搜索到
344
篇与
的结果
-
 STM32 - 定时器的设定 - 基础- 07 - 6-step PWM generation - 6步长PWM的产生 - COM Event的解释 前言:本节主要讲互补输出的步长设定问题,同时引入了一个重要的参数COM,这个再诸多STM32的手册里面都过于分散,在本文有一个比较完备的小结: When complementary outputs are used on a channel, preload bits are available on the OCxM, CCxE and CCxNE bits.互补输出主要由以下三个可以预设的设定决定:1 OC1M,OC1通道的输出模式,首先有OC1REF的模式决定,OC1REF会接到OC1 、OC1N然后,在OC1这里进行第二次设置,这里的设置又包括比较复杂的一组设定,有一个表:COM:(COM COMMUTATION交换 EVENT)or (Capture/Compare control update)COM的引入:提到COM之前,我们先看:定时器的控制寄存器2,里面的CCPC,CCUS控制位TIM1 and TIM8 control register 2 (TIMx_CR2)这里控制寄存器的CCPC位,决定了CCP 的 Preloaded的使能,这里定义了COM的2种出现的形式:(COMG bit set or rising edge detected on TRGI, depending on the CCUS bit).而CCUS里面的定义,则是对上述使能做更新的选择:事件产生寄存器TIM1 and TIM8 event generation register (TIMx_EGR)也就是COMGBit 5 COMG: Capture/Compare control update generation1: When CCPC bit is set, it allows to update CCxE, CCxNE and OCxM bitsCCPC预设值使能后,COM的相关使能位可以通过预设先设定好,而这三个通道恰恰就是决定了互补的输出波形,这些预设值在COM的EVENT的时候给到实际的shadow寄存器。The preload bits are transferred to the shadow bits at the COM commutation event. The user can thus program in advance (提前预设)the configuration for the next step and change the configuration of all the channels at the same time.COM can be generated by software by setting the COM bit in the TIMx_EGR register or by hardware (on TRGI rising edge).COM 的EVENT设定值可以是软件设定TIMx_EGR来实现,也可以 由硬件上升沿触发决定。EVENT发生的时候,会更新状态寄存器A flag is set when the COM event occurs (COMIF bit in the TIMx_SR register),Bit 5 COMIF: COM interrupt flagThis flag is set by hardware on COM event (when Capture/compare Control bits - CCxE, CCxNE, OCxM - have been updated). It is cleared by software.0: No COM event occurred.1: COM interrupt pending. 同时也可以产生中断:which can generate an interrupt (if the COMIE bit is set in the TIMx_DIER register) or a DMA request(if the COMDE bit is set in the TIMx_DIER register).Bit 5 COMIE: COM interrupt enable0: COM interrupt disabled1: COM interrupt enabledFigure 91 describes the behavior of the OCx and OCxN outputs when a COM event occurs,in 3 different examples of programmed configurations.Example 1:1 CO1M = 100 : OC1REF 为低电平 预设值2 CC1NE = 0, 那么 OCXN 的互补输出被关闭了3 CC1E = 1,OC1 的输出依据OCXREF的输出,再结合MIX的Table组合:当COM = 1 ,也就是,TIMx_EGR 的 COMG 更新的时候COM EVENT 事件产生,同时更新设置,那么OC1REF force low,OC1的输出被拉倒低电平Example 2:和例子1不同的是,CC1NE的值设为1,这样互补通道打开,同时OC1M设为1,那么OC1REF 被Force to High 给到OC1如果之前OC1REF就是高,那么他是不变的,互补输出通道则由原来的LOW改为和OC1REF一致为高,所有的这些变动,都是在COM TO 1的时候生效,这个和SAMPLE1 一致,仔细看这个例子,前面互补输出的通道都是正常的,到COM TO 1 触发之后,OC1N的通道就一直未低电平了,DISABLE。该例子给出了OC1REF的两个互补波形,而且还带死区的Delay有道云笔记2021-11-16 15:30:49
