搜索到
344
篇与
的结果
-
 EDA验证总结(1) 从现在各个项目遗漏的bug 来看,目前的问题主要集中在以下个方面 (1)UT/BT 的testfeature 没有考虑场景验证,模块验证负责人不知道自己的模块在客户是实际上配置是什么,怎么使用的。完全是从规格角度进行分解,我之前就反复跟大家强调过,验证要从规格设计(白盒)和使用场景(黑盒)两个角度了解角度进行分解。既要像设计者一样进行考虑,怎么做更好,又要像客户那要考虑,如果遇到问题,仅仅从客户能看到的寄存器配置和端口怎么快速debug 到问题,目前设计是否够友好。(2)testfeature 分解只有配置,没有输出,没有说明要check什么。这次培训 培训内容就是“testfeature 分解和superbench 3.0使用简介"。我们写的testfeature 往往真得还有很多问题,但是我也理解,有时候要写好一个testfeature 真的需要花很多时间,有时间有限,折中处理一下也是可以,关键是有些testfeature 写得实在是太简单了,有些写的像设计规格。有时候感觉还不清楚testfeature 和 设计规格区别。这个不仅仅只是形式问题,现在很多bug 都和这个相关,比如有些testfeature 我们激励给了,但是没有检查到想检查的地方,bug 在出现了,但是没有checker,就这样在眼皮底下漏过去了。尤其是如果验证没有全局的RM 和scoreboard 比较,也没有全局的assertion,testcase 比较都是在用例特定 时刻去读取待检查对象和golden值进行比较。那就有两个问题,1)我们怎么知道在比较时刻之前或者之后有没有出现其他没有满足设计需求的时序(就是不该出现的时序)。 2)我们是怎么知道这个testcase 选取的比较对象就是全的,比如端口有5组output,人为选择其中某些进行比较,剩下没有比较的output 是什么情况。 但是如果用scoreboard 和 assertion 比较 就不是人为在testcase选择对象或者时刻,他们是自动monitor 进行比较的。只要出现都会进行checker。完全没有用scoreboard 和 assertion 验证 , 有漏checker 的风险。(3)对输入把控不严格,我们不能随便接受一个需求,一定要搞清楚原由,是什么原因修改,需求来源哪里,需求是否合理,文档有没有更新描述,而不是别人告诉我们这次修改很简单,随便一个会议就接收了,告诉我们就这么验证哪里哪里就行了。 (4)对于功耗和性能验证不够敏感,这个目前还是我们验证薄弱环境。我们不能只扔一个波形出去,让设计去判断性能是否满足,功耗是否满足。性能我们需要完全能判断,功耗我们也要跑ptpx 做好基本的判断。验证环境支持ptpx,后续我们都配置用起来。如果需要增加时间就要考虑时间增加。项目会正向先排计划,然后考虑和项目规划时间的偏差。验证这个岗位入门是比设计需求低一些,但是要做好,绝对比设计要求高。这就是下限可以很低,上限可以很高。关键是我们怎么去做。既要像设计一样考虑问题,又要像客户一样考虑问题,就这点就不简单做到。我们是验证的负责人,我们不能听别人告诉我们怎么去验证,要怎么验证要我们自己判断,然后评审确定,其他人尤其是是设计告诉就这么验证一下就行了, 只能做参考,最终怎么验证要自己判断。设计岗位从他们角度天然就是只会从时间和PPA 考虑问题,他们天然对质量缺乏敬畏之心。 我们写用例也要尽量像客户能操作那样去考虑(除了一些特殊情况外,比如仿真加速,异常配置,构造错误,并行触发等等情况),少使用一些固定延迟,等待内部信号判断。force 内部信号等等操作。所有做的这些操作基础出发点就是客户能否做得到(客户使用我们芯片能force 内部信号吗),实际情况有没有可能出现。 我们做一些仿真加速,异常配置,并行触发,后门操作时,也要有一个用例保证是真实情况配置。
