搜索到
25
篇与
的结果
-
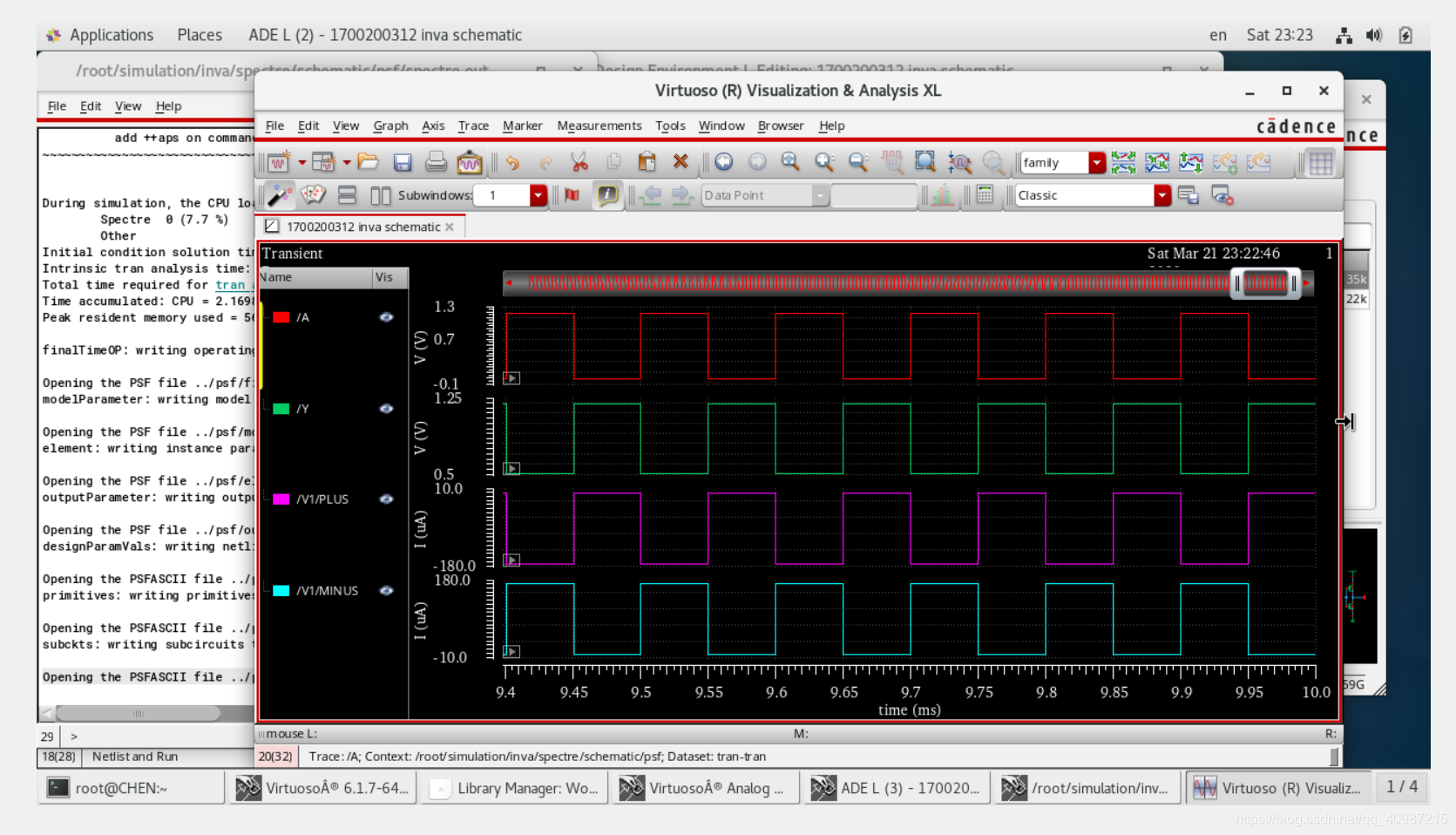
 在IC617中进行xa+vcs数模混仿 基本介绍:本文档介绍了在IC617的ADE L环境的图形化界面中进行数字+模拟信号混合仿真的方法,主要分成以下几个部分:一、软件要求1、与CustomSim兼容的VCS,本文档中分别是xa2018.09和vcsmx_v2018092、Custom Waveview(波形查看软件,非必须)3、IC614或更新版本的Cadence(OA)或更新版本的IC5.1.4.1-USR5(CDBA),本文档以IC617为例。4、相应的license二、安装并设置CustomSim ADE L交互界面安装CustomSim有两种方式,分别是安装在Cadence目录中和目录外。本文档只介绍第二种方法,即安装在Cadence目录外。具体步骤如下:1、设置环境变量:setenv CDS_LOAD_ENV CSF2、在CustomSim的安装目录下找到名为CustomSim.cdsenv的文件,位置在CustomSim安装目录/ade/CustomSimADE/CustomSim.cdsenv,将其复制到home目录下。(这是CustomSim的初始化文件,不复制也无所谓)3、在home下找到.cdsinit文件并在文件中将CustomSim.ile文件的路径添加进去:Load(“CustomSim安装目录/ade/CustomSimADE/CustomSim.ile”)(这里面包含了Cadence环境下的CustomSim ADE SKILL代码)4、设置环境变量:setenv CDS_Netlisting_Mode Analog5、如果Cadence版本早于IC617且CustomSimADE版本晚于M-2017.03,则需要设置如下环境变量:setenv CDS_AUTO_64BIT ALL(在本文档中不需要进行此设置,但设置了也无妨。)6、全部设置完成后就可以按照正常的方式启动Cadence软件了。三、CustomSim ADE L的使用CustomSim ADE交互界面支持Cadence的schematic和config两种方式的设置。Schematic通常用于纯模拟仿真(CustomSim)而config通常用于混合信号仿真(CustomSim-VCS),本文档使用第二种方法。下面是设置数模混合仿真的具体步骤:1、创建原理图:新建schematic并将具体的原理图电路添加进去,模拟部分按照正常的方式创建电路并生成symbol,数字电路的创建方法有如下几种:①新建cell view,类型选择Verilog,view会自动变成functional,确定之后在里面编辑数字电路,保存并检查无误后会自动弹出生成symbol的界面,完成之后就可以用平时调用模拟电路的方法调用该模块。②大多数情况下模拟工程师并不需要写数字代码,只需要将写好的代码调用即可,此时可以用之前的方式新建verilog之后将数字代码复制进来即可。(也可以找到代码的路径将数字代码复制过去覆盖原来的代码,并修改好数字里面的module名字,重新打开该verilog再保存退出,同样可以弹出生成symbol的界面。)③CustomSim也提供了直接加载数字代码的方式,本文档不做介绍。2、创建config:创建config的名字需要和schematic相同,类型选择config,完成后会弹出一个名为New Configuration的窗口,点击view那一栏并选择schematic(唯一的选项),然后Global Bindings需要进行设置,设置之前先对各个选项做简要介绍:①Library List:Library列表,可以是Cadence自带的library,可以是工艺库,也可以是用户自定义的库,可以定义一个,也可以定义多个,如果定义多个需要用空格隔开。②View List:即之前定义过的库中所包含的view都会在里面显示。CustomSim支持的View List包括:hspiceD、spice、cmos_sch、veriloga和schematic。③Stop List:此处的内容定义了生成网表的类型,如果想生成spectre格式的网表需要在此栏填写spectre同时View List栏也需要加入spectre,如果想生成HSPICE格式的网表则需要在两栏同时填写hspiceD或者HSPICE。(注意此栏不要填错,要根据你使用的仿真器类型填写。④Constraint List:(作用不明)实际设置:可以直接点击底部的Use Template然后选择AMS并确定,实测可以成功仿真而无需额外设置,前提是使用spectre仿真。点击ok完成设置会弹出新的界面,在界面中找到ADE L选项并点击就会启动ADE界面和schematic界面。接下来的就可以关闭config界面进行下一步的设置了。四、电路设置这一步的设置方法基本与平时相同,也比较简单。1、点击Setup→Simulator/Directory/Host在弹出的界面选择CustomSim作为仿真器并确认(仿真路径可以按照自己的需求设置,不设置也可)。2、如果你之前的原理图中已经同时包含了数字和模拟模块,CustomSim就会自动选择仿真类型为混合信号仿真,无需手动设置。五、ADE环境下CustomSim的设置这一步主要是对仿真器的部分重要选项进行设置,主要是仿真器的选择和网表类型的选择。具体如下:1、在ADE L界面点击Setup→Environment会弹出设置界面:在其中可以看到Simulator Selection/Netlist Syntax/Waveform Output Format等选项。