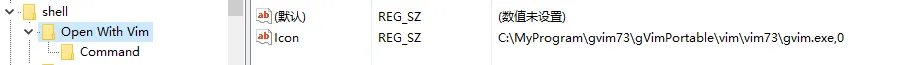搜索到
344
篇与
的结果
-
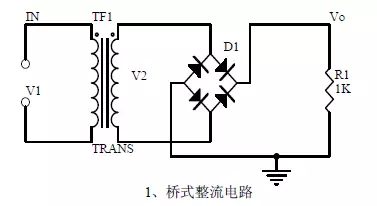
 一文读懂20种模拟电路 https://zhuanlan.zhihu.com/p/385115795初级层次是熟练记住这二十个电路,清楚这二十个电路的作用。只要是学习自动化、电子等电控类专业的人士都应该且能够记住这二十个基本模拟电路。中级层次是能分析这二十个电路中的关键元器件的作用,每个元器件出现故障时电路的功能受到什么影响,测量时参数的变化规律,掌握对故障元器件的处理方法;定性分析电路信号的流向,相位变化;定性分析信号波形的变化过程;定性了解电路输入输出阻抗的大小,信号与阻抗的关系。有了这些电路知识,您极有可能成长为电子产品和工业控制设备的出色的维修维护技师。高级层次是能定量计算这二十个电路的输入输出阻抗、输出信号与输入信号的比值、电路中信号电流或电压与电路参数的关系、电路中信号的幅度与频率关系特性、相位与频率关系特性、电路中元器件参数的选择等。达到高级层次后,只要您愿意,受人尊敬的高薪职业——电子产品和工业控制设备的开发设计工程师将是您的首选职业。(文末有分享给大家的网盘资料,包含单片机、物联网开发、IoT-ARM的智能产品开发、全国电赛优秀作品等)01桥式整流电路注意要点:1、二极管的单向导电性:二极管的PN结加正向电压,处于导通状态;加反向电压,处于截止状态。伏安特性曲线:理想开关模型和恒压降模型:理想模型指的是在二极管正向偏置时,其管压降为0,而当其反向偏置时,认为它的电阻为无穷大,电流为零.就是截止。恒压降模型是说当二极管导通以后,其管压降为恒定值,硅管为0.7V,锗管0.5V。2、桥式整流电流流向过程:当u2是正半周期时,二极管Vd1和Vd2导通;而多极管Vd3和Vd4截止,负载RL是的电流是自上而下流过负载,负载上得到了与u 2正半周期相同的电压;在u 2的负半周,u 2的实际极性是下正上负,二极管Vd3和Vd4导通而Vd1和Vd2截止,负载RL上的电流仍是自上而下流过负载,负载上得到了与u 2正半周期相同的电压。3、计算:Vo, Io,二极管反向电压:Uo=0.9U2, Io=0.9U 2/RL,URM=√2 U 202电源滤波器注意要点:1、电源滤波的过程分析:电源滤波是在负载RL两端并联一只较大容量的电容器。由于电容两端电压不能突变,因而负载两端的电压也不会突变,使输出电压得以平滑,达到滤波的目的。波形形成过程:输出端接负载RL时,当电源供电时,向负载提供电流的同时也向电容C充电,充电时间常数为τ充=(Ri∥RLC)≈RiC,一般Ri〈〈RL,忽略Ri压降的影响,电容上电压将随u 2迅速上升,当ωt=ωt1时,有u 2=u 0,此后u 2低于u 0,所有二极管截止,这时电容C通过RL放电,放电时间常数为RLC,放电时间慢,u 0变化平缓。当ωt=ωt2时,u 2=u 0, ωt2后u 2又变化到比u 0大,又开始充电过程,u 0迅速上升。ωt=ωt3时有u 2=u 0,ωt3后,电容通过RL放电。如此反复,周期性充放电。由于电容C的储能作用,RL上的电压波动大大减小了。电容滤波适合于电流变化不大的场合。LC滤波电路适用于电流较大,要求电压脉动较小的场合。2、计算:滤波电容的容量和耐压值选择电容滤波整流电路输出电压Uo在√2U 2~0.9U 2之间,输出电压的平均值取决于放电时间常数的大小。电容容量RLC≧(3~5)T/2其中T为交流电源电压的周期。实际中,经常进一步近似为Uo≈1.2U2整流管的最大反向峰值电压URM=√2U 2,每个二极管的平均电流是负载电流的一半。03信号滤波器注意要点:1、信号滤波器的作用:把输入信号中不需要的信号成分衰减到足够小的程度,但同时必须让有用信号顺利通过。与电源滤波器的区别和相同点:两者区别为:信号滤波器用来过滤信号,其通带是一定的频率范围,而电源滤波器则是用来滤除交流成分,使直流通过,从而保持输出电压稳定;交流电源则是只允许某一特定的频率通过。相同点:都是用电路的幅频特性来工作。2、LC 串联和并联电路的阻抗计算:串联时,电路阻抗为Z=R+j(XL-XC)=R+j(ωL-1/ωC);并联时电路阻抗为Z=1/jωC∥(R+jωL)=考虑到实际中,常有R<<ωL,所以有Z≈幅频关系和相频关系曲线:画出通频带曲线:计算谐振频率:fo=1/2π√LC04微分和积分电路注意要点:1、电路的作用,与滤波器的区别和相同点;2、微分和积分电路电压变化过程分析,画出电压变化波形图;3、计算:时间常数,电压变化方程,电阻和电容参数的选择。05共射极放大电路注意要点:1、三极管的结构、三极管各极电流关系、特性曲线、放大条件;2、元器件的作用、电路的用途、电压放大倍数、输入和输出的信号电压相位关系、交流和直流等效电路图;3、静态工作点的计算、电压放大倍数的计算。06分压偏置式共射极放大电路注意要点:1、元器件的作用、电路的用途、电压放大倍数、输入和输出的信号电压相位关系、交流和直流等效电路图;2、电流串联负反馈过程的分析,负反馈对电路参数的影响;3、静态工作点的计算、电压放大倍数的计算;4、受控源等效电路分析。07共集电极放大电路(射极跟随器)注意要点:1、元器件的作用、电路的用途、电压放大倍数、输入和输出的信号电压相位关系、交流和直流等效电路图,电路的输入和输出阻抗特点;2、电流串联负反馈过程的分析,负反馈对电路参数的影响;3、静态工作点的计算、电压放大倍数的计算。08电路反馈框图注意要点:1、反馈的概念,正负反馈及其判断方法、并联反馈和串联反馈及其判断方法、电流反馈和电压反馈及其判断方法;2、带负反馈电路的放大增益;3、负反馈对电路的放大增益、通频带、增益的稳定性、失真、输入和输出电阻的影响。09二极管稳压电路注意要点:1、稳压二极管的特性曲线;2、稳压二极管应用注意事项;3、稳压过程分析。10串联稳压电源注意要点:1、串联稳压电源的组成框图;2、每个元器件的作用;稳压过程分析;3、输出电压计算。