搜索到
31
篇与
的结果
-
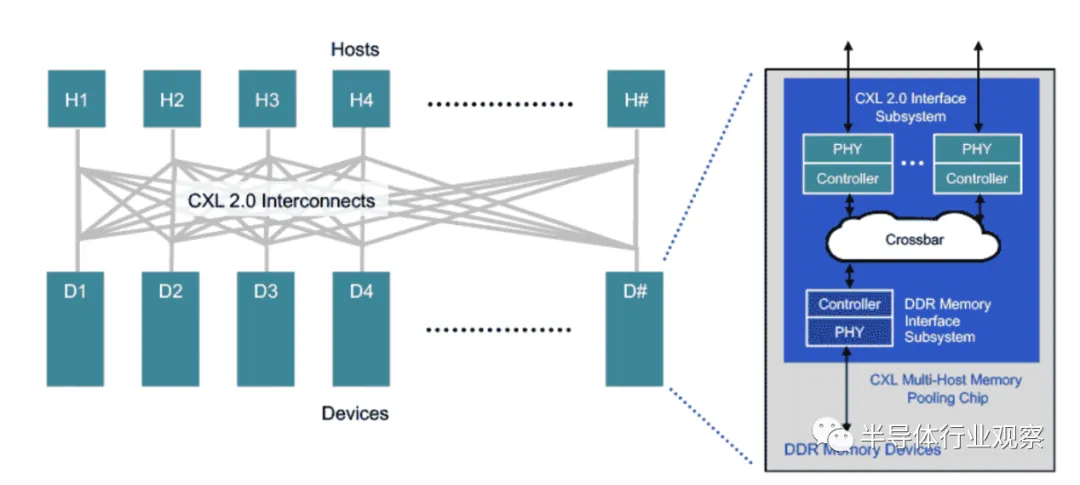
 关于CXL,你想知道的都在这里 半导体行业观察2023年03月08日09:59安徽指数级的数据增长促使计算行业开始进行突破性的架构转变,以从根本上改变数据中心的性能、效率和成本。为了继续提高性能,服务器正越来越多地转向异构计算架构,使用专门构建的加速器从 CPU 卸载专门的工作负载。CXL 的内存缓存一致性允许在 CPU 和加速器之间共享内存资源。此外,CXL 支持部署新的内存层,可以弥合主内存和 SSD 存储之间的延迟差距。这些新的内存层将增加带宽、容量、提高效率并降低总体拥有成本 (TCO)。凭借这些诸多优势,业界果断地将 CXL 融合为处理器、内存和加速器的高速缓存一致性互连。CXL通过一个叫做CXL 联盟的开放行业标准组织开发技术规范,促进新兴使用模型的性能突破,同时支持数据中心加速器和其他高速增强功能的开放生态系统。CXL简介:什么是 Compute Express Link?CXL是一个开放标准的行业支持的缓存一致性互连,用于处理器、内存扩展和加速器。从本质上讲,CXL 技术在 CPU 内存空间和连接设备上的内存之间保持内存一致性。这支持资源共享(或池化)以获得更高的性能,降低软件堆栈的复杂性,并降低整体系统成本。CXL 联盟已经确定了将采用新互连的三类主要设备:类型1设备:智能 NIC 等加速器通常缺少本地内存。通过 CXL,这些设备可以与主机处理器的 DDR 内存进行通信。类型2设备:GPU、ASIC 和 FPGA 都配备了 DDR 或 HBM 内存,并且可以使用 CXL 使主机处理器的内存在本地可供加速器使用,并使加速器的内存在本地可供 CPU 使用。它们还共同位于同一个缓存一致域中,有助于提升异构工作负载。类型 3 设备:内存设备可以通过 CXL 连接,为主机处理器提供额外的带宽和容量。内存的类型独立于主机的主内存。CXL 协议和标准CXL 标准通过三种协议支持各种用例:CXL.io、CXL.cache 和 CXL.memory。CXL.io:该协议在功能上等同于 PCIe 协议,并利用了 PCIe 的广泛行业采用和熟悉度。作为基础通信协议,CXL.io 用途广泛,适用于广泛的用例。CXL.cache:该协议专为更具体的应用程序而设计,使加速器能够有效地访问和缓存主机内存以优化性能。CXL.memory:该协议使主机(例如处理器)能够使用加载/存储命令访问设备连接的内存。这三个协议共同促进了计算设备(例如 CPU 主机和 AI 加速器)之间内存资源的一致共享。从本质上讲,这通过共享内存实现通信简化了编程。用于设备和主机互连的协议如下:类型 1 设备:CXL.io + CXL.cache类型2设备:CXL.io + CXL.cache + CXL.memory类型 3 设备:CXL.io + CXL.memoryCompute Express Link 与 PCIe:这两者有什么关系?CXL 建立在PCIe的物理和电气接口之上,其协议建立了一致性、简化了软件堆栈并保持与现有标准的兼容性。具体来说,CXL 利用 PCIe 5 功能,允许备用协议使用物理 PCIe 层。当支持 CXL 的加速器插入 x16 插槽时,设备会以每秒 2.5 千兆传输 (GT/s) 的默认 PCI Express 1.0 传输速率与主机处理器的端口进行协商。只有双方都支持 CXL,CXL 交易协议才会被激活。否则,它们作为 PCIe 设备运行。CXL 1.1 和 2.0 使用 PCIe 5.0 物理层,允许通过 16 通道链路在每个方向上以 32 GT/s 或高达 64 GB/s 的速度传输数据。CXL 3.0 使用 PCIe 6.0 物理层将数据传输扩展到 64 GT/s,支持通过 x16 链路进行高达 128 GB/s 的双向通信。CXL 2.0 和 3.0 有什么新功能?首先在内存池方面,CXL 2.0 支持切换以启用内存池。使用 CXL 2.0 交换机,主机可以访问池中的一个或多个设备。尽管主机必须支持 CXL 2.0 才能利用此功能,但内存设备可以是支持 CXL 1.0、1.1 和 2.0 的硬件的组合。在 1.0/1.1 中,设备被限制为一次只能由一台主机访问的单个逻辑设备。然而,一个 2.0 级别的设备可以被划分为多个逻辑设备,允许多达 16 台主机同时访问内存的不同部分。例如,主机 1 (H1) 可以使用设备 1 (D1) 中一半的内存和设备 2 (D2) 中四分之一的内存,以将其工作负载的内存需求与内存池中的可用容量完美匹配. 设备 D1 和 D2 中的剩余容量可由一台或多台其他主机使用,最多可达 16 台。设备 D3 和 D4 分别启用了 CXL 1.0 和 1.1,一次只能由一台主机使用。CXL 3.0 引入了对等直接内存访问和对内存池的增强,其中多个主机可以一致地共享 CXL 3.0 设备上的内存空间。