搜索到
1
篇与
的结果
-
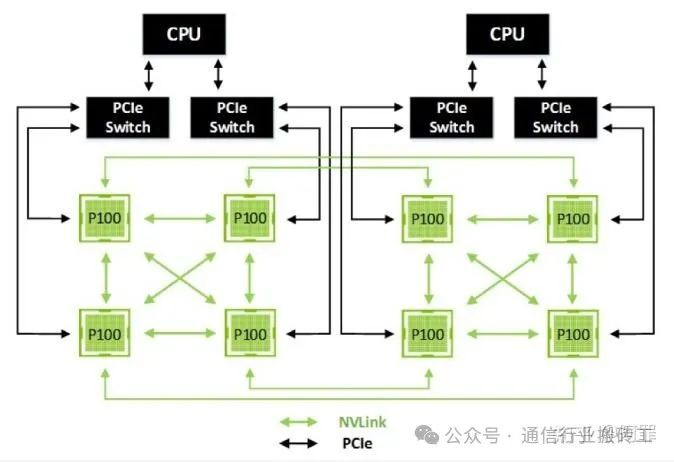
 NVLink1.0~5.0: 高速互联的架构演进之路 01、引言:数据时代的“高速公路”在人工智能(AI)和高性能计算(HPC)的浪潮中,计算能力的提升不仅依赖于处理器性能,还需要高效的数据传输通道。传统 PCIe 互联虽广泛应用,但其带宽和延迟已难以满足现代计算需求。NVIDIA 的 NVLink 应运而生,作为一种高速、低延迟的点对点互联技术,它为多 GPU 和 CPU-GPU 系统提供了“数据高速公路”,显著提升了计算效率。本文将从技术视角深入剖析 NVLink 的架构、演进历程、应用场景及生态布局,为科技人士、通信工程师和学术研究者提供全面洞察。02、NVLink架构:技术核心与关键特性NVLink 是 NVIDIA 专为高性能计算设计的互联技术,旨在实现 GPU 间或 GPU 与 CPU 间的高速数据交换。其架构基于点对点通信,采用多通道设计,每个通道(称为“链接”)包含多个差分对,提供高带宽和低延迟的数据传输。核心特性高带宽:NVLink 提供远超 PCIe 的带宽。例如,最新 NVLink 5.0 单链接双向带宽达 200 GB/s,总带宽可达 1.8 TB/s,而 PCIe 5.0 x16 仅约 126 GB/s。低延迟:通过专用通道和优化协议,NVLink 显著降低数据传输延迟,适合实时计算任务。缓存一致性:NVLink 支持 GPU 间或 GPU-CPU 间的缓存一致性,允许共享统一内存空间,减少数据拷贝开销。可扩展性:结合 NVSwitch,NVLink 支持全连接拓扑,使多 GPU 系统实现高效通信。NVLink 的工作原理类似高速公路网络:每个 GPU 或 CPU 是“城市”,链接是“车道”,NVSwitch 则像“交通枢纽”,确保数据流畅无阻。这种设计特别适合需要大规模并行计算的场景,如 AI 模型训练和科学模拟。03、技术演进:从NVLink 1.0到5.0 的跨越NVLink 自 2016 年首次亮相以来,经历了五代技术迭代,每一代都针对计算需求的增长进行了优化。版本年份GPU 架构每链接带宽(双向,GB/s)链接数总带宽(GB/s)备注1.02016Pascal404160首代,Tesla P1002.02017Volta506300支持 NVSwitch,DGX-13.02020Ampere5012600A100 GPU,广泛用于云4.02022Hopper10018900H100 GPU,PAM4 编码5.02024Blackwell200181800GB200 NVL72,AI 优化以下是对其演进历程的详细分析,涵盖技术原理、软硬件架构及技术演进亮点。1、NVLink 1.0(2016):开创高速互联先河GPU架构:Pascal(Tesla P100)带宽:每链接 40 GB/秒(双向,20 GB/秒单向),P100 支持 4 个链接,总带宽 160 GB/秒。技术原理:采用 NRZ(非归零)信号编码,每个时钟周期传输 1 位数据。NVLink 使用差分对传输,包含 8 条子通道,每条子通道运行在 20 Gbps。协议栈基于定制的点对点通信,优化了数据包格式,减少了传输开销。软硬件软件架构:NVLink 1.0 直接集成在 P100 GPU 芯片上,每个链接占用专用硅片区域。软件方面,CUDA 7.0 引入了cudaMemcpyPeer API技术,支持GPU间直接内存拷贝,简化了多GPU编程。技术演进亮点:首次亮相于Pascal架构的Tesla P100,提供160GB/s总带宽,较PCIexpress 3.0x16(约32GB/s)提升数倍,奠定了多GPU互联基础。应用场景:主要用于早期深度学习任务,如图像识别模型(如 ResNet)的训练。DGX-1 系统首次采用 NVLink 1.0,连接 8 个 P100 GPU,奠定了多 GPU 系统的基础。挑战与突破:NVLink 1.0 的主要挑战是链接数量有限,仅支持 4 个链接,限制了多 GPU 系统的扩展性。NVIDIA 通过优化协议和硬件设计,确保了低延迟和高可靠性,为后续版本奠定了技术基础。2、NVLink 2.0(2017):引入 NVSwitch,扩展规模GPU架构:Volta(Tesla V100)带宽:每链接 50 GB/秒(双向,25 GB/秒单向),V100 支持 6 个链接,总带宽 300 GB/秒。