此处我们选择:CunstomSim/spectre/fsdb+fsdb(分别对应仿真器/网表/数字波形格式+模拟波形格式,波形格式可以根据自己的喜好和使用的看波形的软件设置),另外# of Cores是多核仿真选项,默认为1,如果需要加快仿真速度可以在其中填入需要的CPU的数量,如需要8颗CPU则在里面填写8(需要注意的是CPU数量并非会全部用到,仿真器会自己决定用到的数目,例如填了8,实际可能只用到了6,但不会超过8,猜测跟实际的电路复杂程度有关。)2、仿真选项设置:点击Simulation→Option→Digital,在top name栏点击Use Top Cell Name,并确定。(这一步很重要,不进行此设置仿真会无法继续)3、设置transient仿真:点击Analyses→Choose后在stop栏填入需要的仿真时间并确定。(只有tran可选)4、另外还有Model的添加,以及其它的自定义的设置再次不过多介绍。可以自行试验。六、波形保存上一步结束后就已经可以进行仿真了,但为了加快仿真速度,通常会减少保存的波形节点的数量,这一步介绍保存的方法。点击Optput→To Be Saved→Select On Design之后再原理图中依次选择需要保存的节点电压和电流,按esc完成选择。七、开始仿真Simulation→Netlist and Run开始仿真!八、常见错误及解决方法上一步中可能会有如下错误:如果模拟电路中调用了电阻且电阻是多跟串联的形式,仿真器可能会报错并提示存在器件名字和net冲突的问题,此时只需要将其中一个的名字改掉就可以了。具体方法不做赘述。九、参考文档CustomSim User Guide的CustomSim ADE Interface Integration部分。ps:仅做记录学习用,个人不推荐,仿真还是要使用自动化的命令效率才高,debug 才需要图形界面。
在IC617中进行xa+vcs数模混仿 基本介绍:本文档介绍了在IC617的ADE L环境的图形化界面中进行数字+模拟信号混合仿真的方法,主要分成以下几个部分:一、软件要求1、与CustomSim兼容的VCS,本文档中分别是xa2018.09和vcsmx_v2018092、Custom Waveview(波形查看软件,非必须)3、IC614或更新版本的Cadence(OA)或更新版本的IC5.1.4.1-USR5(CDBA),本文档以IC617为例。4、相应的license二、安装并设置CustomSim ADE L交互界面安装CustomSim有两种方式,分别是安装在Cadence目录中和目录外。本文档只介绍第二种方法,即安装在Cadence目录外。具体步骤如下:1、设置环境变量:setenv CDS_LOAD_ENV CSF2、在CustomSim的安装目录下找到名为CustomSim.cdsenv的文件,位置在CustomSim安装目录/ade/CustomSimADE/CustomSim.cdsenv,将其复制到home目录下。(这是CustomSim的初始化文件,不复制也无所谓)3、在home下找到.cdsinit文件并在文件中将CustomSim.ile文件的路径添加进去:Load(“CustomSim安装目录/ade/CustomSimADE/CustomSim.ile”)(这里面包含了Cadence环境下的CustomSim ADE SKILL代码)4、设置环境变量:setenv CDS_Netlisting_Mode Analog5、如果Cadence版本早于IC617且CustomSimADE版本晚于M-2017.03,则需要设置如下环境变量:setenv CDS_AUTO_64BIT ALL(在本文档中不需要进行此设置,但设置了也无妨。)6、全部设置完成后就可以按照正常的方式启动Cadence软件了。三、CustomSim ADE L的使用CustomSim ADE交互界面支持Cadence的schematic和config两种方式的设置。Schematic通常用于纯模拟仿真(CustomSim)而config通常用于混合信号仿真(CustomSim-VCS),本文档使用第二种方法。下面是设置数模混合仿真的具体步骤:1、创建原理图:新建schematic并将具体的原理图电路添加进去,模拟部分按照正常的方式创建电路并生成symbol,数字电路的创建方法有如下几种:①新建cell view,类型选择Verilog,view会自动变成functional,确定之后在里面编辑数字电路,保存并检查无误后会自动弹出生成symbol的界面,完成之后就可以用平时调用模拟电路的方法调用该模块。②大多数情况下模拟工程师并不需要写数字代码,只需要将写好的代码调用即可,此时可以用之前的方式新建verilog之后将数字代码复制进来即可。(也可以找到代码的路径将数字代码复制过去覆盖原来的代码,并修改好数字里面的module名字,重新打开该verilog再保存退出,同样可以弹出生成symbol的界面。)③CustomSim也提供了直接加载数字代码的方式,本文档不做介绍。2、创建config:创建config的名字需要和schematic相同,类型选择config,完成后会弹出一个名为New Configuration的窗口,点击view那一栏并选择schematic(唯一的选项),然后Global Bindings需要进行设置,设置之前先对各个选项做简要介绍:①Library List:Library列表,可以是Cadence自带的library,可以是工艺库,也可以是用户自定义的库,可以定义一个,也可以定义多个,如果定义多个需要用空格隔开。②View List:即之前定义过的库中所包含的view都会在里面显示。CustomSim支持的View List包括:hspiceD、spice、cmos_sch、veriloga和schematic。③Stop List:此处的内容定义了生成网表的类型,如果想生成spectre格式的网表需要在此栏填写spectre同时View List栏也需要加入spectre,如果想生成HSPICE格式的网表则需要在两栏同时填写hspiceD或者HSPICE。