通过,从而保持输出电压稳定;交流电源则是只允许某一特定的频率通过。相同点:都是用电路的幅频特性来工作。2、LC 串联和并联电路的阻抗计算:串联时,电路阻抗为Z=R+j(XL-XC)=R+j(ωL-1/ωC);并联时电路阻抗为Z=1/jωC∥(R+jωL)=考虑到实际中,常有R<<ωL,所以有Z≈幅频关系和相频关系曲线:画出通频带曲线:计算谐振频率:fo=1/2π√LC04微分和积分电路注意要点:1、电路的作用,与滤波器的区别和相同点;2、微分和积分电路电压变化过程分析,画出电压变化波形图;3、计算:时间常数,电压变化方程,电阻和电容参数的选择。05共射极放大电路注意要点:1、三极管的结构、三极管各极电流关系、特性曲线、放大条件;2、元器件的作用、电路的用途、电压放大倍数、输入和输出的信号电压相位关系、交流和直流等效电路图;3、静态工作点的计算、电压放大倍数的计算。06分压偏置式共射极放大电路注意要点:1、元器件的作用、电路的用途、电压放大倍数、输入和输出的信号电压相位关系、交流和直流等效电路图;2、电流串联负反馈过程的分析,负反馈对电路参数的影响;3、静态工作点的计算、电压放大倍数的计算;4、受控源等效电路分析。07共集电极放大电路(射极跟随器)注意要点:1、元器件的作用、电路的用途、电压放大倍数、输入和输出的信号电压相位关系、交流和直流等效电路图,电路的输入和输出阻抗特点;2、电流串联负反馈过程的分析,负反馈对电路参数的影响;3、静态工作点的计算、电压放大倍数的计算。08电路反馈框图注意要点:1、反馈的概念,正负反馈及其判断方法、并联反馈和串联反馈及其判断方法、电流反馈和电压反馈及其判断方法;2、带负反馈电路的放大增益;3、负反馈对电路的放大增益、通频带、增益的稳定性、失真、输入和输出电阻的影响。09二极管稳压电路注意要点:1、稳压二极管的特性曲线;2、稳压二极管应用注意事项;3、稳压过程分析。10串联稳压电源注意要点:1、串联稳压电源的组成框图;2、每个元器件的作用;稳压过程分析;3、输出电压计算。11差分放大电路注意要点:1、电路各元器件的作用,电路的用途、电路的特点;2、电路的工作原理分析。如何放大差模信号而抑制共模信号;3、电路的单端输入和双端输入,单端输出和双端输出工作方式。12场效应管放大电路注意要点:1、场效应管的分类,特点,结构,转移特性和输出特性曲线;2、场效应放大电路的特点;3、场效应放大电路的应用场合。13选频(带通)放大电路注意要点:1、每个元器件的作用,选频放大电路的特点,电路的作用;2、特征频率的计算,选频元件参数的选择;3、幅频特性曲线。14运算放大电路注意要点:1、理想运算放大器的概念,运放的输入端虚拟短路,运放的输入端的虚拟断路;2、反相输入方式的运放电路的主要用途,输入电压与输出电压信号的相位关系;3、同相输入方式下的增益表达,输入阻抗,输出阻抗。15差分输入运算放大电路注意要点:1、差分输入运算放大电路的的特点,用途;2、输出信号电压与输入信号电压的关系式。16电压比较电路注意要点:1、电压比较器的作用,工作过程;2、比较器的输入-输出特性曲线图;3、如何构成迟滞比较器。17RC振荡电路注意要点:1、振荡电路的组成,作用,起振的相位条件,起振和平衡幅度条件;2、RC电路阻抗与频率的关系曲线,相位与频率的关系曲线;3、RC振荡电路的相位条件分析,振荡频率,如何选择元器件。18LC振荡电路注意要点:1、振荡相位条件分析;2、直流等效电路图和交流等效电路图;3、振荡频率计算。19石英晶体振荡电路注意要点:1、石英晶体的特点,石英晶体的等效电路,石英晶体的特性曲;2、石英晶体振动器的特点;3、石英晶体振动器的振荡频率。20功率放大电路注意要点:1、乙类功率放大器的工作过程以及交越失真;2、复合三极管的复合规则;3、甲乙类功率放大器的工作原理,自举过程,甲类功率放大器,甲乙类功率放大器的特点。超70G的基于STM32物联网开发资料零基础到实战、STM32热门项目合集内含丰富的STM32的设计理念、开发原理、项目实施过程、全国电赛优秀作品合集、物联网理论与实践、IoT-ARM、ESP32教程、四轴飞行器设计制作等资料合集STM32物联网:https://sourl.cn/e8XHeG40个G的百度网盘C语言、C++、Linux从入门、进阶到精通覆盖所有知识点,还有视频教程讲解、C语言的项目源码大全C语言/C++/Linux教程合集:https://sourl.cn/8SpsNv物联网开发 - 从0到1,设计自己的开发板就这么简单 - 创客学院直播室