11差分放大电路注意要点:1、电路各元器件的作用,电路的用途、电路的特点;2、电路的工作原理分析。如何放大差模信号而抑制共模信号;3、电路的单端输入和双端输入,单端输出和双端输出工作方式。12场效应管放大电路注意要点:1、场效应管的分类,特点,结构,转移特性和输出特性曲线;2、场效应放大电路的特点;3、场效应放大电路的应用场合。13选频(带通)放大电路注意要点:1、每个元器件的作用,选频放大电路的特点,电路的作用;2、特征频率的计算,选频元件参数的选择;3、幅频特性曲线。14运算放大电路注意要点:1、理想运算放大器的概念,运放的输入端虚拟短路,运放的输入端的虚拟断路;2、反相输入方式的运放电路的主要用途,输入电压与输出电压信号的相位关系;3、同相输入方式下的增益表达,输入阻抗,输出阻抗。15差分输入运算放大电路注意要点:1、差分输入运算放大电路的的特点,用途;2、输出信号电压与输入信号电压的关系式。16电压比较电路注意要点:1、电压比较器的作用,工作过程;2、比较器的输入-输出特性曲线图;3、如何构成迟滞比较器。17RC振荡电路注意要点:1、振荡电路的组成,作用,起振的相位条件,起振和平衡幅度条件;2、RC电路阻抗与频率的关系曲线,相位与频率的关系曲线;3、RC振荡电路的相位条件分析,振荡频率,如何选择元器件。18LC振荡电路注意要点:1、振荡相位条件分析;2、直流等效电路图和交流等效电路图;3、振荡频率计算。19石英晶体振荡电路注意要点:1、石英晶体的特点,石英晶体的等效电路,石英晶体的特性曲;2、石英晶体振动器的特点;3、石英晶体振动器的振荡频率。20功率放大电路注意要点:1、乙类功率放大器的工作过程以及交越失真;2、复合三极管的复合规则;3、甲乙类功率放大器的工作原理,自举过程,甲类功率放大器,甲乙类功率放大器的特点。超70G的基于STM32物联网开发资料零基础到实战、STM32热门项目合集内含丰富的STM32的设计理念、开发原理、项目实施过程、全国电赛优秀作品合集、物联网理论与实践、IoT-ARM、ESP32教程、四轴飞行器设计制作等资料合集STM32物联网:https://sourl.cn/e8XHeG40个G的百度网盘C语言、C++、Linux从入门、进阶到精通覆盖所有知识点,还有视频教程讲解、C语言的项目源码大全C语言/C++/Linux教程合集:https://sourl.cn/8SpsNv物联网开发 - 从0到1,设计自己的开发板就这么简单 - 创客学院直播室
一文读懂20种模拟电路 https://zhuanlan.zhihu.com/p/385115795初级层次是熟练记住这二十个电路,清楚这二十个电路的作用。只要是学习自动化、电子等电控类专业的人士都应该且能够记住这二十个基本模拟电路。中级层次是能分析这二十个电路中的关键元器件的作用,每个元器件出现故障时电路的功能受到什么影响,测量时参数的变化规律,掌握对故障元器件的处理方法;定性分析电路信号的流向,相位变化;定性分析信号波形的变化过程;定性了解电路输入输出阻抗的大小,信号与阻抗的关系。有了这些电路知识,您极有可能成长为电子产品和工业控制设备的出色的维修维护技师。高级层次是能定量计算这二十个电路的输入输出阻抗、输出信号与输入信号的比值、电路中信号电流或电压与电路参数的关系、电路中信号的幅度与频率关系特性、相位与频率关系特性、电路中元器件参数的选择等。达到高级层次后,只要您愿意,受人尊敬的高薪职业——电子产品和工业控制设备的开发设计工程师将是您的首选职业。(文末有分享给大家的网盘资料,包含单片机、物联网开发、IoT-ARM的智能产品开发、全国电赛优秀作品等)01桥式整流电路注意要点:1、二极管的单向导电性:二极管的PN结加正向电压,处于导通状态;加反向电压,处于截止状态。伏安特性曲线:理想开关模型和恒压降模型:理想模型指的是在二极管正向偏置时,其管压降为0,而当其反向偏置时,认为它的电阻为无穷大,电流为零.就是截止。恒压降模型是说当二极管导通以后,其管压降为恒定值,硅管为0.7V,锗管0.5V。2、桥式整流电流流向过程:当u2是正半周期时,二极管Vd1和Vd2导通;而多极管Vd3和Vd4截止,负载RL是的电流是自上而下流过负载,负载上得到了与u 2正半周期相同的电压;在u 2的负半周,u 2的实际极性是下正上负,二极管Vd3和Vd4导通而Vd1和Vd2截止,负载RL上的电流仍是自上而下流过负载,负载上得到了与u 2正半周期相同的电压。3、计算:Vo, Io,二极管反向电压:Uo=0.9U2, Io=0.9U 2/RL,URM=√2 U 202电源滤波器注意要点:1、电源滤波的过程分析:电源滤波是在负载RL两端并联一只较大容量的电容器。由于电容两端电压不能突变,因而负载两端的电压也不会突变,使输出电压得以平滑,达到滤波的目的。波形形成过程:输出端接负载RL时,当电源供电时,向负载提供电流的同时也向电容C充电,充电时间常数为τ充=(Ri∥RLC)≈RiC,一般Ri〈〈RL,忽略Ri压降的影响,电容上电压将随u 2迅速上升,当ωt=ωt1时,有u 2=u 0,此后u 2低于u 0,所有二极管截止,这时电容C通过RL放电,放电时间常数为RLC,放电时间慢,u 0变化平缓。当ωt=ωt2时,u 2=u 0, ωt2后u 2又变化到比u 0大,又开始充电过程,u 0迅速上升。ωt=ωt3时有u 2=u 0,ωt3后,电容通过RL放电。如此反复,周期性充放电。由于电容C的储能作用,RL上的电压波动大大减小了。电容滤波适合于电流变化不大的场合。LC滤波电路适用于电流较大,要求电压脉动较小的场合。2、计算:滤波电容的容量和耐压值选择电容滤波整流电路输出电压Uo在√2U 2~0.9U 2之间,输出电压的平均值取决于放电时间常数的大小。电容容量RLC≧(3~5)T/2其中T为交流电源电压的周期。实际中,经常进一步近似为Uo≈1.2U2整流管的最大反向峰值电压URM=√2U 2,每个二极管的平均电流是负载电流的一半。