搜索到
11
篇与
的结果
-
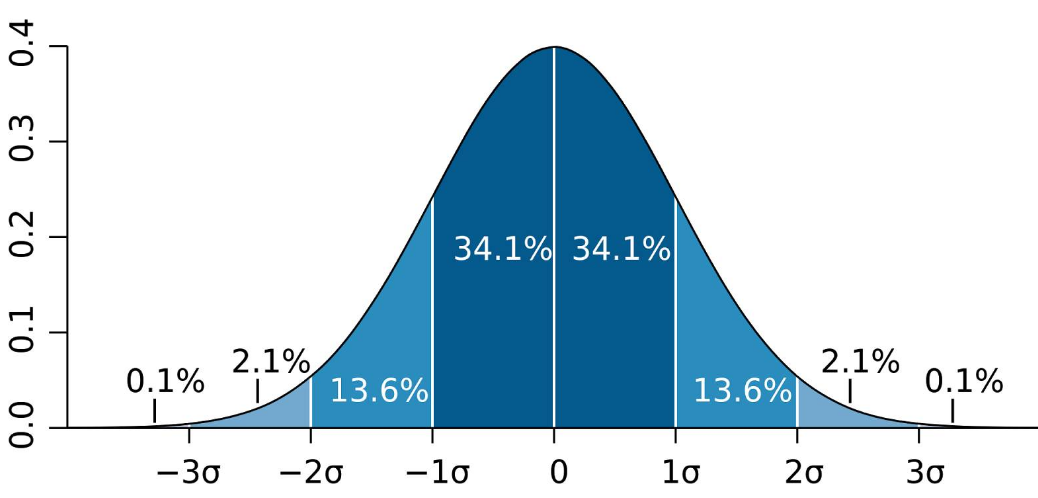
 一份数学小白也能读懂的「马尔可夫链蒙特卡洛方法」入门指南 机器之心2017年12月24日12:46作者:Ben Shaver机器之心编译参与:黄小天、刘晓坤在众多经典的贝叶斯方法中,马尔可夫链蒙特卡洛(MCMC)由于包含大量数学知识,且计算量很大,而显得格外特别。本文反其道而行之,试图通过通俗易懂且不包含数学语言的方法,帮助读者对 MCMC 有一个直观的理解,使得毫无数学基础的人搞明白 MCMC。在我们中的很多人看来,贝叶斯统计学家不是巫术师,就是完全主观的胡说八道者。在贝叶斯经典方法中,马尔可夫链蒙特卡洛(Markov chain Monte Carlo/MCMC)尤其神秘,其中数学很多,计算量很大,但其背后原理与数据科学有诸多相似之处,并可阐释清楚,使得毫无数学基础的人搞明白 MCMC。这正是本文的目标。那么,到底什么是 MCMC 方法?一言以蔽之:MCMC 通过在概率空间中随机采样以近似兴趣参数(parameter of interest)的后验分布。我将在本文中做出简短明了的解释,并且不借助任何数学知识。首先,解释重要的术语。「兴趣参数」(parameter of interest)可以总结我们感兴趣现象的一些数字。我们通常使用统计学评估参数,比如,如果想要了解成年人的身高,我们的兴趣参数可以是精确到英寸的平均身高。「分布」是参数的每个可能值、以及我们有多大可能观察每个参数的数学表征,其最著名的实例是钟形曲线:在贝叶斯统计学中,分布还有另外一种解释。贝叶斯不是仅仅表征一个参数值以及每个参数有多大可能是真值,而是把分布看作是我们对参数的「信念」。因此,钟形曲线表明我们非常确定参数值相当接近于零,但是我们认为在一定程度上真值高于或低于该值的可能性是相等的。事实上,人的身高确实遵从一个正态曲线,因此我们假定平均身高的真值符合钟形曲线,如下所示:很明显,上图表征是巨人的身高分布,因为据图可知,最有可能的平均身高是 6'2"(但他们也并非超级自信)。让我们假设其中某个人后来收集到一些数据,并且观察了身高在 5"和 6"之间的一些人。我们可以用另一条正态曲线表征下面的数据,该曲线表明了哪些平均身高值能最好地解释这些数据:在贝叶斯统计中,表征我们对参数信念的分布被称为「先验分布」,因为它在我们看到任何数据之前捕捉到了我们的信念。「可能性分布」(likelihood distribution)通过表征一系列参数值以及伴随的每个参数值解释观察数据的可能性,以总结数据之中的信息。评估最大化可能性分布的参数值只是回答这一问题:什么参数值会使我们更可能观察到已经观察过的数据?如果没有先验信念,我们可能无法对此作出评估。但是,贝叶斯分析的关键是结合先验与可能性分布以确定后验分布。它可以告诉我们哪个参数值最大化了观察到已观察过的特定数据的概率,并把先验信念考虑在内。在我们的实例中,后验分布如下所示:如上所示,红线表征后验分布。你可以将其看作先验和可能性分布的一种平均值。由于先验分布较小且更加分散,它表征了一组关于平均身高真值的「不太确定」的信念。同时,可能性分布在相对较窄的范围内总结数据,因此它表征了对真参数值的「更确定」的猜测。当先验与可能性分布结合在一起,数据(由可能性分布表征)主导了假定存在于这些巨人之中的个体的先验弱信念。尽管该个体依然认为平均身高比数据告诉他的稍高一些,但是他非常可能被数据说服。在两条钟形曲线的情况下,求解后验分布非常容易。有一个结合了两者的简单等式。但是如果我们的先验和可能性分布表现很差呢?有时使用非简化的形状建模数据或先验信念时是最精确的。如果可能性分布需要带有两个峰值的分布才能得到最好地表征呢?并且出于某些原因我们想要解释一些非常奇怪的先验分布?通过手动绘制一个丑陋的先验分布,我已可视化了该情景,如下所示:可视化由 Matplotlib 渲染,并使用 MS Paint 做了改善如前所述,存在一些后验分布,它给出了每个参数值的可能性分布。但是很难得到完整的分布,也无法解析地求解。这就是使用 MCMC 方法的时候了。MCMC 允许我们在无法直接计算的情况下评估后验分布的形状。为了理解其工作原理,我将首先介绍蒙特卡洛模拟(Monte Carlo simulation),接着讨论马尔可夫链。蒙特卡洛模拟只是一种通过不断地生成随机数来评估固定参数的方法。通过生成随机数并对其做一些计算,蒙特卡洛模拟给出了一个参数的近似值(其中直接计算是不可能的或者计算量过大)。假设我们想评估下图中的圆圈面积:由于圆在边长为 10 英寸的正方形之内,所以通过简单计算可知其面积为 78.5 平方英寸。但是,如果我们随机地在正方形之内放置 20 个点,接着我们计算点落在圆内的比例,并乘以正方形的面积,所得结果非常近似于圆圈面积。由于 15 个点落在了圆内,那么圆的面积可以近似地为 75 平方英寸,对于只有 20 个随机点的蒙特卡洛模拟来说,结果并不差。现在,假设我们想要计算下图中由蝙蝠侠方程(Batman Equation)绘制的图形的面积:我们从来没有学过一个方程可以求这样的面积。不管怎样,通过随机地放入随机点,蒙特卡洛模拟可以相当容易地为该面积提供一个近似值。蒙特卡洛模拟不只用于估算复杂形状的面积。通过生成大量随机数字,它还可用于建模非常复杂的过程。实际上,蒙特卡洛模拟还可以预测天气,或者评估选举获胜的概率。理解 MCMC 方法的第二个要素是马尔科夫链(Markov chains)。马尔科夫链由存在概率相关性的事件的序列构成。每个事件源于一个结果集合,根据一个固定的概率集合,每个结果决定了下一个将出现的结果。马尔科夫链的一个重要特征是「无记忆性」:可能需要用于预测下一个时间的一切都已经包含在当前的状态中,从事件的历史中得不到任何新信息。例如 Chutes and Ladders 这个游戏就展示了这种无记忆性,或者说马尔科夫性,但在现实世界中很少事物是这种性质的。尽管如此,马尔科夫链也是理解现实世界的强大工具。在十九世纪,人们观察到钟形曲线在自然中是一种很常见的模式。(我们注意到,例如,人类的身高服从钟形曲线分布。)Galton Boards 曾通过将弹珠坠落并通过布满木钉的板模拟了重复随机事件的平均值,在弹珠的最终数量分布中重现了钟形曲线:俄罗斯数学家和神学家 Pavel Nekrasov 认为钟形曲线,或者更一般的说,大数规律只不过是小孩子的游戏和普通的谜题中的伪假象,其中每个事件之间都是完全独立的。他认为现实世界中的互相依赖的事件,例如人类行为,并不遵循漂亮的数学模式或分布。Andrey Markov(马尔科夫链正是以他的名字命名)试图证明非独立的事件可能也遵循特定的模式。他的其中一个最著名的例子是从一份俄罗斯诗歌作品中数出几千个两字符对(two-character pairs)。他使用这些两字符对计算了每个字符的条件概率。即,给定一个确定的上述字母或空白,关于下一个字母将是 A、T 或者空白等,存在一个确定的概率。通过这些概率,Markov 可以模拟一个任意的长字符序列。这就是马尔科夫链。虽然早先的几个字符很大程度上依赖于初始字符的选择,Markov 表明在长字符序列中,字符的分布会出现特定的模式。因此,即使是互相依赖的事件,如果服从固定的概率分布,将遵循平均水平的模式。举一个更有意义的例子,假设你住在一个有 5 个房间的房子里,里面有一个卧室、浴室、客厅、厨房、饭厅。然后我们收集一些数据,假定只需要当前你所处的房间和相应的时间就可以预测下一个你所处的房间的概率。例如,如果你在厨房,你有 30% 的概率会留在厨房,有 30% 的概率会走到饭厅,有 20% 的概率会走到客厅,有 10% 的概率会走到浴室,以及有 10% 的概率会走到卧室。使用每个房间的概率集合,我们可以构建一个关于你接下来要去的房间的预测链。如果想预测一个人处于厨房之后所在的房间,基于几个状态而做出预测可能有效。但由于我们的预测仅仅基于一个人在房子中的单次观察,可以合理地认为预测结果是不够好的。例如,如果一个人从卧室走到浴室,相比从厨房走到浴室的情况,他更可能会返回原来的房间。因此,马尔科夫链并不真正适用于现实世界。然而,通过迭代运行马尔科夫链数千次,确实能给出关于你接下来可能所处的房间的长期预测。