这些功能支持新的使用模型并提高数据中心架构的灵活性。其次来到交换方面;通过转向 CXL 2.0 直连架构,数据中心可以获得主内存扩展的性能优势,以及池内存的效率和总体拥有成本 (TCO) 优势。假设所有主机和设备都支持 CXL 2.0,则“切换”通过 CXL 内存池芯片中的交叉开关集成到内存设备中。这可以保持较低的延迟,但需要更强大的芯片,因为它现在负责交换机执行的控制平面功能。通过低延迟直接连接,连接的内存设备可以使用 DDR DRAM 来扩展主机主内存。这可以在非常灵活的基础上完成,因为主机能够访问处理特定工作负载所需的尽可能多的设备的全部或部分容量。CXL 3.0 引入了多层交换,支持交换结构的实施。CXL 2.0 支持单层交换。借助 CXL 3.0,启用了交换结构,其中交换机可以连接到其他交换机,从而大大增加了扩展的可能性。第三,“按需”内存范例;类似于拼车,CXL 2.0 和 3.0 在“按需”的基础上为主机分配内存,从而提供更高的内存利用率和效率。该架构提供了为标称工作负载(而不是最坏情况)配置服务器主内存的选项,能够在需要时访问池以处理高容量工作负载,并为 TCO 带来更多好处。最终,CXL 内存池模型可以支持向服务器分解和可组合性的根本转变。在此范例中,可以按需组合离散的计算、内存和存储单元,以有效地满足任何工作负载的需求。第四,完整性和数据加密 (IDE);分解——或分离服务器架构的组件——增加了攻击面。这正是 CXL 包含安全设计方法的原因。具体来说,所有三个 CXL 协议都通过完整性和数据加密 (IDE) 来保护,IDE 提供机密性、完整性和重放保护。IDE 在 CXL 主机和设备芯片中实例化的硬件级安全协议引擎中实现,以满足 CXL 的高速数据速率要求,而不会引入额外的延迟。应该注意的是,CXL 芯片和系统本身需要防止篡改和网络攻击的保护措施。在 CXL 芯片中实现的硬件信任根可以为安全启动和安全固件下载的安全和支持要求提供此基础。第五,将信令扩展到 64 GT/s;CXL 3.0 带来了标准数据速率的阶跃函数增加。如前所述,CXL 1.1 和 2.0 在其物理层使用 PCIe 5.0 电气:32 GT/s 的 NRZ 信号。CXL 3.0 秉承了以广泛采用的 PCIe 技术为基础构建的相同理念,并将其扩展到 2022 年初发布的最新 6.0 版 PCIe 标准。使用 PAM4 信号将 CXL 3.0 数据速率提高到 64 GT/s。我们涵盖了 PCIe 6 中 PAM4 信令的详细信息——您需要知道的一切。得益于CXL的出现,开发者可以简化和改进低延迟连接和内存一致性,显著提高计算性能和效率,同时降低 TCO。此外,CXL 内存扩展功能可在当今服务器中的直接连接 DIMM 插槽之上实现额外的容量和带宽。CXL 使得通过 CXL 连接设备向 CPU 主机处理器添加更多内存成为可能。当与持久内存配对时,低延迟 CXL 链路允许 CPU 主机将此额外内存与 DRAM 内存结合使用。大容量工作负载的性能取决于大内存容量,例如 AI。考虑到这些是大多数企业和数据中心运营商正在投资的工作负载类型,CXL 的优势显而易见。来自微信
关于CXL,你想知道的都在这里 半导体行业观察2023年03月08日09:59安徽指数级的数据增长促使计算行业开始进行突破性的架构转变,以从根本上改变数据中心的性能、效率和成本。为了继续提高性能,服务器正越来越多地转向异构计算架构,使用专门构建的加速器从 CPU 卸载专门的工作负载。CXL 的内存缓存一致性允许在 CPU 和加速器之间共享内存资源。此外,CXL 支持部署新的内存层,可以弥合主内存和 SSD 存储之间的延迟差距。这些新的内存层将增加带宽、容量、提高效率并降低总体拥有成本 (TCO)。凭借这些诸多优势,业界果断地将 CXL 融合为处理器、内存和加速器的高速缓存一致性互连。CXL通过一个叫做CXL 联盟的开放行业标准组织开发技术规范,促进新兴使用模型的性能突破,同时支持数据中心加速器和其他高速增强功能的开放生态系统。CXL简介:什么是 Compute Express Link?CXL是一个开放标准的行业支持的缓存一致性互连,用于处理器、内存扩展和加速器。从本质上讲,CXL 技术在 CPU 内存空间和连接设备上的内存之间保持内存一致性。这支持资源共享(或池化)以获得更高的性能,降低软件堆栈的复杂性,并降低整体系统成本。CXL 联盟已经确定了将采用新互连的三类主要设备:类型1设备:智能 NIC 等加速器通常缺少本地内存。通过 CXL,这些设备可以与主机处理器的 DDR 内存进行通信。类型2设备:GPU、ASIC 和 FPGA 都配备了 DDR 或 HBM 内存,并且可以使用 CXL 使主机处理器的内存在本地可供加速器使用,并使加速器的内存在本地可供 CPU 使用。它们还共同位于同一个缓存一致域中,有助于提升异构工作负载。类型 3 设备:内存设备可以通过 CXL 连接,为主机处理器提供额外的带宽和容量。