搜索到
1
篇与
的结果
-
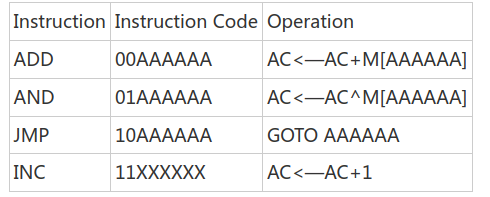
 一个简单的8位处理器完整设计过程及verilog代码 来源: EETOP BBS 作者:weiboshe一个简单的8位处理器完整设计过程及verilog代码,适合入门学习参考,并含有作者个人写的指令执行过程(点击下方 阅读原文 到论坛可下载源码)CPU定义我们按照应用的需求来定义计算机,本文介绍一个非常简单的CPU的设计,它仅仅用来教学使用的。我们规定它可以存取的存储器为64byte,其中1byte=8bits。所以这个CPU就有6位的地址线A[5:0],和8位的数据线D[7:0]。我们仅定义一个通用寄存器AC(8bits寄存器),它仅仅执行4条指令如下:除了寄存器AC外,我们还需要以下几个寄存器:地址寄存器 A[5:0], 保存6位地址。程序计数器 PC[5:0],保存下一条指令的地址。数据寄存器 D[7:0],接受指令和存储器来的数据。指令寄存器 IR[1:0],存储指令操作码。2. 取指设计 在处理器执行指令之前,必须从存储器取出指令。其中取指执行以下操作:1〉 通过地址端口A[5:0]从地址到存储器2〉 等待存储器准备好数据后,读入数据。由于地址端口数据A[5:0]是从地址寄存器中读出的,所以取指第一个执行的状态是Fetch1: AR<—PC接下来cpu发出read信号,并把数据从存储器M中读入数据寄存器DR中。同时pc加一。Fetch2: DR<—M,PC<—PC+1接下来把DR[7:6]送IR,把DR[5:0]送ARFetch3: IR<—DR[7:6],AR<—DR[5:0] 3. 指令译码Cpu在取指后进行译码一边知道执行什么指令,对于本文中的CPU来说只有4条指令也就是只有4个执行例程,状态图如下:4. 指令执行对译码中调用的4个例程我们分别讨论:4.1 ADD指令ADD指令需要CPU做以下两件事情:1〉 从存储器取一个操作数2〉 把这个操作数加到AC上,并把结果存到AC所以需要以下操作:ADD1: DR<—MADD2: AC<—AC+DR4.2 AND指令AND指令执行过程和ADD相似,需要以下操作:AND1: DR<—MAND2: AC<—AC^DR4.3 JMP指令 JMP指令把CPU要跳转的指令地址送PC,执行以下操作JMP1: PC<—DR[5:0]4.4INC指令INC指令执行AC+1操作INC1: AC<—AC+1总的状态图如下:5 建立数据路径 这一步我们来实现状态图和相应的寄存器传输。首先看下面的状态及对应的寄存器传输: Fetch1: AR<—PCFetch2: DR<—M,PC<—PC+1Fetch3: IR<—DR[7:6],AR<—DR[5:0]ADD1: DR<—MADD2: AC<—AC+DRAND1: DR<—MAND2: AC<—AC^DRJMP1: PC<—DR[5:0]INC1: AC<—AC+1为了设计数据路径,我们可以采用两种办法:1〉创造直接的两个要传输组件之间的直接路径2〉在CPU内部创造总线来传输不同组件之间的数据首先我们回顾一下可能发生的数据传输,以便确定各个组件的功能。特别的我们要注意把数据载入组件的各个操作。首先我们按照他们改变了那个寄存器的数据来重组这些操作。得到如下的结果:AR:AR<—PC;AR<—DR[5:0]PC:PC<—PC+1;PC<—DR[5:0]DR:DR<—MIR:IR<—DR[7:6]AC:AC<—AC+DR;AC<—AC^DR;AC<—AC+1现在我们来看每个操作来决定每个组件执行什么样的功能,AR,DR,IR三个组件经常从其他的组件载入数据(从总线),所以只需要执行一个并行输入的操作。PC和AC能够载入数据同时也能够自动加一操作。下一步我们把这些组件连接到总线上来,如图所示:如上图所示,各个组件与总线之间通过三态连接,防止出现总线竞争。AR寄存器送出存储器的地址,DR寄存器用于暂存存数起来的数据。