STM32 - 定时器的设定 - 基础- 07 - 6-step PWM generation - 6步长PWM的产生 - COM Event的解释 前言:本节主要讲互补输出的步长设定问题,同时引入了一个重要的参数COM,这个再诸多STM32的手册里面都过于分散,在本文有一个比较完备的小结: When complementary outputs are used on a channel, preload bits are available on the OCxM, CCxE and CCxNE bits.互补输出主要由以下三个可以预设的设定决定:1 OC1M,OC1通道的输出模式,首先有OC1REF的模式决定,OC1REF会接到OC1 、OC1N然后,在OC1这里进行第二次设置,这里的设置又包括比较复杂的一组设定,有一个表:COM:(COM COMMUTATION交换 EVENT)or (Capture/Compare control update)COM的引入:提到COM之前,我们先看:定时器的控制寄存器2,里面的CCPC,CCUS控制位TIM1 and TIM8 control register 2 (TIMx_CR2)这里控制寄存器的CCPC位,决定了CCP 的 Preloaded的使能,这里定义了COM的2种出现的形式:(COMG bit set or rising edge detected on TRGI, depending on the CCUS bit).而CCUS里面的定义,则是对上述使能做更新的选择:事件产生寄存器TIM1 and TIM8 event generation register (TIMx_EGR)也就是COMGBit 5 COMG: Capture/Compare control update generation1: When CCPC bit is set, it allows to update CCxE, CCxNE and OCxM bitsCCPC预设值使能后,COM的相关使能位可以通过预设先设定好,而这三个通道恰恰就是决定了互补的输出波形,这些预设值在COM的EVENT的时候给到实际的shadow寄存器。The preload bits are transferred to the shadow bits at the COM commutation event. The user can thus program in advance (提前预设)the configuration for the next step and change the configuration of all the channels at the same time.COM can be generated by software by setting the COM bit in the TIMx_EGR register or by hardware (on TRGI rising edge).COM 的EVENT设定值可以是软件设定TIMx_EGR来实现,也可以 由硬件上升沿触发决定。EVENT发生的时候,会更新状态寄存器A flag is set when the COM event occurs (COMIF bit in the TIMx_SR register),Bit 5 COMIF: COM interrupt flagThis flag is set by hardware on COM event (when Capture/compare Control bits - CCxE, CCxNE, OCxM - have been updated). It is cleared by software.0: No COM event occurred.1: COM interrupt pending. 同时也可以产生中断:which can generate an interrupt (if the COMIE bit is set in the TIMx_DIER register) or a DMA request(if the COMDE bit is set in the TIMx_DIER register).Bit 5 COMIE: COM interrupt enable0: COM interrupt disabled1: COM interrupt enabledFigure 91 describes the behavior of the OCx and OCxN outputs when a COM event occurs,in 3 different examples of programmed configurations.Example 1:1 CO1M = 100 : OC1REF 为低电平 预设值2 CC1NE = 0, 那么 OCXN 的互补输出被关闭了3 CC1E = 1,OC1 的输出依据OCXREF的输出,再结合MIX的Table组合:当COM = 1 ,也就是,TIMx_EGR 的 COMG 更新的时候COM EVENT 事件产生,同时更新设置,那么OC1REF force low,OC1的输出被拉倒低电平Example 2:和例子1不同的是,CC1NE的值设为1,这样互补通道打开,同时OC1M设为1,那么OC1REF 被Force to High 给到OC1如果之前OC1REF就是高,那么他是不变的,互补输出通道则由原来的LOW改为和OC1REF一致为高,所有的这些变动,都是在COM TO 1的时候生效,这个和SAMPLE1 一致,仔细看这个例子,前面互补输出的通道都是正常的,到COM TO 1 触发之后,OC1N的通道就一直未低电平了,DISABLE。该例子给出了OC1REF的两个互补波形,而且还带死区的Delay有道云笔记2021-11-16 15:30:49 -
STM32 - 高级定时器的设定 - 基础-05 - 输出波形控制 The advanced-control timers (TIM1 and TIM8) can output two complementary(互补) signals and manage the switching-off and the switching-on instants of the outputs. This time is generally known as dead-time and it has to be adjust it depending on the devices connected to the outputs and their characteristics (intrinsic delays of level-shifters, delays due to power switches...)User can select the polarity of the outputs (main output OCx or complementary OCxN) independently for each output.This is done by writing to the CCxP and CCxNP bits in the TIMx_CCER register.TIMx_CCER 使能控制寄存器,控制CCxP 、CCxNP ,Bit 1 CC1P: Capture/Compare 1 output polarityCC1 channel configured as output:0: OC1 active high1: OC1 active lowBit 3 CC1NP: Capture/Compare 1 complementary output polarity0: OC1N active high.1: OC1N active low.The complementary