(注意此栏不要填错,要根据你使用的仿真器类型填写。④Constraint List:(作用不明)实际设置:可以直接点击底部的Use Template然后选择AMS并确定,实测可以成功仿真而无需额外设置,前提是使用spectre仿真。点击ok完成设置会弹出新的界面,在界面中找到ADE L选项并点击就会启动ADE界面和schematic界面。接下来的就可以关闭config界面进行下一步的设置了。四、电路设置这一步的设置方法基本与平时相同,也比较简单。1、点击Setup→Simulator/Directory/Host在弹出的界面选择CustomSim作为仿真器并确认(仿真路径可以按照自己的需求设置,不设置也可)。2、如果你之前的原理图中已经同时包含了数字和模拟模块,CustomSim就会自动选择仿真类型为混合信号仿真,无需手动设置。五、ADE环境下CustomSim的设置这一步主要是对仿真器的部分重要选项进行设置,主要是仿真器的选择和网表类型的选择。具体如下:1、在ADE L界面点击Setup→Environment会弹出设置界面:在其中可以看到Simulator Selection/Netlist Syntax/Waveform Output Format等选项。此处我们选择:CunstomSim/spectre/fsdb+fsdb(分别对应仿真器/网表/数字波形格式+模拟波形格式,波形格式可以根据自己的喜好和使用的看波形的软件设置),另外# of Cores是多核仿真选项,默认为1,如果需要加快仿真速度可以在其中填入需要的CPU的数量,如需要8颗CPU则在里面填写8(需要注意的是CPU数量并非会全部用到,仿真器会自己决定用到的数目,例如填了8,实际可能只用到了6,但不会超过8,猜测跟实际的电路复杂程度有关。)2、仿真选项设置:点击Simulation→Option→Digital,在top name栏点击Use Top Cell Name,并确定。(这一步很重要,不进行此设置仿真会无法继续)3、设置transient仿真:点击Analyses→Choose后在stop栏填入需要的仿真时间并确定。(只有tran可选)4、另外还有Model的添加,以及其它的自定义的设置再次不过多介绍。可以自行试验。六、波形保存上一步结束后就已经可以进行仿真了,但为了加快仿真速度,通常会减少保存的波形节点的数量,这一步介绍保存的方法。点击Optput→To Be Saved→Select On Design之后再原理图中依次选择需要保存的节点电压和电流,按esc完成选择。七、开始仿真Simulation→Netlist and Run开始仿真!八、常见错误及解决方法上一步中可能会有如下错误:如果模拟电路中调用了电阻且电阻是多跟串联的形式,仿真器可能会报错并提示存在器件名字和net冲突的问题,此时只需要将其中一个的名字改掉就可以了。具体方法不做赘述。九、参考文档CustomSim User Guide的CustomSim ADE Interface Integration部分。ps:仅做记录学习用,个人不推荐,仿真还是要使用自动化的命令效率才高,debug 才需要图形界面。 -
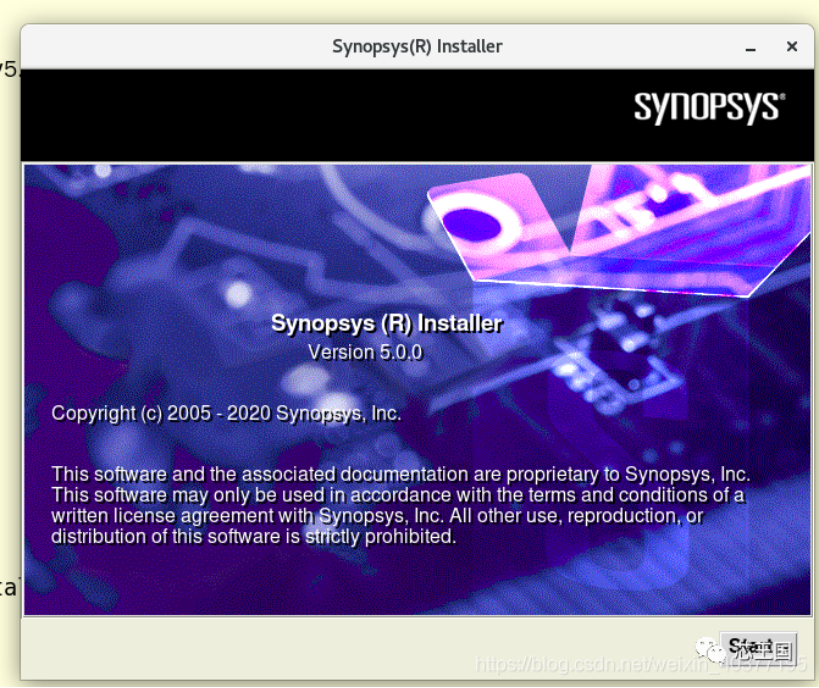
EDA-IC设计平台 Synopsys tools套装 VCS2018 Verdi2018 链接: https://pan.baidu.com/s/1pcuTqFEkMmgndafvnhlzlA 提取码: cm7e 复制这段内容后打开百度网盘手机App,操作更方便哦 --来自百度网盘超级会员v3的分享安装好的EDA环境,解压可以直接使用:环境为vmware虚拟机;解压后,使用vmware打开启动,选择“我已移动”,有问题可以联系我。链接: https://pan.baidu.com/s/1lvp4WUzRCQIZmHM8wrHSyw 提取码: 8q4c 复制这段内容后打开百度网盘手机App,操作更方便哦 --来自百度网盘超级会员v3的分享账户root密码:2020License到2030年安装1)安装installer提示:教程非本人所写,稍有改动,原文详见图片logo进入到synopsysinstaller_v5.0目录下,先运行.run文件,然后提示你输入安装路径,默认回车在当下目录就行;完成后直接运行生成的setup.sh文件。但是会出现如下error。sudo ./SynopsysInstaller_v5.0.run./setup.sh这个问题应该是缺少依赖库,先查找这个库出自那个安装包,然后进行安装。安装过程中会有提示,输入“y”回车就行。repoquery --nvr --whatprovides libXss.so.1sudo yum install libXScrnSaver-1.2.2-6.1.el7依赖库安装好后,再次运行 “./setup.sh”就会出现安装界面了。2)安装IC软件进入到home目录下,新建synopsys的文件夹,以后synopsys的软件均安装在这个目录下;home不是在普通用户下,需要超级用户权限,而软件安装必须在普通用户下所以需要将这个文件加权限打开;sudo mkdir synopsyssudo chmod 777 synopsys然后回到install目录下,运行“./setup.sh”开始安装,点击start;默认,点击next。这里需要选择安装包的路径,我们先安装scl,选择好点击ok;这里选择我们安装路径,选择我们上面新建的synopsys目录下。全部选上,next。安装确认,没有问题点击next;点击接受并安装,安装完成点击 Finish,然后点击Dismiss完成;其他synopsys软件也是这样步骤,依次安装完就行!4.license生成、环境以及激活1)启动scl_keygen生成器这个需要在window下进行,双击运行scl_keygen.exe.