内存的类型独立于主机的主内存。CXL 协议和标准CXL 标准通过三种协议支持各种用例:CXL.io、CXL.cache 和 CXL.memory。CXL.io:该协议在功能上等同于 PCIe 协议,并利用了 PCIe 的广泛行业采用和熟悉度。作为基础通信协议,CXL.io 用途广泛,适用于广泛的用例。CXL.cache:该协议专为更具体的应用程序而设计,使加速器能够有效地访问和缓存主机内存以优化性能。CXL.memory:该协议使主机(例如处理器)能够使用加载/存储命令访问设备连接的内存。这三个协议共同促进了计算设备(例如 CPU 主机和 AI 加速器)之间内存资源的一致共享。从本质上讲,这通过共享内存实现通信简化了编程。用于设备和主机互连的协议如下:类型 1 设备:CXL.io + CXL.cache类型2设备:CXL.io + CXL.cache + CXL.memory类型 3 设备:CXL.io + CXL.memoryCompute Express Link 与 PCIe:这两者有什么关系?CXL 建立在PCIe的物理和电气接口之上,其协议建立了一致性、简化了软件堆栈并保持与现有标准的兼容性。具体来说,CXL 利用 PCIe 5 功能,允许备用协议使用物理 PCIe 层。当支持 CXL 的加速器插入 x16 插槽时,设备会以每秒 2.5 千兆传输 (GT/s) 的默认 PCI Express 1.0 传输速率与主机处理器的端口进行协商。只有双方都支持 CXL,CXL 交易协议才会被激活。否则,它们作为 PCIe 设备运行。CXL 1.1 和 2.0 使用 PCIe 5.0 物理层,允许通过 16 通道链路在每个方向上以 32 GT/s 或高达 64 GB/s 的速度传输数据。CXL 3.0 使用 PCIe 6.0 物理层将数据传输扩展到 64 GT/s,支持通过 x16 链路进行高达 128 GB/s 的双向通信。CXL 2.0 和 3.0 有什么新功能?首先在内存池方面,CXL 2.0 支持切换以启用内存池。使用 CXL 2.0 交换机,主机可以访问池中的一个或多个设备。尽管主机必须支持 CXL 2.0 才能利用此功能,但内存设备可以是支持 CXL 1.0、1.1 和 2.0 的硬件的组合。在 1.0/1.1 中,设备被限制为一次只能由一台主机访问的单个逻辑设备。然而,一个 2.0 级别的设备可以被划分为多个逻辑设备,允许多达 16 台主机同时访问内存的不同部分。例如,主机 1 (H1) 可以使用设备 1 (D1) 中一半的内存和设备 2 (D2) 中四分之一的内存,以将其工作负载的内存需求与内存池中的可用容量完美匹配. 设备 D1 和 D2 中的剩余容量可由一台或多台其他主机使用,最多可达 16 台。设备 D3 和 D4 分别启用了 CXL 1.0 和 1.1,一次只能由一台主机使用。CXL 3.0 引入了对等直接内存访问和对内存池的增强,其中多个主机可以一致地共享 CXL 3.0 设备上的内存空间。这些功能支持新的使用模型并提高数据中心架构的灵活性。其次来到交换方面;通过转向 CXL 2.0 直连架构,数据中心可以获得主内存扩展的性能优势,以及池内存的效率和总体拥有成本 (TCO) 优势。假设所有主机和设备都支持 CXL 2.0,则“切换”通过 CXL 内存池芯片中的交叉开关集成到内存设备中。这可以保持较低的延迟,但需要更强大的芯片,因为它现在负责交换机执行的控制平面功能。通过低延迟直接连接,连接的内存设备可以使用 DDR DRAM 来扩展主机主内存。这可以在非常灵活的基础上完成,因为主机能够访问处理特定工作负载所需的尽可能多的设备的全部或部分容量。CXL 3.0 引入了多层交换,支持交换结构的实施。CXL 2.0 支持单层交换。借助 CXL 3.0,启用了交换结构,其中交换机可以连接到其他交换机,从而大大增加了扩展的可能性。第三,“按需”内存范例;类似于拼车,CXL 2.0 和 3.0 在“按需”的基础上为主机分配内存,从而提供更高的内存利用率和效率。该架构提供了为标称工作负载(而不是最坏情况)配置服务器主内存的选项,能够在需要时访问池以处理高容量工作负载,并为 TCO 带来更多好处。最终,CXL 内存池模型可以支持向服务器分解和可组合性的根本转变。在此范例中,可以按需组合离散的计算、内存和存储单元,以有效地满足任何工作负载的需求。第四,完整性和数据加密 (IDE);分解——或分离服务器架构的组件——增加了攻击面。这正是 CXL 包含安全设计方法的原因。具体来说,所有三个 CXL 协议都通过完整性和数据加密 (IDE) 来保护,IDE 提供机密性、完整性和重放保护。IDE 在 CXL 主机和设备芯片中实例化的硬件级安全协议引擎中实现,以满足 CXL 的高速数据速率要求,而不会引入额外的延迟。应该注意的是,CXL 芯片和系统本身需要防止篡改和网络攻击的保护措施。