搜索到
344
篇与
的结果
-
 跨平台且开源的文本扩展器:Espanso 不论是在手机还是电脑上,我们在与人交流的过程中常常会形成或用到一些重复性的表述,这些表述的内容长度可多可少,但由于它们被用到频率十分之高,所以我们通常会更喜欢用类似于缩写的方式来代替我们一字一句输入的过程,例如说「yyds」(永远滴神)、「dddd」(懂的都懂)、「nbnhhsh」(能不能好好说话)等。这些缩写或缩略语通常也可以被看作是用户自定义词典,我们不仅可以在操作设备上自定义,也可以在输入法上自定义。不过它们也仅限于定义一些纯文字性质的内容且长度有限,同时这些自定义设置可能会和特定的操作系统相绑定又或是无法完全导出,迁移成本存在过高的情况。但有这么一类应用和自定义词典类似,它们为了用户自定义输入的缩写内容而生,不仅能定义纯文字性质的内容,还具备较强的扩展性,也被称为是文本扩展器(Text Expander)。文本扩展器的作用表现和我们在使用自定义词典时的方式别无二致,都是输入一个特定的表达式,然后就会被替换成我们事先定义好的内容,比如:---------------------------------> [input] #42 ---------------------------------- [output] 意大利面拌 42 号混凝土 <---------------------------------当我们在文本扩展器中事先设置完整内容之后,只要输入 #42 后就会转换成「意大利面拌 42 号混凝土」完整的句子。知名的文本扩展器有 TextExpander,不过它属于付费应用也不是我们此次讨论的主角;而本文我们所介绍的则是另外一款免费、开源、跨平台且基于 Rust 语言编写的文本扩展器——Espanso,它不仅简单易用、体积小巧,且可配置性强,用户不但可以基于命令行配置扩展内容,而且还可以安装来自于社区的第三方扩展包。快速上手因为 Espanso 是一个开箱即用的工具,其安装步骤简单到可以一笔带过:打开 Espanso 官网,点击推荐的系统版本,下载并安装。注:安装完成并启动 Espanso 时需要额外的操作授权,否则 Espanso 可能无法正确运行。当然我们主要是看看如何使用 Espanso。毕竟安装完毕后启动 Espanso 是不会直接显示什么华丽的界面,因为它本质可以算是一个名不见经传的后台程序,只不过以应用的方式活跃在系统后台。使用 Espanso 的方式十分简单,我们只需在任意一个可以输入内容的地方,像输入代码一样先按下英文冒号「:」,然后再输入剩下的指令就可以神奇地看到 Espanso 已经为我们补全了内容。其中由 : 开始的一系列内容称为触发器(Trigger),而补全后的内容也被称为是匹配项(Match)。比如我们现在输入 :date 的触发器指令那么 Espanso 直接会就帮我们将内容替换为表示当天日期的匹配项:就是这么简单!不过你可能会好奇,我是怎么知道 :date 匹配项的呢?我们也可以在状态栏中找到 Espanso 的图表并点击「Open Search Bar」选项或是按下 Option+空格(Windows 上是 Alt+空格)就可以弹出相应的列表与搜索界面:除此之外,因为我前面说了 Espanso 本质是一个后台程序,所以我们可以通过命令行来与之交互(可以在终端上通过 espanso --help 命令获取所有命令)。这里我们为了查看有哪些匹配项,可以直接使用 espanso match list 命令:espanso match list:espanso - Hi there!:date - {{ date }}可以看到 Espanso 并没有内置过多的匹配项,所以要想它能为我们更好地自动补全内容,就需要我们像自定义缩略语或短语一样事先进行人为配置。Espanso 的配置主要有两部分,我们可以通过 espanso path 命令来找到配置文件路径:espanso pathConfig: /Users/Bobot/Library/Preferences/espansoPackages: /Users/Bobot/Library/Preferences/espanso/match/packagesRuntime: /Users/Bobot/Library/Application Support/espanso上述结果中的 Config 部分即为 Espanso 在当前操作系统中的配置存放路径。当中主要包含了两部分配置:$CONFIG/ config/default.ymlmatch/base.yml其中:config 部分的配置主要是针对 Espanso 程序本身,包括自定义补全的触发符号(比如将前面的英文冒号 : 更改为其他符号)、是否只在特定应用内 Espanso 才会生效等等;match 部分的配置主要就是我们需要自定义补全的部分,也即 :date 这样的匹配项具体设置。默认情况下 Espanso 是对所有应用都生效,因此当我们在应用中输入时很有可能就会极易触发匹配项弄巧成拙,为了避免冲突我们需要在后续在 config 部分进行配置以进行过滤。不论是 Espanso 本身的配置还是自定义匹配项,Espanso 都采用了目前主流的 YAML 配置文件,我们可以直接通过系统自带的文本编辑器打开。但是由于 YAML 的格式有些特殊,对于语法格式有严格要求,所以建议你使用 VS Code 这类编程专用的编辑器并在当中安装对应的 YAML 插件来进行编辑、配置;除此之外,可能你还需要简单学习一下 YAML 语法 才能更好地自定义相关配置内容。现在就让我们来试着定义一组触发器与匹配项练习一番,这里我就使用 VS Code 来进行操作。首先通过前面的命令我们找到了 Espanso 的配置文件夹后点击并拖拽至 VS Code,然后我们可以在 match/base.yml 默认匹配项的基础上进行设置,也可以像我一样新建一个名为 custom.yml 的匹配项进行设置:接着在当中填入如下内容(注意:如果你是在默认的 base.yml 文件中进行设置,由于已经存在了 matches 键就不需要重复填写): # custom.yml matches: - trigger: ":tomorrow" replace: "{{mytime}}" vars: - name: mytime type: date params: format: "%Y-%m-%d" offset: 86400 - trigger: ":yesterday" replace: "{{mytime}}" vars: - name: mytime type: date params: format: "%Y-%m-%d" offset: -86400 当中的内容是由 YAML 语法构成的配置内容,其中每一组由「-」符号并紧接着 trigger 开始到下一个 trigger 前的一整块内容都表示定义一个匹配项,里面包括了触发器以及对应的替换内容等等,关于这部分配置我们在后续深入展开,现在暂时按下不表。检测到有文件修改或保存后 Espanso 会自动重新加载配置文件,之后当我们输入 :tomorrow 或 :yesterday 时,就会看到 Espanso 帮我们进行了自动补全:以上仅是对 Espanso 管中窥豹一番,虽然它用法简单,但如果我们想要最大程度地发挥它的作用,可能还有更多用法有待我们进一步探索,所以接下来就让我们再深入了解一下 Espanso 的相关细节。深入了解 EspansoEspanso 相关配置Espanso 的设置默认会作用到所有应用,但这通常可能会导致一些意想不到地冲突,所以我们最好需要对其进行调整。只在特定应用中生效Espanso 的默认配置为 config/default.yml 文件,但我们也可以针对不同应用在同一层级下添加不同的配置文件,比如 config/vscode.yml。之后我们可以在 vscode.yml 文件中添加过滤选项,即不让 Espanso 在使用 VS Code 时生效: # vscode.yml filter_class: "com.microsoft.VSCode" enable: false当我写入这短短地两行内容并保存之后,Espanso 就不会在我使用 VS Code 时生效从而避免了冲突。Espanso 提供了三种过滤应用的方式,包括上述示例即 filter_title、filter_exec 以及 filter_class,它们也分别对应了按当前活跃窗口的文本标题过滤、按应用的可执行路径过滤以及按当前活跃窗口的类名(编程概念)过滤。这三种方式默认使用正则表达式,倘若你不清楚具体的内容,那你就可以填写正则表达式:filter_exec: "Chrome$"enable: false当然你也可能会好奇我前面的例子是如何找到 VS Code 对应的类名 com.microsoft.VSCode?因为 Espanso 内置了一个探测指令可以一次性帮我们生成对应三种过滤方式的内容。在未屏蔽 Espanso 的情况下,我们可以像使用匹配项那样输入 #detect# 来进行触发,比如我在 macOS 的微信随便选择一个对话框,然后输入该指令即可弹出如下界面。之后我们只需要点击拷贝到剪切板再自行粘贴选择即可。建议你在配置时侧重选择除 filter_title 之外的另外两种方式,因为当前活跃窗口的标题文本内容变化幅度较大并不是很稳定。但除了像上述示例那样直接使用 enable: false 这样简单粗暴的屏蔽方式之外,Espanso 也提供了另外一种模式,让你可以自主选择在特定应用中只屏蔽(exclude)掉对应的匹配项。比如我现在排除掉我前面自定义的 custom.yml 文件:filter_class: "com.microsoft.VSCode"extra_excludes:"../match/custom.yml"默认情况下的路径为当前的 config 路径,而匹配项则是在与 config 同级的路径中,所以我们需要通过 ../match 的方式返回到同级目录然后再选择 match 目录。保存之后在 VS Code 中即便使用 :tomorrow 或 :yesterday 都不会得到相应的匹配项。如果要屏蔽的内容过多,你既可以使用 glob 模式来设置路径,也可以换一种思路,即只让某些匹配项——比如代码片段(Snippets)——在特定应用中生效,比如我现在有一个 match/pycode.yml 配置,当中准备了一些 Python 相关的代码片段,现在我只想这些片段只在 VS Code 中生效,那么此时就应该这样做:filter_class: "com.microsoft.VSCode"extra_includes:"../match/pycode.yml"修改 Espanso 默认设置尽管说 Espanso 有提供了基本的 UI 界面并驻留在状态栏中,但 Espanso 的设置都是需要通过配置文件来修改,这样的方式缺点很明显,就是对于一般用户而言缺少图形化配置界面还需要额外的学习成本;不过对于喜欢折腾的玩家来说也好处颇多,一方面你可以随时随地同步配置文件在,在不同操作系统之间也能保持配置统一;另一方面,你可以根据自己直接手动快速修改。比如 Espanso 默认的搜索框界面可以用 Option+空格(Windows 为 Alt+空格)打开,那么我们也可以直接修改为 Option+Shift+空格 打开:search_shortcut: OPTION+SHIFT+SPACE当然我们也可以禁用搜索框快捷键的同时,自定义快速弹出 Espanso 匹配项的搜索框界面的触发器: # default.yml search_shortcut: off search_trigger: ">esp" 之后我们只要敲击 >esp 就能令搜索框直接弹出。