更重要的是,这个预测并不受这个人起始所处的房间的影响。对此可以直观地理解为:在模拟和描述长期过程(或普遍情况)一个人所处房间的概率时,时间因素是不重要的。因此,如果我们理解了控制行为的概率,就可以使用马尔科夫链计算变化的长期趋势。希望通过介绍一些蒙特卡洛模拟和马尔科夫链,可以使你对 MCMC 方法的零数学解释有更直观的理解。回到原来的问题,即评估平均身高的后验分布:这个平均身高的后验分布的实例没有基于真实数据。我们知道后验分布在某种程度上处于先验分布和可能性分布的范围内,但无论如何都无法直接计算。使用 MCMC 方法,我们可以有效地从后验分布中提取样本,然后计算统计特征,例如提取样本的平均值。首先,MCMC 方法选择一个随机参数值。模拟过程中会持续生成随机的值(即蒙特卡洛部分),但服从某些能生成更好参数值的规则。即对于一对参数值,可以通过给定先验信度计算每个值解释数据的有效性,从而确定哪个值更好。我们会将更好的参数值以及由这个值的解释数据有效性决定的特定概率添加到参数值的链中(即马尔科夫链部分)。为了可视化地解释上述过程,首先强调一下,一个分布的特定值的高度代表的是观察到该值的概率。因此,参数值(x 轴)对应的概率(y 轴)可能或高或低。对于单个参数,MCMC 方法会从随机在 x 轴上采样开始。红点表征随机参数采样。由于随机采样服从固定的概率,它们倾向于经过一段时间后收敛于参数的高概率区域:蓝点表示当采样收敛之后,经过任意时间的随机采样。注意:垂直堆叠这些点仅仅是为了说明目的。收敛出现之后,MCMC 采样会得到作为后验分布样本的一系列点。用这些点画直方图,然后你可以计算任何感兴趣的统计特征:通过 MCMC 模拟生成的样本集合计算的任何统计特征,都是对真实后验分布的统计特征的最佳近似。MCMC 方法也可以用于评估多于一个参数的后验分布(例如,人类身高和体重)。对于 n 个参数,在 n 维空间中存在高概率的区域,其中特定的参数值集合可以更有效地解释数据。因此,我认为 MCMC 方法的本质,就是在一个概率空间中进行随机采样以近似后验分布。原文链接:https://towardsdatascience.com/a-zero-math-introduction-to-markov-chain-monte-carlo-methods-dcba889e0c50机器之心推出「Synced Machine Intelligence Awards」2017,希望通过四大奖项记录这一年人工智能的发展与进步,传递行业启示性价值。来自微信
一份数学小白也能读懂的「马尔可夫链蒙特卡洛方法」入门指南 机器之心2017年12月24日12:46作者:Ben Shaver机器之心编译参与:黄小天、刘晓坤在众多经典的贝叶斯方法中,马尔可夫链蒙特卡洛(MCMC)由于包含大量数学知识,且计算量很大,而显得格外特别。本文反其道而行之,试图通过通俗易懂且不包含数学语言的方法,帮助读者对 MCMC 有一个直观的理解,使得毫无数学基础的人搞明白 MCMC。在我们中的很多人看来,贝叶斯统计学家不是巫术师,就是完全主观的胡说八道者。在贝叶斯经典方法中,马尔可夫链蒙特卡洛(Markov chain Monte Carlo/MCMC)尤其神秘,其中数学很多,计算量很大,但其背后原理与数据科学有诸多相似之处,并可阐释清楚,使得毫无数学基础的人搞明白 MCMC。这正是本文的目标。那么,到底什么是 MCMC 方法?一言以蔽之:MCMC 通过在概率空间中随机采样以近似兴趣参数(parameter of interest)的后验分布。我将在本文中做出简短明了的解释,并且不借助任何数学知识。首先,解释重要的术语。「兴趣参数」(parameter of interest)可以总结我们感兴趣现象的一些数字。我们通常使用统计学评估参数,比如,如果想要了解成年人的身高,我们的兴趣参数可以是精确到英寸的平均身高。「分布」是参数的每个可能值、以及我们有多大可能观察每个参数的数学表征,其最著名的实例是钟形曲线:在贝叶斯统计学中,分布还有另外一种解释。贝叶斯不是仅仅表征一个参数值以及每个参数有多大可能是真值,而是把分布看作是我们对参数的「信念」。因此,钟形曲线表明我们非常确定参数值相当接近于零,但是我们认为在一定程度上真值高于或低于该值的可能性是相等的。事实上,人的身高确实遵从一个正态曲线,因此我们假定平均身高的真值符合钟形曲线,如下所示:很明显,上图表征是巨人的身高分布,因为据图可知,最有可能的平均身高是 6'2"(但他们也并非超级自信)。让我们假设其中某个人后来收集到一些数据,并且观察了身高在 5"和 6"之间的一些人。我们可以用另一条正态曲线表征下面的数据,该曲线表明了哪些平均身高值能最好地解释这些数据:在贝叶斯统计中,表征我们对参数信念的分布被称为「先验分布」,因为它在我们看到任何数据之前捕捉到了我们的信念。「可能性分布」(likelihood distribution)通过表征一系列参数值以及伴随的每个参数值解释观察数据的可能性,以总结数据之中的信息。评估最大化可能性分布的参数值只是回答这一问题:什么参数值会使我们更可能观察到已经观察过的数据?如果没有先验信念,我们可能无法对此作出评估。但是,贝叶斯分析的关键是结合先验与可能性分布以确定后验分布。它可以告诉我们哪个参数值最大化了观察到已观察过的特定数据的概率,并把先验信念考虑在内。在我们的实例中,后验分布如下所示:如上所示,红线表征后验分布。你可以将其看作先验和可能性分布的一种平均值。由于先验分布较小且更加分散,它表征了一组关于平均身高真值的「不太确定」的信念。同时,可能性分布在相对较窄的范围内总结数据,因此它表征了对真参数值的「更确定」的猜测。当先验与可能性分布结合在一起,数据(由可能性分布表征)主导了假定存在于这些巨人之中的个体的先验弱信念。尽管该个体依然认为平均身高比数据告诉他的稍高一些,但是他非常可能被数据说服。在两条钟形曲线的情况下,求解后验分布非常容易。有一个结合了两者的简单等式。但是如果我们的先验和可能性分布表现很差呢?有时使用非简化的形状建模数据或先验信念时是最精确的。如果可能性分布需要带有两个峰值的分布才能得到最好地表征呢?并且出于某些原因我们想要解释一些非常奇怪的先验分布?通过手动绘制一个丑陋的先验分布,我已可视化了该情景,如下所示:可视化由 Matplotlib 渲染,并使用 MS Paint 做了改善如前所述,存在一些后验分布,它给出了每个参数值的可能性分布。但是很难得到完整的分布,也无法解析地求解。这就是使用 MCMC 方法的时候了。MCMC 允许我们在无法直接计算的情况下评估后验分布的形状。为了理解其工作原理,我将首先介绍蒙特卡洛模拟(Monte Carlo simulation),接着讨论马尔可夫链。蒙特卡洛模拟只是一种通过不断地生成随机数来评估固定参数的方法。通过生成随机数并对其做一些计算,蒙特卡洛模拟给出了一个参数的近似值(其中直接计算是不可能的或者计算量过大)。假设我们想评估下图中的圆圈面积:由于圆在边长为 10 英寸的正方形之内,所以通过简单计算可知其面积为 78.5 平方英寸。但是,如果我们随机地在正方形之内放置 20 个点,接着我们计算点落在圆内的比例,并乘以正方形的面积,所得结果非常近似于圆圈面积。由于 15 个点落在了圆内,那么圆的面积可以近似地为 75 平方英寸,对于只有 20 个随机点的蒙特卡洛模拟来说,结果并不差。现在,假设我们想要计算下图中由蝙蝠侠方程(Batman Equation)绘制的图形的面积:我们从来没有学过一个方程可以求这样的面积。不管怎样,通过随机地放入随机点,蒙特卡洛模拟可以相当容易地为该面积提供一个近似值。蒙特卡洛模拟不只用于估算复杂形状的面积。通过生成大量随机数字,它还可用于建模非常复杂的过程。实际上,蒙特卡洛模拟还可以预测天气,或者评估选举获胜的概率。理解 MCMC 方法的第二个要素是马尔科夫链(Markov chains)。马尔科夫链由存在概率相关性的事件的序列构成。每个事件源于一个结果集合,根据一个固定的概率集合,每个结果决定了下一个将出现的结果。马尔科夫链的一个重要特征是「无记忆性」:可能需要用于预测下一个时间的一切都已经包含在当前的状态中,从事件的历史中得不到任何新信息。