EDA验证总结(1) 从现在各个项目遗漏的bug 来看,目前的问题主要集中在以下个方面 (1)UT/BT 的testfeature 没有考虑场景验证,模块验证负责人不知道自己的模块在客户是实际上配置是什么,怎么使用的。完全是从规格角度进行分解,我之前就反复跟大家强调过,验证要从规格设计(白盒)和使用场景(黑盒)两个角度了解角度进行分解。既要像设计者一样进行考虑,怎么做更好,又要像客户那要考虑,如果遇到问题,仅仅从客户能看到的寄存器配置和端口怎么快速debug 到问题,目前设计是否够友好。(2)testfeature 分解只有配置,没有输出,没有说明要check什么。这次培训 培训内容就是“testfeature 分解和superbench 3.0使用简介"。我们写的testfeature 往往真得还有很多问题,但是我也理解,有时候要写好一个testfeature 真的需要花很多时间,有时间有限,折中处理一下也是可以,关键是有些testfeature 写得实在是太简单了,有些写的像设计规格。有时候感觉还不清楚testfeature 和 设计规格区别。这个不仅仅只是形式问题,现在很多bug 都和这个相关,比如有些testfeature 我们激励给了,但是没有检查到想检查的地方,bug 在出现了,但是没有checker,就这样在眼皮底下漏过去了。尤其是如果验证没有全局的RM 和scoreboard 比较,也没有全局的assertion,testcase 比较都是在用例特定 时刻去读取待检查对象和golden值进行比较。那就有两个问题,1)我们怎么知道在比较时刻之前或者之后有没有出现其他没有满足设计需求的时序(就是不该出现的时序)。 2)我们是怎么知道这个testcase 选取的比较对象就是全的,比如端口有5组output,人为选择其中某些进行比较,剩下没有比较的output 是什么情况。 但是如果用scoreboard 和 assertion 比较 就不是人为在testcase选择对象或者时刻,他们是自动monitor 进行比较的。只要出现都会进行checker。完全没有用scoreboard 和 assertion 验证 , 有漏checker 的风险。(3)对输入把控不严格,我们不能随便接受一个需求,一定要搞清楚原由,是什么原因修改,需求来源哪里,需求是否合理,文档有没有更新描述,而不是别人告诉我们这次修改很简单,随便一个会议就接收了,告诉我们就这么验证哪里哪里就行了。 (4)对于功耗和性能验证不够敏感,这个目前还是我们验证薄弱环境。我们不能只扔一个波形出去,让设计去判断性能是否满足,功耗是否满足。性能我们需要完全能判断,功耗我们也要跑ptpx 做好基本的判断。验证环境支持ptpx,后续我们都配置用起来。如果需要增加时间就要考虑时间增加。项目会正向先排计划,然后考虑和项目规划时间的偏差。验证这个岗位入门是比设计需求低一些,但是要做好,绝对比设计要求高。这就是下限可以很低,上限可以很高。关键是我们怎么去做。既要像设计一样考虑问题,又要像客户一样考虑问题,就这点就不简单做到。我们是验证的负责人,我们不能听别人告诉我们怎么去验证,要怎么验证要我们自己判断,然后评审确定,其他人尤其是是设计告诉就这么验证一下就行了, 只能做参考,最终怎么验证要自己判断。设计岗位从他们角度天然就是只会从时间和PPA 考虑问题,他们天然对质量缺乏敬畏之心。 我们写用例也要尽量像客户能操作那样去考虑(除了一些特殊情况外,比如仿真加速,异常配置,构造错误,并行触发等等情况),少使用一些固定延迟,等待内部信号判断。force 内部信号等等操作。所有做的这些操作基础出发点就是客户能否做得到(客户使用我们芯片能force 内部信号吗),实际情况有没有可能出现。 我们做一些仿真加速,异常配置,并行触发,后门操作时,也要有一个用例保证是真实情况配置。 -
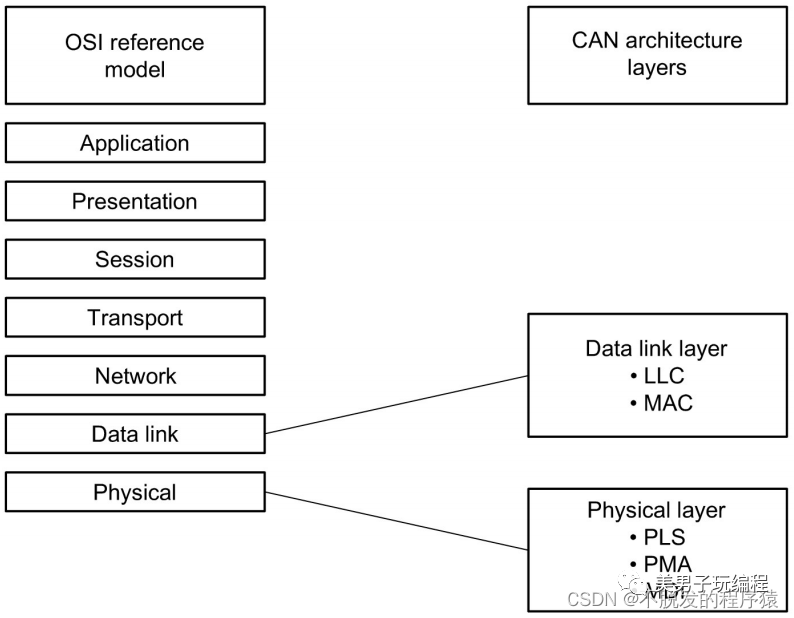