在 CXL 芯片中实现的硬件信任根可以为安全启动和安全固件下载的安全和支持要求提供此基础。第五,将信令扩展到 64 GT/s;CXL 3.0 带来了标准数据速率的阶跃函数增加。如前所述,CXL 1.1 和 2.0 在其物理层使用 PCIe 5.0 电气:32 GT/s 的 NRZ 信号。CXL 3.0 秉承了以广泛采用的 PCIe 技术为基础构建的相同理念,并将其扩展到 2022 年初发布的最新 6.0 版 PCIe 标准。使用 PAM4 信号将 CXL 3.0 数据速率提高到 64 GT/s。我们涵盖了 PCIe 6 中 PAM4 信令的详细信息——您需要知道的一切。得益于CXL的出现,开发者可以简化和改进低延迟连接和内存一致性,显著提高计算性能和效率,同时降低 TCO。此外,CXL 内存扩展功能可在当今服务器中的直接连接 DIMM 插槽之上实现额外的容量和带宽。CXL 使得通过 CXL 连接设备向 CPU 主机处理器添加更多内存成为可能。当与持久内存配对时,低延迟 CXL 链路允许 CPU 主机将此额外内存与 DRAM 内存结合使用。大容量工作负载的性能取决于大内存容量,例如 AI。考虑到这些是大多数企业和数据中心运营商正在投资的工作负载类型,CXL 的优势显而易见。来自微信 -
-
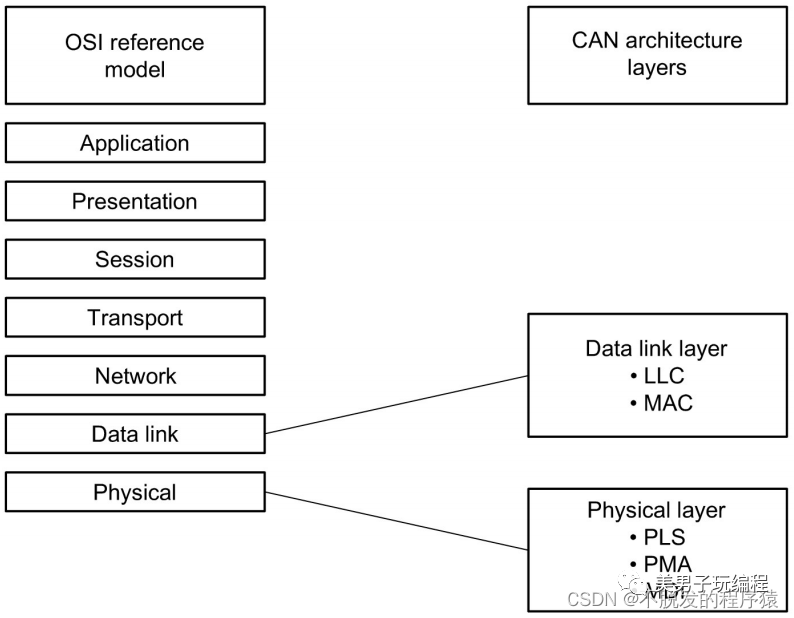
详解CAN总线:什么是CAN总线? 1P与S0C设计2022年10月24日12:00江苏在之前的博文中分享过一系列一文搞懂:SPI协议、I2C协议、PID算法、Modbus协议等文章,也考虑过是否可以出一篇介绍CAN总线协议的文章,但是在之后的学习研究中,发觉CAN总线协议比较庞大和复杂,做为刚刚进入汽车电子行业的开发小白,一篇文章难以讲解清晰,所以决定在汽车电子专栏中连载分享关于CAN总线协议的相关知识。由于本人也处于学习和研究阶段,如果对CAN总线协议有理解不到位的地方,还请各位大佬在文末留言指正一二。1CAN总线简介CAN总线协议(Controller Area Network),控制器局域网总线,是德国BOSCH(博世)公司研发的一种串行通讯协议总线,它可以使用双绞线来传输信号,是世界上应用最广泛的现场总线之一。CAN通讯协议标准(ISO-11898:2003)介绍了设备间信息是如何传递以及符合开放系统互联参考模型(OSI)的哪些分层项。实际CAN通讯是在连接设备的物理介质中进行,物理介质的特性由模型中的物理层定义。ISO11898体系结构定义七层,OSI模型中的最低两层作为数据链路层和物理层,如下图所示:LLC用于接收滤波、超载通告、回复管理;MAC用于数据封装/拆封、帧编码、媒体访问管理、错误检测与标定、应答、串转发/并转串;PLS用于位编码/解码、位定时、同步;PMA为收发器特性。CAN协议主要用于汽车中各种不同元件之间的通信,以此取代昂贵而笨重的配电线束,该协议的健壮性使其同样适用于自动化和工业环境中。CAN总线协议距今已经发展40多年,如今,CAN总线已成为汽车(汽车、卡车、公共汽车、拖拉机等)、轮船、飞机、电动汽车电池、机械等的标准配置。CAN之前的版本:汽车ECU是复杂的点对点布线1986年:BOSCH(博世)开发了CAN协议作为解决方案1991年:BOSCH(博世)发布了CAN 2.0(CAN 2.0A:11位,2.0B:29位)1993年:CAN被采用为国际标准(ISO 11898)2003年:ISO 11898成为标准系列2012年:博世发布了CAN FD 1.02015年:CAN FD协议标准化(ISO 11898-1)2016年:CAN物理层,数据速率高达5 Mbit/s,已通过ISO 11898-2标准化CAN总线具有以下特点:符合OSI开放式通信系统参考模型;两线式总线结构,电气信号为差分式;多主控制,在总线空闲时,所有的单元都可开始发送消息,最先访问总线的单元可获得发送权;多个单元同时开始发送时,发送高优先级ID消息的单元可获得发送权;点对点控制,一点对多点及全局广播几种传送方式接收数据,网络上的节点可分成不同的优先级,可以满足不同的实时要求;采用非破坏性位仲裁总线结构机制,当两个节点同时向网络上传送信息时,优先级低的节点主动停止数据发送,而优先级高的节点可不受影响地继续传送数据消息报文不包含源地址或者目标地址,仅通过标识符表明消息功能和优先级;基于固定消息格式的广播式总线系统,短帧结构;事件触发型,只有当有消息要发送时,节点才向总线上广播消息;可以通过发送远程帧请求其它节点发送数据;消息数据长度0~8Byte;节点数最多可达110个;错误检测功能。