例如 Chutes and Ladders 这个游戏就展示了这种无记忆性,或者说马尔科夫性,但在现实世界中很少事物是这种性质的。尽管如此,马尔科夫链也是理解现实世界的强大工具。在十九世纪,人们观察到钟形曲线在自然中是一种很常见的模式。(我们注意到,例如,人类的身高服从钟形曲线分布。)Galton Boards 曾通过将弹珠坠落并通过布满木钉的板模拟了重复随机事件的平均值,在弹珠的最终数量分布中重现了钟形曲线:俄罗斯数学家和神学家 Pavel Nekrasov 认为钟形曲线,或者更一般的说,大数规律只不过是小孩子的游戏和普通的谜题中的伪假象,其中每个事件之间都是完全独立的。他认为现实世界中的互相依赖的事件,例如人类行为,并不遵循漂亮的数学模式或分布。Andrey Markov(马尔科夫链正是以他的名字命名)试图证明非独立的事件可能也遵循特定的模式。他的其中一个最著名的例子是从一份俄罗斯诗歌作品中数出几千个两字符对(two-character pairs)。他使用这些两字符对计算了每个字符的条件概率。即,给定一个确定的上述字母或空白,关于下一个字母将是 A、T 或者空白等,存在一个确定的概率。通过这些概率,Markov 可以模拟一个任意的长字符序列。这就是马尔科夫链。虽然早先的几个字符很大程度上依赖于初始字符的选择,Markov 表明在长字符序列中,字符的分布会出现特定的模式。因此,即使是互相依赖的事件,如果服从固定的概率分布,将遵循平均水平的模式。举一个更有意义的例子,假设你住在一个有 5 个房间的房子里,里面有一个卧室、浴室、客厅、厨房、饭厅。然后我们收集一些数据,假定只需要当前你所处的房间和相应的时间就可以预测下一个你所处的房间的概率。例如,如果你在厨房,你有 30% 的概率会留在厨房,有 30% 的概率会走到饭厅,有 20% 的概率会走到客厅,有 10% 的概率会走到浴室,以及有 10% 的概率会走到卧室。使用每个房间的概率集合,我们可以构建一个关于你接下来要去的房间的预测链。如果想预测一个人处于厨房之后所在的房间,基于几个状态而做出预测可能有效。但由于我们的预测仅仅基于一个人在房子中的单次观察,可以合理地认为预测结果是不够好的。例如,如果一个人从卧室走到浴室,相比从厨房走到浴室的情况,他更可能会返回原来的房间。因此,马尔科夫链并不真正适用于现实世界。然而,通过迭代运行马尔科夫链数千次,确实能给出关于你接下来可能所处的房间的长期预测。更重要的是,这个预测并不受这个人起始所处的房间的影响。对此可以直观地理解为:在模拟和描述长期过程(或普遍情况)一个人所处房间的概率时,时间因素是不重要的。因此,如果我们理解了控制行为的概率,就可以使用马尔科夫链计算变化的长期趋势。希望通过介绍一些蒙特卡洛模拟和马尔科夫链,可以使你对 MCMC 方法的零数学解释有更直观的理解。回到原来的问题,即评估平均身高的后验分布:这个平均身高的后验分布的实例没有基于真实数据。我们知道后验分布在某种程度上处于先验分布和可能性分布的范围内,但无论如何都无法直接计算。使用 MCMC 方法,我们可以有效地从后验分布中提取样本,然后计算统计特征,例如提取样本的平均值。首先,MCMC 方法选择一个随机参数值。模拟过程中会持续生成随机的值(即蒙特卡洛部分),但服从某些能生成更好参数值的规则。即对于一对参数值,可以通过给定先验信度计算每个值解释数据的有效性,从而确定哪个值更好。我们会将更好的参数值以及由这个值的解释数据有效性决定的特定概率添加到参数值的链中(即马尔科夫链部分)。为了可视化地解释上述过程,首先强调一下,一个分布的特定值的高度代表的是观察到该值的概率。因此,参数值(x 轴)对应的概率(y 轴)可能或高或低。对于单个参数,MCMC 方法会从随机在 x 轴上采样开始。红点表征随机参数采样。由于随机采样服从固定的概率,它们倾向于经过一段时间后收敛于参数的高概率区域:蓝点表示当采样收敛之后,经过任意时间的随机采样。注意:垂直堆叠这些点仅仅是为了说明目的。收敛出现之后,MCMC 采样会得到作为后验分布样本的一系列点。用这些点画直方图,然后你可以计算任何感兴趣的统计特征:通过 MCMC 模拟生成的样本集合计算的任何统计特征,都是对真实后验分布的统计特征的最佳近似。MCMC 方法也可以用于评估多于一个参数的后验分布(例如,人类身高和体重)。对于 n 个参数,在 n 维空间中存在高概率的区域,其中特定的参数值集合可以更有效地解释数据。因此,我认为 MCMC 方法的本质,就是在一个概率空间中进行随机采样以近似后验分布。原文链接:https://towardsdatascience.com/a-zero-math-introduction-to-markov-chain-monte-carlo-methods-dcba889e0c50机器之心推出「Synced Machine Intelligence Awards」2017,希望通过四大奖项记录这一年人工智能的发展与进步,传递行业启示性价值。来自微信 -
什么选择物理不可克隆函数(PUF)? 什么选择物理不可克隆函数(PUF)?20年前,数字安全只在银行卡或支付终端等专用电子设备上实现。今天,每个人都在使用以 "https://"标志的安全互联网连接到银行,我们都希望我们用智能手机操作的信息能够得到保护。加密或数字签名等加密技术已经被部署以满足这些要求。因此,越来越多的ASIC、微控制器和SoC都嵌入了硬件加密加速器或软件加密库。物联网(IoT)的兴起将加快对加密的需求。现在就让我们讨论密码学的普及情况。因为在现代密码学中算法都是公开和标准化的,使得加密技术的普及成为可能。公开算法的直接后果是密钥成为最有价值的资产,因此它们必须得到强有力的保护。历史上,第一个被设计用来保护密钥的集成电路(IC)是智能卡。随着人们对数字安全需求的日益增长,加密已经在越来越多的芯片(如通用微控制器)中得到应用,但密钥的保护一直是一个挑战。今天我们可以看到有以下几种方案:l未未实施特定保护。这种情况不应该发生,但不幸的是,这种情况还是会发生!l内部逻辑保护,如TrustZone™. 密钥可以防止逻辑攻击(如恶意软件),但不能防止物理攻击。l电路内逻辑和物理保护。l密钥存储在位于主处理器外部独立的被称为“安全元件”专用集成电路中。在集成电路(IC)中,密钥保护方案的选择取决于许多因素:lIC制造技术的可用性:非易失性存储器如EEPROM或Flash的存在直接影响到密钥的物理保护方式l市场要求:在集成电路中实现的安全级别取决于其最终用途lIC设计师专有技术:硬件保护单元的设计仍然是专家的事l上市时间l开发成本l单位成本(额外的芯片面积)人们可能认为,在大多数情况下,物理保护是没有必要的。但事实已不再是这样,因为与失效分析技术相关的自动反向工程已经使物理攻击变得可负担得起[1]。传统的安全密钥存储的设计方式包括将密钥存储在非易失性存储器(OTP、EEPROM或Flash)中,并实现布局反击措施或混淆,如芯片屏蔽、总线加扰或伪过孔等[2]。一个更稳健的解决方案依赖于通过主密钥对存储器进行加密,但随后的挑战是对主密钥本身的保护,我们又回到了最初的挑战。以这种方法是有效的并且已通过通用标准之类的认证。典型的如EAL4 +认证(或更高版本AVA_VAN.5),用来对IC的物理攻击抵抗力进行评级。这个评级是基于成功进行攻击的难度来判定,主要基于以下要求:l专业水平l时间l设备成本一般来说,如果上述标准的综合水平与攻击者所能获得的利益相比足够高,那么该实现就被认为是有效的,尽管事实上,只要有足够的时间、专业知识和预算,仍然有可能检索到密钥。上面列出的混淆方法的主要缺点是它们同样需要高度的专业知识,而只有少数IC设计人员才能掌握。这些解决方案无法轻易获得,因此在许多情况下并不适用。我们将看到,以IP形式交付的物理不可克隆功能(PUF)即使对非安全专家来说,也能实现最高级别的安全性。PUF和传统技术之间的一个基本区别是PUF本质上不受逆向工程技术的影响。PUF解决的另一个挑战是需要在密钥注入IC之前保护它们:传统方法需要在制造过程的某些步骤中注入密钥,这可能发生在晶圆测试(CP)、IC终测(FT)或PCB制造过程中。但无论选择什么步骤,秘钥必须通过测试或制造设备注入到IC中,因此安全的周边环境是必需的。