搜索到
344
篇与
的结果
-
 ReRAM将如何影响未来的存储格局? 助力科技创业者的半导体行业观察2021年04月20日08:59存储器是现代信息系统最关键的组件之一,已经形成主要由DRAM与NAND Flash构成的超千亿美元的市场。随着万物智联时代的到来,人工智能、智能汽车等新兴应用场景对存储提出了更高的性能要求,促使新型存储器迅速发展,影响未来存储器市场格局。我国正在大力发展存储产业,除了在传统存储器上努力实现追赶,也在提前布局新型存储器,这将是未来存储产业生态的重要部分。新型存储器究竟指什么,有哪些技术原理,竞争格局如何,未来发展前景会是怎样?本期「云岫研究」,我们聚焦于新型存储器中的阻变存储器 (ReRAM或RRAM,Resistive RAM),并通过分析其技术、应用场景与模式,得出如下判断:1.万物智联时代,需要速度、功耗、容量等性能更强的新型存储器;2.对比四大新型存储器,ReRAM在密度、工艺制程、成本和良率上具备明显优势;3.AIoT、智能汽车、数据中心、AI计算(存算一体)将是ReRAM的重要发展机遇;4.IDM模式是ReRAM厂商的最佳选择;5.新型存储器是中国实现存储领域弯道超车的最佳机会。 存储器是半导体最大细分市场新型存储器是未来选择 存储器是半导体产业的风向标和最大细分市场,约占半导体产业的三分之一。智能时代的到来,将引起存储行业的新一轮爆发。据YOLE统计,2019年以来,存储器成为半导体增速最快的细分行业,总体市场空间将从2019年的1110亿美元增长至2025年的1850亿美元,年复合增长率为9%。细分市场中,新型存储器市场增速最快,将从5亿美元增长到40亿美元,年复合增长率达到42%,发展潜力巨大。图1:全球存储器市场规模及增速(资料来源:YOLE) 存储器可以按照断电是否能保存数据分为两类。图2:存储器分类(云岫资本整理)第一类易失性存储器是以动态随机存取存储器(DRAM)和静态随机存取存储器(SRAM)代表的易失性存储器,二者均具备高读写速度。其中SRAM速度高于DRAM,但密度低于DRAM,这是因为一个DRAM存储单元仅需一个晶体管和一个小电容,而每个SRAM单元需要四到六个晶体管。其共同的缺点是容量较低且成本高,一般分别用作主存和缓存。第二类非易失性存储器包括以NOR FLASH和NAND FLASH为代表的传统存储器和四种新型存储器。NOR FLASH的容量较小且写入速度极低,但读速较快,具备芯片内执行的特点,适合低容量、快速随机读取访问的场景;NAND FLASH的容量大成本较低,但读写速度极低,一般用于大容量的数据存储。除FRAM以外的新型存储器均是通过阻值高低变化实现“0”“1”数据存储,四种新型存储器均具备非易失性,断电后仍可以保存数据,相比传统存储器在读写速度、功耗、寿命等方面各有优势。 存储器的发展取决于应用场景的变化。图3:存储的过去、现在与未来——场景应用决定市场趋势(云岫资本整理)20世纪70年代起,DRAM进入商用市场,并以其极高的读写速度成为存储领域最大分支市场;功能手机出现后,迎来NOR Flash市场的爆发;进入PC时代,人们对于存储容量的需求越来越大,低成本、高容量的NAND Flash成为最佳选择。智能化时代里,万物智联,存储行业市场空间将进一步加大,对数据存储在速度、功耗、容量、可靠性层面也将提出更高要求。而DRAM虽然速度快,但功耗大、容量低、成本高,且断电无法保存数据,使用场景受限;NOR Flash和NAND Flash读写速度低,存储密度受限于工艺制程。市场亟待能够满足新场景的存储器产品,性能有着突破性进展的新型存储器即将迎来爆发期。对比四种新型存储器ReRAM在密度、工艺制程、成本和良率上具备明显优势 目前,新型存储器主要有4种:相变存储器(PCM),以Intel和Micron联合研发的3D Xpoint为代表;铁电存储器(FeRAM),代表公司有Ramtron和Symetrix;磁性存储器(MRAM),代表公司是美国Everspin;阻变存储器(ReRAM),代表公司有松下、Crossbar和昕原半导体。表1:4种新型存储器参数对比(资料来源:Objective Analysis) 1.相变存储器(PCM或PCRAM,Phase-change RAM)PCM的原理是通过改变温度,让相变材料在低电阻结晶(导电)状态与高电阻非结晶(非导电)状态间转换。