除此之外,如果你不喜欢每次修改配置文件时 Espanso 就自动重载,那么你也可以关闭该选项并在每次配置之后手动点击状态栏的驻留程序并选择「Reload config」选项:auto_restart: false如果你觉得 Espanso 在扩展文本时的速度有点慢,那么也可以直接选择将 pre_paste_delay 选项尽量调低一些(默认为毫秒 ms),以便快速替换而不是保留肉眼可见的延迟:pre_paste_delay: 100更多的匹配项用法Espanso 相比于其他文本扩展器或用户自定义词典最为突出的地方在于它的匹配项是灵活且可配置的,并且还能搭配终端的命令行工具一起使用得到最后的匹配结果,当然这都需要我们进行配置。静态匹配项最简单的匹配项配置就是 Espanso 默认自带的例子,它们通常是由 trigger 和 replace 一组内容来组成: - trigger: ":espanso" replace: "Hi, there!" 像这样内容既定的部分和我们自定义词典没有什么区别,也被称为静态匹配项(Static Matches)。借助于 YAML 语法我们也可以编写长串的替换文本,即: - trigger: ":espanso" replace: "Hi,\nthere!" - trigger: ":espanso" replace: | Hi, there!默认情况下 Espanso 会直接将 replace 的部分作为匹配项的描述内容,这当我们存在多个同名触发器且内容近似的匹配项时会很容易造成困惑,所以 Espanso 支持我们为匹配项加上对应的描述信息(label 标签),以便能更好地知道当前触发器所得到的内容是什么: # custom.yml - trigger: ":espanso" replace: "Hi, there!" label: "inline content" - trigger: ":espanso" replace: "Hi,\nthere!" label: "content with newline(\\n)" - trigger: ":espanso" replace: | Hi, there! label: "content with newline" 之后我们再次触发 :espanso 时就会能看到不同匹配项所对应的不同描述内容是什么。类似地,我们也可以让一个匹配项拥有多个触发器,这里就需要用到 YAML 的数组语法来设置,例如: - trigger: [":espanso", ":greet"] replace: "Hi, there!" label: "inline content"但如果你要设置的匹配项其触发器虽然比较多但表达类似,那么 Espanso 也支持你使用正则表达式的方式来进行设置,我们只将 trigger 替换成 regex 并使用正则表达式即可。我们可以直接将上述示例稍作修改: - regex: ":(espanso|greet)" replace: "Hi, there!" label: "inline content" 动态匹配项除了静态匹配项之外,Espanso 也支持动态匹配项,这也是让 Espanso 灵活且强大之处,我前面给出的明天和昨天日期的示例就是如此。因为这两个匹配项有些重复,这里我就以明天时间日期为例: - trigger: ":tomorrow" replace: "{{mytime}}" vars: - name: mytime type: date params: format: "%Y-%m-%d" offset: 86400在当前的匹配项之下我们还可以自定义变量,也即对应着 vars 之下的内容。变量一词就是编程中经常用来保存内容的基本单位,而 Espanso 允许我们沿用这样的设定直接为匹配项设置一连串的变量,之后动态地生成内容,而不是像静态匹配项那样一成不变。所以在设置 :tomorrow 所对应的匹配项时,我自定义了一个 mytime 变量,这个变量的类型(type)是日期类型,然后又分别表示有 format 用于表示日期展示样式和 offset 日期偏移两个参数。像日期类型这样的变量设置在 Espanso 中又被称为扩展(Extension)。所以除了日期类型之外,Espanso 还支持多种类型以适应动态匹配项的需要,如多选类型、随机类型、脚本类型、Shell 命令类型等等。其中脚本类型和 Shell 命令类型有些类似,只不过前者主要是针对于逻辑更为复杂的脚本文件,它们通常由某种编程语言来编写,而后者主要就是适用于我们所示的终端命令行工具: # custom.yml - trigger: ":pynow" replace: "{{now}}" vars: - name: now type: script params: args: - python3 - -c - | from datetime import datetime print(datetime.now()) - trigger: ":sspai_title" replace: "{{title}}" vars: - name: title type: shell params: cmd: "curl -s https://sspai.com | htmlq --text 'title'" shell: zsh 上述定义的 :pynow 和 :sspai_title 两个动态匹配项里分别用到了脚本类型和 Shell 命令类型,前者是执行 Python 解释器及其来输出最终结果,而后者则是通过系统内的 curl 和 htmlq 两个命令行工具来访问少数派官方并通过 HTML 获得最终的标题内容。除了脚本类型和 Shell 命令类型之外,Espanso 还有一种类型——Form 表单——适用于多处动态内容生成的情况,通常可以被作为模板来使用,比如邮件回复模板、问题反馈模板等等: - trigger: ":reply" form: | Hey [[name]], Thank you for your email. We have already try to handle the [[number]] issue. 在上述匹配项中我们没有 replace 键,取而代之的是 form,并且当中的动态内容部分则是由之前的花括号变成了方括号。这是 Espanso 对于表单内容的一个简写方式,本质上等价于定义变量的方式: - trigger: ":reply" replace: | Hey {{template.name}}, Thank you for your email. We have already try to handle the {{template.number}} issue. vars: - name: template type: form params: layout: | Hey [[name]], Thank you for your email. We have already try to handle the [[number]] issue. 所以当我们配置完毕并保存后,输入 :reply 时会直接弹出 Espanso 为我们准备好的表单界面,我们只需填好其中的部分即可快速生成模板内容。但 Espanso 也还支持某个匹配项在其他匹配项中被使用或引用,极大地提高了灵活性与复用性。比方说我们现在再为这个模板自动带上一个当前回复日期:代码块复制Hey 100gle,Thank you for your email. We have already try to handle the #314 issue.2022-12-12那么我们就可以使用这种引用方式: - trigger: ":today" replace: "{{today}}" vars: - name: today type: date params: format: "%Y-%m-%d" - trigger: ":reply" replace: | Hey {{template.name}}, Thank you for your email. We have already try to handle the {{template.number}} issue. {{today}} vars: - name: today type: match params: trigger: ":today" - name: template type: form params: layout: | Hey [[name]], Thank you for your email. We have already try to handle the [[number]] issue.在 :reply 匹配项的变量中,我们会定义一个 today 变量,它的参数类型是特殊的 match 匹配项,然后当中的 trigger 参数与我们 :today 匹配项的触发器一致。这样只要我们填写完姓名与问题 ID 之后就会在模板中还自动生成当前的回复日期。安装社区第三方扩展包自定义匹配项会是一个永无止境的过程,因为它会随着个人的需要而与日俱增。但人类知识是相通的,也有一些内容可能不仅个人会用到,在互联网某一隅的一群人也会用到,譬如说 Emoji。可你知道吗?在我们日常网络交流中经常使用的每一个 Emoji 表情,其实也都基本有一个相对应称呼(CLDR Short Name),这里我就直接引用 Unicode 官方给出的示例列表:Browser CLDR Short Name😀 grinning face😃 grinning face with big eyes😄 grinning face with smiling eyes上述三个表情虽然都属于笑脸范畴,但是它们对应的 Unicode 编码不同,其文字称呼也不同;这也就意味着我们不仅能够通过 Unicode 编码来找到它们,同理文字称呼也适用。所以你要是恰好知道某个 Emoji 的名称而又不像自己四处翻找,那么借助 Espanso 就可以直接类似 :grinning-face 以文字称呼得到 Emoji 表情。Espanso 允许我们安装来自于社区其他人共享的第三方扩展包,它会类似于插件地形式来扩充我们的匹配项,可以让我们「站在巨人的肩膀」上去更好地使用 Espanso。我们可以直接到 Espanso 的官方 Hub 页面 去搜索。比如我们直接就以前面提到的「Emoji」一词进行搜索就可以找到与之相关的扩展包:但我们与扩展包相关的操作都需要通过命令行来完成:Shell复制espanso install all-emojis # 安装 all-emojis 扩展包espanso uninstall all-emojis # 卸载 all-emojis 扩展包espanso package list # 查看 Espanso 中的所有扩展包espanso package update all-emojis # 更新 all-emojis 扩展包espanso package update all # 更新 Espanso 中的所有扩展包安装完成之后我们就再次按照前面提到的查看匹配项的方式来检查是否安装成功。除上述方式之外 Espanso 还支持额外的安装方式,甚至你也可以自己去创建并分享一个扩展包,当然这些内容 Espanso 都在文档中找到详细说明,这里就不再额外赘述。结尾虽然 Espanso 在使用上直接了当并且功能强大,它不仅可以帮我们扩展静态的模板内容,也可以具备较强的扩展性,例如调用脚本或使用命令行来得到内容。不过为了让它好用、易用可能还需要多花一点心思在配置上。受限于篇幅,本文仅介绍了 Espanso 中比较重要的一些配置内容;但像全局变量、导入外部配置、变量注入、如何分享自己的扩展包等等细节并没有一一涉及。好在 Espanso 的官方文档已经给出了较为细致的说明,这些未提及的内容就留给你自行探索。