安全地注入密钥是一个像给银行卡加密操作的过程,但对于医疗、工业或消费品来说,这可能是负担不起的。通常情况下,制造工作由位于偏远地区的分包商负责,而且要求分包商提供安全设施是具有挑战性的,因此必须投资访问控制设备、编写程序和定期进行审计。PUF用例私钥和秘钥存储如上所述,密钥存储通常是主要问题。 PUF生成的密钥用于片上非易失性存储器(例如EEPROM,Flash 或OTP)中建立安全库。 图1使用PUF实施高度安全的密钥库 软件IP保护一些用于医学诊断或生命体征测量的算法是多年积累和研发的结果。因此,它们是极有价值的资产,应该得到强有力的保护。而PUF生成的密钥可以通过加密保护这些软件IP。 图2基于PUF的软件IP保护设备认证身份验证是连接设备的首要安全要求之一,即确保设备是真实的。最安全的方法是执行挑战应答认证(challenge-response authentication)。该方案将随机数(挑战)发送到要进行身份验证的设备,然后该设备使用其私钥对挑战进行签名。同样,私钥必须受到严格保护。PUF原理与传统技术(涉及定制设计)相比,用于实现安全存储且保护等级更高的交钥匙解决方案听起来像是安全圣杯。我们将看到一个健壮且易于集成的PUF现在已成为现实。PUF依赖于微小的制造差异。制造差异会导致设备不一致。 这个想法是,设计上完全相同的两个(或多个)设备实际上将具有不同的电性能参数。电性能参数的差异是无法预测的,无法通过光学或SEM观察来估计。 图3 PUF晶体管对的原理图和布局图在上面的示意图中,尽管两个晶体管A和B在设计上是相同的,但在实践中它们始终具有略微不同的物理特征, 如作为阈值电压(VT),漏源电流(IDS)或漏源电阻(RDSON)等参数是不同的。 设计人员可以选择不同的参数来构建其PUF。 为了为了在本文中保持通用,我们将使用 PA和 PB来表示不同的参数,需要注意的是它可以是任何晶体管参数或它们的组合。由于晶体管A和B在设计上是相同的,因此无论是通过仿真还是逆向工程都不可能预测每个结构的PA>PB还是PA<PB。 如果我们武断的认为PA> PB生成“ 0”而PA <PB生成“ 1”,则无法猜测该对晶体管在被探测时生成的是“ 0”还是“ 1”。通过将该结构重复N次,我们可以生成N位不可预测的数据流。其实我们刚刚已经设计了一个物理不可克隆函数。 图4多个实例晶体管对创建的不可预测的比特流 PUF挑战如图所示,实现一系列多个晶体管实例(instance)或任何其他器件并不是什么大事。因此基于此原理构建PUF似乎非常容易。但其实并不是!如介绍中所述,PUF是基于硅制造中的微小变化。在我们的例子中,这些微小的变化转换成PA > PB或PA < PB。 但是由于制造偏差很小,因此△P=PA-PB之差也是如此。由于△P小,因此必须进行高精度测量。 如果测量不准的话,“ 0”很容易翻转为“ 1”(反之亦然),那么PUF不能用于生成密钥。因此,测量精度是一个重大挑战。更糟糕的是,△P通常对老化、温度、工艺和电源变化很敏感。△P本质上很小而且是随机分布的,因此最低的△P的单元在不同温度下使用时会有发生翻转的趋势。我们可以将这些单元视为“弱”,而将具有较高△P的单元视为“强”,后者对变化的敏感性较小。像在存储器设计中那样,添加额外的或冗余单元是将弱单元替换为强单元的一种有效途径。 图5 弱单元强单元的特性 虽然实现PUF元素相对简单,但要获得上述参数的稳定性是一个真正的挑战。有几种技术可以建立稳定的PUF:l 选择合适的参数(VT、IDS、RDSON)以便容易地进行高精度测量;l 冗余:设计更多的PUF元件来消除“弱”实例。 同样这里需要仔细的估计弱单元的数量。 没有足够的冗余单元会导致良率问题,而增加太多的冗余单元会使PUF的硅面积过大。这两个问题都会增加实际的芯片成本。l 纠错:假设不稳定单元的百分比足够低,实施适当的纠错机制(例如汉明编码)将会“修复”密钥。但局限性在于你需要对潜在的有缺陷的PUF单元进行相当有力的估算。除了测量精度之外,使PUF方案具有价值的实际上是纠错或冗余方案的效率成本。和其他密钥生成过程一样,可靠性是必不可少的,PUF的不可预测性和唯一性也是人们所期望的。不可预测性意味着在给定的芯片上,即使知道PUF对一系列挑战的响应,也无法猜测对下一个挑战的响应。唯一性是给定的PUF设计能够针对每个芯片和相同的挑战生成唯一的响应能力[3]。INVIA PUF:灵活、可靠、安全的解决方案架构我们的PUF基于晶体管失配,并且包括关键的多样化特性。一个实例可提供128个安全位,并且可由经过验证的多样化工艺而生成多个密钥。 图6 INVIA PUF架构 老化韧性让我们看看已知的老化现象如何影响INVIA PUF技术和其他PUF技术 老化现象 描述 对 INVIA PUF的影响 对其他技术的影响热载流子注入(HCI) NMOS晶体管的栅极电介质中捕获的载流子会产生Vt和gm漂移 在125°C下放置10年,PUF晶体管的Vt和gm变化小于1% 中等影响-晶体管在低Vds下工作显著影响-晶体管在高Vds下工作介质层时变击穿(TDDB) 氧化层击穿是由电子隧穿电流引起的 影响非常有限,因为我们的PUF单元的最大工作电压为〜0.5 Vdd 显著影响-MOSFET晶体管的工作电压接近最大规定的工作电压有限影响-正常电压负偏压温度不稳定性(NBTI) 由于正电荷在栅极下方的氧化物半导体边界处捕获,Vt和gm发生偏移。当Vg <Vs时会发生这种现象,这在导通的PMOS晶体管中很普遍 没有影响:-我们的技术仅基于NMOS晶体管-PUF晶体管在Vg> Vs下工作 基于SRAM的PUF技术对NBTI敏感,因为它们使用Vg<Vs的PMOS晶体管上表显示,我们的PUF具有与生俱来的抗老化特性。为了获得更高的可靠性而增加了冗余。如前所述,我们实现了比所需数量更多的单元来消除了弱单元。我们为PUF建立的模型使我们能够设置正确的区分阈值,以消除不可靠的PUF元素。实验已验证了模型的正确性并进行了高温工作寿命试验(HTOL)。模拟结构允许在老化后进行参数漂移测量,这比Go/No-go测试提供了更高的置信度。此外,PUF晶体管只有在被有效感知且在极短的时间内才通电。与持续供电的存储阵列PUF结构相比这自然减少了应力等级。熵除了消除弱单元之外,还建立辅助数据来增强针对外部参数变化和老化的鲁棒性。这可能导致熵损失。INVIA PUF在17亿比特位上显示出一个极好的熵>0.998建模INVIA设计的PUF IP不仅要耐高温、电压和工艺变化而且还能够对其建模,避免了任何形式的黑魔法。因为PUF本质上依赖于非常随机的现象,所以人们可能会通过实验和特性描述来实现PUF单元并凭经验判断其是否工作,然后发布相关IP产品。这可能有用但不能提供最高层次的信任。拥有PUF模型具有以下明显的优势:l方案具有可信性。确保密钥的构建具有足够的熵和健壮性是非常基本的要求。l结果可预测性。将方案移植到其他工艺节点变得更加容易。lIP可以通过认证 结论使用具有可靠性、不可预测性和唯一性保证的PUF IP,即使对于不是安全专家的设计人员,也可以为ASIC或SoC提供最高级别的安全性。 参考文献References[1] e. a. S. Quadir, 《A survey on chip to system reverse engineering》 ACM Journalon Emerging Technologies in Computing Systems, April 2016.[2] D. F. M. M. T. Q. S. Huanyu Wang, 《Probing Attacks on Integrated Circuits:Challenges and Research Opportunities》, IEEE Design & Test , October 2017.[3] M. Bhargava, 《Reliable, Secure, Efficient Physical Unclonable Functions. Thesis》,01 May 2013. [En ligne]. Available: https://doi.org/10.1184/R1/6721310.v1.
