搜索到
31
篇与
的结果
-
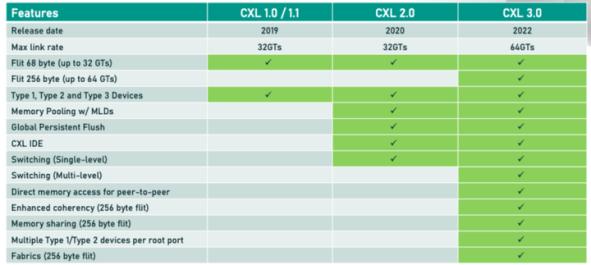
 什么是 CXL? 本文由半导体产业纵横(ID:ICVIEWS)编译自 spiceworksCXL(Compute Express Link)可以提高数据中心内存的性能、可扩展性和灵活性。MemVerge 的 Steve Scargall 解释了 CXL 是什么、它是如何工作的,以及为什么它是各种应用程序的游戏规则改变者,例如 AI/ML、HPC、数据库和分析。他还强调了采用 CXL 标准化的云计算和数据中心基础设施的一些行业趋势。CXL 是一种新兴的开放式行业标准互连,彻底改变了以数据为中心的计算。凭借其在 CPU 和设备(例如加速器、内存扩展和持久内存设备)之间的高带宽和低延迟缓存一致性连接,CXL 有可能重塑数据中心内存的性能、可扩展性和灵活性。通过解决 AI/ML 应用程序面临的常见内存挑战并启用新的高性能内存架构,CXL 有望成为以数据为中心的计算的下一代互连。什么是 CXL?CXL 是一种行业采用的开放标准,为处理器、内存扩展和加速器提供高速缓存一致性互连。它基于 PCI Express (PCIe) 规范物理和电气接口,但为 AI/ML 应用程序提供了额外的功能和优势。CXL 可实现 CPU 内存空间与附加设备(例如加速器、GPU 或内存设备)上的内存之间的内存一致性。这意味着 CPU 和设备可以共享相同的内存视图并访问它,而无需任何软件干预或同步。CXL 还通过允许 CPU 以低延迟和高带宽访问连接设备上更大的内存池来扩展内存。这可以增加 AI/ML 应用程序的内存容量和性能。规范的三个主要版本描述了 CXL 标准。未来计划更多主要版本。现有主要版本的更新也将根据需要公布。每个主要版本都为以前的版本添加了新功能。CXL 1.0 :CXL 的第一个版本,于 2019 年 3 月发布,基于 PCIe 5.0。它允许主机 CPU 使用缓存一致性协议 (CXL.cache) 访问加速器设备上的共享内存,并使用内存语义 (CXL.mem) 启用内存扩展。CXL 2.0 :CXL 的第二个版本,于 2020 年 11 月发布,基于 PCIe 5.0。它支持 CXL 交换,将多个 CXL 设备连接到一个主机处理器或将每个设备连接到多个主机处理器。它还实现了设备完整性和数据加密功能。CXL 3.0 :CXL 的第三个版本,于 2022 年 8 月发布,基于 PCIe 6.0。它支持比 CXL 2.0 更高的带宽和更低的延迟,并增加了设备热插拔、电源管理和错误处理等新功能。图 1 显示了每个主要 CXL 版本的功能比较。图 1:CXL 功能比较CXL 规范描述了三种允许设备相互通信的协议。http://CXL.io:PCIe 5.0 协议的增强版本,可用于初始化、链接、设备发现、枚举和寄存器访问。它为 I/O 设备提供非一致性加载/存储接口。CXL.cache :一种缓存一致性协议,它定义了主机和设备之间的交互,允许连接的 CXL 设备使用请求和响应方法以极低的延迟有效地缓存主机内存。CXL.mem :一种内存协议,它使用加载和存储命令为主机处理器提供对连接设备内存的访问,其中主机 CPU 充当主设备,CXL 设备充当从属设备。它可以支持易失性和持久性内存架构。至少,所有 CXL 设备都必须使用 http://CXL.io,但可以选择支持 CXL.cache 或 CXL.mem,或同时支持两者。这些组合派生出三种设备类型:类型 1 :没有本地内存的专用加速器(例如智能 NIC)。