需要填写这4项信息,HOST ID Daemon 和HOST ID Feature填写一样的,Port选择27000。进入虚拟机,打开terminal使用以下命令查找hostnameifconfig我的填写如下,然后点击Generate生成license打开生成licens文件,修改第二行,这个需要与虚拟机里面scl路径一致,不然license无效。修改好后把这个文件复制到共享文件中。这个文件最后需要放到这个“scl/2018.06/admin/license/”目录下,要与环境里面设置的路径一致。2)环境设置打开.bashrc环境文件,加入以下内容,对应自己安装路径。但是需要注意倒数第二行,需要确认主机名是否正确。保存退出,source一下。export DVE_HOME=/home/synopsys/vcs/O-2018.09-SP2 export VCS_HOME=/home/synopsys/vcs/O-2018.09-SP2 export VCS_MX_HOME=/home/synopsys/vcs-mx/O-2018.09-SP2 export LD_LIBRARY_PATH=/home/synopsys/verdi/Verdi_O-2018.09-SP2/share/PLI/VCS/LINUX64 export VERDI_HOME=/home/synopsys/verdi/Verdi_O-2018.09-SP2 export SCL_HOME=/home/synopsys/scl/2018.06 #dve PATH=$PATH:$VCS_HOME/gui/dve/bin alias dve="dve" #VCS PATH=$PATH:$VCS_HOME/bin alias vcs="vcs" #VERDI PATH=$PATH:$VERDI_HOME/bin alias verdi="verdi" #scl PATH=$PATH:$SCL_HOME/linux64/bin export VCS_ARCH_OVERRIDE=linux #LICENCE export LM_LICENSE_FILE=27000@localhost.localdomain alias lmg_synopsys="lmgrd -c /home/synopsys/scl/2018.06/admin/license/Synopsys.dat"3)激活先使用以下命令设置开放端口:firewall-cmd --zone=public --add-port=27000/tcp --permanentfirewall-cmd --reload然后在输入“lmg_synopsys”进行激活,这个每次启动虚拟机都需要这样操作一下。但是这里提示缺少依赖库。输入以下命令进行安装:lmg_synopsysyum install redhat-lsb.i686激活好后输入“verdi”打开verdi工具,查看是否激活成功,但是这儿有是有错误,使用下面命令进行安装,成功后再输入“verdi”,能够打开verdi,激活成功sudo yum install libpng12 -y4.测试工程使用以下命令将12文件下的ic_pro.tar解压在home目录下,然后进入到工程的仿真目录下,用gvim打开make脚本,这个就是仿真的脚本。tar -xf ./12/ic_pro.tarcd ic_pro/heart/sim/输入以下命令进行仿真,make vcsmake verdi如果有错误提示:gcc: Command not found。需要安装一下gcc,但是也会有其他问题,一般可能是环境和license有问题,需要仔细去核对一下。使用以下命令安装gcc:yum -y update gccyum -y install gcc+ gcc-c++仿真的效果如下,使用verdi查看波形,这个工程可以看我这篇文章: 来自:https://bbs.eetop.cn/thread-895489-1-1.htmlps:本文章自做笔记记录,个人不推荐,现在开源工具也很发达,个人学习使用可以使用开源工具。
-
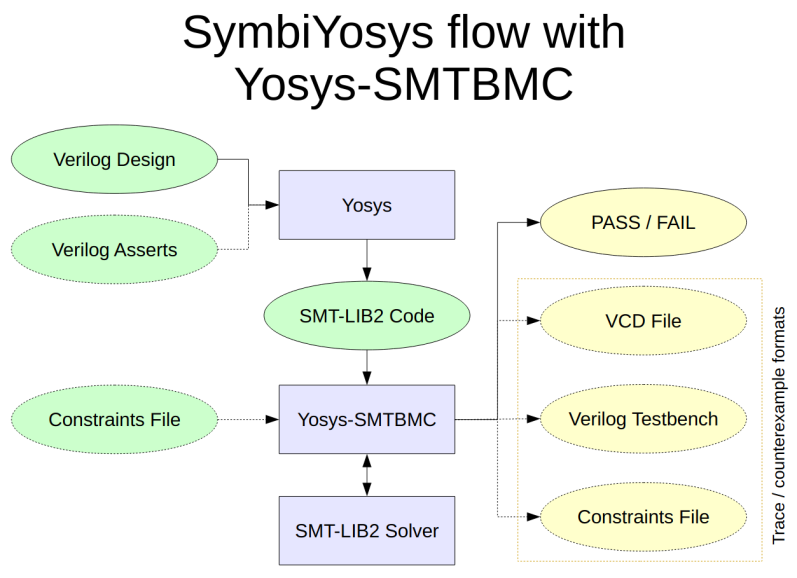
使用 SymbiYosys 进行验证 Yosys 是一个开源的 Verilog HDL 综合工具包。它支持将电路的状态转换编码为 SMT-LIBv2 中的函数。由此出发,可以对电路进行一系列形式化验证。注意本文仅对相关工具的一般使用方法进行介绍,不涉及验证原理、算法分析等内容。本文讨论的内容均为 Assertion Based Verification (ABV),除此之外 Yosys 还支持 Symbolic Model Checking、Formal Equivalence Checking,相关用法有待进一步整理。Motivating Exampletest.v 定义了一个简单的时序逻辑电路(此示例电路来自 Yosys Command Reference Manual),它只有输出,没有输入。它的输出可以理解为一个数列 yn+1=or(shl(yn),neg(yn)),首项 y0 的值是电路的初始状态。module test(input clk, output reg [3:0] y); always @(posedge clk) y <= (y << 1) | ^y; endmodule我们的目标是验证输出 y 的值不可能从一个非零值变为一个零值。为了验证该性质,需要将其写为 SMT-LIBv2 表达式,交给 SMT solver 求解。因此,首先需要明白编码电路的方式。使用以下综合脚本(synthesis script)test.ys 指示 Yosys 对电路进行变换,得到 test.smt2 文件。