-
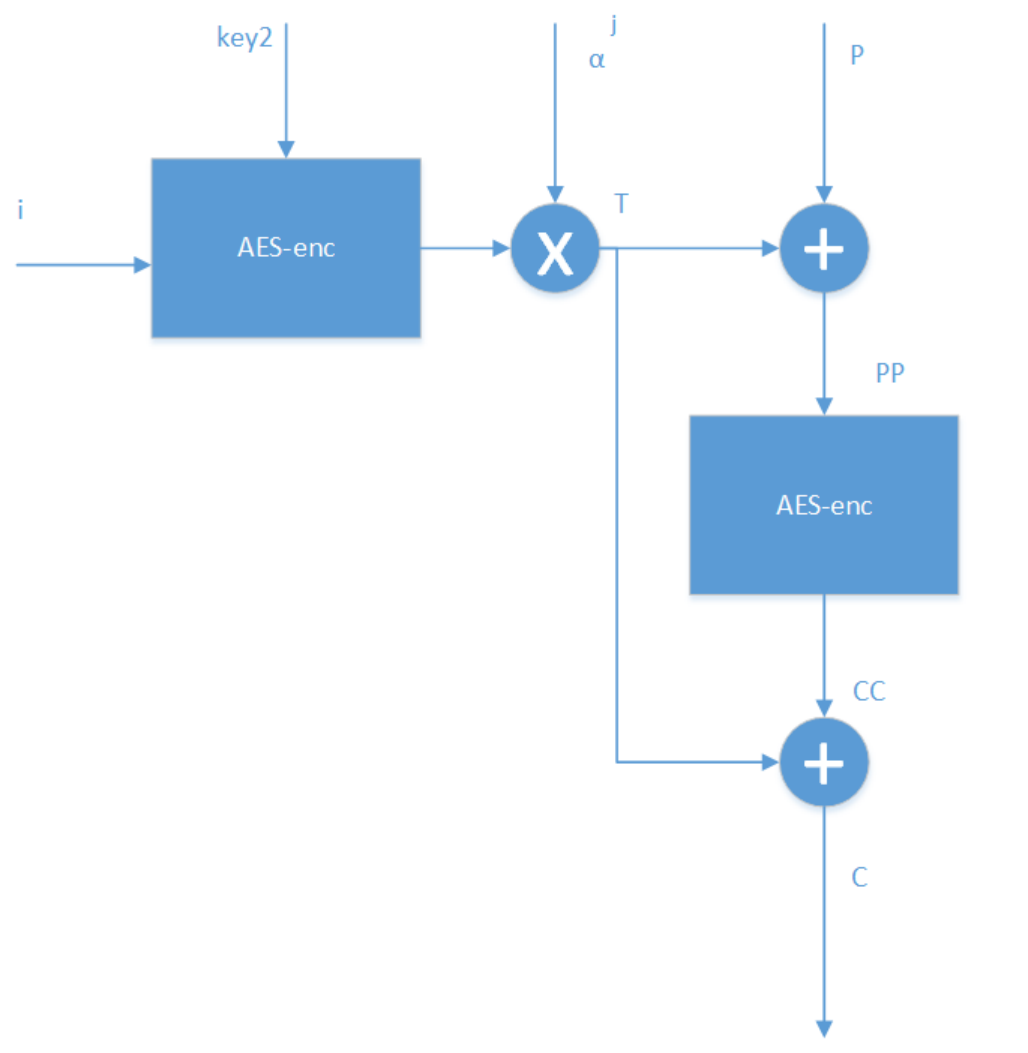
XTS-AES模式主要是解决什么问题,是怎样解决的? XTS-AES模式主要是解决什么问题,是怎样解决的?作者:蒋伟伟链接:https://www.zhihu.com/question/26452995/answer/142440391来源:知乎著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。XTS即基于XEX(XOR-ENCRYPT-XOR)的密文窃取算法的可调整的密码本模式(Tweakable Codebook mode),该算法主要用于以数据单元(包括扇区、逻辑磁盘块等)为基础结构的存储设备中静止状态数据的加密。以上是官方的解释,谈一下我的理解。我们都知道磁盘上的数据是有一定格式的,比如一个扇区是512字节,磁盘加密直接要对写入扇区的明文进行加密,记录在磁盘扇区上的是相应的密文。而我们通过传统的AES加密方法,比如CBC加密模式,密文须包含一个128bit的初始向量。那么问题来了,我们岂不是要腾出额外的128个bit专门存储初始向量?这样做是增加了磁盘的开销,而且明文和密文在扇区上的存储也不是一一对应的,这给磁盘底层的加密实现带来很大的麻烦。更为关键的是,传统的加密算法,更改密匙非常不便,一旦更改,就意味着要重新进行密匙扩展算法,对磁盘来说要增加很大的开销,同时还要担心密匙泄露的问题。在这种情况下,针对磁盘加密的特点,2002年,Moses Liskov,Ronald L.Rivest, David Wagner,首次提出了可调整的分组密码这个概念,跟传统的分组密码相比,除了密匙和明文这两个输入外,还引入另外一个输入---tweak,即可调整值。这样做的好处是,在不更改密匙的情况下,仅仅改变tweak值,就可以给加密系统提供多变性,既减少了磁盘的开销,也不怕密匙泄露,因为tweak值是公开的,就算泄露了tweak值,如果不知道密匙,是无法破解系统的。而且,这种算法,不需要初始向量,也就避免我们上面所述的明文和密文在扇区上的存储不对应的问题。XTS-AES算法是基于以上思想,被IEEE采用的一个标准。简单介绍下其原理,以传输单个128bit数据块为例:i为128-bit调整值,j为128-bit数据块在数据单元中的位置值,C为128-bit密文数据块。AES-enc为标准AES算法,key2为调整值密匙,key1为数据密匙,模乘操作中 α为GF(2^128)域中对应于多项式x的本源。计算的步骤顺序如下:T <---- AES-enc(key2,i) ⓧ (α^j );PP <----P⊕Thttp://3.CC<---AES-enc(Key1,PP)C<--CC⊕T需要指出的是,j代表数据块在数据单元里的index,比如256个bit数据块,那么 0bit-127bit的j=1,128bit-256bit 的j=2。j 的引入,是让各个数据块的加密保持独立。Disk encryption theoryFrom Wikipedia, the free encyclopediaJump to navigationJump to searchDisk encryption is a special case of data at rest protection when the storage medium is a sector-addressable device (e.g., a hard disk). This article presents cryptographic aspects of the problem. For an overview, see disk encryption. For discussion of different software packages and hardware devices devoted to this problem, see disk encryption software and disk encryption hardware.Contents1Problem definition2Block cipher-based modes2.1Cipher-block chaining (CBC)2.1.1Encrypted salt-sector initialization vector (ESSIV)2.1.2Malleability attack2.2Liskov, Rivest, and Wagner (LRW)2.3Xor–encrypt–xor (XEX)2.3.1XEX-based tweaked-codebook mode with ciphertext stealing (XTS)2.3.2XTS weaknesses2.4CBC–mask–CBC (CMC) and ECB–mask–ECB (EME)3Patents4See also5References6Further reading7External linksProblem definition[edit]Disk encryption methods aim to provide three distinct properties:1.The data on the disk should remain confidential.2.Data retrieval and storage should both be fast operations, no matter where on the disk the data is stored.3.The encryption method should not waste disk space (i.e., the amount of storage used for encrypted data should not be significantly larger than the size of plaintext).The first property requires defining an adversary from whom the data is being kept confidential. The strongest adversaries studied in the field of disk encryption have these abilities:1.they can read the raw contents of the disk at any time;2.they can request the disk to encrypt and store arbitrary files of their choosing;3.and they can modify unused sectors on the disk and then request their decryption.A method provides good confidentiality if the only information such an adversary can determine over time is whether the data in a sector has or has not changed since the last time they looked.The second property requires dividing the disk into several sectors, usually 512 bytes (4096 bits) long, which are encrypted and decrypted independently of each other. In turn, if the data is to stay confidential, the encryption method must be tweakable; no two sectors should be processed in exactly the same way. Otherwise, the adversary could decrypt any sector of the disk by copying it to an unused sector of the disk and requesting its decryption.The third property is generally non-controversial. However, it indirectly prohibits the use of stream ciphers, since stream ciphers require, for their security, that the same initial state not be used twice (which would be the case if a sector is updated with different data); thus this would require an encryption method to store separate initial states for every sector on disk—seemingly a waste of space. The alternative, a block cipher, is limited to a certain block size (usually 128 or 256 bits). Because of this, disk encryption chiefly studies chaining modes, which expand the encryption block length to cover a whole disk sector. The considerations already listed make several well-known chaining modes unsuitable: ECB mode, which cannot be tweaked, and modes that turn block ciphers into stream ciphers, such as the CTR mode.These three properties do not provide any assurance of disk integrity; that is, they don't tell you whether an adversary has been modifying your ciphertext. In part, this is because an absolute assurance of disk integrity is impossible: no matter what, an adversary could always revert the entire disk to a prior state, circumventing any such checks. If some non-absolute level of disk integrity is desired, it can be achieved within the encrypted disk on a file-by-file basis using message authentication codes.Block cipher-based modes[edit]Like most encryption schemes, block cipher-based disk encryption makes use of modes of operation, which allow encrypting larger amounts of data than the ciphers' block-size (typically 128 bits). Modes are therefore rules on how to repeatedly apply the ciphers' single-block operations.Cipher-block chaining (CBC)[edit]Main article: Cipher-block chainingCipher-block chaining (CBC) is a common chaining mode in which the previous block's ciphertext is xored with the current block's plaintext before encryption:Since there isn't a "previous block's ciphertext" for the first block, an initialization vector (IV) must be used as . This, in turn, makes CBC tweakable in some ways.CBC suffers from some problems. For example, if the IVs are predictable, then an adversary may leave a "watermark" on the disk, i.e., store a specially created file or combination of files identifiable even after encryption. The exact method of constructing the watermark depends on the exact function providing the IVs, but the general recipe is to create two encrypted sectors with identical first blocks and ; these two are then related to each other by . Thus the encryption of is identical to the encryption of , leaving a watermark on the disk. The exact pattern of "same-different-same-different" on disk can then be altered to make the watermark unique to a given file.To protect against the watermarking attack, a cipher or a hash function is used to generate the IVs from the key and the current sector number, so that an adversary cannot predict the IVs. In particular, the ESSIV approach uses a block cipher in CTR mode to generate the IVs.Encrypted salt-sector initialization vector (ESSIV)[edit]ESSIV[1] is a method for generating initialization vectors for block encryption to use in disk encryption. The usual methods for generating IVs are predictable sequences of numbers based on, for example, time stamp or sector number, and prevents certain attacks such as a watermarking attack. ESSIV prevents such attacks by generating IVs from a combination of the sector number SN with the hash of the key. It is the combination with the key in form of a hash that makes the IV unpredictable.ESSIV was designed by Clemens Fruhwirth and has been integrated into the Linux kernel since version 2.6.10, though a similar scheme has been used to generate IVs for OpenBSD's swap encryption since 2000.[2]ESSIV is supported as an option by the dm-crypt[3] and FreeOTFE disk encryption systems.Malleability attack[edit]While CBC (with or without ESSIV) ensures confidentiality, it does not ensure integrity of the encrypted data. If the plaintext is known to the adversary, it is possible to change every second plaintext block to a value chosen by the attacker, while the blocks in between are changed to random values. This can be used for practical attacks on disk encryption in CBC or CBC-ESSIV mode.[4]Liskov, Rivest, and Wagner (LRW)[edit]In order to prevent such elaborate attacks, different modes of operation were introduced: tweakable narrow-block encryption (LRW and XEX) and wide-block encryption (CMC and EME).Whereas a purpose of a usual block cipher is to mimic a random permutation for any secret key , the purpose of tweakable encryption is to mimic a random permutation for any secret key and any known tweak . The tweakable narrow-block encryption (LRW)[5] is an instantiation of the mode of operations introduced by Liskov, Rivest, and Wagner[6] (see Theorem 2). This mode uses two keys: is the key for the block cipher and is an additional key of the same size as block. For example, for AES with a 256-bit key, is a 256-bit number and is a 128-bit number. Encrypting block with logical index (tweak) uses the following formula:Here multiplication and addition are performed in the finite field ( for AES). With some precomputation, only a single multiplication per sector is required (note that addition in a binary finite field is a simple bitwise addition, also known as xor): , where are precomputed for all possible values of . This mode of operation needs only a single encryption per block and protects against all the above attacks except a minor leak: if the user changes a single plaintext block in a sector then only a single ciphertext block changes. (Note that this is not the same leak the ECB mode has: with LRW mode equal plaintexts in different positions are encrypted to different ciphertexts.)Some security concerns exist with LRW, and this mode of operation has now been replaced by XTS.LRW is employed by BestCrypt and supported as an option for dm-crypt and FreeOTFE disk encryption systems.Xor–encrypt–xor (XEX)[edit]Main article: Xor–encrypt–xorAnother tweakable encryption mode, XEX (xor–encrypt–xor), was designed by Rogaway[7] to allow efficient processing of consecutive blocks (with respect to the cipher used) within one data unit (e.g., a disk sector). The tweak is represented as a combination of the sector address and index of the block within the sector (the original XEX mode proposed by Rogaway[7] allows several indices). The ciphertext, , is obtained using:where: is the plaintext, is the number of the sector, is the primitive element of defined by polynomial ; i.e., the number 2, is the number of the block within the sector.The basic operations of the LRW mode (AES cipher and Galois field multiplication) are the same as the ones used in the Galois/Counter Mode (GCM), thus permitting a compact implementation of the universal LRW/XEX/GCM hardware.XEX has a weakness.