03信号滤波器注意要点:1、信号滤波器的作用:把输入信号中不需要的信号成分衰减到足够小的程度,但同时必须让有用信号顺利通过。与电源滤波器的区别和相同点:两者区别为:信号滤波器用来过滤信号,其通带是一定的频率范围,而电源滤波器则是用来滤除交流成分,使直流通过,从而保持输出电压稳定;交流电源则是只允许某一特定的频率通过。相同点:都是用电路的幅频特性来工作。2、LC 串联和并联电路的阻抗计算:串联时,电路阻抗为Z=R+j(XL-XC)=R+j(ωL-1/ωC);并联时电路阻抗为Z=1/jωC∥(R+jωL)=考虑到实际中,常有R<<ωL,所以有Z≈幅频关系和相频关系曲线:画出通频带曲线:计算谐振频率:fo=1/2π√LC04微分和积分电路注意要点:1、电路的作用,与滤波器的区别和相同点;2、微分和积分电路电压变化过程分析,画出电压变化波形图;3、计算:时间常数,电压变化方程,电阻和电容参数的选择。05共射极放大电路注意要点:1、三极管的结构、三极管各极电流关系、特性曲线、放大条件;2、元器件的作用、电路的用途、电压放大倍数、输入和输出的信号电压相位关系、交流和直流等效电路图;3、静态工作点的计算、电压放大倍数的计算。06分压偏置式共射极放大电路注意要点:1、元器件的作用、电路的用途、电压放大倍数、输入和输出的信号电压相位关系、交流和直流等效电路图;2、电流串联负反馈过程的分析,负反馈对电路参数的影响;3、静态工作点的计算、电压放大倍数的计算;4、受控源等效电路分析。07共集电极放大电路(射极跟随器)注意要点:1、元器件的作用、电路的用途、电压放大倍数、输入和输出的信号电压相位关系、交流和直流等效电路图,电路的输入和输出阻抗特点;2、电流串联负反馈过程的分析,负反馈对电路参数的影响;3、静态工作点的计算、电压放大倍数的计算。08电路反馈框图注意要点:1、反馈的概念,正负反馈及其判断方法、并联反馈和串联反馈及其判断方法、电流反馈和电压反馈及其判断方法;2、带负反馈电路的放大增益;3、负反馈对电路的放大增益、通频带、增益的稳定性、失真、输入和输出电阻的影响。09二极管稳压电路注意要点:1、稳压二极管的特性曲线;2、稳压二极管应用注意事项;3、稳压过程分析。10串联稳压电源注意要点:1、串联稳压电源的组成框图;2、每个元器件的作用;稳压过程分析;3、输出电压计算。11差分放大电路注意要点:1、电路各元器件的作用,电路的用途、电路的特点;2、电路的工作原理分析。如何放大差模信号而抑制共模信号;3、电路的单端输入和双端输入,单端输出和双端输出工作方式。12场效应管放大电路注意要点:1、场效应管的分类,特点,结构,转移特性和输出特性曲线;2、场效应放大电路的特点;3、场效应放大电路的应用场合。13选频(带通)放大电路注意要点:1、每个元器件的作用,选频放大电路的特点,电路的作用;2、特征频率的计算,选频元件参数的选择;3、幅频特性曲线。14运算放大电路注意要点:1、理想运算放大器的概念,运放的输入端虚拟短路,运放的输入端的虚拟断路;2、反相输入方式的运放电路的主要用途,输入电压与输出电压信号的相位关系;3、同相输入方式下的增益表达,输入阻抗,输出阻抗。15差分输入运算放大电路注意要点:1、差分输入运算放大电路的的特点,用途;2、输出信号电压与输入信号电压的关系式。16电压比较电路注意要点:1、电压比较器的作用,工作过程;2、比较器的输入-输出特性曲线图;3、如何构成迟滞比较器。17RC振荡电路注意要点:1、振荡电路的组成,作用,起振的相位条件,起振和平衡幅度条件;2、RC电路阻抗与频率的关系曲线,相位与频率的关系曲线;3、RC振荡电路的相位条件分析,振荡频率,如何选择元器件。18LC振荡电路注意要点:1、振荡相位条件分析;2、直流等效电路图和交流等效电路图;3、振荡频率计算。19石英晶体振荡电路注意要点:1、石英晶体的特点,石英晶体的等效电路,石英晶体的特性曲;2、石英晶体振动器的特点;3、石英晶体振动器的振荡频率。20功率放大电路注意要点:1、乙类功率放大器的工作过程以及交越失真;2、复合三极管的复合规则;3、甲乙类功率放大器的工作原理,自举过程,甲类功率放大器,甲乙类功率放大器的特点。超70G的基于STM32物联网开发资料零基础到实战、STM32热门项目合集内含丰富的STM32的设计理念、开发原理、项目实施过程、全国电赛优秀作品合集、物联网理论与实践、IoT-ARM、ESP32教程、四轴飞行器设计制作等资料合集STM32物联网:https://sourl.cn/e8XHeG40个G的百度网盘C语言、C++、Linux从入门、进阶到精通覆盖所有知识点,还有视频教程讲解、C语言的项目源码大全C语言/C++/Linux教程合集:https://sourl.cn/8SpsNv物联网开发 - 从0到1,设计自己的开发板就这么简单 - 创客学院直播室 -
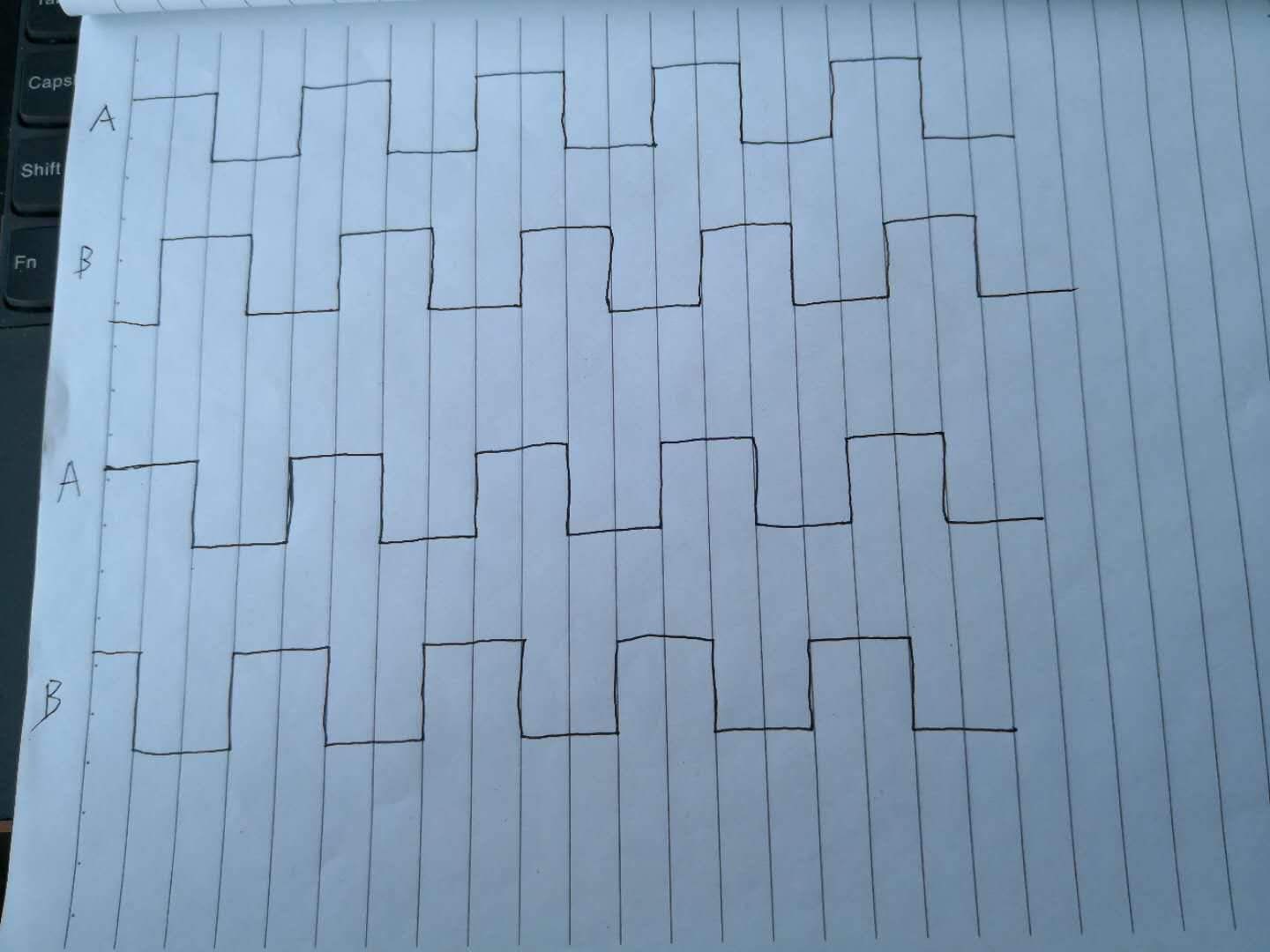
轮毂电机光电增量编码器的ABZ信号详解 轮毂电机ABZ信号详解。 轮毂电机的定位使用了霍尔信号和光电增量编码器,1024线的。也就意味着,轮子转一圈,A信号和B信号各有1024个高电平和低电平。实际应用中,我们将A/B信号的上升沿和下降沿分别设置为外部中断触发信号,这样,我们就进行了1024的四倍频,最后的结果就4096。 如下如所示:第一行是顺转,可以看到A比B快1/4个周期;第二行是倒转,A比B慢1/4个周期。 轮子机械角度上转一圈,A和B各有1024个周期,通过4倍频,就能实现轮子转一圈编码为4096了。 如何通过A和B判断转向呢: 第一行: A下降沿中断且B为高,或者A为上升沿中断且B为低 ,是顺转。 第二行: A下降沿中断且B为低,或者A为上升沿中断且B为高 ,是倒转。 Z信号相当于是每转一圈给一个脉冲。
-