# Read Verilog source file and convert to internal representation .read_verilog test.v # Elaborate the design hierarchy. # Should always be the first command after reading the design. hierarchy -check -top test # Convert “processes” (the internal representation of behavioral Verilog code) # into multiplexers and registers .proc # Perform some basic optimizations and cleanups .opt # Check for obvious problems in the design .check -assert # Write a SMT-LIBv2 description of the current design .write_smt2 test.smt2理解 synthesis script以上脚本包含了3种类型的指令:Frontends:从文件中读取输入(一般为 Verilog 代码)Passes:在电路上应用等价变换Backends:将处理后的电路输出到文件(支持不同的格式,如 Verilog, BLIF, EDIF, SPICE, BTOR 等)这也是所有典型的 Yosys synthesis script 都具有的结构,由此可见综合的过程与编译的过程非常相似。事实上,Yosys 定义了一种电路的中间表示格式 RTLIL (RTL Intermediate Language),所有的 Passes 都是在以此 IR 表示的抽象语法树(AST)上实现的。1 $ yosys test.ysYosys 输出的文件如下。此文件中定义了一个对应电路状态的类型 |_s|;电路中的输入(input)、输出(output)、寄存器(register)、线路(wire)都有各自对应的函数,这些函数名为 |_n |,它们接受一个电路状态作为输入,返回 Bool 类型或 BitVec 类型,对应具体的值。另外一个重要的函数为 |_t|,它接受两个状态 state, next_state 作为输入,当两者之间存在状态转换关系时,则返回 True,反之则返回 False。它们组合起来编码了电路的行为。SMT-LIBv2 description generated by Yosys 0.21+7 (git sha1 d98738db5, clang 10.0.0-4ubuntu1 -fPIC -Os); yosys-smt2-module test(declare-sort |test_s| 0)(declare-fun |test_is| (|test_s|) Bool)(declare-fun |test#0| (|test_s|) Bool) ; \clk; yosys-smt2-input clk 1; yosys-smt2-clock clk posedge; yosys-smt2-witness {"offset": 0, "path": ["\clk"], "smtname": "clk", "type": "posedge", "width": 1}; yosys-smt2-witness {"offset": 0, "path": ["\clk"], "smtname": "clk", "type": "input", "width": 1}(define-fun |test_n clk| ((state |test_s|)) Bool (|test#0| state)); yosys-smt2-witness {"offset": 0, "path": ["\y"], "smtname": 1, "type": "reg", "width": 4}(declare-fun |test#1| (|test_s|) (_ BitVec 4)) ; \y; yosys-smt2-output y 4;yosys-smt2-register y 4(define-fun |test_n y| ((state |test_s|)) (_ BitVec 4) (|test#1| state))(define-fun |test#2| ((state |test_s|)) Bool (xor (= ((_ extract 0 0) (|test#1| state)) #b1) (= ((_ extract 1 1) (|test#1| state)) #b1) (= ((_ extract 2 2) (|test#1| state)) #b1) (= ((_ extract 3 3) (|test#1| state)) #b1))) ; $reduce_xor $test.v:3$3_Y(define-fun |test#3| ((state |test_s|)) (_ BitVec 4) (bvor (concat ((_ extract 2 0) (|test#1| state)) #b0) (concat #b000 (ite (|test#2| state) #b1 #b0)))) ; $0\y3:0) Bool true)(define-fun |test_u| ((state |test_s|)) Bool true)(define-fun |test_i| ((state |test_s|)) Bool true)(define-fun |test_h| ((state |test_s|)) Bool true)(define-fun |test_t| ((state |test_s|) (next_state |test_s|)) Bool (= (|test#3| state) (|test#1| next_state)) ; $procdff$5 \y) ; end of module test; yosys-smt2-topmod test; end of yosys output现在,为了表示上述性质,可以定义两个状态 s1, s2,它们满足:1.s1 到 s2 存在状态转换关系2.s1 中 y != 03.s2 中 y == 0之后交给 SMT solver 验证其可满足性,若不能满足,则验证了不存在这样的情况。 