[8]XEX-based tweaked-codebook mode with ciphertext stealing (XTS)[edit]Ciphertext stealing provides support for sectors with size not divisible by block size, for example, 520-byte sectors and 16-byte blocks. XTS-AES was standardized on 2007-12-19[9] as IEEE P1619.[10] The standard supports using a different key for the IV encryption than for the block encryption; this is contrary to the intent of XEX and seems to be rooted in a misinterpretation of the original XEX paper, but does not harm security.11 As a result, users wanting AES-256 and AES-128 encryption must supply 512 bits and 256 bits of key respectively.On January 27, 2010, NIST released Special Publication (SP) 800-38E[12] in final form. SP 800-38E is a recommendation for the XTS-AES mode of operation, as standardized by IEEE Std 1619-2007, for cryptographic modules. The publication approves the XTS-AES mode of the AES algorithm by reference to the IEEE Std 1619-2007, subject to one additional requirement, which limits the maximum size of each encrypted data unit (typically a sector or disk block) to 220 AES blocks. According to SP 800-38E, "In the absence of authentication or access control, XTS-AES provides more protection than the other approved confidentiality-only modes against unauthorized manipulation of the encrypted data."XTS is supported by BestCrypt, Botan, NetBSD's cgd,[13] dm-crypt, FreeOTFE, TrueCrypt, VeraCrypt,[14] DiskCryptor, FreeBSD's geli, OpenBSD softraid disk encryption software, OpenSSL, Mac OS X Lion's FileVault 2, Windows 10's BitLocker[15] and wolfCrypt.XTS weaknesses[edit]XTS mode is susceptible to data manipulation and tampering, and applications must employ measures to detect modifications of data if manipulation and tampering is a concern: "...since there are no authentication tags then any ciphertext (original or modified by attacker) will be decrypted as some plaintext and there is no built-in mechanism to detect alterations. The best that can be done is to ensure that any alteration of the ciphertext will completely randomize the plaintext, and rely on the application that uses this transform to include sufficient redundancy in its plaintext to detect and discard such random plaintexts." This would require maintaining checksums for all data and metadata on disk, as done in ZFS or Btrfs. However, in commonly used file systems such as ext4 and NTFS only metadata is protected against tampering, while the detection of data tampering is non-existent.[16]The mode is susceptible to traffic analysis, replay and randomization attacks on sectors and 16-byte blocks. As a given sector is rewritten, attackers can collect fine-grained (16 byte) ciphertexts, which can be used for analysis or replay attacks (at a 16-byte granularity). It would be possible to define sector-wide block ciphers, unfortunately with degraded performance (see below).[17]CBC–mask–CBC (CMC) and ECB–mask–ECB (EME)[edit]CMC and EME protect even against the minor leak mentioned above for LRW. Unfortunately, the price is a twofold degradation of performance: each block must be encrypted twice; many consider this to be too high a cost, since the same leak on a sector level is unavoidable anyway.CMC, introduced by Halevi and Rogaway, stands for CBC–mask–CBC: the whole sector encrypted in CBC mode (with ), the ciphertext is masked by xoring with , and re-encrypted in CBC mode starting from the last block. When the underlying block cipher is a strong pseudorandom permutation (PRP) then on the sector level the scheme is a tweakable PRP. One problem is that in order to decrypt one must sequentially pass over all the data twice.In order to solve this problem, Halevi and Rogaway introduced a parallelizable variant called EME (ECB–mask–ECB). It works in the following way:the plaintexts are xored with , shifted by different amount to the left, and are encrypted: ;the mask is calculated: , where and ;intermediate ciphertexts are masked: for and ;the final ciphertexts are calculated: for .Note that unlike LRW and CMC there is only a single key .CMC and EME were considered for standardization by SISWG. EME is patented, and so is not favored to be a primary supported mode.[18]Patents[edit]While the authenticated encryption scheme IAPM provides encryption as well as an authentication tag, the encryption component of the IAPM mode completely describes the LRW and XEX schemes above, and hence XTS without the ciphertext stealing aspect. This is described in detail in Figures 8 and 5 of the US patent 6,963,976.[19]See also[edit]Data remanenceCold boot attackDisk encryption softwareDisk encryption hardwareIEEE P1619, standardization project for encryption of the storage dataReferences[edit]1.^ Clemens Fruhwirth (July 18, 2005). "New Methods in Hard Disk Encryption" (PDF). Institute for Computer Languages: Theory and Logic Group (PDF). Vienna University of Technology.2.^ "Encrypting Virtual Memory" (Postscript).3.^ Milan Broz. "DMCrypt dm-crypt: Linux kernel device-mapper crypto target". gitlab.com. Retrieved April 5, 2015.4.^ Jakob Lell (2013-12-22). "Practical malleability attack against CBC-encrypted LUKS partitions".5.^ Latest SISWG and IEEE P1619 drafts and meeting information are on the P1619 home page [1].6.^ M. Liskov, R. Rivest, and D. Wagner. Tweakable block ciphers [2], CRYPTO '02 (LNCS, volume 2442), 2002.7.^ Jump up to:a b c Rogaway, Phillip (2004-09-24). "Efficient Instantiations of Tweakable Blockciphers and Refinements to Modes OCB and PMAC" (PDF). Dept. Of Computer Science(PDF). University of California, Davis.8.^ https://link.springer.com/content/pdf/10.1007/978-3-540-74462-7_8.pdf section 4.1.9.^ Karen McCabe (19 December 2007). "IEEE Approves Standards for Data Encryption". IEEE Standards Association. Archived from the original on 2008-03-06.10.^ Standard for Cryptographic Protection of Data on Block-Oriented Storage Devices. IEEE Xplore Digital Library. April 18, 2008. doi:10.1109/IEEESTD.2008.4493450. ISBN 978-0-7381-5363-6.11.^ Liskov, Moses; Minematsu, Kazuhiko (2008-09-02). "Comments on XTS-AES" (PDF)., On the Use of Two Keys, pp. 1–3.12.^ Morris Dworkin (January 2010). "Recommendation for Block Cipher Modes of Operation: The XTS-AES Mode for Confidentiality on Storage Devices" (PDF). NIST Special Publication 800-38E. National Institute of Standards and Technology.13.^ "NetBSD cryptographic disk driver".14.^ "Modes of Operation". VeraCrypt Documentation. IDRIX. Retrieved 2017-10-13.15.^ "What's new in BitLocker?". November 12, 2015. Retrieved 2015-11-15.16.^ Standard for Cryptographic Protection of Data on Block-Oriented Storage Devices (PDF), IEEE P1619/D16, 2007, p. 34, archived from the original (PDF) on 14 April 2016, retrieved 14 September 201217.^ Thomas Ptacek; Erin Ptacek (2014-04-30). "You Don't Want XTS".18.^ P. Rogaway, Block cipher mode of operation for constructing a wide-blocksize block cipher from a conventional block cipher, US Patent Application 20040131182 A1.19.^ * U.S. Patent 6,963,976, "Symmetric Key Authenticated Encryption Schemes" (filed Nov. 2000, issued Nov. 2005, expires 25 Nov. 2022) 3.Further reading[edit]S. Halevi and P. Rogaway, A Tweakable Enciphering Mode, CRYPTO '03 (LNCS, volume 2729), 2003.S. Halevi and P. Rogaway, A Parallelizable Enciphering Mode [5], 2003.Standard Architecture for Encrypted Shared Storage Media, IEEE Project 1619 (P1619), [6].SISWG, Draft Proposal for Key Backup Format [7], 2004.SISWG, Draft Proposal for Tweakable Wide-block Encryption [8], 2004.James Hughes, Encrypted Storage — Challenges and Methods [9]J. Alex Halderman, Seth D. Schoen, Nadia Heninger, William Clarkson, William Paul, Joseph A. Calandrino, Ariel J. Feldman, Jacob Appelbaum, and Edward W. Felten (2008-02-21). "Lest We Remember: Cold Boot Attacks on Encryption Keys" (PDF). Princeton University. Archived from the original (PDF) on 2008-05-14.Niels Fergusson (August 2006). "AES-CBC + Elephant Diffuser: A Disk Encryption Algorithm for Windows Vista" (PDF). Microsoft.External links[edit]Security in Storage Working Group SISWG."The eSTREAM project". Retrieved 2010-03-28.