跨平台且开源的文本扩展器:Espanso 不论是在手机还是电脑上,我们在与人交流的过程中常常会形成或用到一些重复性的表述,这些表述的内容长度可多可少,但由于它们被用到频率十分之高,所以我们通常会更喜欢用类似于缩写的方式来代替我们一字一句输入的过程,例如说「yyds」(永远滴神)、「dddd」(懂的都懂)、「nbnhhsh」(能不能好好说话)等。这些缩写或缩略语通常也可以被看作是用户自定义词典,我们不仅可以在操作设备上自定义,也可以在输入法上自定义。不过它们也仅限于定义一些纯文字性质的内容且长度有限,同时这些自定义设置可能会和特定的操作系统相绑定又或是无法完全导出,迁移成本存在过高的情况。但有这么一类应用和自定义词典类似,它们为了用户自定义输入的缩写内容而生,不仅能定义纯文字性质的内容,还具备较强的扩展性,也被称为是文本扩展器(Text Expander)。文本扩展器的作用表现和我们在使用自定义词典时的方式别无二致,都是输入一个特定的表达式,然后就会被替换成我们事先定义好的内容,比如:---------------------------------> [input] #42 ---------------------------------- [output] 意大利面拌 42 号混凝土 <---------------------------------当我们在文本扩展器中事先设置完整内容之后,只要输入 #42 后就会转换成「意大利面拌 42 号混凝土」完整的句子。知名的文本扩展器有 TextExpander,不过它属于付费应用也不是我们此次讨论的主角;而本文我们所介绍的则是另外一款免费、开源、跨平台且基于 Rust 语言编写的文本扩展器——Espanso,它不仅简单易用、体积小巧,且可配置性强,用户不但可以基于命令行配置扩展内容,而且还可以安装来自于社区的第三方扩展包。快速上手因为 Espanso 是一个开箱即用的工具,其安装步骤简单到可以一笔带过:打开 Espanso 官网,点击推荐的系统版本,下载并安装。注:安装完成并启动 Espanso 时需要额外的操作授权,否则 Espanso 可能无法正确运行。当然我们主要是看看如何使用 Espanso。毕竟安装完毕后启动 Espanso 是不会直接显示什么华丽的界面,因为它本质可以算是一个名不见经传的后台程序,只不过以应用的方式活跃在系统后台。使用 Espanso 的方式十分简单,我们只需在任意一个可以输入内容的地方,像输入代码一样先按下英文冒号「:」,然后再输入剩下的指令就可以神奇地看到 Espanso 已经为我们补全了内容。其中由 : 开始的一系列内容称为触发器(Trigger),而补全后的内容也被称为是匹配项(Match)。比如我们现在输入 :date 的触发器指令那么 Espanso 直接会就帮我们将内容替换为表示当天日期的匹配项:就是这么简单!不过你可能会好奇,我是怎么知道 :date 匹配项的呢?我们也可以在状态栏中找到 Espanso 的图表并点击「Open Search Bar」选项或是按下 Option+空格(Windows 上是 Alt+空格)就可以弹出相应的列表与搜索界面:除此之外,因为我前面说了 Espanso 本质是一个后台程序,所以我们可以通过命令行来与之交互(可以在终端上通过 espanso --help 命令获取所有命令)。这里我们为了查看有哪些匹配项,可以直接使用 espanso match list 命令:espanso match list:espanso - Hi there!:date - {{ date }}可以看到 Espanso 并没有内置过多的匹配项,所以要想它能为我们更好地自动补全内容,就需要我们像自定义缩略语或短语一样事先进行人为配置。Espanso 的配置主要有两部分,我们可以通过 espanso path 命令来找到配置文件路径:espanso pathConfig: /Users/Bobot/Library/Preferences/espansoPackages: /Users/Bobot/Library/Preferences/espanso/match/packagesRuntime: /Users/Bobot/Library/Application Support/espanso上述结果中的 Config 部分即为 Espanso 在当前操作系统中的配置存放路径。当中主要包含了两部分配置:$CONFIG/ config/default.ymlmatch/base.yml其中:config 部分的配置主要是针对 Espanso 程序本身,包括自定义补全的触发符号(比如将前面的英文冒号 : 更改为其他符号)、是否只在特定应用内 Espanso 才会生效等等;match 部分的配置主要就是我们需要自定义补全的部分,也即 :date 这样的匹配项具体设置。默认情况下 Espanso 是对所有应用都生效,因此当我们在应用中输入时很有可能就会极易触发匹配项弄巧成拙,为了避免冲突我们需要在后续在 config 部分进行配置以进行过滤。不论是 Espanso 本身的配置还是自定义匹配项,Espanso 都采用了目前主流的 YAML 配置文件,我们可以直接通过系统自带的文本编辑器打开。但是由于 YAML 的格式有些特殊,对于语法格式有严格要求,所以建议你使用 VS Code 这类编程专用的编辑器并在当中安装对应的 YAML 插件来进行编辑、配置;除此之外,可能你还需要简单学习一下 YAML 语法 才能更好地自定义相关配置内容。现在就让我们来试着定义一组触发器与匹配项练习一番,这里我就使用 VS Code 来进行操作。首先通过前面的命令我们找到了 Espanso 的配置文件夹后点击并拖拽至 VS Code,然后我们可以在 match/base.yml 默认匹配项的基础上进行设置,也可以像我一样新建一个名为 custom.yml 的匹配项进行设置:接着在当中填入如下内容(注意:如果你是在默认的 base.yml 文件中进行设置,由于已经存在了 matches 键就不需要重复填写): # custom.yml matches: - trigger: ":tomorrow" replace: "{{mytime}}" vars: - name: mytime type: date params: format: "%Y-%m-%d" offset: 86400 - trigger: ":yesterday" replace: "{{mytime}}" vars: - name: mytime type: date params: format: "%Y-%m-%d" offset: -86400 当中的内容是由 YAML 语法构成的配置内容,其中每一组由「-」符号并紧接着 trigger 开始到下一个 trigger 前的一整块内容都表示定义一个匹配项,里面包括了触发器以及对应的替换内容等等,关于这部分配置我们在后续深入展开,现在暂时按下不表。检测到有文件修改或保存后 Espanso 会自动重新加载配置文件,之后当我们输入 :tomorrow 或 :yesterday 时,就会看到 Espanso 帮我们进行了自动补全:以上仅是对 Espanso 管中窥豹一番,虽然它用法简单,但如果我们想要最大程度地发挥它的作用,可能还有更多用法有待我们进一步探索,所以接下来就让我们再深入了解一下 Espanso 的相关细节。深入了解 EspansoEspanso 相关配置Espanso 的设置默认会作用到所有应用,但这通常可能会导致一些意想不到地冲突,所以我们最好需要对其进行调整。只在特定应用中生效Espanso 的默认配置为 config/default.yml 文件,但我们也可以针对不同应用在同一层级下添加不同的配置文件,比如 config/vscode.yml。之后我们可以在 vscode.yml 文件中添加过滤选项,即不让 Espanso 在使用 VS Code 时生效: # vscode.yml filter_class: "com.microsoft.VSCode" enable: false当我写入这短短地两行内容并保存之后,Espanso 就不会在我使用 VS Code 时生效从而避免了冲突。Espanso 提供了三种过滤应用的方式,包括上述示例即 filter_title、filter_exec 以及 filter_class,它们也分别对应了按当前活跃窗口的文本标题过滤、按应用的可执行路径过滤以及按当前活跃窗口的类名(编程概念)过滤。这三种方式默认使用正则表达式,倘若你不清楚具体的内容,那你就可以填写正则表达式:filter_exec: "Chrome$"enable: false当然你也可能会好奇我前面的例子是如何找到 VS Code 对应的类名 com.microsoft.VSCode?因为 Espanso 内置了一个探测指令可以一次性帮我们生成对应三种过滤方式的内容。在未屏蔽 Espanso 的情况下,我们可以像使用匹配项那样输入 #detect# 来进行触发,比如我在 macOS 的微信随便选择一个对话框,然后输入该指令即可弹出如下界面。之后我们只需要点击拷贝到剪切板再自行粘贴选择即可。建议你在配置时侧重选择除 filter_title 之外的另外两种方式,因为当前活跃窗口的标题文本内容变化幅度较大并不是很稳定。但除了像上述示例那样直接使用 enable: false 这样简单粗暴的屏蔽方式之外,Espanso 也提供了另外一种模式,让你可以自主选择在特定应用中只屏蔽(exclude)掉对应的匹配项。比如我现在排除掉我前面自定义的 custom.yml 文件:filter_class: "com.microsoft.VSCode"extra_excludes:"../match/custom.yml"默认情况下的路径为当前的 config 路径,而匹配项则是在与 config 同级的路径中,所以我们需要通过 ../match 的方式返回到同级目录然后再选择 match 目录。保存之后在 VS Code 中即便使用 :tomorrow 或 :yesterday 都不会得到相应的匹配项。如果要屏蔽的内容过多,你既可以使用 glob 模式来设置路径,也可以换一种思路,即只让某些匹配项——比如代码片段(Snippets)——在特定应用中生效,比如我现在有一个 match/pycode.yml 配置,当中准备了一些 Python 相关的代码片段,现在我只想这些片段只在 VS Code 中生效,那么此时就应该这样做:filter_class: "com.microsoft.VSCode"extra_includes:"../match/pycode.yml"修改 Espanso 默认设置尽管说 Espanso 有提供了基本的 UI 界面并驻留在状态栏中,但 Espanso 的设置都是需要通过配置文件来修改,这样的方式缺点很明显,就是对于一般用户而言缺少图形化配置界面还需要额外的学习成本;不过对于喜欢折腾的玩家来说也好处颇多,一方面你可以随时随地同步配置文件在,在不同操作系统之间也能保持配置统一;另一方面,你可以根据自己直接手动快速修改。