设备依赖于使用 http://CXL.io 和 CXL.cache 协议对主机 CPU 内存进行一致访问。它们可以扩展 PCIe 协议功能(例如原子操作),并且可能需要实现自定义排序模型。类型 2 :具有高性能本地内存(GDDR 或 HBM)的通用加速器(GPU、ASIC 或 FPGA)。要访问主机 CPU 和设备内存,设备可以使用 http://CXL.io、CXL.cache 和 CXL.mem 协议。它们可以支持连贯和非连贯事务。类型 3 :没有本地缓存的内存扩展板和持久内存设备。设备可以使用 http://CXL.io 和 CXL.mem 协议通过加载和存储命令为主机 CPU 提供对内存的访问。它们可以支持易失性和持久性内存架构。基础设施用例CXL 是云和本地数据中心基础设施的游戏规则改变者,预计将很快得到广泛采用和标准化,包括:云计算CXL 可以使云服务提供商通过利用支持 CXL 的设备(例如加速器、内存扩展设备和持久性内存设备)为其客户提供更快、更高效的服务。云服务提供商每年在未使用或未充分利用的主内存(称为「搁浅内存」)上花费数十亿美元。应用程序可以更优化地使用集群中的计算节点按需访问的 CXL 设备池,从而优化数据中心资源。数据中心存储与云环境类似,虽然规模小得多,但 CXL 设备可以使数据中心运营商构建可持续发展的环境,并通过使用支持 CXL 的设备显著降低其基础设施成本和使用率。CXL 可以通过启用对内存驻留数据的低延迟和高带宽访问来提高块存储性能和可靠性。边缘计算CXL 可以使边缘计算平台通过使用支持 CXL 的设备(例如加速器、智能 NIC、内存扩展设备和持久内存设备)来处理不断增加的数据量和复杂性。在将数据发送到主数据中心之前在边缘处理数据可以减少流量并提高边缘计算性能、效率和安全性。网络CXL 可以使网络平台通过使用支持 CXL 的网络设备(例如智能 NIC、FPGA 和 ASIC)来处理不断增加的网络流量和复杂性。CXL 可以通过实现对设备内存的一致和非一致访问以及支持原子操作和自定义排序模型来提高网络性能、可扩展性和功能。应用用例应用程序将从支持 CXL 的基础架构中受益匪浅。一些主要的兴趣领域包括:1.AI/ML 加速CXL 可以为 GPU、ASIC 或 FPGA 等 AI/ML 加速器实现更快、更高效的 CPU 到设备和 CPU 到内存的连接。CXL 可以支持异构设备之间的一致性和非一致性事务、内存扩展和资源共享。允许应用程序处理更大的数据集,同时减少主机之间传输的数据量,从而缩短获得结果的时间。大规模内存、分析和图形数据库CXL 允许数据库访问无限的低延迟和高带宽内存,从而使系统能够在更大的数据池上工作。高性能计算CXL 可以通过利用支持 CXL 的加速器和内存池来提高高性能计算的性能、可扩展性和灵活性。CXL 3.0 引入了共享内存功能,允许许多计算节点就地访问内存驻留数据,而无需在运行前将其复制到本地,然后再将结果复制回来。使用 CXL 的行业标准互连加速以数据为中心的计算CXL 是一种新兴的开放式行业标准互连,可在 CPU 和设备(如加速器、内存扩展和持久内存设备)之间提供高带宽和低延迟缓存一致性连接。CXL 可以提高数据中心资源的性能、可扩展性和灵活性。CXL 可以帮助解决 AI/ML 应用程序面临的一些常见内存挑战,例如内存不足错误、溢出到磁盘以及数据/计算偏差。CXL 还可以支持需要大规模和高性能内存架构的新应用程序和用例,例如内存数据库、实时分析和高性能计算。由英特尔、AMD、Arm、Astera Labs、三星、美光、X-Conn 等众多行业领导者和创新者组成的不断壮大的生态系统支持 CXL。作为以数据为中心的计算的下一代互连,CXL 有望在不久的将来得到广泛接受和标准化。