到现在为止我们还没有讨论有关的控制信号,我们现在只是保证了所有的数据传输能够产生,我们将在后面章节来使这些数据传输正确的产生---控制逻辑。现在我们来看以下者写数据传输中有没有不必要的传输:1〉 AR仅仅提供数据给存储器,所以他不需要连接到总线上。2〉 IR不通过总线提供数据给任何组件,所以他可以直接输出到控制单元(后面章节)。3〉 AC不提供数据到任何的组件,可以不连接到总线上。4〉 总线是8bit宽度的,但是有些传输是6bit或者2bit的,我们必须制定寄存器的那几位送到总线的那几位。5〉 AC要可以载入AC和DR的和或者逻辑与的值,数据路径中还需要进行运算的ALU。由此我们做以下工作:1〉 去掉AR,IR, AC与总线的连接。2〉 我们约定寄存器连接是从总线的低位开始的。AR,PC连接到Bus[5:0],由于IR是接受DR[7:6]的,所以可以连接到总线的Bus[7:6]。3〉 我们设定,AC作为ALU的一个输入,另一个输入来自总线Bus。下面我们检查是否有争用总线的情况,幸运的是这里没有。修改后的CPU内部组织图如下:ALU设计这个CPU的ALU执行的功能就是两个操作数相加、逻辑与。这里不作详细介绍。电路如如下: 控制单元 我们来考虑如何产生数据路径所需的控制信号,有两种方法:硬布线逻辑和为程序控制。这里我们用硬布线逻辑来实现。这个简单的CPU需要的控制逻辑由三个部件组成: 1〉计数器: 用于保存现在的状态 2〉译码器: 生成各个状态的控制信号 3〉其他的组合逻辑来产生控制信号一个通用的控制单元原理图如下: 对于这个CPU来说,一共有9个状态。所以需要一个4bit的计数器和一个4-16的译码器。接下来的工作就是按照前面的状态转换图来对状态进行赋值。 首先考虑如何的对译码输出状态进行赋值才能达到最佳状态。我们按照以下规则: 1〉给Fetch1赋计数器的0值,并用计数器的清零端来达到这个状态。由这个CPU的状态图可以看出,除了Fetch1状态外的状态都只能由一个状态转化而来,Fetch1需要从4个分支而来,这4个分支就可以发出清零信号(CLR)来转移到Fetch1。 2〉把连续的状态赋连续的计数器值,这样就可以用计数器的INC输入来达到状态的转移。 3〉给每个例程的开始状态赋值时,要基于指令的操作码和这个例程的最大状态数。这样就可以用操作码来生成计数器的LD信号达到正确的状态转移。首先,在Fetch3状态发出LD信号,然后要把正确的例程地址放到计数器的输入端。对这个CPU来说,我们考虑以地址1 [IR] 0作为计数器的预置输入。则得到状态编码如下:如上表所示,下面我们需要设计产生计数器的LD、INC、CLR等信号,总的控制单元的逻辑如下图:下面我们用这些译码信号来产生数据路径控制所必需的AR、PC、DR、IR、M和ALU的控制信号。首先考虑寄存器AR,他在Fetch1状态取PC的值,并在Fetch3状态取DR[5:0]的值,所以我们得到ARLOAD=Fetch1 or Fetch3。以此类推我们可以得到如下结果:PCLOAD=JMP1PCINC=Fetch2DRLOAD=Fetch1or ADD1 or AND1ACLOAD=ADD2 or AND2IRLOAD=Fetch3对于ALU的控制信号ALUSEL是用来控制ALU做逻辑或者算数运算的,所以有:ALUSEL=AND2对于片内总线的控制较为复杂,我们先来看DR,对于DR他只在Fetch3、AND2 、ADD2和JMP1状态占用总线进行相信的数据传输,所以有:DRBUS=Fetch3 or AND2 or ADD2 or JMP1其他类似有:MEMBUS=Fetch2or ADD1 or AND1PCBUS=Fetch1最后,控制单元需要产生存储器的读信号(READ),它发生在Fetch2、ADD1、AND1三个状态:READ=Fetch2or ADD1 or AND1这样我们得到了总的控制逻辑,完成了整个CPU的设计。8. 设计验证 我们执行如下指令进行设计验证,0:ADD41:AND52:INC3:JMP04:27H5:39H指令执行过程如下(初始化所有寄存器为全零态):