we need QF_UFBV for this proof(set-logic QF_UFBV); insert the auto-generated code here%%; declare two state variables s1 and s2(declare-fun s1 () test_s)(declare-fun s2 () test_s); state s2 is the successor of state s1(assert (test_t s1 s2)); we are looking for a model with y non-zero in s1(assert (distinct (|test_n y| s1) #b0000)); we are looking for a model with y zero in s2(assert (= (|test_n y| s2) #b0000)); is there such a model?(check-sat)将上面的 test.ys 最后一行修改为:1 write_smt2 -tpl test.tpl test.smt2新的输出文件中包含了模版文件 test.tpl 的内容,并将其中的 %% 替换为了原本 write_smt2 命令的输出,可以将它作为 SMT solver 的输入。例如,调用 z3 进行求解,得到 unsat 的结果。12 $ z3 test.smt2unsat使用 SymbiYosys 进行验证上一节介绍的方法需要用户理解 write_smt2 命令的输出,并直接使用其中定义的函数,才能将需要验证的性质编写为 SMT-LIBv2 格式的表达式,这样不免有些繁琐。Yosys 还提供了 SymbiYosys (sby) 工具,它可以理解为一个前端驱动程序(front-end driver program),支持解析用户在源文件中定义的断言(assertions),直接尝试进行证明。来看另一个例子,下面是用 System Verilog 定义的一个计数器(此示例代码来自参考资料中 Formal Verification of RISC-V cores with riscv-formal 这一幻灯片的第3~4页)。module hello ( input clk, rst, output [3:0] cnt); reg [3:0] cnt = 0; always @(posedge clk) begin if (rst) cnt <= 0; else cnt <= cnt + 1; endendmodule现在来定义此电路需要满足的性质。首先用1个 assume 语句表明验证的前提(也就是在求解器考虑的所有情形中,此性质都得到满足);assert 语句则是求解器需要证明的性质。module hello (/* ... */);/* ... */ `ifdef FORMAL always @* assume (cnt != 10); always @* assert (cnt != 15); `endif endmoduleSymbiYosys 使用一个 .sby 文件来描述验证过程中执行的任务,文件中包含若干个节(section),每个节由方括号括起的小标题表示。下面的文件中,[options] 节将证明模式设置为“使用 Unbounded model check 验证 safety properties”,并且将 k-induction 的深度设置为10;[script] 中是处理输入文件用到的 Yosys 命令;输入文件列在 [files] 节中。关于 .sby 文件语法的更多信息请参考 Reference for .sby file format,这里并不展开说明。mode provedepth 10[engines] smtbmc z3[script] read_verilog -formal hello.sv prep -top hello[files] hello.sv将上面的两个文件放在同一目录下,然后调用 sby 程序,即可获得证明结果。$ sby -f hello.sby...SBY 19:06:39[hello] engine_0.induction: finished (returncode=0)SBY 19:06:39 [hello] engine_0: Status returned by engine for induction: pass...SBY 19:06:39 [hello] engine_0.basecase: finished (returncode=0)SBY 19:06:39 [hello] engine_0: Status returned by engine for basecase: passSBY 19:06:39 [hello] summary: Elapsed clock time [H:MM:SS (secs)]: 0:00:00 (0)SBY 19:06:39 [hello] summary: Elapsed process time [H:MM:SS (secs)]: 0:00:00 (0)SBY 19:06:39 [hello] summary: engine_0 (smtbmc z3) returned pass for inductionSBY 19:06:39 [hello] summary: engine_0 (smtbmc z3) returned pass for basecaseSBY 19:06:39 [hello] summary: successful proof by k-induction.SBY 19:06:39 [hello] DONE (PASS, rc=0)