-
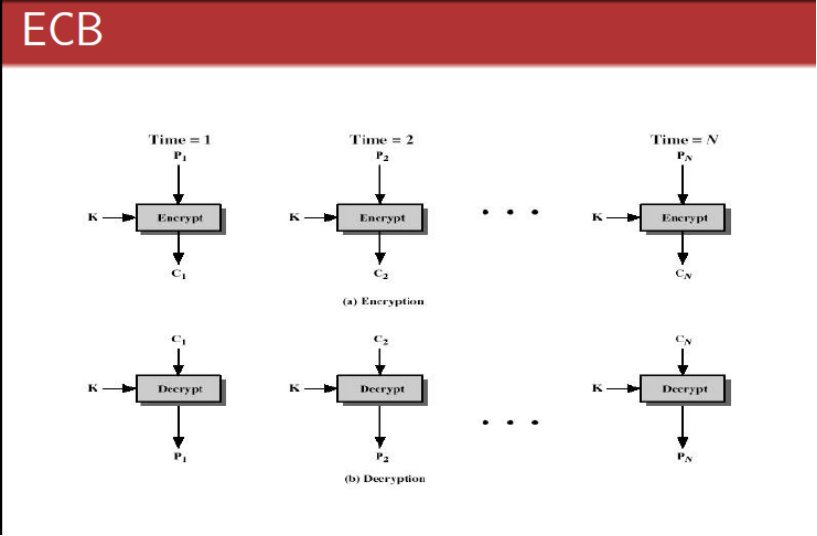
五种加解密模式(CBC、ECB、CTR、OCF、CFB) 分组密码有五种工作体制:1.电码本模式(Electronic Codebook Book (ECB));2.密码分组链接模式(Cipher Block Chaining (CBC));3.计算器模式(Counter (CTR));4.密码反馈模式(Cipher FeedBack (CFB));5.输出反馈模式(Output FeedBack (OFB))。以下逐一介绍一下:1.电码本模式(Electronic Codebook Book (ECB) 这种模式是将整个明文分成若干段相同的小段,然后对每一小段进行加密。 2.密码分组链接模式(Cipher Block Chaining (CBC)) 这种模式是先将明文切分成若干小段,然后每一小段与初始块或者上一段的密文段进行异或运算后,再与密钥进行加密。 3.计算器模式(Counter (CTR)) 计算器模式不常见,在CTR模式中, 有一个自增的算子,这个算子用密钥加密之后的输出和明文异或的结果得到密文,相当于一次一密。这种加密方式简单快速,安全可靠,而且可以并行加密,但是在计算器不能维持很长的情况下,密钥只能使用一次。CTR的示意图如下所示: 4.密码反馈模式(Cipher FeedBack (CFB)) 这种模式较复杂。 5.输出反馈模式(Output FeedBack (OFB)) 这种模式较复杂。 以下附上C++源代码:/** *@autho stardust *@time 2013-10-10 *@param 实现AES五种加密模式的测试*/ #include <iostream>using namespace std; //加密编码过程函数,16位1和0int dataLen = 16; //需要加密数据的长度int encLen = 4; //加密分段的长度int encTable[4] = {1,0,1,0}; //置换表int data[16] = {1,0,0,1,0,0,0,1,1,1,1,1,0,0,0,0}; //明文int ciphertext[16]; //密文 //切片加密函数void encode(int arr[]) { for(int i=0;i<encLen;i++) { arr[i] = arr[i] ^ encTable[i]; } } //电码本模式加密,4位分段void ECB(int arr[]) { //数据明文切片 int a[4][4]; int dataCount = 0; //位置变量 for(int k=0;k<4;k++) { for(int t=0;t<4;t++) { a[k][t] = data[dataCount]; dataCount++; } } dataCount = 0;//重置位置变量 for(int i=0;i<dataLen;i=i+encLen) { int r = i/encLen;//行 int l = 0;//列 int encQue[4]; //编码片段 for(int j=0;j<encLen;j++) { encQue[j] = a[r][l]; l++; } encode(encQue); //切片加密 //添加到密文表中 for(int p=0;p<encLen;p++) { ciphertext[dataCount] = encQue[p]; dataCount++; } } cout<<"ECB加密的密文为:"<<endl; for(int t1=0;t1<dataLen;t1++) //输出密文 { if(t1!=0 && t1%4==0) cout<<endl; cout<<ciphertext[t1]<<" "; } cout<<endl; cout<<"---------------------------------------------"<<endl; } //CBC//密码分组链接模式,4位分段void CCB(int arr[]) { //数据明文切片 int a[4][4]; int dataCount = 0; //位置变量 for(int k=0;k<4;k++) { for(int t=0;t<4;t++) { a[k][t] = data[dataCount]; dataCount++; } } dataCount = 0;//重置位置变量 int init[4] = {1,1,0,0}; //初始异或运算输入 //初始异或运算 for(int i=0;i<dataLen;i=i+encLen) { int r = i/encLen;//行 int l = 0;//列 int encQue[4]; //编码片段 //初始化异或运算 for(int k=0;k<encLen;k++) { a[r][k] = a[r][k] ^ init[k]; } //与Key加密的单切片 for(int j=0;j<encLen;j++) { encQue[j] = a[r][j]; } encode(encQue); //切片加密 //添加到密文表中 for(int p=0;p<encLen;p++) { ciphertext[dataCount] = encQue[p]; dataCount++; } //变换初始输入 for(int t=0;t<encLen;t++) { init[t] = encQue[t]; } } cout<<"CCB加密的密文为:"<<endl; for(int t1=0;t1<dataLen;t1++) //输出密文 { if(t1!=0 && t1%4==0) cout<<endl; cout<<ciphertext[t1]<<" "; } cout<<endl; cout<<"---------------------------------------------"<<endl; } //CTR//计算器模式,4位分段void CTR(int arr[]) { //数据明文切片 int a[4][4]; int dataCount = 0; //位置变量 for(int k=0;k<4;k++) { for(int t=0;t<4;t++) { a[k][t] = data[dataCount]; dataCount++; } } dataCount = 0;//重置位置变量 int init[4][4] = {{1,0,0,0},{0,0,0,1},{0,0,1,0},{0,1,0,0}}; //算子表 int l = 0; //明文切片表列 //初始异或运算 for(int i=0;i<dataLen;i=i+encLen) { int r = i/encLen;//行 int encQue[4]; //编码片段 //将算子切片 for(int t=0;t<encLen;t++) { encQue[t] = init[r][t]; } encode(encQue); //算子与key加密 //最后的异或运算 for(int k=0;k<encLen;k++) { encQue[k] = encQue[k] ^ a[l][k]; } l++; //添加到密文表中 for(int p=0;p<encLen;p++) { ciphertext[dataCount] = encQue[p]; dataCount++; } } cout<<"CTR加密的密文为:"<<endl; for(int t1=0;t1<dataLen;t1++) //输出密文 { if(t1!=0 && t1%4==0) cout<<endl; cout<<ciphertext[t1]<<" "; } cout<<endl; cout<<"---------------------------------------------"<<endl; } //CFB//密码反馈模式,4位分段void CFB(int arr[]) { //数据明文切片,切成2 * 8 片 int a[8][2]; int dataCount = 0; //位置变量 for(int k=0;k<8;k++) { for(int t=0;t<2;t++) { a[k][t] = data[dataCount]; dataCount++; } } dataCount = 0; //恢复初始化设置 int lv[4] = {1,0,1,1}; //初始设置的位移变量 int encQue[2]; //K的高两位 int k[4]; //K for(int i=0;i<2 * encLen;i++) //外层加密循环 { //产生K for(int vk=0;vk<encLen;vk++) { k[vk] = lv[vk]; } encode(k); for(int k2=0;k2<2;k2++) { encQue[k2] = k[k2]; } //K与数据明文异或产生密文 for(int j=0;j<2;j++) { ciphertext[dataCount] = a[dataCount/2][j] ^ encQue[j]; dataCount++; } //lv左移变换 lv[0] = lv[2]; lv[1] = lv[3]; lv[2] = ciphertext[dataCount-2]; lv[3] = ciphertext[dataCount-1]; } cout<<"CFB加密的密文为:"<<endl; for(int t1=0;t1<dataLen;t1++) //输出密文 { if(t1!=0 && t1%4==0) cout<<endl; cout<<ciphertext[t1]<<" "; } cout<<endl; cout<<"---------------------------------------------"<<endl; } //OFB//输出反馈模式,4位分段void OFB(int arr[]) { //数据明文切片,切成2 * 8 片 int a[8][2]; int dataCount = 0; //位置变量 for(int k=0;k<8;k++) { for(int t=0;t<2;t++) { a[k][t] = data[dataCount]; dataCount++; } } dataCount = 0; //恢复初始化设置 int lv[4] = {1,0,1,1}; //初始设置的位移变量 int encQue[2]; //K的高两位 int k[4]; //K for(int i=0;i<2 * encLen;i++) //外层加密循环 { //产生K for(int vk=0;vk<encLen;vk++) { k[vk] = lv[vk]; } encode(k); for(int k2=0;k2<2;k2++) { encQue[k2] = k[k2]; } //K与数据明文异或产生密文 for(int j=0;j<2;j++) { ciphertext[dataCount] = a[dataCount/2][j] ^ encQue[j]; dataCount++; } //lv左移变换 lv[0] = lv[2]; lv[1] = lv[3]; lv[2] = encQue[0]; lv[3] = encQue[1]; } cout<<"CFB加密的密文为:"<<endl; for(int t1=0;t1<dataLen;t1++) //输出密文 { if(t1!