signals OCx and OCxN are activated by a combination of several control bits:the CCxE and CCxNE bits in the TIMx_CCER registerOC/OCN输出使能控制Bit 0 CC1E: Capture/Compare 1 output enableCC1 channel configured as output:0: Off - OC1 is not active. OC1 level is then function of MOE, OSSI, OSSR, OIS1, OIS1N and CC1NE bits.1: On - OC1 signal is output on the corresponding output pin depending on MOE, OSSI, OSSR, OIS1, OIS1N and CC1NE bits.Bit 2 CC1NE: Capture/Compare 1 complementary output enable0: Off - OC1N is not active. OC1N level is then function of MOE, OSSI, OSSR, OIS1, OIS1N and CC1E bits.1: On - OC1N signal is output on the corresponding output pin depending on MOE, OSSI, OSSR, OIS1, OIS1N and CC1E bits.and the MOE, OISx, OISxN, OSSI and OSSR bits in the TIMx_BDTR TIM1 and TIM8 break and dead-time register (TIMx_BDTR)Bit 15 MOE: Main output enableThis bit is cleared asynchronously by hardware as soon as the break input is active. It is set by software or automatically depending on the AOE bit. It is acting only on the channels which are configured in output.0: OC and OCN outputs are disabled or forced to idle state.1: OC and OCN outputs are enabled if their respective enable bits are set (CCxE, CCxNE in TIMx_CCER register).See OC/OCN enable description for more details (Section 14.4.9: TIM1 and TIM8 capture/compare enable register (TIMx_CCER)).Bit 11 OSSR: Off-state selection for Run modeThis bit is used when MOE=1 on channels having a complementary output which are configured as outputs. OSSR is not implemented if no complementary output is implemented in the timer.See OC/OCN enable description for more details (Section 14.4.9: TIM1 and TIM8 capture/compare enable register (TIMx_CCER)).0: When inactive, OC/OCN outputs are disabled (OC/OCN enable output signal=0).1: When inactive, OC/OCN outputs are enabled with their inactive level as soon as CCxE=1or CCxNE=1. Then, OC/OCN enable output signal=1Bit 10 OSSI: Off-state selection for Idle modeThis bit is used when MOE=0 on channels configured as outputs.See OC/OCN enable description for more details (Section 14.4.9: TIM1 and TIM8 capture/compare enable register (TIMx_CCER)).0: When inactive, OC/OCN outputs are disabled (OC/OCN enable output signal=0).1: When inactive, OC/OCN outputs are forced first with their idle level as soon as CCxE=1 or CCxNE=1. OC/OCN enable output signal=1)Bits 7:0 DTG[7:0]: Dead-time generator setupThis bit-field defines the duration of the dead-time inserted between the complementary outputs. DT correspond to this duration.DTG[7:5]=0xx => DT=DTG[7:0]x tdtg with tdtg=tDTS.DTG[7:5]=10x => DT=(64+DTG[5:0])xtdtg with Tdtg=2xtDTS.DTG[7:5]=110 => DT=(32+DTG[4:0])xtdtg with Tdtg=8xtDTS.DTG[7:5]=111 => DT=(32+DTG[4:0])xtdtg with Tdtg=16xtDTS.Example if TDTS=125ns (8MHz), dead-time possible values are:0 to 15875 ns by 125 ns steps,16 us to 31750 ns by 250 ns steps,32 us to 63us by 1 us steps,64 us to 126 us by 2 us stepsand TIMx_CR2 registers.for more details. In