详解CAN总线:什么是CAN总线? 1P与S0C设计2022年10月24日12:00江苏在之前的博文中分享过一系列一文搞懂:SPI协议、I2C协议、PID算法、Modbus协议等文章,也考虑过是否可以出一篇介绍CAN总线协议的文章,但是在之后的学习研究中,发觉CAN总线协议比较庞大和复杂,做为刚刚进入汽车电子行业的开发小白,一篇文章难以讲解清晰,所以决定在汽车电子专栏中连载分享关于CAN总线协议的相关知识。由于本人也处于学习和研究阶段,如果对CAN总线协议有理解不到位的地方,还请各位大佬在文末留言指正一二。1CAN总线简介CAN总线协议(Controller Area Network),控制器局域网总线,是德国BOSCH(博世)公司研发的一种串行通讯协议总线,它可以使用双绞线来传输信号,是世界上应用最广泛的现场总线之一。CAN通讯协议标准(ISO-11898:2003)介绍了设备间信息是如何传递以及符合开放系统互联参考模型(OSI)的哪些分层项。实际CAN通讯是在连接设备的物理介质中进行,物理介质的特性由模型中的物理层定义。ISO11898体系结构定义七层,OSI模型中的最低两层作为数据链路层和物理层,如下图所示:LLC用于接收滤波、超载通告、回复管理;MAC用于数据封装/拆封、帧编码、媒体访问管理、错误检测与标定、应答、串转发/并转串;PLS用于位编码/解码、位定时、同步;PMA为收发器特性。CAN协议主要用于汽车中各种不同元件之间的通信,以此取代昂贵而笨重的配电线束,该协议的健壮性使其同样适用于自动化和工业环境中。CAN总线协议距今已经发展40多年,如今,CAN总线已成为汽车(汽车、卡车、公共汽车、拖拉机等)、轮船、飞机、电动汽车电池、机械等的标准配置。CAN之前的版本:汽车ECU是复杂的点对点布线1986年:BOSCH(博世)开发了CAN协议作为解决方案1991年:BOSCH(博世)发布了CAN 2.0(CAN 2.0A:11位,2.0B:29位)1993年:CAN被采用为国际标准(ISO 11898)2003年:ISO 11898成为标准系列2012年:博世发布了CAN FD 1.02015年:CAN FD协议标准化(ISO 11898-1)2016年:CAN物理层,数据速率高达5 Mbit/s,已通过ISO 11898-2标准化CAN总线具有以下特点:符合OSI开放式通信系统参考模型;两线式总线结构,电气信号为差分式;多主控制,在总线空闲时,所有的单元都可开始发送消息,最先访问总线的单元可获得发送权;多个单元同时开始发送时,发送高优先级ID消息的单元可获得发送权;点对点控制,一点对多点及全局广播几种传送方式接收数据,网络上的节点可分成不同的优先级,可以满足不同的实时要求;采用非破坏性位仲裁总线结构机制,当两个节点同时向网络上传送信息时,优先级低的节点主动停止数据发送,而优先级高的节点可不受影响地继续传送数据消息报文不包含源地址或者目标地址,仅通过标识符表明消息功能和优先级;基于固定消息格式的广播式总线系统,短帧结构;事件触发型,只有当有消息要发送时,节点才向总线上广播消息;可以通过发送远程帧请求其它节点发送数据;消息数据长度0~8Byte;节点数最多可达110个;错误检测功能。所有节点均可检测错误,检测错误的单元会立即通知其它所有单元;发送消息出错后,节点会自动重发;故障限制,具有自动关闭总线的功能,节点控制器可以判断错误是暂时的数据错误还是持续性错误,当总线上发生持续数据错误时,控制器可将节点从总线上隔离,以使总线上的其他操作不受影响;通信介质可采用双绞线、同轴电缆和光导纤维,一般使用最便宜的双绞线;理论上,CAN总线用单根信号线就可以通信,但还是配备了第二根导线,第二根导线与第一根导线信号为差分关系,可以有效抑制电磁干扰;直接通信距离最远可达10KM(速率4Kbps以下),通信速率最高可达1MB/s(此时距离最长40M);总线上可同时连接多个节点,可连接节点总数理论上是没有限制的,但实际可连接节点数受总线上时间延迟及电气负载的限制。