技术原理:继续使用 NRZ 编码,但通过提高时钟频率和优化信号完整性,将单链接带宽提升 25%。引入 NVSwitch,一个高性能交换矩阵,支持全连接拓扑,允许多达 16 个 GPU 直接通信。NVSwitch 包含 18 个 NVLink 端口,每个端口提供 50 GB/秒带宽,总吞吐量达 900 GB/秒。软硬件架构:NVSwitch 作为独立芯片,集成在 DGX-2 系统,连接 16 个 V100 GPU。软件方面,CUDA 9.0 和 NCCL 2.0 优化了集体通信操作(如 all-reduce),提升了分布式训练效率。NVLink 2.0 支持缓存一致性,允许多 GPU 共享统一内存空间。技术演进亮点:引入 NVSwitch,支持全连接拓扑,带宽增至 300 GB/s,广泛用于 DGX-1 系统。应用场景:广泛用于 AI 研究和企业级应用,如自然语言处理(BERT 模型)和推荐系统训练。Summit 超级计算机(橡树岭国家实验室)采用 NVLink 2.0,连接 IBM Power9 CPU 和 V100 GPU,位列全球超算前列。挑战与突破:NVLink 2.0 解决了扩展性问题,但 NVSwitch 的引入增加了系统复杂性和成本。NVIDIA 通过优化交换矩阵设计和协议栈,确保了高吞吐量和低延迟。3、NVLink 3.0(2020):链接数量翻倍GPU架构:Ampere(A100)带宽:每链接 50 GB/秒(双向),A100 支持 12 个链接,总带宽 600 GB/秒。技术原理:维持 NRZ 编码,但通过增加链接数量(从 6 到 12),将总带宽翻倍。引入多实例 GPU(MIG)技术,允许将 A100 GPU 虚拟化为多个独立实例,每个实例可分配 NVLink 链接,提升资源利用率。协议栈进一步优化,支持更高效的缓存一致性。软硬件架构:A100 GPU 的 NVLink 端口集成在芯片边缘,采用高密度封装技术。DGX A100 系统使用 8 个 A100 GPU,通过 NVSwitch 连接,提供 4.8 TB/秒的内部带宽。CUDA 11.0 和 NCCL 2.7 增强了对 NVLink 3.0 的支持,优化了分布式训练和推理。技术演进亮点:链接数翻倍至 12,带宽达 600 GB/s,搭配 A100 GPU,满足大模型训练需求。应用场景:云服务(如 AWS P4d 实例)、AI 训练和推理,以及 HPC 任务(如分子动力学模拟)。A100 的 MIG 功能特别适合云端多租户环境。挑战与突破:链接数量的增加提高了芯片设计复杂性,NVIDIA 通过先进的硅片布局和信号完整性技术解决了这一问题。MIG 技术的引入进一步提升了灵活性。4、NVLink 4.0(2022):PAM4 信号革命GPU架构:Hopper(H100)带宽:每链接 100 GB/秒(双向,50 GB/秒单向),H100 支持 18 个链接,总带宽 900 GB/秒。技术原理:首次采用 PAM4(4 级脉冲幅度调制)信号编码,每个时钟周期传输 2 位数据,较 NRZ 翻倍数据率。PAM4 要求更高的信噪比,NVIDIA 通过先进的纠错码(ECC)和信号调制技术确保可靠性。协议栈优化了流量管理,支持动态带宽分配。软硬件架构:H100 GPU 使用 TSMC 4nm 工艺,NVLink 端口数量增至 18,集成在芯片边缘的高速 I/O 区域。DGX H100 系统通过 NVSwitch 连接 8 个 H100 GPU,提供 7.2 TB/秒的内部带宽。CUDA 12.0 和 NCCL 2.10 引入了新的通信原语,优化了超大规模模型训练。技术演进亮点:采用 PAM4 编码,链接数增至 18,总带宽 900 GB/s,H100 GPU 成为 HPC 标杆。应用场景:训练超大规模 AI 模型(如 GPT-4)和高精度科学模拟(如量子化学计算)。H100 的 NVLink 4.0 特别适合需要极高吞吐量的任务。挑战与突破:PAM4 的复杂性增加了设计难度,NVIDIA 通过优化信号处理和芯片布局,确保了高性能和可靠性。5、NVLink 5.0(2024):面向 exascale 计算GPU架构:Blackwell(B200)带宽:每链接 200 GB/秒(双向,100 GB/秒单向),B200 支持 18 个链接,总带宽 1.8 TB/秒。