particular, the dead-time is activated when switching to the IDLE state (MOE falling down to 0). Dead-time insertion is enabled by setting both CCxE and CCxNE bits, and the MOE bit if the break circuit is present. DTG[7:0] bits of the TIMx_BDTR register are used to control the dead-time generation for all channels.From a reference waveform OCxREF, it generates 2 outputs OCx and OCxN. If OCx and OCxN are active high:• The OCx output signal is the same as the reference signal except for the rising edge, which is delayed relative to the reference rising edge.(见下面分析)• The OCxN output signal is the opposite of the reference signal except for the rising edge, which is delayed relative to the reference falling edge.(见下面分析)If the delay is greater than the width of the active output (OCx or OCxN) then the corresponding pulse is not generated.The following figures show the relationships between the output signals of the dead-time generator and the reference signal OCxREF. (we suppose CCxP=0, CCxNP=0, MOE=1, CCxE=1 and CCxNE=1 in these examples)CC1P=0 ----> 0: OC1 active high CC1NP =0 ----> : 0: OC1N active high.MOE=1 ----> 1: OC and OCN outputs are enabledCCxE=1 ----> 1: On - OC1 signal is output on the corresponding output pin depending on MOE, OSSI, OSSR, OIS1, OIS1N and CC1NE bits.CCxNE=1 ----> 1: On - OC1N signal is output on the corresponding output pin depending on MOE, OSSI, OSSR, OIS1, OIS1N and CC1E bits.笔者案:我们现在依据上面的这个例子来分析一下:• The OCx output signal is the same as the reference signal except for the rising edge, which is delayed relative to the reference rising edge首先看OCX的输出,他应该是完全和OCXREF的输出一致,除了,上升沿会增加死区延时:蓝色为相同部分,后面上升沿往后移动了一格设定的delay时间。• The OCxN output signal is the opposite of the reference signal except for the rising edge, which is delayed relative to the reference falling edge.(见下面分析)The dead-time delay is the same for each of the channels and is programmable with the DTG bits in the TIMx_BDTR register.delay的时间通过DTG来控制。Re-directing OCxREF to OCx or OCxNIn output mode (forced, output compare or PWM), OCxREF can be re-directed to the OCx output or to OCxN output by configuring the CCxE and CCxNE bits in the TIMx_CCER register.将输出的OCXREF的波形可以转接到OCX 等其他端口,This allows the user to send a specific waveform (such as PWM or static active level) on one output while the complementary remains at its inactive level. Other possibilities are to have both outputs at inactive level or both outputs active and complementary with dead-time.Note: When only OCxN is enabled (CCxE=0, CCxNE=1), it is not complemented and becomes active as soon as OCxREF is high. For example, if CCxNP=0 then OCxN=OCxRef. On the other hand, when both OCx and OCxN are enabled CCxE=CCxNE=1) OCx becomes active when OCxREF is high whereas OCxN is complemented and becomes active whenOCxREF is low.有道云笔记2021-11-15 19:29:53
-
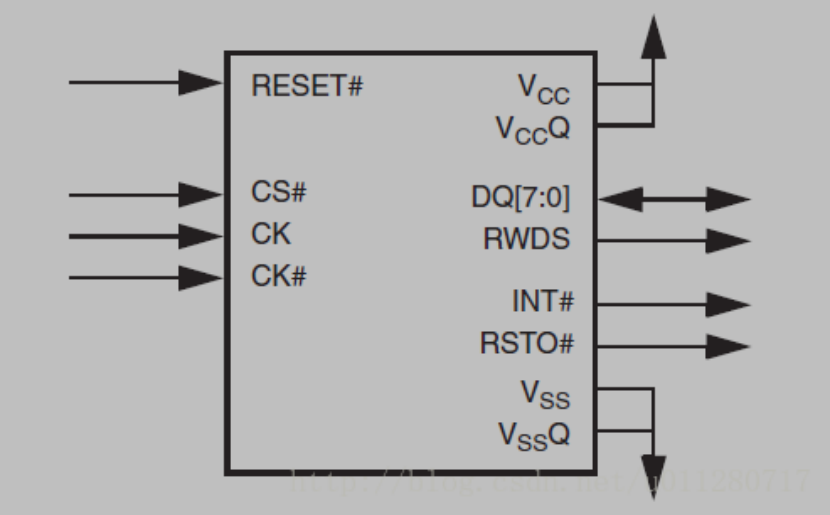