每帧信息都有CRC校验及其他检错措施,数据错误率极低;废除了传统的站地址编码,取而代之的是对通信数据块进行编码。采用这种方法的优点是可使网络内的节点个数在理论上不受限制,数据块的标识码可由11位或29位二进制数组成,因此可以定义211或229个不同的数据块,这种数据块编码方式,还可使不同的节点同时接收到相同的数据,这一点在分步式控制中非常重要。CAN总线具体以下优势:2CAN节点组成CAN节点通常由三部分组成:CAN收发器、CAN控制器和MCU。CAN总线通过差分信号进行数据传输,CAN收发器将差分信号转换为TTL电平信号,或者将TTL电平信号转换为差分信号,CAN控制器将TTL电平信号接收并传输给MCU,如下图所示:目前,我们常用的STM32、华大、瑞萨等单片机内部就集成了CAN控制器外设,通过配置就可实现对CAN报文数据的读取和发送。3CAN总线结构CAN总线是一种广播类型的总线,可支持线形拓扑、星形拓扑、树形拓扑和环形拓扑等。CAN网络中至少需要两个节点设备才可进行通信,无法仅向某一个特定节点设备发送消息,发送数据时所有节点都不可避免地接收所有流量。但是,CAN总线硬件支持本地过滤,因此每个节点可以设置对有效的消息做出反应。线形拓扑是在一条主干总线分出各个节点支线,其优点在于布线施工简单,接线方便,阻抗匹配规则固定,缺点是拓扑不够灵活,在一定程度上影响通讯距离,如下图所示:星形拓扑是每个节点通过中央设备连到一起,其优点是容易扩展,缺点是一旦中央设备出故障会导致总线集体故障,而且分支线长不同,阻抗匹配复杂,可能需要通过一些中继器或集线器进行扩展,如下图所示:树形拓扑是节点分支比较多,且分支长度不同,其优点是布线方便,缺点是网络拓扑复杂,阻抗匹配困难,通讯中极易出现问题,必须加一些集线器设备,如下图所示:环形拓扑是将CAN总线头尾相连,形成环状,其优点是线缆任意位置断开,总线都不会出现问题,缺点是信号反射严重,无法用于高波特率和远距离传输,如下图所示:虽然CAN总线可以支持多种网络拓扑,但在实际应用中比较推荐使用线形拓扑,且在IOS 11898-2中高速CAN物理层规范推荐也是线形拓扑。在ISO 11898-2和ISO 11898-3中分别规定了两种CAN总线结构(在BOSCH CAN2.0规范中,并没有关于总线拓扑结构的说明)。ISO 11898-2中定义了通信速率为125Kbps~1Mbps的高速闭环CAN通信标准,当通信总线长度≤40米,最大通信速率可达到1Mbps,高速闭环CAN(高速CAN)通信如下图所示:ISO 11898-3中定义了通信速率为10~125Kbps的低速开环CAN通信标准,当传输速率为40Kbps时,总线距离可达到1000米。低速开环CAN(低速容错CAN)通信如下图所示:4CAN总线物理电气特性在CAN总线上,利用CAN_H和CAN_L两根线上的电位差来表示CAN信号。CAN 总线上的电位差分为显性电平(Dominant Voltage)和隐性电平(Recessive Voltage),其中显性电平为逻辑 0,隐性电平为逻辑 1。高速CAN总线(ISO 11898-2,通信速率为125Kbps~1Mbps)在传输显性(0)信号时,会将 CAN_H端抬向5V高电平,将CAN_L拉向0V低电平。当传输隐性(1)信号时,并不会驱动 CAN_H 或者 CAN_L 端。 显性信号 CAN_H 和 CAN_L 两端差分标称电压为 2V。 终端电阻在没有驱动时,将差分标称电压降回 0V。显性信号(0)的共模电压需要在 1.5V 到 3.5V 之间。隐性信号(1)的共模电压需要在+/-12V。低速/容错CAN(ISO 11898-3,通信速率为10~125Kbps)在传输显性信号(0)时,驱动CANH端抬向5V,将CANL端降向0V。