一个简单的8位处理器完整设计过程及verilog代码 来源: EETOP BBS 作者:weiboshe一个简单的8位处理器完整设计过程及verilog代码,适合入门学习参考,并含有作者个人写的指令执行过程(点击下方 阅读原文 到论坛可下载源码)CPU定义我们按照应用的需求来定义计算机,本文介绍一个非常简单的CPU的设计,它仅仅用来教学使用的。我们规定它可以存取的存储器为64byte,其中1byte=8bits。所以这个CPU就有6位的地址线A[5:0],和8位的数据线D[7:0]。我们仅定义一个通用寄存器AC(8bits寄存器),它仅仅执行4条指令如下:除了寄存器AC外,我们还需要以下几个寄存器:地址寄存器 A[5:0], 保存6位地址。程序计数器 PC[5:0],保存下一条指令的地址。数据寄存器 D[7:0],接受指令和存储器来的数据。指令寄存器 IR[1:0],存储指令操作码。2. 取指设计 在处理器执行指令之前,必须从存储器取出指令。其中取指执行以下操作:1〉 通过地址端口A[5:0]从地址到存储器2〉 等待存储器准备好数据后,读入数据。由于地址端口数据A[5:0]是从地址寄存器中读出的,所以取指第一个执行的状态是Fetch1: AR<—PC接下来cpu发出read信号,并把数据从存储器M中读入数据寄存器DR中。同时pc加一。Fetch2: DR<—M,PC<—PC+1接下来把DR[7:6]送IR,把DR[5:0]送ARFetch3: IR<—DR[7:6],AR<—DR[5:0] 3. 指令译码Cpu在取指后进行译码一边知道执行什么指令,对于本文中的CPU来说只有4条指令也就是只有4个执行例程,状态图如下:4. 指令执行对译码中调用的4个例程我们分别讨论:4.1 ADD指令ADD指令需要CPU做以下两件事情:1〉 从存储器取一个操作数2〉 把这个操作数加到AC上,并把结果存到AC所以需要以下操作:ADD1: DR<—MADD2: AC<—AC+DR4.2 AND指令AND指令执行过程和ADD相似,需要以下操作:AND1: DR<—MAND2: AC<—AC^DR4.3 JMP指令 JMP指令把CPU要跳转的指令地址送PC,执行以下操作JMP1: PC<—DR[5:0]4.4INC指令INC指令执行AC+1操作INC1: AC<—AC+1总的状态图如下:5 建立数据路径 这一步我们来实现状态图和相应的寄存器传输。首先看下面的状态及对应的寄存器传输: Fetch1: AR<—PCFetch2: DR<—M,PC<—PC+1Fetch3: IR<—DR[7:6],AR<—DR[5:0]ADD1: DR<—MADD2: AC<—AC+DRAND1: DR<—MAND2: AC<—AC^DRJMP1: PC<—DR[5:0]INC1: AC<—AC+1为了设计数据路径,我们可以采用两种办法:1〉创造直接的两个要传输组件之间的直接路径2〉在CPU内部创造总线来传输不同组件之间的数据首先我们回顾一下可能发生的数据传输,以便确定各个组件的功能。特别的我们要注意把数据载入组件的各个操作。首先我们按照他们改变了那个寄存器的数据来重组这些操作。得到如下的结果:AR:AR<—PC;AR<—DR[5:0]PC:PC<—PC+1;PC<—DR[5:0]DR:DR<—MIR:IR<—DR[7:6]AC:AC<—AC+DR;AC<—AC^DR;AC<—AC+1现在我们来看每个操作来决定每个组件执行什么样的功能,AR,DR,IR三个组件经常从其他的组件载入数据(从总线),所以只需要执行一个并行输入的操作。PC和AC能够载入数据同时也能够自动加一操作。下一步我们把这些组件连接到总线上来,如图所示:如上图所示,各个组件与总线之间通过三态连接,防止出现总线竞争。AR寄存器送出存储器的地址,DR寄存器用于暂存存数起来的数据。到现在为止我们还没有讨论有关的控制信号,我们现在只是保证了所有的数据传输能够产生,我们将在后面章节来使这些数据传输正确的产生---控制逻辑。