比如 Espanso 默认的搜索框界面可以用 Option+空格(Windows 为 Alt+空格)打开,那么我们也可以直接修改为 Option+Shift+空格 打开:search_shortcut: OPTION+SHIFT+SPACE当然我们也可以禁用搜索框快捷键的同时,自定义快速弹出 Espanso 匹配项的搜索框界面的触发器: # default.yml search_shortcut: off search_trigger: ">esp" 之后我们只要敲击 >esp 就能令搜索框直接弹出。除此之外,如果你不喜欢每次修改配置文件时 Espanso 就自动重载,那么你也可以关闭该选项并在每次配置之后手动点击状态栏的驻留程序并选择「Reload config」选项:auto_restart: false如果你觉得 Espanso 在扩展文本时的速度有点慢,那么也可以直接选择将 pre_paste_delay 选项尽量调低一些(默认为毫秒 ms),以便快速替换而不是保留肉眼可见的延迟:pre_paste_delay: 100更多的匹配项用法Espanso 相比于其他文本扩展器或用户自定义词典最为突出的地方在于它的匹配项是灵活且可配置的,并且还能搭配终端的命令行工具一起使用得到最后的匹配结果,当然这都需要我们进行配置。静态匹配项最简单的匹配项配置就是 Espanso 默认自带的例子,它们通常是由 trigger 和 replace 一组内容来组成: - trigger: ":espanso" replace: "Hi, there!" 像这样内容既定的部分和我们自定义词典没有什么区别,也被称为静态匹配项(Static Matches)。借助于 YAML 语法我们也可以编写长串的替换文本,即: - trigger: ":espanso" replace: "Hi,\nthere!" - trigger: ":espanso" replace: | Hi, there!默认情况下 Espanso 会直接将 replace 的部分作为匹配项的描述内容,这当我们存在多个同名触发器且内容近似的匹配项时会很容易造成困惑,所以 Espanso 支持我们为匹配项加上对应的描述信息(label 标签),以便能更好地知道当前触发器所得到的内容是什么: # custom.yml - trigger: ":espanso" replace: "Hi, there!" label: "inline content" - trigger: ":espanso" replace: "Hi,\nthere!" label: "content with newline(\\n)" - trigger: ":espanso" replace: | Hi, there! label: "content with newline" 之后我们再次触发 :espanso 时就会能看到不同匹配项所对应的不同描述内容是什么。类似地,我们也可以让一个匹配项拥有多个触发器,这里就需要用到 YAML 的数组语法来设置,例如: - trigger: [":espanso", ":greet"] replace: "Hi, there!" label: "inline content"但如果你要设置的匹配项其触发器虽然比较多但表达类似,那么 Espanso 也支持你使用正则表达式的方式来进行设置,我们只将 trigger 替换成 regex 并使用正则表达式即可。我们可以直接将上述示例稍作修改: - regex: ":(espanso|greet)" replace: "Hi, there!" label: "inline content" 动态匹配项除了静态匹配项之外,Espanso 也支持动态匹配项,这也是让 Espanso 灵活且强大之处,我前面给出的明天和昨天日期的示例就是如此。因为这两个匹配项有些重复,这里我就以明天时间日期为例: - trigger: ":tomorrow" replace: "{{mytime}}" vars: - name: mytime type: date params: format: "%Y-%m-%d" offset: 86400在当前的匹配项之下我们还可以自定义变量,也即对应着 vars 之下的内容。变量一词就是编程中经常用来保存内容的基本单位,而 Espanso 允许我们沿用这样的设定直接为匹配项设置一连串的变量,之后动态地生成内容,而不是像静态匹配项那样一成不变。所以在设置 :tomorrow 所对应的匹配项时,我自定义了一个 mytime 变量,这个变量的类型(type)是日期类型,然后又分别表示有 format 用于表示日期展示样式和 offset 日期偏移两个参数。像日期类型这样的变量设置在 Espanso 中又被称为扩展(Extension)。所以除了日期类型之外,Espanso 还支持多种类型以适应动态匹配项的需要,如多选类型、随机类型、脚本类型、Shell 命令类型等等。其中脚本类型和 Shell 命令类型有些类似,只不过前者主要是针对于逻辑更为复杂的脚本文件,它们通常由某种编程语言来编写,而后者主要就是适用于我们所示的终端命令行工具: # custom.yml - trigger: ":pynow" replace: "{{now}}" vars: - name: now type: script params: args: - python3 - -c - | from datetime import datetime print(datetime.now()) - trigger: ":sspai_title" replace: "{{title}}" vars: - name: title type: shell params: cmd: "curl -s https://sspai.com | htmlq --text 'title'" shell: zsh 上述定义的 :pynow 和 :sspai_title 两个动态匹配项里分别用到了脚本类型和 Shell 命令类型,前者是执行 Python 解释器及其来输出最终结果,而后者则是通过系统内的 curl 和 htmlq 两个命令行工具来访问少数派官方并通过 HTML 获得最终的标题内容。除了脚本类型和 Shell 命令类型之外,Espanso 还有一种类型——Form 表单——适用于多处动态内容生成的情况,通常可以被作为模板来使用,比如邮件回复模板、问题反馈模板等等: - trigger: ":reply" form: | Hey [[name]], Thank you for your email. We have already try to handle the [[number]] issue. 在上述匹配项中我们没有 replace 键,取而代之的是 form,并且当中的动态内容部分则是由之前的花括号变成了方括号。这是 Espanso 对于表单内容的一个简写方式,本质上等价于定义变量的方式: - trigger: ":reply" replace: | Hey {{template.name}}, Thank you for your email. We have already try to handle the {{template.number}} issue. vars: - name: template type: form params: layout: | Hey [[name]], Thank you for your email. We have already try to handle the [[number]] issue. 所以当我们配置完毕并保存后,输入 :reply 时会直接弹出 Espanso 为我们准备好的表单界面,我们只需填好其中的部分即可快速生成模板内容。但 Espanso 也还支持某个匹配项在其他匹配项中被使用或引用,极大地提高了灵活性与复用性。比方说我们现在再为这个模板自动带上一个当前回复日期:代码块复制Hey 100gle,Thank you for your email. We have already try to handle the #314 issue.2022-12-12那么我们就可以使用这种引用方式: - trigger: ":today" replace: "{{today}}" vars: - name: today type: date params: format: "%Y-%m-%d" - trigger: ":reply" replace: | Hey {{template.name}}, Thank you for your email. We have already try to handle the {{template.number}} issue. {{today}} vars: - name: today type: match params: trigger: ":today" - name: template type: form params: layout: | Hey [[name]], Thank you for your email. We have already try to handle the [[number]] issue.在 :reply 匹配项的变量中,我们会定义一个 today 变量,它的参数类型是特殊的 match 匹配项,然后当中的 trigger 参数与我们 :today 匹配项的触发器一致。这样只要我们填写完姓名与问题 ID 之后就会在模板中还自动生成当前的回复日期。安装社区第三方扩展包自定义匹配项会是一个永无止境的过程,因为它会随着个人的需要而与日俱增。但人类知识是相通的,也有一些内容可能不仅个人会用到,在互联网某一隅的一群人也会用到,譬如说 Emoji。可你知道吗?在我们日常网络交流中经常使用的每一个 Emoji 表情,其实也都基本有一个相对应称呼(CLDR Short Name),这里我就直接引用 Unicode 官方给出的示例列表:Browser CLDR Short Name😀 grinning face😃 grinning face with big eyes😄 grinning face with smiling eyes上述三个表情虽然都属于笑脸范畴,但是它们对应的 Unicode 编码不同,其文字称呼也不同;这也就意味着我们不仅能够通过 Unicode 编码来找到它们,同理文字称呼也适用。所以你要是恰好知道某个 Emoji 的名称而又不像自己四处翻找,那么借助 Espanso 就可以直接类似 :grinning-face 以文字称呼得到 Emoji 表情。Espanso 允许我们安装来自于社区其他人共享的第三方扩展包,它会类似于插件地形式来扩充我们的匹配项,可以让我们「站在巨人的肩膀」上去更好地使用 Espanso。我们可以直接到 Espanso 的官方 Hub 页面 去搜索。比如我们直接就以前面提到的「Emoji」一词进行搜索就可以找到与之相关的扩展包:但我们与扩展包相关的操作都需要通过命令行来完成:Shell复制espanso install all-emojis # 安装 all-emojis 扩展包espanso uninstall all-emojis # 卸载 all-emojis 扩展包espanso package list # 查看 Espanso 中的所有扩展包espanso package update all-emojis # 更新 all-emojis 扩展包espanso package update all # 更新 Espanso 中的所有扩展包安装完成之后我们就再次按照前面提到的查看匹配项的方式来检查是否安装成功。除上述方式之外 Espanso 还支持额外的安装方式,甚至你也可以自己去创建并分享一个扩展包,当然这些内容 Espanso 都在文档中找到详细说明,这里就不再额外赘述。结尾虽然 Espanso 在使用上直接了当并且功能强大,它不仅可以帮我们扩展静态的模板内容,也可以具备较强的扩展性,例如调用脚本或使用命令行来得到内容。不过为了让它好用、易用可能还需要多花一点心思在配置上。受限于篇幅,本文仅介绍了 Espanso 中比较重要的一些配置内容;但像全局变量、导入外部配置、变量注入、如何分享自己的扩展包等等细节并没有一一涉及。好在 Espanso 的官方文档已经给出了较为细致的说明,这些未提及的内容就留给你自行探索。 -