在传输隐性信号(1)时并不驱动CAN 总线的任何一端。在电源电压VCC为5V时,显性信号差分电压需要大于2.3V,隐性信号的差分电压需要小于0.6V。CAN总线两端未被驱动时,终端电阻使CAN L端回归到RTH电压(当电源电压VCC为5V时,RTH电压至少为Vcc-0.3V=4.7V),同时使CAN H端回归至RTL电压(RTL电压最大为0.3V)。两根线需要能够承受-27V至40V的电压而不被损坏。在高速和低速CAN中从隐性信号向显性信号过渡的速度更快,因为此时CAN线缆被主动积极地驱动,显性向隐性的过渡速度主要取决于CAN网络的长度和导线的电容。来自微信
-
几款免费好用的电路设计软件,你一定要试试! 果果小师弟嵌入式微处理器2022年09月16日12:01北京工程软件和在线资源往往比较昂贵,不过,对于专业人员、学生和爱好者来说是非常有益的。用户开展项目或者仅进行工程验证时,这些资源往往是必要的,但是相关成本却令许多人望而却步。今天给大家分享几款高质量的免费软件,相信你肯定喜欢!一、电路仿真PartSim网址:https://www.partsim.com/PartSim是一款基于浏览器的电路仿真器,用户可以通过该软件进行电路实验。该仿真器布局简单,从而确保易用性,同时提供完整的SPICE仿真引擎、基于Web的原理图捕获工具和图形示波器,可以监视电路的模拟/数字信号电平。该工具还包含Digi-Key BOM(物料清单),允许用户为设计组件分配零件号,然后找到分销商。▲PartSim▲PartSimEasyEDA网址:https://easyeda.com/EasyEDA旨在“通过为电子设计提供全面的数据和协作工具,帮助设计人员更快地将创意转化为制造原型”。EasyEDA提供免费的在线电路仿真、PCB设计和电子电路设计功能。人们可以访问大量的原理图元件库、PCB封装和包装、spice仿真、模型和子电路,从而节省设计时间。还可以邀请他人进行项目协作,并轻松地在团队中分享设计。标准版免费使用,并提供无限公共项目和2个私人项目。Autodesk Circuits网址:https://www.autodesk.com.cn/solutions/circuit-design-softwareAutodesk Circuits是用于电子设计和实验的一组工具。初学者可以通过Electronics Lab或Circuit Scribe开始简单的实验,而经验丰富的用户则可以直接跳至PCB设计。该软件提供大量的免费入门教程和项目教程,可以通过Electronics Lab学习。二、PCB设计DesignSpark PCB官网:https://www.rs-online.com/designspark/pcb-softwareDesignSpark PCB将自己称为世界上最易于使用的电子设计软件,专门用于快速原型设计,并且可以将你的电路想法更快地转化为可测试的电路板”。这个软件对原理图尺寸没有限制,所以用户在创建PCB设计时也没有限制。用户也可以导入和导出他们需要的任何格式的文件,并且能够以所需格式创建BOM(物料清单)。虽然该工具完全免费,但是要注意重要的一点,即用户必须在其网站上注册才能解锁程序,并且在开始工作之前必须确认所显示的广告。▲DesignSpark PCB▲DesignSpark PCB▲DesignSpark PCB▲DesignSparkPCBKiCadEDA网址:https://www.kicad.org/KiCad是一款跨平台的开源电子设计自动化套件。该套件由三个不同的工具组成:Eeschema(原理图捕捉)、PcbNEW(PCB布局)和3D Viewer(通过3D方式查看电路板设计)。其中3D Viewer是一个独特的工具,可以旋转和平移你的电路板,从而查看2D图中无法看到的细节。