-
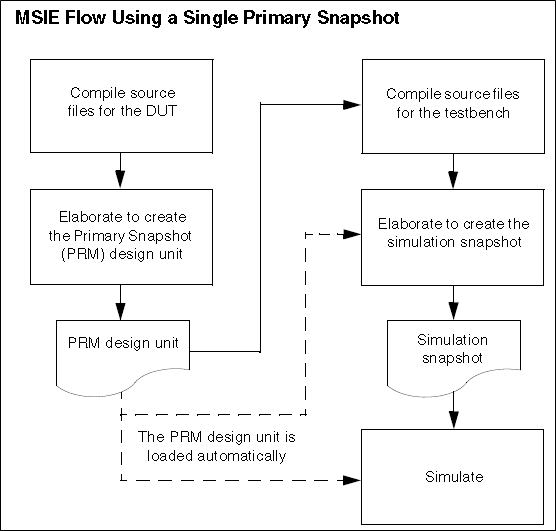
cadence-irun(xrun) 增量编译 irun支持MSIE编译,MSIE的全称是 multi-snapshot incremental elaboration。将多个编译好的snapshot,组合成一个最终的snapshot,去仿真。利用这个技术,我们就可以使用irun来进行增量编译,从而节约编译时间。为了实现增量编译,我们将snapshot分为primary snapshot和incremental snapshot,primary snapshot指环境中不经常变化的代码,编译成的snapshot,incremental snapshot指环境中经常变化的代码,编译成的snapshot,最后再将这两个snapshot进行组合,得到最终的snapshot,去仿真。一、编译流程下图是单个primary snapshot的编译流程:将DUT,编译成primary snapshot,TB载入primary snapshot后,和tb一起进行编译,得到仿真的snapshot,再去仿真。下图是多个primary snapshot的编译流程:将SOC编译成primary snapshot,将IP编译成primary snapshot,将2个primary snapshot,和tb一起编译,得到最终的仿真snapshot,再进行仿真。二、实现方法一般情况下,我们是将DUT和TB进行分开编译,以实现增量编译。对于验证人员来说,DUT是不会变化的,因此我们可以将DUT,编译成primary snapshot,TB部分载入DUT的primary snapshot,和自己的TB代码一起编译,成最终的incremental snapshot,去仿真。这样,当环境修改之后,不需要重新编译RTL,这样,就节省了编译时间。特别是RTL的设计规模很大之后,这节约的时间,就更明显了。三、测试测试环境,组织结构如下:flist.rtl : 编译rtl的flistflist.tb : 编译tb的flistMakefiletop_tb.sv : testbench顶层source: 存放rtl code的目录uvm_code:存放tb code的目录1、makefile解析 Makefile内容如下:tc:= base_test_0 irun_prim: irun -sv -64bit -f flist.rtl -mkprimsnap -top uart_tx -l irun_rtl.log irun_inca: irun -c -sv -64bit -f flist.tb -uvm -uvmhome CDNS-1.2 -primtop uart_tx -l irun_tb.log irun_run: irun -R +UVM_TESTNAME=$(tc) -l irun_run.log clean: rm -rf INCA_libs rm -f *.log 对于 irun_prim 目标,根据RTL代码生成primary snapshot。-sv: 启动sv编译-64bit: 启动64位的irun-f flist.rtl : 指定编译RTL的flist-mkprimsnap: 生成primary snapshot-top: 指定RTL的顶层-l: 指定log文件对于 irun_inca 目标,载入RTL编译得到的primary snapshot,根据TB代码生成incremental snapshot, -c: 只编译,不仿真-f flist.tb: 指定编译TB的flist-uvm: 启动uvm编译-uvmhome CDNS-1.2: 指定uvm的home目录为irun工具目录下的UVM-1.2目录-primtop uart_tx: 指定需要载入primary snapshot的顶层。对于 irun_run 目标,仿真。-R : 不编译,直接仿真+UVM_TESTNAME: uvm指定testcase的选项2、第一次执行make irun_prim; 生成primary snapshotmake irun_inca: 载入primary snapshot,和tb一起编译生成incremantal snapshot。载入primary snapshot:生成incremantal snapshot。3、第二次执行此时,修改top_tb.sv的代码,增加一行打印。因为RTL没有编译,因此可以跳过编译RTL,直接make irun_inca。载入 primary snapshot,跳过了代码生成。生成incremantal snapshot。仿真,打印出hello。测试的RTL,规模比较小,感受不到增量编译的好处,但是当RTL的规模一旦变得很大,编译RTL就要花费数十分钟,此时,就可以体会到增量编译的好处了。在服务器,测试我们的环境,使用增量编译后,将编译时间,从5分钟,缩减到了20秒。https://www.cnblogs.com/david-wei0810/p/14177607.html
-