所有节点均可检测错误,检测错误的单元会立即通知其它所有单元;发送消息出错后,节点会自动重发;故障限制,具有自动关闭总线的功能,节点控制器可以判断错误是暂时的数据错误还是持续性错误,当总线上发生持续数据错误时,控制器可将节点从总线上隔离,以使总线上的其他操作不受影响;通信介质可采用双绞线、同轴电缆和光导纤维,一般使用最便宜的双绞线;理论上,CAN总线用单根信号线就可以通信,但还是配备了第二根导线,第二根导线与第一根导线信号为差分关系,可以有效抑制电磁干扰;直接通信距离最远可达10KM(速率4Kbps以下),通信速率最高可达1MB/s(此时距离最长40M);总线上可同时连接多个节点,可连接节点总数理论上是没有限制的,但实际可连接节点数受总线上时间延迟及电气负载的限制。每帧信息都有CRC校验及其他检错措施,数据错误率极低;废除了传统的站地址编码,取而代之的是对通信数据块进行编码。采用这种方法的优点是可使网络内的节点个数在理论上不受限制,数据块的标识码可由11位或29位二进制数组成,因此可以定义211或229个不同的数据块,这种数据块编码方式,还可使不同的节点同时接收到相同的数据,这一点在分步式控制中非常重要。CAN总线具体以下优势:2CAN节点组成CAN节点通常由三部分组成:CAN收发器、CAN控制器和MCU。CAN总线通过差分信号进行数据传输,CAN收发器将差分信号转换为TTL电平信号,或者将TTL电平信号转换为差分信号,CAN控制器将TTL电平信号接收并传输给MCU,如下图所示:目前,我们常用的STM32、华大、瑞萨等单片机内部就集成了CAN控制器外设,通过配置就可实现对CAN报文数据的读取和发送。3CAN总线结构CAN总线是一种广播类型的总线,可支持线形拓扑、星形拓扑、树形拓扑和环形拓扑等。CAN网络中至少需要两个节点设备才可进行通信,无法仅向某一个特定节点设备发送消息,发送数据时所有节点都不可避免地接收所有流量。但是,CAN总线硬件支持本地过滤,因此每个节点可以设置对有效的消息做出反应。线形拓扑是在一条主干总线分出各个节点支线,其优点在于布线施工简单,接线方便,阻抗匹配规则固定,缺点是拓扑不够灵活,在一定程度上影响通讯距离,如下图所示:星形拓扑是每个节点通过中央设备连到一起,其优点是容易扩展,缺点是一旦中央设备出故障会导致总线集体故障,而且分支线长不同,阻抗匹配复杂,可能需要通过一些中继器或集线器进行扩展,如下图所示:树形拓扑是节点分支比较多,且分支长度不同,其优点是布线方便,缺点是网络拓扑复杂,阻抗匹配困难,通讯中极易出现问题,必须加一些集线器设备,如下图所示:环形拓扑是将CAN总线头尾相连,形成环状,其优点是线缆任意位置断开,总线都不会出现问题,缺点是信号反射严重,无法用于高波特率和远距离传输,如下图所示:虽然CAN总线可以支持多种网络拓扑,但在实际应用中比较推荐使用线形拓扑,且在IOS 11898-2中高速CAN物理层规范推荐也是线形拓扑。在ISO 11898-2和ISO 11898-3中分别规定了两种CAN总线结构(在BOSCH CAN2.0规范中,并没有关于总线拓扑结构的说明)。ISO 11898-2中定义了通信速率为125Kbps~1Mbps的高速闭环CAN通信标准,当通信总线长度≤40米,最大通信速率可达到1Mbps,高速闭环CAN(高速CAN)通信如下图所示:ISO 11898-3中定义了通信速率为10~125Kbps的低速开环CAN通信标准,当传输速率为40Kbps时,总线距离可达到1000米。低速开环CAN(低速容错CAN)通信如下图所示:4CAN总线物理电气特性在CAN总线上,利用CAN_H和CAN_L两根线上的电位差来表示CAN信号。CAN 总线上的电位差分为显性电平(Dominant Voltage)和隐性电平(Recessive Voltage),其中显性电平为逻辑 0,隐性电平为逻辑 1。高速CAN总线(ISO 11898-2,通信速率为125Kbps~1Mbps)在传输显性(0)信号时,会将 CAN_H端抬向5V高电平,将CAN_L拉向0V低电平。当传输隐性(1)信号时,并不会驱动 CAN_H 或者 CAN_L 端。 显性信号 CAN_H 和 CAN_L 两端差分标称电压为 2V。 终端电阻在没有驱动时,将差分标称电压降回 0V。显性信号(0)的共模电压需要在 1.5V 到 3.5V 之间。隐性信号(1)的共模电压需要在+/-12V。低速/容错CAN(ISO 11898-3,通信速率为10~125Kbps)在传输显性信号(0)时,驱动CANH端抬向5V,将CANL端降向0V。在传输隐性信号(1)时并不驱动CAN 总线的任何一端。在电源电压VCC为5V时,显性信号差分电压需要大于2.3V,隐性信号的差分电压需要小于0.6V。CAN总线两端未被驱动时,终端电阻使CAN L端回归到RTH电压(当电源电压VCC为5V时,RTH电压至少为Vcc-0.3V=4.7V),同时使CAN H端回归至RTL电压(RTL电压最大为0.3V)。两根线需要能够承受-27V至40V的电压而不被损坏。在高速和低速CAN中从隐性信号向显性信号过渡的速度更快,因为此时CAN线缆被主动积极地驱动,显性向隐性的过渡速度主要取决于CAN网络的长度和导线的电容。来自微信
-
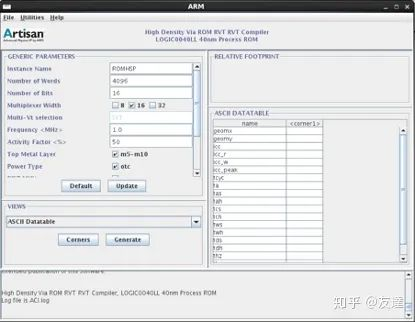