▲KiCad▲KiCad▲KiCad三、CAD建模FreeCAD网址:freecadweb.org/FreeCAD是一款多平台开源参数化3D建模工具,旨在帮助用户将设计项目变为现实。这是一款通用多功能工具,适合不同级别的用户。想要涉及3D打印的初学者、教育工作者或经验丰富的CAD用户都可以使用FreeCAD。程序员还可以利用Python“扩展FreeCAD的功能、用脚本实现自动化、构建自己的模块,甚至将FreeCAD嵌入到自己的应用程序中。”▲FreeCAD▲FreeCAD▲FreeCADQCAD网址:qcad.org/en/QCAD是一款免费的开源2D CAD应用程序。QCAD 是一个免费的开源应用程序,用于二维 (2D) 计算机辅助绘图 (CAD)。使用 QCAD,您可以创建技术图纸,例如建筑平面图、室内设计、机械零件或示意图和图表。QCAD 适用于 Windows、macOS 和 Linux。该程序的功能列举如下:图层、块(分组)、35种CAD字体、40多种施工工具、20多种修改工具等等。许多用户都非常喜欢QCAD易于使用的界面和多功能性,给出了很高的评价。▲QCADImplicitCAD官网:implicitcad.org/ImplicitCAD网站表示:“ImplicitCAD项目致力于利用数学和计算机科学的力量来解决3D打印革命中的愚蠢设计问题”。ImplicitCAD是一款开源程序化CAD工具。这意味着ImplicitCAD使用了一种可以编译成3D对象的编程语言。程序化CAD的优点包括:对象的可重用性和抽象性;重复性任务的自动化;参数化设计以及软件开发(比如版本控制)的常用工具。▲ImplicitCAD▲ImplicitCADOpenSCAD官网:openscad.orgOpenSCAD是一款可以创建实体三维CAD模型的免费软件,可用于 Linux/UNIX、MS Windows和 MacOS X。它允许设计人员创建精确的3D模型和参数化设计,并且可以通过更改参数进行轻松调整。这些文档都是ASCII纯文本脚本,因此OpenSCAD更像是面向程序员的实体建模工具,通常被认为是设计开源硬件的入门级CAD工具,比如科研和教育科学工具。▲OpenSCAD四、电路仿真APP▲Droid PCB▲Circuit Wizard▲Bright Spark来自微信
-
-
C语言关键字的应用技巧 嵌入式微处理器2022年05月26日12:00北京摘要:嵌入式C开发关键字的应用技巧1、volatilevolatile修饰表示变量是易变的,编译器中的优化器在用到这个变量时必须每次都小心地从内存中重新读取这个变量的值,而不是使用保存在寄存器里的备份,有效的防止编译器自动优化,从而与软件设计相符合。中断服务与主程序共享变量://volatile uint8_t flag=1; uint8_t flag=1; void test(void) { while(flag) { //do something } } //interrupt service routine void isr_test(void) { flag=0; }如果没使用volatile定义flag,可能在优化后test陷入死循环,因为test里使用的flag并没修改它,开启优化后,编译器可能会固定从某个内存取值。例如:for(int i=0; i<100000; i++); //对比 for(volatile int i=0; i<100000; i++);前者可能被优化掉,虽然编码本意是需要执行操作延时,但编译器认为代码无意义。总的来说,volatile是告知编译器,不管代码如何,必须保留,而且使用时需要重新从内存读取更新,不能使用先前读取的缓存,一般在驱动代码中使用较多。2、constconst是恒定不变的意思,其修饰的各种数据类似只读效果。1)、 修饰变量采用const修饰变量,即变量声明为只读,保护变量值以防被修改。