=0 && t1%4==0) cout<<endl; cout<<ciphertext[t1]<<" "; } cout<<endl; cout<<"---------------------------------------------"<<endl; } void printData() { cout<<"以下示范AES五种加密模式的测试结果:"<<endl; cout<<"---------------------------------------------"<<endl; cout<<"明文为:"<<endl; for(int t1=0;t1<dataLen;t1++) //输出密文 { if(t1!=0 && t1%4==0) cout<<endl; cout<<data[t1]<<" "; } cout<<endl; cout<<"---------------------------------------------"<<endl; }int main() { printData(); ECB(data); CCB(data); CTR(data); CFB(data); OFB(data); return 0; }
-
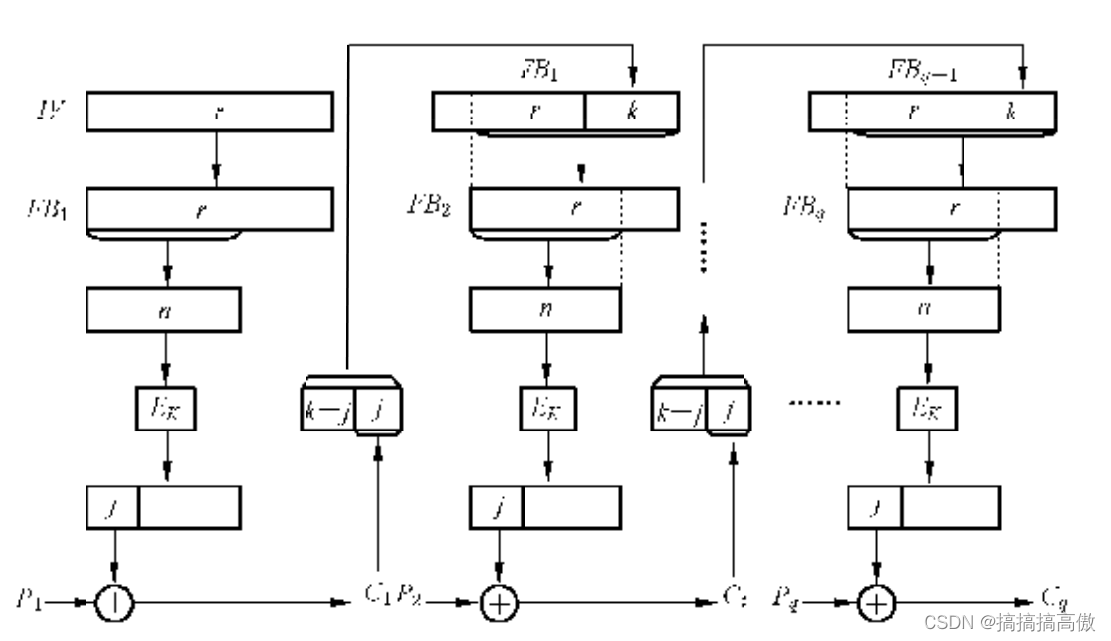
分组密码算法的工作模式——KeyWrap密钥封装模式 密钥封装是为了对密钥进行保护,比如密钥存储在不太安全的存储设备中,或者密钥需要在网络中传输。早在2001年,NIST就发布了AES Key Wrap Specification。2002年,IETF在RFC 3394中也描述了密钥封装算法AES-KeyWrap Algorithm,电信行业协会发布了使用TDES的密钥封装算法。2008年,美国标准认可委员会(Accredited Standards Committee X9, Inc.)发布了金融服务业的密钥封装算法。2009年,RFC 5649 描述了带填充的密钥封装算法。 2012年,NIST SP 800-38F描述了AES KW、AES KWP(带填充的密钥封装算法)和TDES的TKW。NIST的这三个算法和RFC等的描述几乎完全一致。 以下描述以NIST SP 800-38F为主,结合RFC 3394和RFC 5649。 参考文献Key Wrap - Wikipedia, the free encyclopedia, http://en.wikipedia.org/wiki/Key_WrapNIST Special Publication 800-38F: Recommendation for Block Cipher Modes of Operation Methods for Key Wrapping, December 2012.J. Schaad and R. Housley, Advanced Encryption Standard (AES) Key Wrap Algorithm, RFC 3394, September, 2002.R. Housley and M. Dworkin, Advanced Encryption Standard (AES) Key Wrap with Padding Algorithm, RFC 5649, August, 2009.ANSI/TIA-102.AACA-1-2002: Project 25 – Digital Radio Over-the-Air-Rekeying (OTAR) Protocol: Addendum 1 – Key Management Security Requirements for Type 3 Block Encryption Algorithms, Telecommunications Industry Association, November, 2002.ANS X9.102-2008, Symmetric Key Cryptography For the Financial Services Industry—Wrapping of Keys and Associated Data, Accredited Standards Committee X9, Inc., June, 2008. 密钥封装有三种KW 基于AES的密钥封装,不使用填充。KWP 基于AES的密钥封装,使用填充。TKW 基于TDES的密钥封装,不使用填充。 算法明文密文使用模块KW2—254-1个64bit长3—254个64bit长W和W-1KWP1—232-1个8bit长2—232个8bit长W和W-1TKW2—228-1个32bit长3—228个32bit长TW和TW-1WC = W(S)模块准备:K(即KEK)128-bit 分组密码CIPH.输入:S,长度为n×64bit,n ≥ 3.输出C,与S等长(长度为n×64bit,n ≥ 3)。步骤初始化s = 6(n-1).S=S1 || S2 ||… || Sn . Si都是64itA0 = S1.For i = 2, …, nR0i = Si.迭代For t = 1, …, s At = MSB64(CIPHK(At-1 || R2t-1)) ⊕ [t]64; For i = 2, …, n-1:Rit = Ri+1t-1; Rnt = LSB64(CIPHK (At-1 || R2t-1)).输出结果C1 = As.For i = 2, …, nCi = Ris.Return C1 || C2 || … || Cn. W的示意图如下W的示意图 W中迭代器的示意图如下:W中迭代器的示意图 W-1S = W-1(C)模块准备:K(即KEK)128-bit 分组密码CIPH的逆函数CIPH-1输入:C,长度为n×64bit,n ≥ 3.输出S,与c等长(长度为n×64bit,n ≥ 3)。步骤初始化s = 6(n-1).C = C1 || C2 ||… || Cn . Ci都是64bitAs = C1.For i = 2, …, nRsi = Ci.迭代For t = s, …, 1 At-1 = MSB64((CIPH-1K(At ⊕[t]64)) || Rnt);R2t-1 = LSB64(CIPH-1K ((At ⊕[t]64) || Rnt). For i = 2, …, n-1:Ri+1t-1 = Rit ; 输出结果S1 = A0.For i = 2, …, nSi = Ri0.Return S1 || S2 || … || Sn. KWKW的加密KW-AE(P)和解密KW-AD(C)。加密C = KW-AE(P)输入:明文P输出:密文CICV1 = 0xA6A6A6A6A6A6A6A6.S = ICV1 || P.Return C = W(S). 解密P = KW-AD(C)输入:密文C输出:明文P或者失败ICV1 = 0xA6A6A6A6A6A6A6A6.S = W-1(C).If MSB64(S) ≠ICV1, return FAIL and stop.Return P = LSB64(n-1)(S). RFC 3394对KW采用一种便于软件实现的描述方式。输入:明文 P = P1||P2||...||Pn,n个64-bit密钥 K (KEK).输出:密文 C = C0||C1||...||Cn,(n+1)个64-bit步骤1) A = IV, IV = 0xA6A6A6A6A6A6A6A6 For i = 1 to n, R[i] = P[i]2) For j = 0 to 5 { For i=1 to n { B = AES(K, A || R[i]) A = MSB(64, B) ⊕ t,其中t = (n*j)+i R[i] = LSB(64, B) }//i }//j3) C[0] = AFor i = 1 to n, C[i] = R[i]Return C = C[0] || C[1] || ... || C[n]KWP带填充的KW加密KWP-AE(P)和带填充的KW解密KWP-AD(C)。加密C = KWP-AE(P)输入:明文P输出:密文CICV2 = 0xA65959A6.2. PAD = 08×padlenS = ICV2 || [len(P)/8]32 || P || PAD5. If len(P) ≤ 64, return C = CIPHK(S);else, return C = W(S). 这里的padlen是指将明文P填充为64bit的整数倍时需要填充(填充数据为全零字节)的最短字节数,可以为0。消息S表示在填充后消息的前面再加64比特的特殊消息,以保证S长度最少为一个分组大小(128bit)。如果S长度只有一个分组大小,则直接执行AES。 解密P = KW-AD(C)输入:密文C,C = C1||C2||...||Cn, n个64-bit输出:明文P或者失败1. ICV2 = 0xA65959A6.If n = 2, S = CIPH-1K(C); if n > 2, S = W-1(C).If MSB32(S) ≠ ICV2, return FAIL and stop.4. Plen = int(LSB32(MSB64(S))).padlen = 8(n-1)-Plen.If padlen < 0 or padlen > 7, return FAIL and stop.If LSB8×padlen(S) ≠ 08×padlen, return FAIL and stop.Return P = MSB8×Plen(LSB64×(n-1)(S)).TKW这个和KW其实是一样的,只有一下几个地方有区别:使用的密码算法不一样:KW采用AES;TKW采用TDES分组大小不一样导致半分组大小不一样:KW半分组大小64bit;TKW半分组大小32bit。详细流程可辅助参见KW。注意:TKW没有加填充的所谓TKWP算法。测试数据NIST SP 800-38F里面没有测试数据;测试数据可以在RFC 3394和RFC 5649里面查。LibTomCrypt目前尚不支持KeyWrap。————————————————版权声明:本文为CSDN博主「网糸隹」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。原文链接:https://blog.csdn.net/samsho2/article/details/85263837