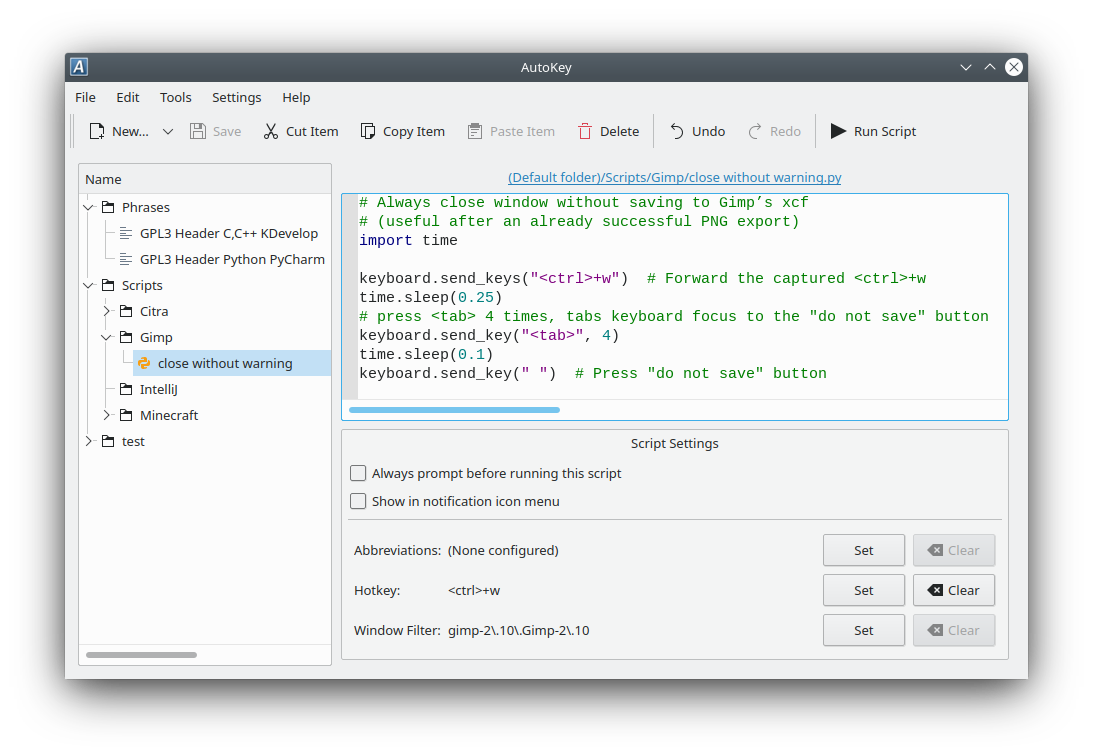
Linux自动化脚本工具——AutoKey简介 下面简介了AutoKey软件的概述、安装和使用方法。了解到这个软件的起因是在Ubuntu中想实现Windows中的自定义短语,但是Ubuntu中的Ibus输入法不是很支持该功能。搜索之后了解到espanso和AutoKey可以实现该功能。另外,AutoKey和WIndows中的AutoHotKey功能很相似,但并不是同一个软件。注:AutoKey目前不支持Wayland协议,只支持Xorg,而Ubuntu22.04默认使用的是Wayland。虽然可以切换,但也很麻烦。生成AI:Claude-3-Opus(POE)官方文档:1. https://github.com/autokey/autokey 2. Welcome to AutoKey!1 AutoKey 简介什么是 AutoKeyAutoKey 是一款开源的 Linux 桌面自动化工具,主要用于自动输入文本和执行预定义的操作。它可以帮助用户将常用的短语、句子或代码片段绑定到缩写或热键上,从而提高输入效率,节省时间。AutoKey 支持纯文本和富文本格式,可以在各种应用程序中使用,如文本编辑器、邮件客户端、IDE 等。AutoKey 的主要功能AutoKey 提供了以下主要功能:文本替换:将预定义的缩写替换为相应的文本内容,支持纯文本和富文本格式。脚本执行:可以将 Python 脚本绑定到缩写或热键上,实现更加灵活和强大的自动化操作。快捷键绑定:可以将缩写或脚本绑定到特定的热键组合,通过按键触发相应的操作。应用程序特定的缩写:可以为特定的应用程序设置专属的缩写,实现更加精准的自动化。文本模板:支持创建包含动态内容的文本模板,如日期、时间、剪贴板内容等。AutoKey 的工作原理AutoKey 的工作原理如下:用户在 AutoKey 中创建缩写,并将其绑定到相应的文本内容或 Python 脚本。AutoKey 在后台监听用户的键盘输入,当检测到与预定义缩写匹配的输入时,触发相应的替换操作。如果缩写绑定的是文本内容,AutoKey 会自动删除缩写,并将绑定的文本内容输入到当前光标所在位置。如果缩写绑定的是 Python 脚本,AutoKey 会执行该脚本,并根据脚本的逻辑执行相应的自动化操作,如模拟按键、粘贴文本、控制窗口等。AutoKey 的优势和适用场景AutoKey 的优势包括:提高输入效率:通过将常用的文本绑定到缩写,可以显著减少输入所需的时间和按键次数。自动化重复性任务:利用 Python 脚本,可以自动执行一些重复性的操作,如数据格式转换、文件处理等。减少错误:预定义的缩写和脚本可以确保输入的一致性和准确性,减少手动输入带来的错误。易于自定义:用户可以根据自己的需求,创建和管理缩写和脚本,实现个性化的自动化。AutoKey 适用于以下场景:编程:可以将常用的代码片段、函数模板绑定到缩写,提高编码效率。文案写作:可以将常用的句子、段落、签名等绑定到缩写,加快写作速度。客户服务:可以将常用的回复模板绑定到缩写,提高响应速度和一致性。数据录入:可以将常用的数据格式、表格模板绑定到缩写,简化录入过程。总之,AutoKey 是一款功能强大、灵活易用的 Linux 自动化工具,通过自定义缩写和脚本,可以显著提高工作效率,适用于各种需要重复输入和操作的场景。2 AutoKey 的安装和配置在 Ubuntu 系统中安装 AutoKey在 Ubuntu 系统中,可以通过两种方式安装 AutoKey:通过 Ubuntu 软件中心安装或使用 apt 命令安装。通过 Ubuntu 软件中心安装打开 Ubuntu 软件中心。在搜索框中输入 "AutoKey",点击搜索。在搜索结果中找到 "AutoKey" 应用,点击 "安装" 按钮。输入用户密码,等待安装完成。使用 apt 命令安装打开终端。输入以下命令,按回车执行:sudo apt updatesudo apt install autokey-gtk输入用户密码,等待安装完成。启动和配置 AutoKey启动 AutoKey安装完成后,可以通过以下方式启动 AutoKey:在 Ubuntu 的应用程序菜单中找到并点击 "AutoKey" 图标。在终端中输入 autokey-gtk 命令,按回车执行。熟悉 AutoKey 的用户界面AutoKey 的主界面由以下几个部分组成:缩写列表:显示所有已创建的缩写。缩写编辑器:用于编辑选中的缩写的内容和属性。工具栏:包含常用的操作按钮,如新建缩写、保存、删除等。菜单栏:提供访问 AutoKey 各种功能和设置的菜单项。创建和管理缩写创建新的缩写在 AutoKey 主界面中,点击工具栏上的 "新建" 按钮,或右键点击缩写列表中的 "My Phrases" 文件夹,选择 "New" > "Phrase"。在缩写编辑器中,输入缩写的名称、缩写内容以及可选的注释。点击工具栏上的 "保存" 按钮,或按 Ctrl+S 键保存缩写。编辑和删除现有缩写在缩写列表中,双击要编辑的缩写,或选中缩写后点击工具栏上的 "编辑" 按钮。在缩写编辑器中,修改缩写的内容或属性。点击工具栏上的 "保存" 按钮,或按 Ctrl+S 键保存修改。要删除缩写,在缩写列表中选中要删除的缩写,点击工具栏上的 "删除" 按钮,或按 Delete 键。设置触发方式AutoKey 支持两种触发方式:缩写触发和快捷键触发。缩写触发在缩写编辑器中,找到 "Abbreviations" 字段。输入要用作触发缩写的缩写内容,多个缩写之间用逗号分隔。保存缩写。当在任意应用程序中输入设定的缩写并按下空格、回车或标点符号时,缩写将被替换为预定义的内容。快捷键触发在缩写编辑器中,找到 "Hotkey" 字段。点击 "Set" 按钮,按下要用作触发缩写的快捷键组合。保存缩写。当在任意应用程序中按下设定的快捷键时,缩写内容将被插入到光标所在位置。通过以上步骤,你可以在 Ubuntu 系统中安装、配置 AutoKey,并创建和管理自定义的缩写。合理使用缩写触发和快捷键触发,可以显著提高输入效率和工作流程的自动化程度。3 AutoKey 的进阶使用使用 Python 脚本扩展 AutoKey 功能AutoKey 支持使用 Python 脚本来扩展其功能,使其能够执行更加复杂和灵活的自动化任务。编写 Python 脚本在 AutoKey 主界面中,右键点击 "My Scripts" 文件夹,选择 "New" > "Script"。在脚本编辑器中,输入 Python 脚本的内容。AutoKey 提供了一些内置的模块和函数,如 keyboard、mouse、system 等,可以用于模拟键盘输入、鼠标操作和执行系统命令等。保存脚本,并为其指定一个易于识别的名称。在缩写中调用 Python 脚本创建一个新的缩写或编辑现有的缩写。在缩写内容中,使用 标签来引用 Python 脚本,例如 myscript.py。保存缩写。当触发该缩写时,AutoKey 将执行指定的 Python 脚本。AutoKey 的常见问题和解决方法常见问题 1:缩写无法触发可能原因: - 缩写内容与实际输入不匹配。 - 缩写触发方式设置不正确。 - AutoKey 服务未启动或已停止。解决方法: 1. 仔细检查缩写内容,确保与实际输入完全匹配。 2. 检查缩写的触发方式设置,确保已选择正确的触发方式(缩写触发或快捷键触发)。 3. 确保 AutoKey 服务已启动并正常运行。如果服务已停止,可以在终端中输入 autokey-gtk 命令重新启动。常见问题 2:Python 脚本执行错误可能原因: - Python 脚本中存在语法错误或逻辑错误。 - 脚本中使用的模块或函数不受支持或未正确导入。解决方法: 1. 仔细检查 Python 脚本的语法和逻辑,确保没有错误。 2. 确保脚本中使用的模块和函数已正确导入,并受 AutoKey 支持。可以参考 AutoKey 的文档和示例代码。AutoKey 的使用技巧和建议使用技巧 1:创建递归缩写递归缩写是指在缩写的替换内容中包含缩写本身,从而实现多级展开。例如,创建缩写 "dt" 替换为 "$(date +%Y-%m-%d) $(date +%H:%M:%S)"。当输入 "dtdt" 时,将展开为 "2023-04-20 10:30:00 2023-04-20 10:30:00"。使用技巧 2:使用 Python 脚本实现动态内容在 Python 脚本中,可以使用变量、函数和控制结构等编程元素来生成动态内容。例如,可以编写脚本从文件或数据库中读取数据,根据条件生成不同的输出,或执行一些自动化操作后返回结果。AutoKey 的替代品和对比替代品 1:EspansoEspanso 是一款跨平台的文本扩展工具,支持 Windows、macOS 和 Linux。它使用 YAML 格式的配置文件来定义缩写和替换内容,支持 Shell 和 JavaScript 脚本,并提供了丰富的匹配选项和变量。与 AutoKey 相比,Espanso 的优势在于跨平台支持和更简洁的配置语法,但缺少图形化的用户界面。替代品 2:AutoHotkey (Windows)AutoHotkey 是一款功能强大的 Windows 自动化脚本语言和工具,可用于创建热键、宏、文本扩展等。它使用自己的脚本语言,提供了大量的内置函数和命令,可以与 Windows API 和其他应用程序交互。与 AutoKey 相比,AutoHotkey 更加灵活和功能丰富,但仅支持 Windows 平台,学习曲线也较为陡峭。总的来说,AutoKey 的进阶使用涉及 Python 脚本的编写和调用,以及一些常见问题的解决方法和使用技巧。对于有更高级需求的用户,可以考虑使用 Espanso 或 AutoHotkey 等替代工具,根据具体的使用场景和平台选择最适合的方案。
-