科普:Memory Compiler生成的Register file和SRAM有何区别? IP与S0C设计2021年09月03日04:01前两期,我们分别对OTP和MTP,RAM和ROM进行了比较。这一次,我们来谈谈Memory Compiler,以及通过它生成的Register file和SRAM。什么是Memory Compiler ?Memory Compiler,内存编译器。顾名思义,是用来生成不同容量memory的工具,输入参数,我们就可以得到生成的文件。生成的文件包括:前端设计verilog模型、逻辑综合的时序库、后端需要的电路网表和LEF/GDS版图文件、其他DFT验证相关的、datasheet手册等等。Memory Compiler由供应商提供,往往是不通用的,界面也不尽相同。同一个厂商的不同工艺下,Memory Compiler不同。相同工艺,不同厂商,Memory Compiler也不同。内存编译器通常是供应商的知识产权,其功能是根据客户的需求生成各种类型的memory。一般的Memory Compiler提供五个ram脚本(rf_sp,sram_sp,rf_tp,sram_dp,rom)。这意味着可以生成1 Port Register file、Single Port SRAM、2 Port Register file、Dual Port SRAM以及ROM。不同的厂商或许还拥有特殊工艺。一般来说,MC只生成常用的memory,特殊的往往需要定制或者组合。考虑到面积和性能,又可以划分为High Speed和High Density等等。图源知乎:SMIC 的Memory Compiler,由Artisan公司提供Memory Compiler使用介绍在使用Memory Compiler时,请务必确保你的RAM从头到位的规格与设定都相同,否则会造成一些不可避免的错误。首先在RTL代码阶段,要用到RAM就要用到verilog代码,此时不需要着急产生其他后阶段的必要数据,因为RTL代码阶段只需要行为级模型即可。当进入门级代码后,RAM compiler就要产生其他的相关数据了,同时要考虑RAM版图的位置与方向。由于重大的设计不会一蹴而就,所以有两个重点,第一个是每次使用RAM compiler时都一定要让它产生特性设置文档,避免忘记自己做过的设定。第二件事是对应的文件名要定义好,否则RAM的方向不同但是又用到了相同的文件名,就会把原始数据覆盖掉。RTL阶段在RTL阶段主要只是产生verilog行为级和设置文件。因为在RTL阶段不需要考虑RAM的位置信息。Memory Compiler提供多种选择,在这个阶段,选择生成RF或是SRAM,以及确定端口数量。如果容量比较大的话,相同设置下,单端口比双端口面积要小,速度也要快,功耗要低。综合与布局布线阶段为了避免重新启用Memory Compiler与以前设置有出入,所以最好一次性将Memory Compiler能够产生的相关数据一并输出。在这里,Memory Compiler还需要产生3种数据。 .LIB 该数据是RAM的时序信息文件 .VCLEF 布局布线工具需要使用的物理信息文件 .SPEC RAM的注释文件在布局布线前,需要考虑RAM的长与宽,估计它的位置与方向,尽量让功能想关的模块靠近一些。将产生的.LIB文件转换成.DB文件,就可以把Memory Compiler生成的RAM加入到代码中进行综合了。在综合工具的脚本中的serch_path下加入RAM的DB文件地址即可。以上为Memory Compiler大致的使用流程,不同的工具在细节上或许有所区别,但大体流程如此。苏州腾芯微电子的Memory Compiler界面接下来,我们来聊一聊,生成的memory——Register file和SRAM。Register file与SRAM的比较首先,厘清一下概念上的问题,Register file和很多的registers不是同一个概念。我们在IC设计里谈到register时,常常是指D触发器,而Register file是一种memory。那么,同为Memory Compiler生成,RF和SRAM有什么区别呢?在比较中,不同规格相比较显然不够客观,也不能让我们更清晰地认识到它们的差异。在比较前,我们需要先把端口的概念搞清楚: 1 port / single port:单端口,读写同端口,需要WE控制输入输出 2 port:双端口,读写分开,输入输出端口固定,可以不用WE控制 dual port:同样是双端口,但读写端口不固定,且都可读可写 RF 的端口示意图SRAM 的端口示意图所以我们应当把1P RF和SP SRAM,2P RF和DP SRAM比较,才有意义。1 Port Register file 和 Single Port SRAM同为单端口,从外部端口看,难以区分1P RF和SP SRAM的区别,但是我们可以从以下几个方面,来进行区分。