技术原理:进一步优化 PAM4 编码,通过提高时钟频率和信号调制效率,将单链接带宽翻倍。引入 NVLink-C2C(Chip-to-Chip)技术,支持与 Grace CPU 的高速连接,提供 900 GB/秒的 CPU-GPU 带宽。协议栈支持动态流量优先级,确保多种工作负载的平衡。软硬件架构:B200 GPU 使用 3nm 工艺,NVLink 端口采用高密度封装,支持更高的信号密度。GB200 NVL72 系统连接 72 个 Blackwell GPU,通过 NVSwitch 提供 130 TB/秒的内部带宽。CUDA 13.0 和 NCCL 2.12 优化了 exascale 级通信模式。技术演进亮点:带宽翻倍至 1.8 TB/s,搭配 Blackwell 架构的 GB200 NVL72,支持超大规模 AI 集群。应用场景:exascale 级别的 AI 和 HPC 任务,如气候建模、基因组分析和超大规模语言模型训练。NVLink-C2C 特别适合 CPU-GPU 协同计算。挑战与突破:高带宽和高链接数量增加了功耗和散热挑战,NVIDIA 通过先进的电源管理和冷却技术解决了这些问题。04、NVLink技术原理分析信号技术NVLink 的信号技术从 NRZ 进化到 PAM4。NRZ 每个时钟周期传输 1 位数据,而 PAM4 传输 2 位,通过四种电平表示 00、01、10、11。这使得在相同物理带宽下,数据传输率翻倍。PAM4 虽然对信噪比要求更高,但通过先进的纠错码(ECC)和信号调制技术,NVLink 4.0 及以后的版本成功实现了高可靠性的高速传输。协议栈NVLink 使用定制的协议栈,优化了数据包格式和传输机制。与 PCIe 相比,NVLink 的协议更精简,减少了开销,降低了延迟。协议支持多种流量类型,包括内存访问、I/O 操作和消息传递,确保了灵活性和高效性。NVLink 5.0 引入了动态流量优先级,允许根据工作负载需求调整带宽分配。缓存一致性NVLink 支持硬件级的缓存一致性,允许多个 GPU 共享统一的内存地址空间,而无需软件干预。这通过目录式缓存一致性协议实现,类似于多核 CPU 的设计。每个 GPU 维护自己的缓存,并通过 NVLink 广播或点对点通信来维护一致性。这种机制极大地简化了编程模型,提高了开发效率。软硬件架构硬件集成NVLink 接口直接集成在 GPU 芯片上,每个 GPU 拥有多个 NVLink 端口。端口数量和带宽随 GPU 型号而异。NVSwitch 作为交换矩阵,连接多个 GPU,形成全连接或部分连接的拓扑结构,确保任意两个 GPU 间都有直接或间接的高速路径。NVLink-C2C 技术将 CPU 和 GPU 连接,提供高带宽协同计算能力。软件支持NVIDIA 提供了丰富的软件栈来利用 NVLink:CUDA:提供cudaMemcpyPeer等API,支持GPU间直接内存拷贝。NCCL:优化了集体通信操作,如 all-reduce、broadcast,广泛用于分布式训练。Unified Memory:允许 CPU 和 GPU 共享内存,NVLink 提供高带宽支持,减少数据移动开销。演进亮点NVLink 1.0(2016):首次亮相于 Pascal 架构的 Tesla P100,提供 160 GB/s 总带宽,较 PCIe 3.0 x16(约 32 GB/s)提升数倍,奠定了多 GPU 互联基础。NVLink 2.0(2017):引入 NVSwitch,支持全连接拓扑,带宽增至 300 GB/s,广泛用于 DGX-1 系统。NVLink 3.0(2020):链接数翻倍至 12,带宽达 600 GB/s,搭配 A100 GPU,满足大模型训练需求。NVLink 4.0(2022):采用 PAM4 编码,链接数增至 18,总带宽 900 GB/s,H100 GPU 成为 HPC 标杆。NVLink 5.0(2024):带宽翻倍至 1.8 TB/s,搭配 Blackwell 架构的 GB200 NVL72,支持超大规模 AI 集群。NVLink 的演进反映了 NVIDIA 对计算规模和复杂性增长的精准应对。从最初的 GPU-GPU 互联,到如今支持 CPU-GPU 协同(如 Grace CPU),NVLink 已从单一技术成长为数据中心计算的核心支柱。05、应用场景:赋能AI与HPCNVLink 的高带宽和低延迟使其在以下领域大放异彩:人工智能与深度学习AI 模型(如大语言模型)需要处理海量参数和数据,单 GPU 内存和计算能力往往不足。