现在我们来看以下者写数据传输中有没有不必要的传输:1〉 AR仅仅提供数据给存储器,所以他不需要连接到总线上。2〉 IR不通过总线提供数据给任何组件,所以他可以直接输出到控制单元(后面章节)。3〉 AC不提供数据到任何的组件,可以不连接到总线上。4〉 总线是8bit宽度的,但是有些传输是6bit或者2bit的,我们必须制定寄存器的那几位送到总线的那几位。5〉 AC要可以载入AC和DR的和或者逻辑与的值,数据路径中还需要进行运算的ALU。由此我们做以下工作:1〉 去掉AR,IR, AC与总线的连接。2〉 我们约定寄存器连接是从总线的低位开始的。AR,PC连接到Bus[5:0],由于IR是接受DR[7:6]的,所以可以连接到总线的Bus[7:6]。3〉 我们设定,AC作为ALU的一个输入,另一个输入来自总线Bus。下面我们检查是否有争用总线的情况,幸运的是这里没有。修改后的CPU内部组织图如下:ALU设计这个CPU的ALU执行的功能就是两个操作数相加、逻辑与。这里不作详细介绍。电路如如下: 控制单元 我们来考虑如何产生数据路径所需的控制信号,有两种方法:硬布线逻辑和为程序控制。这里我们用硬布线逻辑来实现。这个简单的CPU需要的控制逻辑由三个部件组成: 1〉计数器: 用于保存现在的状态 2〉译码器: 生成各个状态的控制信号 3〉其他的组合逻辑来产生控制信号一个通用的控制单元原理图如下: 对于这个CPU来说,一共有9个状态。所以需要一个4bit的计数器和一个4-16的译码器。接下来的工作就是按照前面的状态转换图来对状态进行赋值。 首先考虑如何的对译码输出状态进行赋值才能达到最佳状态。我们按照以下规则: 1〉给Fetch1赋计数器的0值,并用计数器的清零端来达到这个状态。由这个CPU的状态图可以看出,除了Fetch1状态外的状态都只能由一个状态转化而来,Fetch1需要从4个分支而来,这4个分支就可以发出清零信号(CLR)来转移到Fetch1。 2〉把连续的状态赋连续的计数器值,这样就可以用计数器的INC输入来达到状态的转移。 3〉给每个例程的开始状态赋值时,要基于指令的操作码和这个例程的最大状态数。这样就可以用操作码来生成计数器的LD信号达到正确的状态转移。首先,在Fetch3状态发出LD信号,然后要把正确的例程地址放到计数器的输入端。对这个CPU来说,我们考虑以地址1 [IR] 0作为计数器的预置输入。则得到状态编码如下:如上表所示,下面我们需要设计产生计数器的LD、INC、CLR等信号,总的控制单元的逻辑如下图:下面我们用这些译码信号来产生数据路径控制所必需的AR、PC、DR、IR、M和ALU的控制信号。首先考虑寄存器AR,他在Fetch1状态取PC的值,并在Fetch3状态取DR[5:0]的值,所以我们得到ARLOAD=Fetch1 or Fetch3。以此类推我们可以得到如下结果:PCLOAD=JMP1PCINC=Fetch2DRLOAD=Fetch1or ADD1 or AND1ACLOAD=ADD2 or AND2IRLOAD=Fetch3对于ALU的控制信号ALUSEL是用来控制ALU做逻辑或者算数运算的,所以有:ALUSEL=AND2对于片内总线的控制较为复杂,我们先来看DR,对于DR他只在Fetch3、AND2 、ADD2和JMP1状态占用总线进行相信的数据传输,所以有:DRBUS=Fetch3 or AND2 or ADD2 or JMP1其他类似有:MEMBUS=Fetch2or ADD1 or AND1PCBUS=Fetch1最后,控制单元需要产生存储器的读信号(READ),它发生在Fetch2、ADD1、AND1三个状态:READ=Fetch2or ADD1 or AND1这样我们得到了总的控制逻辑,完成了整个CPU的设计。8. 设计验证 我们执行如下指令进行设计验证,0:ADD41:AND52:INC3:JMP04:27H5:39H指令执行过程如下(初始化所有寄存器为全零态):