例如const int i = 1;上面这个例子表明,变量i具有只读特性,不能够被更改;若想对i重新赋值,如i = 10;属于错误操作。特别说明,定义变量的同时进行初始化,写成int const i=1,是正确的。2)、 修饰数组C语言中const还可以修饰数组,举例如下:const int array[5] = {1,2,3,4,5}; array[0] = array[0]+1; //错误,array是只读的,禁止修改数组元素与变量类似,具有只读属性,不能被更改;一旦更改,编译时就会报错。使用大数组存储固定的信息,例如查表(表驱动法的键值表),可以使用const节省ram。编译器并不给普通const只读变量分配空间,而是将它们保存到符号表中,无需读写内存操作,程序执行效率也会提高。3)、 修饰指针C语言中const修饰指针要特别注意,共有两种形式,一种是用来限定指向空间的值不能修改;另一种是限定指针不可更改。举例如下:int i = 1; int j = 2; const int *p1 = &i; int* const p2 = &j;上面定义了两个指针p1和p2,区别是const后面是指针本身还是指向的内容。在定义1中const限定的是 p1,即其指向空间的值不可改变,若改变其指向空间的值如 p1=10,则程序会报错;但p1的值是可以改变的,对p1重新赋值如p1=&k是没有任何问题的。在定义2中const限定的是指针p2,若改变p2的值如p2=&k,程序将会报错;但 p2,即其所指向空间的值可以改变,如 p2=20是没有问题的,程序正常执行。4)、 修饰函数参数const关键字修饰函数参数,对参数起限定作用,防止其在函数内部被修改。所限定的函数参数可以是普通变量,也可以是指针变量。例如:void fun(const int i) { …… i++; //对i的值进行了修改,程序报错 }常用的函数如strlensize_t strlen(const char *string);const在库函数中使用非常普遍,是一种自我保护的安全编码思维。3、struct与union对于struct 结构体和union共联体在嵌入式领域是使用得非常频繁的,一些可编程芯片提供的寄存器库都是采用结构体和共联体结合的方式来提供给软件人员进行开发,同时在平时的编码过程中这两个数据类型的灵活应用也能够实现代码更好的封装与简化。如下面的简单示例,就可以非常灵活的访问Val中的bit位。 typedef union { BYTE Val; struct __packed { BYTE b0:1; BYTE b1:1; BYTE b2:1; BYTE b3:1; BYTE b4:1; BYTE b5:1; BYTE b6:1; BYTE b7:1; } bits; }BYTE_VAL, BYTE_BITS;其中:1表示按位操作。不只是位-字节可以,单字节与多字节也可以简化拼接。#include "stdio.h" typedef struct { union { struct { unsigned char low; unsigned char high; }; unsigned short result; }; }test_t; int main(int argc, char *argv[]) { test_t hello; hello.high=0x12; hello.low=0x34; printf("result=%04X\r\n",hello.result);//输出 result=1234 return 0; }运行输出 result=1234 (win7系统下QT开发环境),原本需要 (high<<8)|low 运算,可以简化为共用体类型自动完成,但必须注意平台的字节顺序,属于大端还是小端模式。在应用层面,如果明确某个数据可能存在两种可能,而且两种结果不会同时存在,也可以使用结构体与共用体组合的方式,确保模块对外接口统一。