RISC-V CPU侧信道攻击原理与实践 https://zhuanlan.zhihu.com/p/393106129RISC-V作为一种全新的开源CPU指令集体系结构(ISA),目前无论是在高校与各研究机构,还是商业应用中,皆方兴未衰,大有与X86和ARM形成成三足鼎立之势。但对于RISC-V CPU本身的安全, 却资料少而凌乱,晦涩难懂,面目狰狞,拒人于千里之外。故有此冲动,写几篇有关RISC-V CPU侧信道攻击的文章,介绍RISC-V CPU侧信道攻击的原理和作者本人的实践;作者研究CPU侧信道攻击的初衷也是为“防守”,意在为某款RISC-V CPU提供一个安全性验证平台,验证该CPU安全设计加固方案之有效性。我将用一系列文章来来介绍:什么是CPU侧信道攻击?导致CPU产生侧信道攻击风险的微架构设计技术Spectre攻击的种类与攻击方法细节;Meltdown攻击原理与工具过程;降低CPU侧信道攻击风险的手段那就让我们开始吧。侧信道攻击概述1.1什么是侧信道攻击1.1.1 日常生活中的侧信道攻击在科技日新月异的今天,在享受高科技带来的幸福感的同时,我们的隐私也会在不知不觉中从各种渠道被泄露出去,有些甚至你完全想不到,可以说防不胜防,比如说,你想过单从按键声音就分析出你的手机号码么?大家可能听说过网友“清华南都”就根据一段视频中的按键音,还原出了360总裁周鸿祎的手机号。事情起源于优酷的记者电话采访周鸿祎先生的一段视频. 在视频的第33-43秒,记者与周鸿祎先生进行了电话连线,视频播放把整个拨号过程也原封不动地播放了出来,包括在电话拨号阶段的产生的电话拨号音,“清华南都”就根据这段拨号音结合一些DTMF(双音多频, Dual-tone multi-frequency)的技术基础,破解这个电话号码;在这个事情中,如果把周鸿祎先生的电话号码当做一个高度机密信息(private data)的话,“清华南都”本人并没有看到过周先生的电话号码,也没有采用暴力破解的方式一个个电话号码去尝试,而“清华南都”通过分析声音特征信息获取了该机密信息,这个过程从技术范畴的角度讲就是一种利用了声波信息的“侧信道攻击”。那到底什么是侧信道攻击?维基百科是这么定义的:“在密码学中,侧信道攻击(Side-channel attack)是一种攻击方式,它基于从密码系统的物理实现中获取的信息,而非暴力破解法或是算法中的理论性缺陷,例如利用时间信息、功率消耗、电磁泄露或甚是声音可以提供额外的信息,来对系统的破解。”这个定义对于非密码学行业从业人员来讲还是非常抽象的。我们简单一点理解就是利用一些“旁门左道”的手法来获取我们需要的机密信息;比如我们经常在电视剧中看到的一个场景:一个窃贼将听诊器压在保险柜的前面板上,通过内部的机械声来打开保险柜。小偷会慢慢地转动转盘,听着内部机械结构所泄露出的咔哒声或阻力声,来分析保险箱齿轮的内部运作,并从而得知其密码的组合。除了拨号盘上的数字和保险柜“是”或“否”的打开状态以外,这个保险柜并不会给用户任何反馈。但保险箱的物理机械所产生的那些微小的触动和声音线索,这也是一个典型的侧信道攻击。某网站(https://www.wired.com/story/lamphone-light-bulb-vibration-spying/...)曾经公布了一项新技术(lamphone):“通过使用望远镜观察室内悬挂的灯泡的振动(通过灯泡所发出的光的微弱变化),可以实时窃听房间内的对话”。这种技术将测信道攻击变得更加具有广泛性。1.1.2 计算机领域的侧信道攻击计算机领域的侧信道攻击是利用计算机不经意间释放出的信息信号(如电磁辐射,电脑硬件运行产生的声音)来进行破译的攻击模式:例如,黑客可以通过计算机显示屏或硬盘驱动器所产生的电磁辐射,来读取你所显示的画面和磁盘内的文件信息;或是,通过计算机组件在执行某些程序时需要消耗不同的电量,来监控你的电脑;亦或是,仅通过键盘的敲击声就能知道你的账号和密码。最早的计算机侧信道攻击之一,是美国国家安全局(National Security Agency)所称的TEMPEST。1943年贝尔实验室发现,每当有人在电传打字机上打字时,电传打字机会导致附近示波器的读数移动。贝尔实验室的研究人员很快意识到这一问题。电传打字机的目的是为了实现安全、加密的通信,但任何接近它的人,只要能读到它的电磁辐射,就有可能破译它的秘密。这种现象直到1985年才被完全公开记录下来,当时一位名叫维姆·范·埃克(Wim van Eck)的计算机研究人员发表了一篇论文,这就是后来被称为 "屏幕辐射窃密(van Eck phreaking)",即通过远距离检测电脑屏幕放电的电信号,在电脑屏幕上重建图像。计算机领域的侧信道攻击,目前使用最为广泛的攻击手段就是基于时序的攻击(timing attack)。讲了那么多故事,让我们来看一段代码直观地了解一下什么是时序攻击:这是某产品中的一个秘钥比对函数,假设这个函数的用户无法看到源码(也不进行反汇编),我们只是通过库函数的头文件知道这个函数接口定义为int does_password_match(char * input_password)。那我们怎么能够快速地获取函数内部设定的机密信息strPrivateKey的值呢?你可能首先想到的是采用暴力破解方式,逐一尝试各种字符组合,直到函数返回true为止;如果这个秘钥只使用字母和数字,并且秘钥的最大长度7,那你需要尝试的最大次数为62**7=3,521,614,606,208【注26大写字母+26小写字母+10数字)。如果我们利用一下这个函数的timing信息,测量一下这个函数的处理时间,我们其实可以有一种更为快捷的方法,我们可以采用逐位破解的方法快速地完成这个任务;因为我们输入的密码与机密信息的匹配度越高,该函数的处理时间越长,这样我们通过测量这个函数的处理时间就可以判断前面的第一位,第二位,第三位等是否验证通过;则最坏的尝试的次数为62*7=434;用这种方式实现的一个产品(比如密码门禁系统),通过采用timing-attack的方法,其破解是完全可以通过人力的方式在数分钟内完成的;1.1.3 CPU的侧信道攻击目前随着超标量CPU技术的飞速发展,其处理性能大幅提升的同时, 以计算机为中心的侧信道攻击也变得更加复杂和手段多样。所谓道高一尺,魔高一丈; 2018伊始,两个芯片级漏洞Meltdown(熔断)、Spectre(幽灵)漏洞震惊了安全界。