HyperBus Nor Flash小记 InterfaceMandatory I/O SummaryOptional I/O SummaryProtocal当HyperBus处于Idle状态(CK=Low & CK#=High)时,CS#从High变成Low,hyperbus的传输开始进行。最前面的三个时钟周期传输3个word的Command/Address(CA0, CA1, CA2),这三个word的CA用来决定这个传输一些特性。PS:这里面的word是2个byte,就是16bit。一个时钟周期是指两个clock,至于为什么这样定,我也不知道,Hyperbus的specification就是这么定的所以3个word的CA信息一共是48个bit。当传输完CA信息后,bus上需要传输一些dummy clock初始化RWDS信号。RWDS就是CK加了一些延迟的信号,用作高速读操作时的DQS。当数据传输开始,读数据是在RWDS的边沿进行采样,写数据是在Single-ended clock(即3.0V的CK)的边沿采样,或者在Differential clock(即1.8V CK和CK#)模式下,在CK和CK#交叉点进行数据采样。一旦完成数据传输,host就可以把CS#拉高并且把clock置为IDLE状态。当clock已经是IDLE状态了,拉嘎CS#就能结束一次传输。读时序下面贴出一个实际的读数据的时序, 读数据的地址是0x400。CA[48:0] = 0xA000004000。其中CA[47] = 1代表读,CA[46] = 0, CA[45] =1代表linear burst,ROW & Upper Column Address = 0x0000040 = 0x400 / 0x10, Lower Column Address=0x0 = 0x400 % 0x10。在插入了一些dummy的时钟周期后,进行了数据的采集。其中, 插入在CA和数据之间的dummy clock的个数是随设备不同而不同的,同时也跟Hyperbus的采样频率有关,这个需要参考不同的Hyberbus设备的手册才能知道。写时序写时序分为Write Transactions with Initial Latency和Write Transactions without Initial Latency。由于我并没有涉及太多的写设备的工作,所以这里就不多讲了。有Initial Latency的时序跟读时序差不多,只不过需要注意的是采样的时钟并不是RWDS即DQS,而是CK和CK#。而没有Initial Latency的就更简单了,直接数据就跟在CA后面,下面贴出官方Specification的是时序图。有道云笔记2021-11-08 11:34:45
-
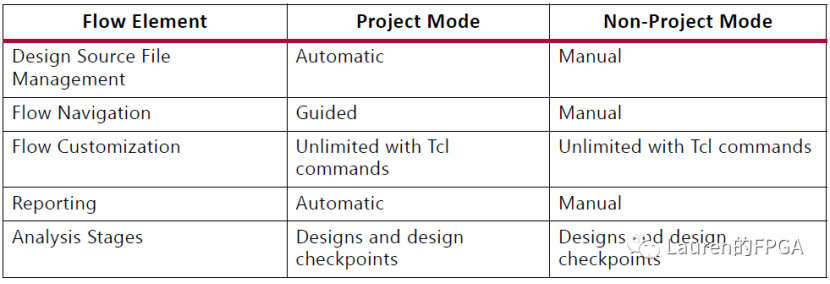
用Tcl实现Vivado设计全流程 Vivado有两种工作模式:project模式和non-project模式。这两种模式都可以借助VivadoIDE或Tcl命令来运行。相比之下,VivadoIDE给project模式提供了更多的好处,而Tcl命令使得non-project模式运行起来更简单。在project模式下,Vivado会自动管理整个设计流程和文件数据。最直接的体现是在Vivado左侧导航Flow Navigator下会显示所有流程,从设计输入到最终生成bit文件。同时,Vivado会自动创建相应的文件目录,生成相应的文件例如dcp以及相应的报告。Non-project模式是一种内存编译流程。用户可以从指定位置读取文件到内存中,然后进行编译。可以逐步执行每个步骤如综合、布局、布线等,可以根据需求设定编译参数。这一切都可以通过Tcl命令完成。显然,non-project模式下,用户可以通过Tcl命令管理设计文件和设计流程,体现了该模式的主要优势即用户对设计流程有完全的掌控力。Project模式和non-project模式的主要区别如下图所示。不难看出,project模式下更多的管理、操作都是“自动”完成的;而non-project模式下,则是“手工”完成的。从Tcl命令的角度而言,project和non-project模式也是不同的,如下图所示。Project模式下用到的Tcl命令是一种打包的命令,例如添加设计文件需用add_files,文件可以是HDL(包括VHDL,Verilog或SystemVerilog),可以是约束文件(包括.xdc或.tcl),可以是网表文件(可以是dcp,ngc或edif)等。Implementation时,命令launch_runs就可以按照指定的策略完成所有的步骤,包括生成相应的DCP。Non-project模式下用到的Tcl命令是分立的,例如,读入设计文件,如果是VHDL,需要用到read_vhdl;如果是Verilog,需要用到read_verilog,如果是.xdc,需要用到read_xdc;如果是DCP,需要用到read_checkpoint;如果是EDIF,需要用到read_edif。而在implementation时,需要分别用到opt_design、place_design、phys_opt_design和route_design等。因为Tcl命令使得non-project模式更能简单地运行,这里我们将介绍如何通过Tcl命令在non-project模式下完成所有步骤。有道云笔记2021-11-04 16:41:15
-
Vscode自动生成verilog例化 前言veirlog模块例化的时候,辣么多的信号端子,手动例化又慢又容易出错,葵花妈妈开课啦,孩子手残老犯错怎么办?当然是脚本一劳永逸,妈妈再也不担心手残党。流程(1)在vscode中安装如下插件。(2)在电脑中安装python3以上的环境。下载地址:https://www.python.org/downloads/release/python-373/安装记得一定要勾选添加路径,记得管理员安装。重启你的电脑。在cmd窗口输入python即可验证是否安装成功!(3)安装chardet。为确保插件可用,这个需要安装。参考链接:https://blog.csdn.net/sinat_28631741/article/details/80483064方式一 源码按照: 第一步:下载压缩文件,例如: 'chardet-3.0.4.tar.gz'; 第二步:解压文件到python安装位置下的‘site-packages’目录下,例如:‘D:\python2.7\Lib\site-packages’; 第三步:打开终端命令窗口,进入解压的‘chardet’目录下,执行命令:python setup.py install (4)修改插件的原始py文件,觉得开发者的py有瑕疵,让帅气的同事重新整了个,把以下代码替换进原始py文件即可。在打开v文件的vscode下按ctrl+p,输入instance可出现下述界面。替换此py文件的代码即可。