例如移动通信模块,使用数据结构保存其基站信息,因为制式不同,模块可能工作在2G-GSM,也可能在4G-Cat1,为保证上层读取基站信息接口唯一,使用共用体就非常合适,否则需定义两套接口。如果觉得文章可以,可关注微信公众号【嵌入式系统】获取更多信息。4、预定义标识符一般编译器都支持预定义标识符,这些标识符结合printf等打印信息帮助程序员调试程序是非常有用的,一般编译器会自动根据用户指定完成替换和处理。部分标识:__FILE__ //表示编译的源文件名 __LINE__ //表示当前文件的行号 __FUNCTION__ //表示函数名 __DATE__ //表示编译日期 __TIME__ //表示编译时间使用范例:printf("file:%s,line:%d,date:%s,time:%s",__FILE__,__LINE__,__DATE__,__TIME__);这些比较常见,主要用于日志分析、版本记录,便于调试。5、#与###:是一种运算符,用于带参宏的文本替换,将跟在后面的参数转成一个字符串常量。 ##:是一种运算符,是将两个运算对象连接在一起,也只能出现在带参宏定义的文本替换中。#include "stdio.h" #define TO_STR(s) #s #define COMB(str1,str2) str1##str2 int main(int argc, char *argv[]) { int UART0= 115200; printf("UART0=%d\n", COMB(UART, 0));//字符串合并为变量UART0 printf("%s\n", TO_STR(3.14));//将数字变成字符串 return 0; }6、void 与 void*void表示的是无类型,不能声明变量或常量,但是可以把指针定义为void类型,如void ptr。void 指针可以指向任意类型的数据,在C语言指针操作中,任意类型的数据地址都可转为void* 指针。因为指针本质上都是unsigned int。常用的内存块操作库函数:void * memcpy( void *dest, const void *src, size_t len ); void * memset( void *buffer, int c, size_t num);数据指针为void* 类型,对传入任意类型数据的指针都可以操作。另外其中memcpy第二个参数,const现在也如前文所述,拷贝时对传入的原数据内容禁止修改。特殊说明,指针是不能使用sizeof求内容大小的,在ARM系统固定为int 4字节。对于函数无输入参数的,也尽量加上void,如void fun(void);7、weak一般简化定义#define _WEAK __attribute__((weak)) 函数名称前面加上__WEAK属性修饰符称为“弱函数”,类似C++的虚函数。链接时优先链接为非weak定义的函数,如果找不到则再链接带weak函数。_WEAK void fun(void) { //do this } //不在同一个.c,两同名函数不能在同一个文件 void fun(void) { //do that } 这种自动选择的机制,在代码移植和多模块配合工作的场景下应用较多。例如前期移植代码,需要调用某个接口fun,但当前该接口不存在或者未移植完整使用,可以使用weak关键字定义为空函数先保证编译正常。后续移植完成实现了fun,即软件中有2个fun函数没有任何错误,编译器自动会识别使用后者。当然也粗暴的#if 0屏蔽对fun的调用,但要确保后续记得放开。8、总结存在即合理,C语言里面的关键字,每个都有其特殊的意义,只是一般使用较少,譬如作文,使用常用的汉字可以;但引经据典,使用特殊的修饰辞藻更能显出水平。后续对section 进行详细说明,它和动态加载(OTA)、接口自启动相关。来自微信