Verilog-AMS 知识汇总 verilog-AMS数据类型 --- wrealWREAL 是Verilog-AMS支持的一种新的数值模型。WREAL的特殊之处在于它使用有限的浮点数值的点来模拟一条电路工作曲线。而SPICE和Verilog-A的计算结果是一条理论上可以无限精度,包含无限点的的曲线。从某种程度上,WREAL的实现方式类似于Fast-Spice的查表点工作模式,其目的是进一步简化仿真,从而支持更大规模的模拟系统仿真。 使用WREAL的最大好处是速度快。使用WREAL变量的模型在计算的时候无需使用SPICE迭代运算。它使用的是比较简单的,直接推导的函数来模仿模拟电路真正的工作情况。 相比SPICE和Verilog-A的模型必须使用SPICE仿真器的迭代运算,WREAL仿真器使用离散事件触发,就像数字仿真器那样。这给WREAL的计算上带来极大的速度优势。但同时,离散的计算模式使得WREA模型在含有反馈的电路中无法给出准确的结果。在普通电路中它也需要牺牲输出的精度。所以,WREAL并不适用于需要精确度量的模拟电路的模型中。 WREAL的一个问题是,它需要对真正的模拟电路的行为有一个非常好的预测。因为,WREAL的所有计算都是前向的,我们想要用这些前向计算来模拟SPICE仿真器迭代结算的结果,就需要对实际电路工作情况有个很好的了解。然而,模型通常在设计阶段的前期实现,而此时通常不会有很好的对真实电路的预测。如果WREAL模型无法很好的体现SPICE仿真器对真实电路的仿真结果,那模型的意义就不大了。亦或需要在设计后期随着真实电路的开发修改模型,这样就会牺牲一些研发的时间。 有一些相关的研究正在进行中,比如利用简单的电路生成WREAL模型,这样可以作为未来新项目系统的起始WREAL模型。也有一些研究包括迭代WREAL和真实电路仿真,这样可以自动修改WREAL模型等等。但不管怎么,对于WREAL在大规模需要精度的验证中的使用,还是需要一定考虑。 一、端口(Port) Port(端口),也被称为引脚或端子,被用来连接模块到其他模块。因此,端口就是电线。简单连接的端口声明是连接声明,其中关键字wire被以下方向说明符之一替换:input、output或inout。例如: module inv (out, in); output out; input in;assign out = ~in;endmodulemodule mux (out, in0, in1, sel); output [7:0] out; input [7:0] in0, in1; input sel;assign out = sel ? in1 : in0;endmodule 对于其他类型的连接,或者寄存器(寄存器只能作为输出声明),声明的前面简单地加上方向说明符: module counter (out, clk); output reg [3:0] out;initial out = 0;always @(posedge ckl) out = out + 1;endmodule 默认情况下,多位端口的内容被解释为无符号数(值被解释为正二进制数)。可以明确指定数字是被解释为有符号数还是无符号数,如下所示: input unsigned [3:0] gain;input signed [6:0] offset;在这种情况下,增益是无符号的,而偏移量是有符号的,这意味着它被解释为有符号的双补数。因此,如果增益= 4'bF,则其值解释为15,如果offset = 7'b7FF,则其值解释为-1。 If it is necessary to apply a discipline to a port, the port declaration should be repeated with direction specifier replaced by the discipline. For example: module buffer (out, in); output out; input in; electrical out, in;analog V(out) <+ V(in);endmodule Verilog还支持连续信号总线和wreal(必须声明为总线而不是数组): module mux (out, in, sel); output out; input [1:0] in; input sel; electrical out; electrical [1:0] in;analog begin @(sel); V(out) <+ transition(sel === 0, 0, 100n)*V(in[0]); V(out) <+ transition(sel === 1, 0, 100n)*V(in[1]);endendmodulemodule mux (out, in, sel); output wreal out; input wreal [1:0] in; input sel;assign out = sel ? in[1] : in[0];endmodule Note:The Cadence simulator does not seem to follow the standard when it comes to declaring buses of wreals. With the Cadence simulator you should declare buses of wreals as arrays rather than as buses: module mux (out, in, sel); output wreal out; input wreal in[1:0]; input sel;assign out = sel ? in[1] : in[0];endmodule———————————————— 版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。 原文链接:https://blog.csdn.net/gsjthxy/article/details/107618649