首先我们以Memory Size:512*32的1P RF和SP SRAM为例。此为1P RF此为SP SRAM从datasheet直观上来看,SRAM比Register file多了OEN(输出使能)。除此之外,Register file和SRAM两者相比,SRAM的最大容量比RF要大。相同配置下,RF的面积更大,功耗更低。在mem比较小的情况下用RF划算,并且同样的mem,RF的长宽比会更小,方便后端floorplan。大容量的时候,SRAM的速度是有优势的。并且SRAM速度快,面积小。同样大小的RF,面积就很大了,速度也慢下来了。所以简单来说,小容量选RF,大容量选SRAM。2P Register file 和 Dual Port SRAM比起1P RF与SP SRAM的比较,2P RF与DP SRAM的差异较为直观。2P RF有一个输入数据总线,一个输出的数据总线。DP SRAM有两个数据输入总线,两个数据输出总线。换句话说,2P RF是一组信号,读写端口固定;而DP SRAM则有两组信号,读写不分开。且两组信号,每组都有自己的地址,输入数据总线,输出数据总线,时钟,读/写控制。这两组可以分别往存储单元写,或从存储单元读出。读可以一直读,写时数据可能存储单元数据更新,数据也可能输出端口。DP SRAM就好像2个SP SRAM共用存储单元。具体的应用,需要结合设计人员和项目自身的需求来选用。小容量,地址少的用RF。有两个外设要同时读写SRAM的,就要用DP SRAM。涉及到具体的选取,则需要由设计人员自己做判断了。以下为读写时序图:图源:数字IC自修室来自微信
-
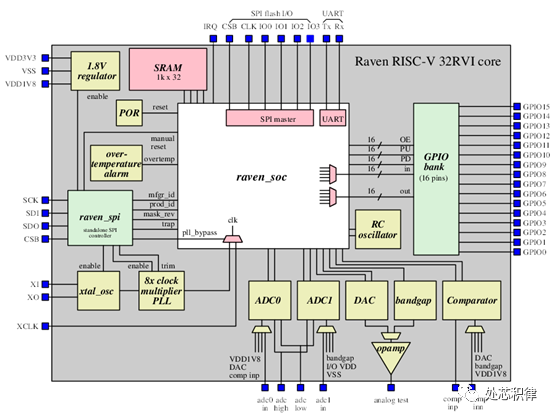
如何用云服务器搭建一个芯片SOC环境 ICbug猎人处芯积律2021年08月01日07:52今天这篇文章将介绍如何在云端服务器安装EDA软件并且搭建SOC环境。EDA是一个很大的概念,我们这里讲的是芯片设计中的EDA软件。芯片设计的EDA软件包括设计输入工具如composer,设计仿真工具如VCS/Verdi,综合工具如Design Compile,布局布线工具如Design Planner,物理验证工具Dracula,模拟电路仿真器SPICE等。举例的这些EDA工都是收费软件。目前也有一些开源的EDA工具可以用,如仿真用的Iverilog/ Verilator,看波形用的gtkwave,综合用的YoSys等。Efabless曾经用这些纯开源的EDA软件开发并流片过一款芯片。这款芯片结构如下该芯片的资料在这里:https://github.com/efabless/raven-picorv32。这个链接里面包含了该芯片的开源软件,代码,测试等资料,作为一款SOC开源项目大家有兴趣可以去看看。刚才提到的开源EDA Iverilog和Gtkwave的安装方法比较简单,直接敲下面的命令即可:sudo apt-get install iverilog sudo apt-get install gtkwave对于Verilator的安装我们等会在搭建SOC环境的时候介绍,其他开源EDA的安装方法这里不再介绍,有兴趣的可以在网上搜索。Verdi/VCS/simvision/irun等需要授权的EDA软件也可以在云服务器上安装,但是需要license支持才能用。虽然网上也有破解版本,但是个人不推荐使用。如果是企业用户且员工比较少的情况下可以向各个地方的集成电路设计服务机构(如苏州ICC)申请各家EDA的license,能够得到比较大的支持。下面我们介绍搭建一个SOC项目并用相关EDA工具进行仿真。Opentitan是一个开源项目,他是由RISCV搭建的一款简单芯片,其系统架构如下这颗芯片主要构成有1个riscv核,512kB的eflash,64kB的SRAM,16kB的ROM,安全加密模块,32个IO端口,一个UART,一个GPIO,一个SPI。目前I2C还没加进去,据说后面会加进去。从opentitan提供的资料来看,该项目包括了开源的软件,硬件代码,还提供了三套仿真测试环境,分别是verilator仿真环境,FPGA测试环境以及需要VCS的仿真环境。学习人员可以根据自己需要选择不同的运行环境。我们提供的SOC环境搭建步骤在opentitan 的开源网站都能找到,如果有不清楚的地方可以在下面这个链接处查找。https://docs.opentitan.org/doc/ug/getting_started/搭建环境的第一步是创建工具的路径。 sudo mkdir/tools sudo chown $(id -un) /tools第二步是克隆opentitan的库,这样就将SOC的源代码和相关资料拷贝到你的云服务器上。working-area 是你创建的工作路径。