NVLink 允许多 GPU 共享统一内存池,加速模型训练。例如,训练 GPT-3 规模的模型需数十 GB 参数,NVLink 确保 GPU 间快速交换梯度和权重,缩短训练时间。NVIDIA DGX A100(8 个 A100 GPU,NVLink 3.0)可将训练时间从数月缩短至数周。高性能计算(HPC)HPC 任务,如气候建模、分子动力学模拟,需处理大规模矩阵运算。NVLink 的高带宽减少数据传输瓶颈,提升计算效率。例如,美国橡树岭国家实验室的 Summit 超级计算机使用 IBM Power9 CPU 和 NVIDIA V100 GPU,通过 NVLink 2.0 实现高效互联,位列全球超算前列。数据科学与分析在数据密集型任务中,NVLink 加速多 GPU 协作处理。例如,金融风控模型需分析海量交易数据,NVLink 确保快速数据分发,缩短分析时间。云服务云服务商如 AWS(P4d 实例,A100 GPU)、Azure 和 Google Cloud 提供 NVLink 连接的 GPU 实例,允许用户按需租用高性能计算资源,无需自建硬件。例如,AWS P4d 实例使用 NVLink 3.0,支持多 GPU 训练和推理。06、生态布局:硬件、软件与合作伙伴NVLink 的成功不仅在于技术本身,还得益于 NVIDIA 构建的强大生态系统。硬件生态GPU与CPU:NVLink 支持 NVIDIA 全系列 GPU,从 Pascal 到 Blackwell。Grace CPU 通过 NVLink-C2C 与 GPU 实现高带宽连接,Grace Hopper 超级芯片更是将 CPU 和 GPU 集成于同一封装,提供超高性能。NVSwitch:NVSwitch 扩展了 NVLink 的连接能力,支持全连接拓扑。例如,DGX-2 使用 12 个 NVSwitch 连接 16 个 V100 GPU,GB200 NVL72 则连接 72 个 Blackwell GPU。DGX与HGX系统:DGX 系统(如 DGX A100、H100)是 NVLink 的旗舰平台,预配置多 GPU 和 NVSwitch,适合企业 AI 开发。HGX 平台则为服务器厂商提供灵活的 NVLink 集成方案。软件生态CUDA与 NCCL:CUDA 提供 NVLink 专用 API,简化多 GPU 数据传输。NCCL(NVIDIA 集体通信库)优化了多 GPU 通信模式,广泛用于 AI 框架。AI框架:TensorFlow、PyTorch 等主流框架支持 NVLink,开发者可无缝利用其高带宽特性。NVIDIA AI Enterprise:提供预优化模型和微服务(如 NIM),与 NVLink 硬件协同,提升 AI 部署效率。合作伙伴生态服务器厂商:Dell、HPE、Lenovo 等厂商推出 NVLink 服务器,满足企业需求。云服务商:AWS、Azure、Google Cloud 提供 NVLink 实例,降低用户进入门槛。超算中心:Summit、Perlmutter 等顶级超算采用 NVLink,验证其在极端计算中的可靠性。未来方向NVLink 的生态布局正向更广泛领域扩展。Grace CPU 和 Blackwell 架构的推出表明 NVIDIA 致力于构建 CPU-GPU 统一计算平台。未来,NVLink 或将融入 6G 网络、边缘计算等新兴领域,进一步推动计算架构创新。然而,开放标准如 UALink(支持 1,024 GPU,200 GT/s 带宽)可能对 NVLink 的专有性构成挑战,NVIDIA 需平衡技术领先与生态开放性。07、写在最后:NVLink的计算革命NVLink 从 2016 年的初代到 2024 年的第五代,已成为 AI 和 HPC 的核心技术。其高带宽、低延迟和缓存一致性特性,赋能了从云端到边缘的计算创新。无论是训练万亿参数的 AI 模型,还是运行复杂的科学模拟,NVLink 都提供了不可或缺的“数据动脉”。通过硬件、软件和合作伙伴的协同,NVIDIA 构建了强大的 NVLink 生态,为计算行业树立了标杆。未来,随着计算需求的持续增长,NVLink 无疑将继续引领技术前沿,驱动下一代计算革命。本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。原始发表:2025-04-29,如有侵权请联系 hegangben@163.com 删除