什么是 CXL? 本文由半导体产业纵横(ID:ICVIEWS)编译自 spiceworksCXL(Compute Express Link)可以提高数据中心内存的性能、可扩展性和灵活性。MemVerge 的 Steve Scargall 解释了 CXL 是什么、它是如何工作的,以及为什么它是各种应用程序的游戏规则改变者,例如 AI/ML、HPC、数据库和分析。他还强调了采用 CXL 标准化的云计算和数据中心基础设施的一些行业趋势。CXL 是一种新兴的开放式行业标准互连,彻底改变了以数据为中心的计算。凭借其在 CPU 和设备(例如加速器、内存扩展和持久内存设备)之间的高带宽和低延迟缓存一致性连接,CXL 有可能重塑数据中心内存的性能、可扩展性和灵活性。通过解决 AI/ML 应用程序面临的常见内存挑战并启用新的高性能内存架构,CXL 有望成为以数据为中心的计算的下一代互连。什么是 CXL?CXL 是一种行业采用的开放标准,为处理器、内存扩展和加速器提供高速缓存一致性互连。它基于 PCI Express (PCIe) 规范物理和电气接口,但为 AI/ML 应用程序提供了额外的功能和优势。CXL 可实现 CPU 内存空间与附加设备(例如加速器、GPU 或内存设备)上的内存之间的内存一致性。这意味着 CPU 和设备可以共享相同的内存视图并访问它,而无需任何软件干预或同步。CXL 还通过允许 CPU 以低延迟和高带宽访问连接设备上更大的内存池来扩展内存。这可以增加 AI/ML 应用程序的内存容量和性能。规范的三个主要版本描述了 CXL 标准。未来计划更多主要版本。现有主要版本的更新也将根据需要公布。每个主要版本都为以前的版本添加了新功能。CXL 1.0 :CXL 的第一个版本,于 2019 年 3 月发布,基于 PCIe 5.0。它允许主机 CPU 使用缓存一致性协议 (CXL.cache) 访问加速器设备上的共享内存,并使用内存语义 (CXL.mem) 启用内存扩展。CXL 2.0 :CXL 的第二个版本,于 2020 年 11 月发布,基于 PCIe 5.0。它支持 CXL 交换,将多个 CXL 设备连接到一个主机处理器或将每个设备连接到多个主机处理器。它还实现了设备完整性和数据加密功能。CXL 3.0 :CXL 的第三个版本,于 2022 年 8 月发布,基于 PCIe 6.0。它支持比 CXL 2.0 更高的带宽和更低的延迟,并增加了设备热插拔、电源管理和错误处理等新功能。图 1 显示了每个主要 CXL 版本的功能比较。图 1:CXL 功能比较CXL 规范描述了三种允许设备相互通信的协议。http://CXL.io:PCIe 5.0 协议的增强版本,可用于初始化、链接、设备发现、枚举和寄存器访问。它为 I/O 设备提供非一致性加载/存储接口。CXL.cache :一种缓存一致性协议,它定义了主机和设备之间的交互,允许连接的 CXL 设备使用请求和响应方法以极低的延迟有效地缓存主机内存。CXL.mem :一种内存协议,它使用加载和存储命令为主机处理器提供对连接设备内存的访问,其中主机 CPU 充当主设备,CXL 设备充当从属设备。它可以支持易失性和持久性内存架构。至少,所有 CXL 设备都必须使用 http://CXL.io,但可以选择支持 CXL.cache 或 CXL.mem,或同时支持两者。这些组合派生出三种设备类型:类型 1 :没有本地内存的专用加速器(例如智能 NIC)。设备依赖于使用 http://CXL.io 和 CXL.cache 协议对主机 CPU 内存进行一致访问。