在verilog或者systemverilog中通过systemverilog获得环境变量setenv,getenv 在芯片验证的仿真中,有时候需要从文件中加载一些数据,比如激励、初始化数据、code等等,这些文件路径可以用绝对路径,当然为了其他人也可以用,最好用相对路径,这就需要用到环境变量来做路径的前半段。在module中得到或设置系统环境变量需要用到systemverilog的DPI-C,import C函数,然后在module中的块语句中调用C函数。步骤如下:在要获得环境变量的文件中 import setenv和getenv如下所示,把这两个函数import进去,不需要定义对应的C函数import "DPI-C" function int setenv(input string env_name, input string env_value, input int overwrite);import "DPI-C" function string getenv (input string env_name);直接使用getenv, setenv来获得和设置环境变量module mem read( input [8*200-1: O] mem_file ); initial begin $display("mem_file is %Os", mem_file); end endmodule module dut ( input clk, input wire [31:0]addr, output [31:0] rdata, input [31:0] wdata, input wire wr ); string path; initial begin setenv("PRJDIR", "/project/uart", 1); path = getenv( "PRJDIR"); $display("PRJDIR is %Os", path); setenv( "PRJDIR", "/project/sp", 1); path = getenv( "PRJDIR"); $display("PRJDIR is %0s", path); end mem_read u_mem_rd(.mem_file(path)); endmodule————————————————版权声明:本文为CSDN博主「甲六乙」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。原文链接:https://blog.csdn.net/m0_38037810/article/details/126136552
-
gvim+tmux 和vscode+neovim 的ide 模式 vscode 界面安装的插件:vscode+neovim 设置参考这篇文档:http://bennyhe.cn/index.php/archives/327/gvim 的界面:常用功能都有,文件浏览、语法高亮、彩虹括号、括号自动补齐、输入关键词提示,ctag 函数跳转、文档状态、多terminal(tmux)集成等等常用功能。terminal界面采用tmux,配合clipper 工具可以和gvim 文本窗口互相粘贴,可以分页多个terminal。gvim 按照的插件~/.vim/ 下文件夹结构~/.vim/ 下文件(插件)acp.vim auto-pairs.vim grep.vim mark.vim NERD_tree.vim scala.vim Tabular.vim verilog_systemverilog.vim vtreeexplorer.vimairline.vim ctrlp.vim marksbrowser.vim matchit.vim rainbow_parentheses.vim showmarks.vim taglist.vim visual-increment.vim~/.vimrc 文件如下:if v:version >= 900 set scroll=1 let g:airline_scroll_size = 1 " 覆盖插件默认值 endif set number syntax on set showmode set showcmd set hlsearch set autoindent set smartindent set cindent set ts=4 set softtabstop=4 set shiftwidth=4 set noexpandtab set tabstop=4 set cursorline set cursorcolumn set lines=35 columns=100 set ruler set showmatch set wrap noremap <C-S-A> gggH<C-O>G inoremap <C-S-A> <C-O>gg<C-O>gH<C-O>G cnoremap <C-S-A> <C-C>gggH<C-O>G onoremap <C-S-A> <C-C>gggH<C-O>G snoremap <C-S-A> <C-C>gggH<C-O>G xnoremap <C-S-A> <C-C>ggVG noremap <C-S> :update<CR> vnoremap <C-S> <C-C>:update<CR> inoremap <C-S> <Esc>:update<CR>gi if has("clipboard") " CTRL-X and SHIFT-Del are Cut vnoremap <C-A-X> "+x vnoremap <S-Del> "+x " CTRL-C and CTRL-Insert are Copy vnoremap <C-A-C> "+y vnoremap <C-Insert> "+y " CTRL-V and SHIFT-Insert are Paste map <C-A-V> "+gP map <S-Insert> "+gP cmap <C-A-V> <C-R>+ cmap <S-Insert> <C-R>+ endif "source $VIMRUNTIME/mswin.vim behave mswin set guifont=Monospace\ 14 set linespace=4 colorscheme evening "unmap <C-V> "unmap <C-A> "unmap <C-C> "unmap <C-X> " copy paste map <C-Insert> "+y map <S-Insert> "+gP "Mouse could be controled when INSERT model set mouse=a set selection=exclusive set selectmode=mouse,key "============================= " showmarks setting "============================= " Enable ShowMarks let showmarks_enable = 1 " Show which marks let showmarks_include = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ" " Ignore help, quickfix, non-modifiable buffers let showmarks_ignore_type = "hqm" " Hilight lower & upper marks let showmarks_hlline_lower = 1 let showmarks_hlline_upper = 1 hi ShowMarksHLl ctermbg=Yellow ctermfg=Black guibg=#FFDB72 guifg=Black hi ShowMarksHLu ctermbg=Magenta ctermfg=Black guibg=#FFB3FF guifg=Black "============================= " markbrowser setting "============================= nmap <silent> <leader>mk :MarksBrowser<cr> "Config for treeExplorer plugin let g:treeExplVertical=0 let g:treeExplDirSort=1 let g:treeExplWinSize=20 nmap vt :VSTreeExplore<cr> set autoread nmap <S-F> :call Verilog_format()<cr> function! Verilog_format() :w :silent execute '!~/.vim/tool/verible-verilog-format --column_limit=120 --indentation_spaces=4 --assignment_statement_alignment=align --named_port_alignment=align --port_declarations_alignment=align --module_net_variable_alignment=align --distribution_items_alignment=align --formal_parameters_indentation=indent --port_declarations_right_align_packed_dimensions=true --port_declarations_right_align_unpacked_dimensions=true --inplace=true --verify_convergence=true' expand('%:p') endfunction "ctrlp let g:ctrlp_map = '<c-p>' let g:ctrlp_cmd = 'CtrlP' "Grep hot key nnoremap <silent><C-F> :Grep -r<CR> "filetype, 'indent on' is necessary for smartindent filetype on filetype plugin on filetype indent on "header nmap <C-H> :call AddHeader()<cr> function! AddHeader() call append(0, '///////////////////////////////////////////////////////////////////') call append(1, '//copyright : Copyright © 2019-2023 INNOSTAR. All rights reserved') call append(2, '//project name: demo') call append(3, '//file name : '.expand('%:t')) call append(4, '//author : bennyhe') call append(5, '//abstraction : ') call append(6, '//date : '.strftime('%Y-%m-%d %H:%M:%S')) call append(7, '//version : 2.0') call append(8, '//platform : SuperBench 2.0') call append(9, '//history : created by bennyhe @'.strftime('%Y-%m-%d %H:%M:%S').expand(' v2.0')) call append(10, '///////////////////////////////////////////////////////////////////') endfunction "function nmap <C-L> :call AddFunction()<cr> function! AddFunction() call append(line(".")