NVLink1.0~5.0: 高速互联的架构演进之路 01、引言:数据时代的“高速公路”在人工智能(AI)和高性能计算(HPC)的浪潮中,计算能力的提升不仅依赖于处理器性能,还需要高效的数据传输通道。传统 PCIe 互联虽广泛应用,但其带宽和延迟已难以满足现代计算需求。NVIDIA 的 NVLink 应运而生,作为一种高速、低延迟的点对点互联技术,它为多 GPU 和 CPU-GPU 系统提供了“数据高速公路”,显著提升了计算效率。本文将从技术视角深入剖析 NVLink 的架构、演进历程、应用场景及生态布局,为科技人士、通信工程师和学术研究者提供全面洞察。02、NVLink架构:技术核心与关键特性NVLink 是 NVIDIA 专为高性能计算设计的互联技术,旨在实现 GPU 间或 GPU 与 CPU 间的高速数据交换。其架构基于点对点通信,采用多通道设计,每个通道(称为“链接”)包含多个差分对,提供高带宽和低延迟的数据传输。核心特性高带宽:NVLink 提供远超 PCIe 的带宽。例如,最新 NVLink 5.0 单链接双向带宽达 200 GB/s,总带宽可达 1.8 TB/s,而 PCIe 5.0 x16 仅约 126 GB/s。低延迟:通过专用通道和优化协议,NVLink 显著降低数据传输延迟,适合实时计算任务。缓存一致性:NVLink 支持 GPU 间或 GPU-CPU 间的缓存一致性,允许共享统一内存空间,减少数据拷贝开销。可扩展性:结合 NVSwitch,NVLink 支持全连接拓扑,使多 GPU 系统实现高效通信。NVLink 的工作原理类似高速公路网络:每个 GPU 或 CPU 是“城市”,链接是“车道”,NVSwitch 则像“交通枢纽”,确保数据流畅无阻。这种设计特别适合需要大规模并行计算的场景,如 AI 模型训练和科学模拟。03、技术演进:从NVLink 1.0到5.0 的跨越NVLink 自 2016 年首次亮相以来,经历了五代技术迭代,每一代都针对计算需求的增长进行了优化。版本年份GPU 架构每链接带宽(双向,GB/s)链接数总带宽(GB/s)备注1.02016Pascal404160首代,Tesla P1002.02017Volta506300支持 NVSwitch,DGX-13.02020Ampere5012600A100 GPU,广泛用于云4.02022Hopper10018900H100 GPU,PAM4 编码5.02024Blackwell200181800GB200 NVL72,AI 优化以下是对其演进历程的详细分析,涵盖技术原理、软硬件架构及技术演进亮点。1、NVLink 1.0(2016):开创高速互联先河GPU架构:Pascal(Tesla P100)带宽:每链接 40 GB/秒(双向,20 GB/秒单向),P100 支持 4 个链接,总带宽 160 GB/秒。技术原理:采用 NRZ(非归零)信号编码,每个时钟周期传输 1 位数据。NVLink 使用差分对传输,包含 8 条子通道,每条子通道运行在 20 Gbps。协议栈基于定制的点对点通信,优化了数据包格式,减少了传输开销。软硬件软件架构:NVLink 1.0 直接集成在 P100 GPU 芯片上,每个链接占用专用硅片区域。软件方面,CUDA 7.0 引入了cudaMemcpyPeer API技术,支持GPU间直接内存拷贝,简化了多GPU编程。技术演进亮点:首次亮相于Pascal架构的Tesla P100,提供160GB/s总带宽,较PCIexpress 3.0x16(约32GB/s)提升数倍,奠定了多GPU互联基础。应用场景:主要用于早期深度学习任务,如图像识别模型(如 ResNet)的训练。DGX-1 系统首次采用 NVLink 1.0,连接 8 个 P100 GPU,奠定了多 GPU 系统的基础。挑战与突破:NVLink 1.0 的主要挑战是链接数量有限,仅支持 4 个链接,限制了多 GPU 系统的扩展性。NVIDIA 通过优化协议和硬件设计,确保了低延迟和高可靠性,为后续版本奠定了技术基础。2、NVLink 2.0(2017):引入 NVSwitch,扩展规模GPU架构:Volta(Tesla V100)带宽:每链接 50 GB/秒(双向,25 GB/秒单向),V100 支持 6 个链接,总带宽 300 GB/秒。