#! /usr/bin/env python ''' vTbgenerator.py -- generate verilog module Testbench generated bench file like this: fifo_sc #( .DATA_WIDTH ( 8 ), .ADDR_WIDTH ( 8 ) ) u_fifo_sc ( .CLK ( CLK ), .RST_N ( RST_N ), .RD_EN ( RD_EN ), .WR_EN ( WR_EN ), .DIN ( DIN [DATA_WIDTH-1 :0] ), .DOUT ( DOUT [DATA_WIDTH-1 :0] ), .EMPTY ( EMPTY ), .FULL ( FULL ) ); Usage: python vTbgenerator.py ModuleFileName.v ''' import random import re import sys from queue import Queue import chardet def delComment(Text): """ removed comment """ single_line_comment = re.compile(r"//(.*)$", re.MULTILINE) multi_line_comment = re.compile(r"/\*(.*?)\*/", re.DOTALL) Text = multi_line_comment.sub('\n', Text) Text = single_line_comment.sub('\n', Text) return Text def delBlock(Text): """ removed task and function block """ Text = re.sub(r'\Wtask\W[\W\w]*?\Wendtask\W', '\n', Text) Text = re.sub(r'\Wfunction\W[\W\w]*?\Wendfunction\W', '\n', Text) return Text def findName(inText): """ find module name and port list""" p = re.search(r'([a-zA-Z_][a-zA-Z_0-9]*)\s*', inText) mo_Name = p.group(0).strip() return mo_Name def paraDeclare(inText, portArr): """ find parameter declare """ pat = r'\s' + portArr + r'\s[\w\W]*?[;,)]' ParaList = re.findall(pat, inText) return ParaList def portDeclare(inText, portArr): """find port declare, Syntax: input [ net_type ] [ signed ] [ range ] list_of_port_identifiers return list as : (port, [range]) """ port_definition = re.compile( r'\b' + portArr + r''' (\s+(wire|reg|logic|interface)\s+)* (\s*signed\s+)* (\s*\[.*?:.*?\]\s*)* (?P<port_list>.*?) (?= \binput\b | \boutput\b | \binout\b | ; | \) ) ''', re.VERBOSE | re.MULTILINE | re.DOTALL ) pList = port_definition.findall(inText) t = [] for ls in pList: if len(ls) >= 2: t = t + portDic(ls[-2:]) return t def portDic(port): """delet as : input a =c &d; return list as : (port, [range]) """ pRe = re.compile(r'(.*?)\s*=.*', re.DOTALL) pRange = port[0] pList = port[1].split(',') pList = [i.strip() for i in pList if i.strip() != ''] pList = [(pRe.sub(r'\1', p), pRange.strip()) for p in pList] return pList def formatPort(AllPortList, isPortRange=1): PortList = AllPortList str = '' if PortList != []: l1 = max([len(i[0]) for i in PortList])+2 l3 = max(18, l1) strList = [] str = ',\n'.join([' ' * 4 + '.' + i[0].ljust(l3) + '(' + (i[0]) + ')' for i in AllPortList]) strList = strList + [str] str = ',\n\n'.join(strList) return str def formatDeclare(PortList, portArr, initial=""): str = '' if PortList != []: str = '\n'.join([portArr.ljust(4) + ' '+(i[1]+min(len(i[1]), 1)*' ' + i[0]) + ';' for i in PortList]) return str def formatPara(ParaList): paraDec = '' paraDef = '' if ParaList != []: s = '\n'.join(ParaList) pat = r'([a-zA-Z_][a-zA-Z_0-9]*)\s*=\s*([\w\W]*?)