-1, ' /*****************************************************************') call append(line(".")-1, ' *') call append(line(".")-1, ' *****************************************************************/') endfunction set tags=tags; set tags+=~/.vim/tags/tags; set tags+=~/.vim/tags/tags_uvm; set tags+=~/.vim/tags/tags_vip; set autochdir "config for tlist plugin let Tlist_Ctags_Cmd = '/usr/bin/ctags' let Tlist_Use_Right_Window=0 let Tlist_Max_Tag_Length=1 let g:Tlist_Compact_Format=1 "let g:Tlist_WinHeight=5 let g:Tlist_WinWidth=15 let g:Tlist_Use_Horiz_Window=0 let g:Tlist_Show_One_File=1 "let g:Tlist_Exit_OnlyWindow=1 nmap tl :Tlist<cr> "terminal noremap <F8> :close!<cr> noremap <S-M-p> :sp<cr> noremap <S-M-q> :vs<cr> "noremap <F3> :belowright term ++rows=5 d:\msys64\msys2_shell.cmd -msys -defterm -no-start <cr> noremap <F3> :belowright term ++rows=5 powershell ubuntu2204.exe<cr> noremap <F4> :belowright term ++rows=5 powershell<cr> let b:match_words='\<begin\>:\<end\>' let g:rbpt_colorpairs = [ \ ['brown', 'RoyalBlue3'], \ ['Darkblue', 'SeaGreen3'], \ ['darkgray', 'DarkOrchid3'], \ ['darkgreen', 'firebrick3'], \ ['darkcyan', 'RoyalBlue3'], \ ['darkred', 'SeaGreen3'], \ ['darkmagenta', 'DarkOrchid3'], \ ['brown', 'firebrick3'], \ ['gray', 'RoyalBlue3'], \ ['black', 'SeaGreen3'], \ ['darkmagenta', 'DarkOrchid3'], \ ['Darkblue', 'firebrick3'], \ ['darkgreen', 'RoyalBlue3'], \ ['darkcyan', 'SeaGreen3'], \ ['darkred', 'DarkOrchid3'], \ ['red', 'firebrick3'], \ ] let g:rbpt_max = 16 let g:rbpt_loadcmd_toggle = 0 ""update ctags nmap <F10> :call UpdateCtags()<CR> function! UpdateCtags() let curdir=getcwd() while !filereadable("./tags") cd .. if getcwd() == "/" break endif endwhile if filewritable("./tags") silent !ctags -R --file-scope=yes --languages=systemverilog --links=yes --fields=+iaS --extra=+q TlistUpdate endif execute ":cd " . curdir endfunction nmap <F11> :call UpdateCtags_vip()<CR> function! UpdateCtags_vip() silent !ctags -R --languages=systemverilog -f ~/.vim/tags/tags_vip /data/ver/powervip/v2_0/ endfunction "autocmd BufWritePost *.sv,*.svh,*.v call UpdateCtags() "auto exce "set lines=999 columns=999 augroup initial autocmd! "autocmd VimEnter * VSTreeExplore "autocmd VimEnter * bo terminal ++rows=5 autocmd VimEnter * wincmd k autocmd VimEnter * Tlist autocmd VimEnter * wincmd h autocmd VimEnter * sp autocmd VimEnter * VSTreeExplore autocmd VimEnter * wincmd l autocmd VimEnter * q autocmd VimEnter * wincmd l au VimEnter * RainbowParenthesesToggleAll au Syntax * RainbowParenthesesLoadRound au Syntax * RainbowParenthesesLoadSquare au Syntax * RainbowParenthesesLoadBraces augroup END ":autocmd GUIEnter * VSTreeExplore "let g:airline_powerline_fonts = 1 let g:airline_theme = 'dark' let g:airline#extensions#tabline#enabled = 1 let g:airline#extensions#tabline#show_splits = 1 let g:airline#extensions#tabline#buffer_nr_show = 0 let g:airline#extensions#tabline#buffer_idx_mode = 3 let g:airline#extensions#tabline#show_tab_nr = 1 let g:airline#extensions#tabline#tab_nr_type = 1 let g:airline#extensions#branch#format =2 let g:airline_left_sep='>' let g:airline_inactive_collapse=0 let g:airline#extensions#tabline#formatter = 'unique_tail' let g:airline#extensions#tabline#buffer_idx_format = { \ '0': '0', \ '1': '1', \ '2': '2', \ '3': '3', \ '4': '4', \ '5': '5', \ '6': '6', \ '7': '7', \ '8': '8', \ '9': '9', \ ' ': ' ' \} let mapleader = "\<space>" let g:mapleader = "\<space>" set foldenable set foldmethod=marker set foldlevel=99 "" 代码折叠自定义快捷键 <leader>zz let g:FoldMethod = 0 map <leader>zz :call ToggleFold()<cr> fun! ToggleFold() if g:FoldMethod == 0 exe "normal! zM" let g:FoldMethod = 1 else exe "normal! zR" let g:FoldMethod = 0 endif endfun "set nocompatible "autocmd! bufwritepost .vimrc source % nmap <tab> :bn<cr> nmap <S-Tab> :bp<CR> "nmap <leader>1 :b 1<CR> nmap <leader>1 <Plug>AirlineSelectTab1 "{{{ nmap <leader>2 <Plug>AirlineSelectTab2 nmap <leader>3 <Plug>AirlineSelectTab3 nmap <leader>4 <Plug>AirlineSelectTab4 nmap <leader>5 <Plug>AirlineSelectTab5 nmap <leader>6 <Plug>AirlineSelectTab6 nmap <leader>7 <Plug>AirlineSelectTab7 nmap <leader>8 <Plug>AirlineSelectTab8 nmap <leader>9 <Plug>AirlineSelectTab9 nmap <leader>10 <Plug>AirlineSelectTab10 nmap <leader>11 <Plug>AirlineSelectTab11 nmap <leader>12 <Plug>AirlineSelectTab12 nmap <leader>13 <Plug>AirlineSelectTab13 nmap <leader>14 <Plug>AirlineSelectTab14 nmap <leader>15 <Plug>AirlineSelectTab15 nmap <leader>16 <Plug>AirlineSelectTab16 nmap <leader>17 <Plug>AirlineSelectTab17 nmap <leader>18 <Plug>AirlineSelectTab18 nmap <leader>19 <Plug>AirlineSelectTab19 nmap <leader>20 <Plug>AirlineSelectTab20 nmap <leader>21 <Plug>AirlineSelectTab21 nmap <leader>22 <Plug>AirlineSelectTab22 