cd git clone https://github.com/lowRISC/opentitan.git代码资料会被存在 /opentitan 下面,我们后面介绍的$REPO_TOP 指的就是 /opentitan 这个路径。第三步安装相关软件sudo apt install autoconf bison build-essentialclang-format cmake curl \doxygenflex g++ git golang libelf1 libelf-dev libftdi1-2 libftdi1-dev \ibncurses5 libssl-dev libusb-1.0-0 lsb-release make ninja-build perl \pkgconfpython3 python3-pip python3-setuptools python3-wheel python3-yaml \srecordtree xsltproc zlib1g-dev xz-utils第四步 芯片环境中有用到python3相关的脚本,而云服务器没有安装python3的相关组件,因此需要我们自己安装。apt install python-pippip install --upgrade setuptoolspython -m pip install --upgrade pipsudo apt install djangopip3 install --upgrade pippip3 install django-haystackpip3 install setuptools-scmpip3 install django-haystack装完这些软件后再按照下面步骤安装python3相关的脚本软件。cd $REPO_TOPpip3 install --user -r python-requirements.txt第五步是安装riscv的编译工具链,官网提供了两种方法,一个直接下载,另外一个需要自己编译工具链,对于初学者来讲,建议选择第一种。cd $REPO_TOP./util/get-toolchain.py通过上面五步,我们已经将芯片的源代码和工具链软件都准备好了。在上述文中也讲到,opentatian可以用开源的EDA工具进行仿真,也可以用VCS等需要授权的软件进行仿真。在这里我们选择开源的verilator仿真工具进行仿真。为此需要按照以下步骤安装verilator仿真工具。export VERILATOR_VERSION=4.104git clonehttps://github.com/verilator/verilator.gitcd verilatorgit checkout v$VERILATOR_VERSIONautoconf./configure--prefix=/tools/verilator/$VERILATOR_VERSIONmakemake install做完这些我们就可以去跑仿真了。第六步build环境cd $REPO_TOPfusesoc --cores-root . run --flag=fileset_top--target=sim --setup --build lowrisc:systems:chip_earlgrey_verilator./meson_init.shninja -C build-out all第七步输入以下指令进行跑仿真。cd $REPO_TOPbuild/lowrisc_systems_chip_earlgrey_verilator_0.1/sim-verilator/Vchip_earlgrey_verilator\ --meminit=rom,build-bin/sw/device/boot_rom/boot_rom_sim_verilator.scr.39.vmem--meminit=flash,build-bin/sw/device/examples/hello_world/hello_world_sim_verilator.elf\--meminit=otp,build-bin/sw/device/otp_img/otp_img_sim_verilator.vmem 这个时候我们可以在工作界面上看到类似以下log 为了看运行的结果用screen /dev/pts/4进行查看。由于开源软件运行的效率会比较低,跑仿真的时间会比较久,所以需要耐心等待一下。 如果想看信号波形,在上面跑仿真的命令里面加—trace,即可生成波形。然后用gtkwave sim.fst 查看波形,其效果如下。写在最后,opentitan这个项目的开发流程还是比较全的,对于芯片从业者是一个很好的学习资源,特别是里面验证的介绍很多公司都可以借鉴。经常看到很多芯片初从业人员没有什么项目经验,如果能够吃透这个项目那你在找工作的时候是非常有竞争力的。通过这篇文章我希望能够将做芯片这件看起来门槛很高的事情简单化,让更多的大学生甚至中学生都能参与其中,让更多的人更早的去了解知道计算机的工作原理。来自微信