受影响的CPU包括Intel、AMD和ARM,基本囊括的消费级CPU市场的绝大部分。Meltdown漏洞可以在用户态越权读取内核态的内存数据,Spectre漏洞可以通过浏览器的Javascript,读取用户态的内存数据。这两个漏洞摧毁了公有云的基石(用户数据隔离),因为通过Meltdown和Spectre的攻击,用户在虚拟机里就可以无限制的读取宿主机或者其他虚拟机的数据。Spectre、Meltdown等攻击方式利用了微处理器的 "微架构"设计中的这些特性(站在安全的角度也可以叫漏洞,包括但不局限于分支预测,推断执行,乱序执行,等)。随着计算机变得越来越复杂,如果计算行业继续优先考虑性能而不是安全,侧信道攻击将会越来越猖獗,今天一个你看似巧妙的设计,非常有可能成为明天攻击的一个突破口。1.2 侧信道攻击的分类对于CPU侧信道攻击,很多公司(比如google和微软)成立了专门的安全团队,用来发现目前市场上主流CPU的安全风险并提供安全解决方案以降低危害(mitigation of the risk)。 随着对上述meltdown和Spectre攻击方式的研究深入,越来越多的基于meltdown和spectre的变种被开发了出来。参考文献[A Systematic Evaluation of Transient Execution Attacks and Defenses]对瞬态执行攻击进行了系统的分析,并把当前已经发现的针对CPU微架构的侧信道攻击方法进行了总结与归类(见图),文献的作者认为当前大部分的安全防护方法无法有效应对当前如此多的攻击方式带来的安全风险。本系列文章主要描述如下几种Spectre变种攻击方式:• Variant 1 (Spectre_PHT): bounds check bypass• Variant 2 (Spectre_BTB): branch target injection• Variant 4 (Spectre_STL): Store bypass• Variant 5 (Spectre_RSB): Return Stack Buffer【注:PHT: Pattern History Table, BTB:Branch Target Buffer, STL:Store To Load, RSB:Return Stack Buffer】Meltdown属于 Variant 3, Meltdown还可以进一步细分为:• Meltdown-US(Supervisor-only Bypass)• Meltdown-P(Virtual Translation Bypass)• Meltdown-GP(System Register Bypass)• Meltdown-NM(FPU Register Bypass)• Meltdown-RW(Readonly Bypass)• Meltdown-PK(Protection Key Bypass)• Meltdown-BR(Bounds Check Bypass)我们重点关注高性能CPU的一些通用设计带来的风险,而对于某些厂家独特设计带来的问题,本文不做过多的描述。
-
windows 知识汇总 1 右键菜单添加使用gvim打开方式①打开注册表编辑器,开始-->运行-->regedit②定位到:HKEY_CLASSSES_ROOT---> * --->Shell,在Shell 上右击,新建---> 项,输入: Open With gvim(使用vim打开)③在 Open With gvim 右键--->新建--->字符串值,数值名称设置为:Icon,数值数据设置为:C:\MyProgram\gvim73\gVimPortable\vim\vim73\gvim.exe,0数值名称:Icon数值数据:C:\MyProgram\gvim73\gVimPortable\vim\vim73\gvim.exe,0④在刚才新建的项:Open With gvim 下面添加一个新项:Command修改 Commnad 项右边窗口的数值数据为:C:\MyProgram\gvim73\gVimPortable\vim\vim73\gvim.exe %1C:\MyProgram\gvim73\gVimPortable\vim\vim73\gvim.exe %1上面的设置会带来一个小问题:当文件名的最后一个字符为空格时,使用GVIM打开某个文件时会新建一个空白的文件,而不是直接打开该文件。解决方法:加引号,如下:C:\MyProgram\gvim73\gVimPortable\vim\vim73\gvim.exe "%1"效果如下:本文转自hapjin博客园博客,原文链接:http://www.cnblogs.com/hapjin/,如需转载请自行联系原作者2 windows 家庭版添加gpedit@echo off pushd "%~dp0" dir /b C:\Windows\servicing\Packages\Microsoft-Windows-GroupPolicy-ClientExtensions-Package~3*.mum >List.txt dir /b C:\Windows\servicing\Packages\Microsoft-Windows-GroupPolicy-ClientTools-Package~3*.mum >>List.txt for /f %%i in ('findstr /i . List.txt 2^>nul') do dism /online /norestart /add-package:"C:\Windows\servicing\Packages\%%i" pause
-