它们可以扩展 PCIe 协议功能(例如原子操作),并且可能需要实现自定义排序模型。类型 2 :具有高性能本地内存(GDDR 或 HBM)的通用加速器(GPU、ASIC 或 FPGA)。要访问主机 CPU 和设备内存,设备可以使用 http://CXL.io、CXL.cache 和 CXL.mem 协议。它们可以支持连贯和非连贯事务。类型 3 :没有本地缓存的内存扩展板和持久内存设备。设备可以使用 http://CXL.io 和 CXL.mem 协议通过加载和存储命令为主机 CPU 提供对内存的访问。它们可以支持易失性和持久性内存架构。基础设施用例CXL 是云和本地数据中心基础设施的游戏规则改变者,预计将很快得到广泛采用和标准化,包括:云计算CXL 可以使云服务提供商通过利用支持 CXL 的设备(例如加速器、内存扩展设备和持久性内存设备)为其客户提供更快、更高效的服务。云服务提供商每年在未使用或未充分利用的主内存(称为「搁浅内存」)上花费数十亿美元。应用程序可以更优化地使用集群中的计算节点按需访问的 CXL 设备池,从而优化数据中心资源。数据中心存储与云环境类似,虽然规模小得多,但 CXL 设备可以使数据中心运营商构建可持续发展的环境,并通过使用支持 CXL 的设备显著降低其基础设施成本和使用率。CXL 可以通过启用对内存驻留数据的低延迟和高带宽访问来提高块存储性能和可靠性。边缘计算CXL 可以使边缘计算平台通过使用支持 CXL 的设备(例如加速器、智能 NIC、内存扩展设备和持久内存设备)来处理不断增加的数据量和复杂性。在将数据发送到主数据中心之前在边缘处理数据可以减少流量并提高边缘计算性能、效率和安全性。网络CXL 可以使网络平台通过使用支持 CXL 的网络设备(例如智能 NIC、FPGA 和 ASIC)来处理不断增加的网络流量和复杂性。CXL 可以通过实现对设备内存的一致和非一致访问以及支持原子操作和自定义排序模型来提高网络性能、可扩展性和功能。应用用例应用程序将从支持 CXL 的基础架构中受益匪浅。一些主要的兴趣领域包括:1.AI/ML 加速CXL 可以为 GPU、ASIC 或 FPGA 等 AI/ML 加速器实现更快、更高效的 CPU 到设备和 CPU 到内存的连接。CXL 可以支持异构设备之间的一致性和非一致性事务、内存扩展和资源共享。允许应用程序处理更大的数据集,同时减少主机之间传输的数据量,从而缩短获得结果的时间。大规模内存、分析和图形数据库CXL 允许数据库访问无限的低延迟和高带宽内存,从而使系统能够在更大的数据池上工作。高性能计算CXL 可以通过利用支持 CXL 的加速器和内存池来提高高性能计算的性能、可扩展性和灵活性。CXL 3.0 引入了共享内存功能,允许许多计算节点就地访问内存驻留数据,而无需在运行前将其复制到本地,然后再将结果复制回来。使用 CXL 的行业标准互连加速以数据为中心的计算CXL 是一种新兴的开放式行业标准互连,可在 CPU 和设备(如加速器、内存扩展和持久内存设备)之间提供高带宽和低延迟缓存一致性连接。CXL 可以提高数据中心资源的性能、可扩展性和灵活性。CXL 可以帮助解决 AI/ML 应用程序面临的一些常见内存挑战,例如内存不足错误、溢出到磁盘以及数据/计算偏差。CXL 还可以支持需要大规模和高性能内存架构的新应用程序和用例,例如内存数据库、实时分析和高性能计算。由英特尔、AMD、Arm、Astera Labs、三星、美光、X-Conn 等众多行业领导者和创新者组成的不断壮大的生态系统支持 CXL。作为以数据为中心的计算的下一代互连,CXL 有望在不久的将来得到广泛接受和标准化。