技术原理:继续使用 NRZ 编码,但通过提高时钟频率和优化信号完整性,将单链接带宽提升 25%。引入 NVSwitch,一个高性能交换矩阵,支持全连接拓扑,允许多达 16 个 GPU 直接通信。NVSwitch 包含 18 个 NVLink 端口,每个端口提供 50 GB/秒带宽,总吞吐量达 900 GB/秒。软硬件架构:NVSwitch 作为独立芯片,集成在 DGX-2 系统,连接 16 个 V100 GPU。软件方面,CUDA 9.0 和 NCCL 2.0 优化了集体通信操作(如 all-reduce),提升了分布式训练效率。NVLink 2.0 支持缓存一致性,允许多 GPU 共享统一内存空间。技术演进亮点:引入 NVSwitch,支持全连接拓扑,带宽增至 300 GB/s,广泛用于 DGX-1 系统。应用场景:广泛用于 AI 研究和企业级应用,如自然语言处理(BERT 模型)和推荐系统训练。Summit 超级计算机(橡树岭国家实验室)采用 NVLink 2.0,连接 IBM Power9 CPU 和 V100 GPU,位列全球超算前列。挑战与突破:NVLink 2.0 解决了扩展性问题,但 NVSwitch 的引入增加了系统复杂性和成本。NVIDIA 通过优化交换矩阵设计和协议栈,确保了高吞吐量和低延迟。3、NVLink 3.0(2020):链接数量翻倍GPU架构:Ampere(A100)带宽:每链接 50 GB/秒(双向),A100 支持 12 个链接,总带宽 600 GB/秒。技术原理:维持 NRZ 编码,但通过增加链接数量(从 6 到 12),将总带宽翻倍。引入多实例 GPU(MIG)技术,允许将 A100 GPU 虚拟化为多个独立实例,每个实例可分配 NVLink 链接,提升资源利用率。协议栈进一步优化,支持更高效的缓存一致性。软硬件架构:A100 GPU 的 NVLink 端口集成在芯片边缘,采用高密度封装技术。DGX A100 系统使用 8 个 A100 GPU,通过 NVSwitch 连接,提供 4.8 TB/秒的内部带宽。CUDA 11.0 和 NCCL 2.7 增强了对 NVLink 3.0 的支持,优化了分布式训练和推理。技术演进亮点:链接数翻倍至 12,带宽达 600 GB/s,搭配 A100 GPU,满足大模型训练需求。应用场景:云服务(如 AWS P4d 实例)、AI 训练和推理,以及 HPC 任务(如分子动力学模拟)。A100 的 MIG 功能特别适合云端多租户环境。挑战与突破:链接数量的增加提高了芯片设计复杂性,NVIDIA 通过先进的硅片布局和信号完整性技术解决了这一问题。MIG 技术的引入进一步提升了灵活性。4、NVLink 4.0(2022):PAM4 信号革命GPU架构:Hopper(H100)带宽:每链接 100 GB/秒(双向,50 GB/秒单向),H100 支持 18 个链接,总带宽 900 GB/秒。技术原理:首次采用 PAM4(4 级脉冲幅度调制)信号编码,每个时钟周期传输 2 位数据,较 NRZ 翻倍数据率。PAM4 要求更高的信噪比,NVIDIA 通过先进的纠错码(ECC)和信号调制技术确保可靠性。协议栈优化了流量管理,支持动态带宽分配。软硬件架构:H100 GPU 使用 TSMC 4nm 工艺,NVLink 端口数量增至 18,集成在芯片边缘的高速 I/O 区域。DGX H100 系统通过 NVSwitch 连接 8 个 H100 GPU,提供 7.2 TB/秒的内部带宽。CUDA 12.0 和 NCCL 2.10 引入了新的通信原语,优化了超大规模模型训练。技术演进亮点:采用 PAM4 编码,链接数增至 18,总带宽 900 GB/s,H100 GPU 成为 HPC 标杆。应用场景:训练超大规模 AI 模型(如 GPT-4)和高精度科学模拟(如量子化学计算)。H100 的 NVLink 4.0 特别适合需要极高吞吐量的任务。挑战与突破:PAM4 的复杂性增加了设计难度,NVIDIA 通过优化信号处理和芯片布局,确保了高性能和可靠性。5、NVLink 5.0(2024):面向 exascale 计算GPU架构:Blackwell(B200)带宽:每链接 200 GB/秒(双向,100 GB/秒单向),B200 支持 18 个链接,总带宽 1.8 TB/秒。技术原理:进一步优化 PAM4 编码,通过提高时钟频率和信号调制效率,将单链接带宽翻倍。