各个系统下效率提升工具 windowsutools 快速启动软件文件夹或者自定义功能uTools 是一个极简、插件化的现代桌面软件,通过自由选配丰富的插件,打造得心应手的工具集合。通过快捷键(默认 alt + space )就可以快速呼出这个搜索框。你可以往输入框内粘贴文本、图片、截图、文件、文件夹等等,能够处理此内容的插件也早已准备就绪,统一的设计风格和操作方式,助你高效的得到结果至于好用的截图工具snipaste、历史剪切板工具ditto,ocr 工具等等,在utools 都包含了其功能,甚至是自动化处理流程,utools 还有很多其他插件,等待你去探索,任何一个操作都可以自定义快捷键。还支持window、linux、macos。quicker 自动化鼠标键盘工具,可以自定义自动化工作流、根据当前窗口进程自动弹出自定义操作你的指尖工具箱,提供快捷面板和组合动作定制的自动化工作流神器。 简介 Quicker 是一款专为Windows操作系统设计的高效率工具,它通过引入快捷面板和组合动作功能,致力于简化用户的操作流程,大幅提升工作效率。 Quicker让用户能够创建个性化的捷径,自动化执行一系列复杂任务,并通过多种触发方式快速执行这些任务。 产品功能 快捷面板:提供一键访问常用操作和软件的功能,快速启动应用或执行命令quicker 这个工具除了可以模拟键盘鼠标的任何操作,一键输入用户名密码,还可以识别当前的活动窗口进程,根据不同的活动窗口弹出的操作界面不一样,特别方便,比如识别到当前窗口是wps,按快捷键启动quicker ,弹出的窗口的操作都是wps 的操作。文件或者文件夹快速搜索:Everything"Everything" 是 Windows 上一款搜索引擎,它能够基于文件名快速定文件和文件夹位置。您在搜索框输入的关键词将会筛选显示的文件和文件夹;如果日常生活工作涉及各种文件,那这个工具你绝对不容错过。个人总结:速度非常快,随点随用,比Windows自带的好用太多;搜索全面,连回收站里未清空的文件都能搜索出来;体积很小、完全免费、绿色无广告;支持关键词+检索式检索文档内容搜索:anytxt searchAnytxt Searcher(中文名:文件内容秒搜软件),是一个功能强大的本地全文搜索工具。它内置了一个强悍的文档分析器,几乎可以在1秒以内,搜索出存储在电脑里面所有文字内容。Anytxt Searcher支持对100多种格式文件的全文搜索,包括:文本文档 (txt、cpp、py、java、css 等)Microsoft Outlook电子邮件 (eml)Word文档 (doc、docx)Excel文档 (xls、xlsx)PPT文档 (ppt、pptx)PDF文档格式(pdf)WPS Office文档格式 (wps、et、dps)开放文档格式 (OpenOffice、LibreOffice、ofd 等)电子书格式 (epub、mobi、chm、fb2、azw 等)思维导图格式 (xmind、mm、mmap、lighten 等)图片格式[OCR版] (jpg、png、bmp 等)二进制文件(exe、dll、so 等)压缩归档文件(zip、7z、rar、iso 等)日历 任务 番茄时间管理 :时光序 时光序是一款帮你规划日程、高效完成事务的时间管理应用。它的一大特色之一便是功能强大却不复杂,简约的同时却不简单。 文件浏览&&预览:double commanderDouble Commander 是一款开源的跨平台文件管理软件,灵感来源于 Total Commander,采用了两栏式界面设计,支持 Windows、Linux 和 MacOS 系统。该软件的开发始于 2007 年,旨在提供一个高效、功能丰富的文件管理解决方案。Double Commander 的特点包括对各种文件和压缩包格式的支持,内置文件查看器和文本编辑器,以及可定制的快捷键和外观。用户可以通过插件扩展其功能,满足不同的文件管理需求。优点方面,Double Commander 提供了强大的文件搜索、比较和同步功能,支持批量重命名,且其用户界面可以高度定制,使得文件管理工作更加高效。linuxutools 快速启动软件文件夹或者自定义功能uTools 是一个极简、插件化的现代桌面软件,通过自由选配丰富的插件,打造得心应手的工具集合。通过快捷键(默认 alt + space )就可以快速呼出这个搜索框。你可以往输入框内粘贴文本、图片、截图、文件、文件夹等等,能够处理此内容的插件也早已准备就绪,统一的设计风格和操作方式,助你高效的得到结果至于好用的截图工具snipaste、历史剪切板工具ditto,ocr 工具等等,在utools 都包含了其功能,utools 还有很多其他插件,等待你去探索,任何一个操作都可以自定义快捷键。autokey 自动化鼠标键盘工具,可以自定义自动化工作流AutoKey 是一款专为Linux和X11桌面环境设计的自动化工具,它允许用户通过脚本和快捷方式自动执行常见的输入任务,极大地提高效率。此项目原托管于Google Code,现已全面更新以支持Python 3文件或者文件夹快速搜索: FsearchFSearch 是 Linux 上的一个免费文件搜索工具。据说它的灵感来自于“Everything”搜索引擎,这是一个流行的搜索工具,用于在 Windows上查找文件和文件夹。FSearch 基于 GTK3,用 C 语言编写。除此之外,这使得它在 Linux 上索引和搜索文件时非常快。此外,增加了对使用正则表达式查询的支持,从而实现更快、更灵活的搜索体验。FSearch 有哪些功能?FSearch 是 Linux 上功能丰富的搜索实用程序之一。因此,它带来了以下特性:快速索引即时结果(在输入查询时开始显示结果)高级搜索(支持各种操作符、通配符、修饰符和函数)正则表达式查询过滤器(用于将搜索范围缩小到文件、文件夹或两者都有)快速排序(具有多个排序选项)可定制的用户界面文档内容搜索:docfectcherDocFetcher 直译的意思是“文档获取者”,是一款“站在文件夹顶端”的桌面全文检索引擎。DocFetcher 能够在你指定的一堆文件里,用关键词秒级定位到含有该文字的具体位置,并把上下文像搜索引擎那样高亮呈现出来。