nmap <leader>23 <Plug>AirlineSelectTab23 nmap <leader>24 <Plug>AirlineSelectTab24 nmap <leader>25 <Plug>AirlineSelectTab25 nmap <leader>26 <Plug>AirlineSelectTab26 nmap <leader>27 <Plug>AirlineSelectTab27 nmap <leader>28 <Plug>AirlineSelectTab28 nmap <leader>29 <Plug>AirlineSelectTab29 nmap <leader>30 <Plug>AirlineSelectTab30 nmap <leader>31 <Plug>AirlineSelectTab31 nmap <leader>32 <Plug>AirlineSelectTab32 nmap <leader>33 <Plug>AirlineSelectTab33 nmap <leader>34 <Plug>AirlineSelectTab34 nmap <leader>35 <Plug>AirlineSelectTab35 nmap <leader>36 <Plug>AirlineSelectTab36 nmap <leader>37 <Plug>AirlineSelectTab37 nmap <leader>38 <Plug>AirlineSelectTab38 nmap <leader>39 <Plug>AirlineSelectTab39 nmap <leader>40 <Plug>AirlineSelectTab40 nmap <leader>41 <Plug>AirlineSelectTab41 nmap <leader>42 <Plug>AirlineSelectTab42 nmap <leader>43 <Plug>AirlineSelectTab43 nmap <leader>44 <Plug>AirlineSelectTab44 nmap <leader>45 <Plug>AirlineSelectTab45 nmap <leader>46 <Plug>AirlineSelectTab46 nmap <leader>47 <Plug>AirlineSelectTab47 nmap <leader>48 <Plug>AirlineSelectTab48 nmap <leader>49 <Plug>AirlineSelectTab49 nmap <leader>50 <Plug>AirlineSelectTab50 nmap <leader>51 <Plug>AirlineSelectTab51 nmap <leader>52 <Plug>AirlineSelectTab52 nmap <leader>53 <Plug>AirlineSelectTab53 nmap <leader>54 <Plug>AirlineSelectTab54 nmap <leader>55 <Plug>AirlineSelectTab55 nmap <leader>56 <Plug>AirlineSelectTab56 nmap <leader>57 <Plug>AirlineSelectTab57 nmap <leader>58 <Plug>AirlineSelectTab58 nmap <leader>59 <Plug>AirlineSelectTab59 nmap <leader>60 <Plug>AirlineSelectTab60 nmap <leader>61 <Plug>AirlineSelectTab61 nmap <leader>62 <Plug>AirlineSelectTab62 nmap <leader>63 <Plug>AirlineSelectTab63 nmap <leader>64 <Plug>AirlineSelectTab64 nmap <leader>65 <Plug>AirlineSelectTab65 nmap <leader>66 <Plug>AirlineSelectTab66 nmap <leader>67 <Plug>AirlineSelectTab67 nmap <leader>68 <Plug>AirlineSelectTab68 nmap <leader>69 <Plug>AirlineSelectTab69 nmap <leader>70 <Plug>AirlineSelectTab70 nmap <leader>71 <Plug>AirlineSelectTab71 nmap <leader>72 <Plug>AirlineSelectTab72 nmap <leader>73 <Plug>AirlineSelectTab73 nmap <leader>74 <Plug>AirlineSelectTab74 nmap <leader>75 <Plug>AirlineSelectTab75 nmap <leader>76 <Plug>AirlineSelectTab76 nmap <leader>77 <Plug>AirlineSelectTab77 nmap <leader>78 <Plug>AirlineSelectTab78 nmap <leader>79 <Plug>AirlineSelectTab79 nmap <leader>80 <Plug>AirlineSelectTab80 nmap <leader>81 <Plug>AirlineSelectTab81 nmap <leader>82 <Plug>AirlineSelectTab82 nmap <leader>83 <Plug>AirlineSelectTab83 nmap <leader>84 <Plug>AirlineSelectTab84 nmap <leader>85 <Plug>AirlineSelectTab85 nmap <leader>86 <Plug>AirlineSelectTab86 nmap <leader>87 <Plug>AirlineSelectTab87 nmap <leader>88 <Plug>AirlineSelectTab88 nmap <leader>89 <Plug>AirlineSelectTab89 nmap <leader>90 <Plug>AirlineSelectTab90 nmap <leader>91 <Plug>AirlineSelectTab91 nmap <leader>92 <Plug>AirlineSelectTab92 nmap <leader>93 <Plug>AirlineSelectTab93 nmap <leader>94 <Plug>AirlineSelectTab94 nmap <leader>95 <Plug>AirlineSelectTab95 nmap <leader>96 <Plug>AirlineSelectTab96 nmap <leader>97 <Plug>AirlineSelectTab97 nmap <leader>98 <Plug>AirlineSelectTab98 nmap <leader>99 <Plug>AirlineSelectTab99 "nmap <leader>- <Plug>AirlineSelectPrevTab "nmap <leader>+ <Plug>AirlineSelectNextTab "}}}
-
C语言枚举end是做什么用的? 最近在知乎上看到一个问题:C语言枚举end是做什么用的?刚开始,我也有一些疑惑,后面查了一些资料,对于这个问题,简单地说一下我的看法。枚举有多大?枚举类型到底有多大,占多少空间呢?这个要具体情况具体分析,编译器会视情况而定。下面是我测试用的编译器版本:gcc (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0Copyright (C) 2017 Free Software Foundation, Inc.This is free software; see the source for copying conditions. There is NOwarranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.当我写下这段代码的时候,实际的输出会是多少呢?有人会说是 1,有人会说是 4,我最终运行的确实是4;▲输出结果但是,这个结果并不是唯一的,它取决于你的编译器,另外还取决于编译器参数,gcc这里有个编译器参数 -fshort-enums,如果我们在编译的时候加上这个,那么编译出来是什么呢?▲短枚举的输出结果最终结果变成了1现在我在原先的代码中,加入CMD_MAX_16BIT = 0xFFFF,下面看看输出结果是多少。▲增带值范围运行输出结果如下:▲输出结果是的,它变成了2。因此,我们可以得出结论就是:编译器将为枚举分配足够的内存大小,来保存我们所声明的任何值。所以,如果我们的代码中只使用低于 256(8位的范围是0~255) 的值,我们的枚举应该是 8 位宽,也就是一个字节,而后面的0xFFFF显然是16位,两个字节,所以最终输出为2为此,我参考了一下gcc user manual,如下;https ://gcc.gnu.org/onlinedocs/gcc/Code-Gen-Options.html-fshort-enumsAllocate to an enum type only as many bytes as it needs for the declared range of possible values. Specifically, the enum type is equivalent to the smallest integer type that has enough room.Warning: the -fshort-enums switch causes GCC to generate code that is not binary compatible with code generated without that switch. Use it to conform to a non-default application binary interface.所以,我们需要明确的是编译器是否会默认执行 -fshort-enums这个命令,大多数是不会的,这里我还测试了一些clang,具体结果和gcc相同。但是,在嵌入式编程中需要注意,这里我查了一下,IAR的编译器默认会执行 -fshort-enums 。电脑上没有IAR,这里我参考了IAR 的 ARM C 编译器的文档IAR C/C++ Development Guide。可以看到enum类型默认的规定,如果要强制为int类型的话,需要编译的时候提那就--enum_is_int的编译参数,如下所示:▲枚举类型所以,这里为了避免编译器的优化,以及不同的硬件平台和不同编译器,从而导致枚举分配内存空间的变化,所以上述增加了一个0xFFFFFFFF,强制编译器为枚举分配4个字节的空间。▲设置最大范围为4字节最终的输出结果都是4,如下图所示:▲输出结果比较看来虽然是一个很小的知识点,但这中间的坑还真不少!好了,本期的文章就到这里了,我们下期再见。