引入 NVLink-C2C(Chip-to-Chip)技术,支持与 Grace CPU 的高速连接,提供 900 GB/秒的 CPU-GPU 带宽。协议栈支持动态流量优先级,确保多种工作负载的平衡。软硬件架构:B200 GPU 使用 3nm 工艺,NVLink 端口采用高密度封装,支持更高的信号密度。GB200 NVL72 系统连接 72 个 Blackwell GPU,通过 NVSwitch 提供 130 TB/秒的内部带宽。CUDA 13.0 和 NCCL 2.12 优化了 exascale 级通信模式。技术演进亮点:带宽翻倍至 1.8 TB/s,搭配 Blackwell 架构的 GB200 NVL72,支持超大规模 AI 集群。应用场景:exascale 级别的 AI 和 HPC 任务,如气候建模、基因组分析和超大规模语言模型训练。NVLink-C2C 特别适合 CPU-GPU 协同计算。挑战与突破:高带宽和高链接数量增加了功耗和散热挑战,NVIDIA 通过先进的电源管理和冷却技术解决了这些问题。04、NVLink技术原理分析信号技术NVLink 的信号技术从 NRZ 进化到 PAM4。NRZ 每个时钟周期传输 1 位数据,而 PAM4 传输 2 位,通过四种电平表示 00、01、10、11。这使得在相同物理带宽下,数据传输率翻倍。PAM4 虽然对信噪比要求更高,但通过先进的纠错码(ECC)和信号调制技术,NVLink 4.0 及以后的版本成功实现了高可靠性的高速传输。协议栈NVLink 使用定制的协议栈,优化了数据包格式和传输机制。与 PCIe 相比,NVLink 的协议更精简,减少了开销,降低了延迟。协议支持多种流量类型,包括内存访问、I/O 操作和消息传递,确保了灵活性和高效性。NVLink 5.0 引入了动态流量优先级,允许根据工作负载需求调整带宽分配。缓存一致性NVLink 支持硬件级的缓存一致性,允许多个 GPU 共享统一的内存地址空间,而无需软件干预。这通过目录式缓存一致性协议实现,类似于多核 CPU 的设计。每个 GPU 维护自己的缓存,并通过 NVLink 广播或点对点通信来维护一致性。这种机制极大地简化了编程模型,提高了开发效率。软硬件架构硬件集成NVLink 接口直接集成在 GPU 芯片上,每个 GPU 拥有多个 NVLink 端口。端口数量和带宽随 GPU 型号而异。NVSwitch 作为交换矩阵,连接多个 GPU,形成全连接或部分连接的拓扑结构,确保任意两个 GPU 间都有直接或间接的高速路径。NVLink-C2C 技术将 CPU 和 GPU 连接,提供高带宽协同计算能力。软件支持NVIDIA 提供了丰富的软件栈来利用 NVLink:CUDA:提供cudaMemcpyPeer等API,支持GPU间直接内存拷贝。NCCL:优化了集体通信操作,如 all-reduce、broadcast,广泛用于分布式训练。Unified Memory:允许 CPU 和 GPU 共享内存,NVLink 提供高带宽支持,减少数据移动开销。演进亮点NVLink 1.0(2016):首次亮相于 Pascal 架构的 Tesla P100,提供 160 GB/s 总带宽,较 PCIe 3.0 x16(约 32 GB/s)提升数倍,奠定了多 GPU 互联基础。NVLink 2.0(2017):引入 NVSwitch,支持全连接拓扑,带宽增至 300 GB/s,广泛用于 DGX-1 系统。NVLink 3.0(2020):链接数翻倍至 12,带宽达 600 GB/s,搭配 A100 GPU,满足大模型训练需求。NVLink 4.0(2022):采用 PAM4 编码,链接数增至 18,总带宽 900 GB/s,H100 GPU 成为 HPC 标杆。NVLink 5.0(2024):带宽翻倍至 1.8 TB/s,搭配 Blackwell 架构的 GB200 NVL72,支持超大规模 AI 集群。NVLink 的演进反映了 NVIDIA 对计算规模和复杂性增长的精准应对。从最初的 GPU-GPU 互联,到如今支持 CPU-GPU 协同(如 Grace CPU),NVLink 已从单一技术成长为数据中心计算的核心支柱。05、应用场景:赋能AI与HPCNVLink 的高带宽和低延迟使其在以下领域大放异彩:人工智能与深度学习AI 模型(如大语言模型)需要处理海量参数和数据,单 GPU 内存和计算能力往往不足。