DocFetcher 支持 Word、Excel、PPT、PDF、EPUB、TXT、HTML、代码文件(C/C++、Java、Python、Go 等)、邮件 eml、压缩包 zip/7z/rar(内层文件也能穿透)等 40 余种格式,只要先让它“索引”一次,以后每次搜索都像是把 Google 搬进自己硬盘,回车一按,结果立现。日历 任务 番茄时间管理 :时光序 时光序是一款帮你规划日程、高效完成事务的时间管理应用。它的一大特色之一便是功能强大却不复杂,简约的同时却不简单。 文件浏览&&预览:doublecommanderDouble Commander 是一款开源的跨平台文件管理软件,灵感来源于 Total Commander,采用了两栏式界面设计,支持 Windows、Linux 和 MacOS 系统。该软件的开发始于 2007 年,旨在提供一个高效、功能丰富的文件管理解决方案。Double Commander 的特点包括对各种文件和压缩包格式的支持,内置文件查看器和文本编辑器,以及可定制的快捷键和外观。用户可以通过插件扩展其功能,满足不同的文件管理需求。优点方面,Double Commander 提供了强大的文件搜索、比较和同步功能,支持批量重命名,且其用户界面可以高度定制,使得文件管理工作更加高效。macosutools 快速启动软件文件夹或者自定义功能uTools 是一个极简、插件化的现代桌面软件,通过自由选配丰富的插件,打造得心应手的工具集合。通过快捷键(默认 alt + space )就可以快速呼出这个搜索框。你可以往输入框内粘贴文本、图片、截图、文件、文件夹等等,能够处理此内容的插件也早已准备就绪,统一的设计风格和操作方式,助你高效的得到结果至于好用的截图工具snipaste、历史剪切板工具ditto,ocr 工具等等,在utools 都包含了其功能,utools 还有很多其他插件,等待你去探索,任何一个操作都可以自定义快捷键。KeysmithKeysmith 描述自己为「创建自定义快捷键」,实在是有些谦虚,看似简单的功能其实给了用户很大的想象空间。与 Automator 相反,Keysmith 的设计十分克制,你并不可以凭空添加自动化动作,一切动作都始于你的「录制」。也正因这份克制,Keysmith 拥有十分简洁的界面。文件或者文件夹快速搜索: Pro Everything闪电般的搜索速度:全盘文件秒级定位,比 Spotlight 快 100 倍,输入文件名瞬间出结果!隐藏文件全覆盖:系统文件、隐藏文件一个不漏,连 ~/.ssh 这种隐藏文件都能轻松搜出来,Spotlight 直接被秒成渣!文件预览如丝般顺滑:搜索结果直接预览文件内容,省去打开文件的麻烦,效率党狂喜!批量操作逆天省时:支持批量移动、复制、删除,处理上千个文件很轻松!拖放交互超爽:搜索结果直接拖到其他应用,文件分享、编辑很方便,工作效率直接翻倍!隐私保护滴水不漏:仅收集设备序列号和系统版本号,数据安全到让你放心!多语言搜索无压力:中文、英文、日文随便搜,全球用户都能用得爽!轻量级设计:软件体积小到感人,资源占用低文档内容搜索:recollRecoll,跨平台( Recoll是一款开源的桌面搜索软件,支持Windows、Mac和Linux系统)免费的全文搜索软件,支持索引.Recoll是一款开源全文搜索软件,它通过智能索引技术,能够快速定位您电脑中的文件内容。无论是文档、电子书还是其他各类文件,Recoll都能轻松地帮助您找到所需信息,提高工作效率。项目技术分析核心技术Recoll 版本的核心技术是基于Xapian的全文搜索引擎。Xapian是一个开源的搜索引擎库,以其高效性和灵活性著称。以下是该软件的主要技术亮点:全文检索:通过全文检索技术,Recoll能够深入文件内部,搜索到关键词的确切位置。索引构建:软件会自动对指定文件夹内的文件进行索引,加快搜索速度。多格式支持:Recoll支持多种文件格式,包括txt、doc、pdf等,满足不同用户的需求。技术架构Recoll的技术架构主要包括以下几个部分:用户界面:采用简洁直观的图形界面,方便用户操作。索引引擎:基于Xapian的索引引擎,保证搜索的快速和准确。日历 任务 番茄时间管理 :时光序 时光序是一款帮你规划日程、高效完成事务的时间管理应用。它的一大特色之一便是功能强大却不复杂,简约的同时却不简单。 文件浏览&&预览:double commanderDouble Commander 是一款开源的跨平台文件管理软件,灵感来源于 Total Commander,采用了两栏式界面设计,支持 Windows、Linux 和 MacOS 系统。该软件的开发始于 2007 年,旨在提供一个高效、功能丰富的文件管理解决方案。Double Commander 的特点包括对各种文件和压缩包格式的支持,内置文件查看器和文本编辑器,以及可定制的快捷键和外观。用户可以通过插件扩展其功能,满足不同的文件管理需求。优点方面,Double Commander 提供了强大的文件搜索、比较和同步功能,支持批量重命名,且其用户界面可以高度定制,使得文件管理工作更加高效。iosLock Launcher锁屏启动 (Lock Launcher) 是一款 iOS 16 专用的「锁屏小组件」增强 APP 工具,可帮助用户快速一键启动:任意 APP / 微信或支付宝的健康码 (全国或分省) / 出示行程码 / 微信扫一扫 / 收付款码 (支付宝、云闪付) / 乘车码 / 快捷指令 / 网页 Web Apps / URL Scheme / 调用系统功能等,让新的锁屏界面发挥出应有的高效!快捷指令快捷指令是一种可让你使用 App 完成一个或多个任务的快捷方式。“快捷指令” App 可让你创建包含多个步骤的快捷指令。例如,你可以构建一个“冲浪时间”快捷指令来获取冲浪报道、提供预计到达海滩的时间以及播放冲浪音乐播放列表。