\s*[;,)]' p = re.findall(pat, s) l1 = max([len(i[0]) for i in p]) l2 = max([len(i[1]) for i in p]) paraDec = '\n'.join(['parameter %s = %s;' % (i[0].ljust(l1 + 1), i[1].ljust(l2)) for i in p]) paraDef = '#(\n' + ',\n'.join([' .' + i[0].ljust(l1 + 1) + '( ' + i[1].ljust(l2)+' )' for i in p]) + ')\n' return paraDec, paraDef def portT(inText, ioPadAttr): x = {} count_list = [] order_list = [] for i in ioPadAttr: p = port_index_list(inText, i) for j in p: count_list.append(j) x[j] = i count_list = quick_sort(count_list, 0, len(count_list)-1) for c in count_list: order_list.append(x.get(c)) return order_list def quick_sort(myList, start, end): if start < end: i, j = start, end base = myList[i] while i < j: while (i < j) and (myList[j] >= base): j = j - 1 myList[i] = myList[j] while (i < j) and (myList[i] <= base): i = i + 1 myList[j] = myList[i] myList[i] = base quick_sort(myList, start, i - 1) quick_sort(myList, j + 1, end) return myList def formatPort_order(padAttr, orderList): for p in padAttr: q = Queue() for i in padAttr.get(p): q.put(i) padAttr[p] = q AllPortList = [] for o in orderList: AllPortList.append(padAttr.get(o).get()) return AllPortList def port_index_list(intext, text): l = [] t = intext index = t.find(text) while index > -1: t = t.replace(text, random_str(len(text)), 1) l.append(index) index = t.find(text) return l def random_str(size): s = '' for i in range(size): s += str(random.randint(0, 9)) return s def getPortMap(AllPortList, ioPadAttr): if len(AllPortList) != len(ioPadAttr): return p_map = {} for i in range(len(AllPortList)): p_map[ioPadAttr[i]] = AllPortList[i] return p_map def writeTestBench(input_file): """ write testbench to file """ with open(input_file, 'rb') as f: f_info = chardet.detect(f.read()) f_encoding = f_info['encoding'] with open(input_file, encoding=f_encoding) as inFile: inText = inFile.read() # removed comment,task,function inText = delComment(inText) inText = delBlock(inText) # moduel ... endmodule # moPos_begin = re.search(r'(\b|^)module\b', inText).end() moPos_end = re.search(r'\bendmodule\b', inText).start() inText = inText[moPos_begin:moPos_end] name = findName(inText) paraList = paraDeclare(inText, 'parameter') paraDec, paraDef = formatPara(paraList) ioPadAttr = ['input', 'output', 'inout','interface'] orlder = portT(inText, ioPadAttr) input = portDeclare(inText, ioPadAttr[0]) output = portDeclare(inText, ioPadAttr[1]) inout = portDeclare(inText, ioPadAttr[2]) interface = portDeclare(inText, ioPadAttr[3]) portList = formatPort(formatPort_order( getPortMap([input, output, inout,interface], ioPadAttr), orlder)) input = formatDeclare(input, 'reg') output = formatDeclare(output, 'wire') inout = formatDeclare(inout, 'wire') interface = formatDeclare(interface, 'wire') # write Instance # module_parameter_port_list if(paraDec != ''): print("// %s Parameters\n%s\n" % (name, paraDec)) # list_of_port_declarations #print("// %s Inputs\n%s\n" % (name, input)) #print("// %s Outputs\n%s\n" % (name, output)) #if(inout != ''): # print("// %s Bidirs\n%s\n" % (name, inout)) print("\n") # UUT print("%s %s inst_%s (\n%s\n);" % (name, paraDef, name, portList)) if __name__ == '__main__': writeTestBench(sys.argv[1])(5)享受一下吧。比如我们有如下代码:crtl+p,输入instance,按回车即可。 复制粘贴大发好。以上。转载于:https://www.cnblogs.com/kingstacker/p/9944259.html有道云笔记2021-11-02 11:37:58