NVLink 允许多 GPU 共享统一内存池,加速模型训练。例如,训练 GPT-3 规模的模型需数十 GB 参数,NVLink 确保 GPU 间快速交换梯度和权重,缩短训练时间。NVIDIA DGX A100(8 个 A100 GPU,NVLink 3.0)可将训练时间从数月缩短至数周。高性能计算(HPC)HPC 任务,如气候建模、分子动力学模拟,需处理大规模矩阵运算。NVLink 的高带宽减少数据传输瓶颈,提升计算效率。例如,美国橡树岭国家实验室的 Summit 超级计算机使用 IBM Power9 CPU 和 NVIDIA V100 GPU,通过 NVLink 2.0 实现高效互联,位列全球超算前列。数据科学与分析在数据密集型任务中,NVLink 加速多 GPU 协作处理。例如,金融风控模型需分析海量交易数据,NVLink 确保快速数据分发,缩短分析时间。云服务云服务商如 AWS(P4d 实例,A100 GPU)、Azure 和 Google Cloud 提供 NVLink 连接的 GPU 实例,允许用户按需租用高性能计算资源,无需自建硬件。例如,AWS P4d 实例使用 NVLink 3.0,支持多 GPU 训练和推理。06、生态布局:硬件、软件与合作伙伴NVLink 的成功不仅在于技术本身,还得益于 NVIDIA 构建的强大生态系统。硬件生态GPU与CPU:NVLink 支持 NVIDIA 全系列 GPU,从 Pascal 到 Blackwell。Grace CPU 通过 NVLink-C2C 与 GPU 实现高带宽连接,Grace Hopper 超级芯片更是将 CPU 和 GPU 集成于同一封装,提供超高性能。NVSwitch:NVSwitch 扩展了 NVLink 的连接能力,支持全连接拓扑。例如,DGX-2 使用 12 个 NVSwitch 连接 16 个 V100 GPU,GB200 NVL72 则连接 72 个 Blackwell GPU。DGX与HGX系统:DGX 系统(如 DGX A100、H100)是 NVLink 的旗舰平台,预配置多 GPU 和 NVSwitch,适合企业 AI 开发。HGX 平台则为服务器厂商提供灵活的 NVLink 集成方案。软件生态CUDA与 NCCL:CUDA 提供 NVLink 专用 API,简化多 GPU 数据传输。NCCL(NVIDIA 集体通信库)优化了多 GPU 通信模式,广泛用于 AI 框架。AI框架:TensorFlow、PyTorch 等主流框架支持 NVLink,开发者可无缝利用其高带宽特性。NVIDIA AI Enterprise:提供预优化模型和微服务(如 NIM),与 NVLink 硬件协同,提升 AI 部署效率。合作伙伴生态服务器厂商:Dell、HPE、Lenovo 等厂商推出 NVLink 服务器,满足企业需求。云服务商:AWS、Azure、Google Cloud 提供 NVLink 实例,降低用户进入门槛。超算中心:Summit、Perlmutter 等顶级超算采用 NVLink,验证其在极端计算中的可靠性。未来方向NVLink 的生态布局正向更广泛领域扩展。Grace CPU 和 Blackwell 架构的推出表明 NVIDIA 致力于构建 CPU-GPU 统一计算平台。未来,NVLink 或将融入 6G 网络、边缘计算等新兴领域,进一步推动计算架构创新。然而,开放标准如 UALink(支持 1,024 GPU,200 GT/s 带宽)可能对 NVLink 的专有性构成挑战,NVIDIA 需平衡技术领先与生态开放性。07、写在最后:NVLink的计算革命NVLink 从 2016 年的初代到 2024 年的第五代,已成为 AI 和 HPC 的核心技术。其高带宽、低延迟和缓存一致性特性,赋能了从云端到边缘的计算创新。无论是训练万亿参数的 AI 模型,还是运行复杂的科学模拟,NVLink 都提供了不可或缺的“数据动脉”。通过硬件、软件和合作伙伴的协同,NVIDIA 构建了强大的 NVLink 生态,为计算行业树立了标杆。未来,随着计算需求的持续增长,NVLink 无疑将继续引领技术前沿,驱动下一代计算革命。本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。原始发表:2025-04-29,如有侵权请联系 hegangben@163.com 删除