文件或者文件夹快速搜索:easy searcheasySearch is a fast and efficient search and research tool for your iPad and iPhone. Search for text in files stored on your device, in iCloud, Dropbox, OneDrive, network and external media. Save your findings and track your progress.Find text in different storage locations文档内容搜索:FindText Find and replace text:1). Enter or Paste your text from the clipboard into the TextView2). You can choose Find or Replace function3). Enter the word or phrase you want to replace in Find what.4). Enter your new text in Replace with.日历 任务 番茄时间管理 :时光序 时光序是一款帮你规划日程、高效完成事务的时间管理应用。它的一大特色之一便是功能强大却不复杂,简约的同时却不简单。 文件浏览&&预览:ES文件浏览ES文件浏览器是一款功能强大的本地和网络文件管理器,支持多种文件管理和传输功能,广受用户欢迎。主要功能文件管理:ES文件浏览器支持多种视图和排序方式,用户可以方便地查看和打开各类文件。它允许在本地SD卡、局域网、OTG设备和互联网计算机之间自由传输文件。 应用管理:用户可以通过该应用安装、卸载和备份程序,并创建快捷方式,方便管理手机应用。 压缩与解压:支持文件的压缩和解压功能,用户可以轻松处理ZIP、RAR等格式的文件。 文本编辑:内置强大的文本编辑器,用户可以查看和编辑文本文件。 FTP和局域网访问:用户可以访问远程FTP服务器和局域网内的所有计算机,方便文件的共享和管理。 视频编辑:支持视频转GIF、视频拼接、添加音乐/字幕等功能,增强了多媒体处理能力。 云存储支持:用户可以同时登录多个云存储账号,方便管理和访问网络存储空间。AndroidFast! 快速启动软件文件夹或者自定义功能无论你是职场人士,需要在众多会议应用间快速切换,还是学生族,寻找快速访问学习工具的方式,FAST都能大显身手。对于那些追求效率的极客来说,这款应用更是如虎添翼,通过自定义设置和快捷操作选项(如长按应用图标进行深度管理),极大地提高了设备使用的便捷度。项目特点超快启动:仅需少量字符就能定位到应用。极致简约:不需要额外权限,保障隐私安全。灵活定制:用户可自由调整应用标签或创建快捷方式。高级功能:包括应用锁定、隐藏、通知访问等。开源精神:基于GPLv3许可,鼓励社群参与与贡献。社区支持:活跃的Google+社区,随时解答疑惑。MacroDroid 一款自动化神器——MacroDroid 这可不是什么普通的应用,它是一款功能强大的任务自动化和配置应用程序,能让你的手机变得更智能,从此告别繁琐的手动操作。是一个强大的Android自动化工具,它可以让你的手机根据特定的触发条件自动执行任务。这些任务可以是简单的,比如发送消息、连接网络,也可以是复杂的,比如根据你的位置自动调整手机设置。MacroDroid的界面直观,操作简单,即使是初学者也能轻松上手。文件或者文件夹快速搜索:anysearch这是一个快速搜索文件的工具。1).支持系统目录搜索(需要Root,无Root也可搜索部分系统文件,如系统Apk)2).支持通配符和正则表达式3).支持路径搜索4).支持媒体文件信息预览5).支持多种查看方式文档内容搜索:Anything安卓app手机版是一款安卓手机版的EverythingAnything安卓app手机版是一款安卓手机版的Everything,相信很多用户都对Everything这款PC上的搜索软件比较了解,这款Anything可以说是同样的强大,快速,简洁,准确,可以帮助搜索到很多文件,包括文件名,甚至文件中的内容都能搜到,非常好用。软件特色1)、按照文件名搜索,软件下方有视频、音乐、图片、文档四个分类可以筛选。2)、输入文件后缀也能快速找到文件,比如输入.mp4就能看到自己收藏的文件。3)、如果你实在想不起文件名,别急,它还支持文档搜索,输入文档中的内容也能搜到该文件。4)、Office 文档中除了Word,PPT和Excel表格正文也是支持的。5)、它支持文件忽略大小写搜索,长按文件的话可以直接在APP中打开文件所在路径,不过这里只能删除文件不支持重命名等其他操作。6)、除了上面提到的文件名搜索和office文档正文外,Anything还支持目录名搜索日历 任务 番茄时间管理 :时光序 时光序是一款帮你规划日程、高效完成事务的时间管理应用。它的一大特色之一便是功能强大却不复杂,简约的同时却不简单。 文件浏览&&预览:ES文件浏览ES文件浏览器是一款功能强大的本地和网络文件管理器,支持多种文件管理和传输功能,广受用户欢迎。主要功能文件管理:ES文件浏览器支持多种视图和排序方式,用户可以方便地查看和打开各类文件。它允许在本地SD卡、局域网、OTG设备和互联网计算机之间自由传输文件。 应用管理:用户可以通过该应用安装、卸载和备份程序,并创建快捷方式,方便管理手机应用。 压缩与解压:支持文件的压缩和解压功能,用户可以轻松处理ZIP、RAR等格式的文件。 文本编辑:内置强大的文本编辑器,用户可以查看和编辑文本文件。 FTP和局域网访问:用户可以访问远程FTP服务器和局域网内的所有计算机,方便文件的共享和管理。 视频编辑:支持视频转GIF、视频拼接、添加音乐/字幕等功能,增强了多媒体处理能力。 云存储支持:用户可以同时登录多个云存储账号,方便管理和访问网络存储空间。关于anytxt search、docfetcher、recoll等文件内容搜索的工具的比较,详见:http://www.bennyhe.cn/index.php/archives/357/