图4:PCM原理(资料来源:Intel)PCM虽然读写速度比NAND Flash有所提高,但其RESET后的冷却过程需要高热导率,会带来更高功耗,且由于其存储原理是利用温度实现相变材料的阻值变化,所以对温度十分敏感,无法用在宽温场景。其次,为了使相变材料兼容CMOS工艺,PCM必须采取多层结构,因此存储密度过低,在容量上无法替代NAND Flash。除此之外,成本和良率也是瓶颈之一。Intel和Samsung于2006年生产了第一款商用PCM芯片。2015年,Intel和Micron合作开发了名为3D XPoint的存储技术,该技术也是PCM的一种。2018年双方结束了联合开发工作,2021年3月,Micron宣布停止所有基于3D XPoint技术产品的进一步开发。 2.铁电存储器 (FRAM或FeRAM,Ferroelectric RAM)FRAM并非使用铁电材料,只是由于存储机制类似铁磁存储的滞后行为,因此得名。FRAM晶体材料的电压-电流关系具有可用于存储的特征滞后回路。图5:FRAM原理(资料来源:Objective Analysis)FRAM优势在于读写速度快、寿命良好,但其存储单元基于双晶体管,双电阻器单元,单元尺寸至少是DRAM的两倍,存储密度受限,成本较高。并且它的读取是破坏性的,每次读取后必须通过后续写入来抵消,以将该位的内容恢复到其原始状态。材料方面,目前铁电晶体材料PZT(锆钛酸铅)和SBT(钽酸锶铋)都存在疲劳退化、污染环境等问题,尚未找到完美商业化的材料。目前,Ramtron(归属于Cypress)和Symetrix两家公司正主导FRAM的开发。 3.磁性存储器 (MRAM,Magnetic RAM)目前主流的MRAM技术是STT MRAM,使用隧道层的“巨磁阻效应”来读取位单元,当该层两侧的磁性方向一致时为低电阻,当磁性方向相反时,电阻会变得很高。图6:MRAM原理(资料来源:Avalanche Technology)STT MRAM虽然性能较好,但临界电流密度和功耗仍需进一步降低,目前MRAM的存储单元尺寸仍较大且不支持堆叠,工艺较为复杂,大规模制造难以保证均一性,存储容量和良率爬坡缓慢。在工艺取得进一步突破之前,MRAM产品主要适用于容量要求低的特殊应用领域,以及新兴的IoT嵌入式存储领域。商业上,Everspin与Global Foundries合作,UMC与Avalanche Technology合作,推广STT-MRAM。 4.阻变存储器 (ReRAM或RRAM,Resistive RAM)阻变存储器全称是电阻式随机存取存储器,是以非导性材料的电阻在外加电场作用下,在高阻态和低阻态之间实现可逆转换为基础的非易失性存储器。ReRAM包括许多不同的技术类别,比如氧空缺存储器(OxRAM,Oxygen Vacancy Memories)、导电桥存储器 (CBRAM,Conductive Bridge Memories)、金属离子存储器(Metal Ion Memories)以及纳米碳管 (Carbon Nano-tubes)。图7:ReRAM原理(资料来源:Objective Analysis) ReRAM的单元面积极小,可做到4F²,读写速度是NAND FLASH的1000倍,同时功耗下降15倍。ReRAM工艺也更为简单。以Crossbar和昕原半导体为例,其采用对CMOS友善的材料,能够使用标准的CMOS工艺与设备,对产线无污染,整体制造成本低,可以很容易地让半导体代工厂具备ReRAM的生产制造能力,这对于量产和商业化推动有很大优势。 图8:Crossbar的电阻切换机制和新型3D堆叠ReRAM(资料来源:Crossbar官网)上图是Crossbar的ReRAM结构设计,大致分为顶部电极,开关介质和底部电极三层结构,其电阻切换机制是:两个电极之间施加电压时,切换材料中将形成纳米细丝,通过细丝连接上下两个电极,改变转换层的电阻,细丝相连代表存储值“1”,细丝断裂代表存储值“0”。由于电阻切换机制基于金属导丝,因此Crossbar ReRAM单元非常稳定,能够承受从-40°C到125°C的温度波动,写周期为1M +,在85°C的温度下可保存10年。从密度、能效比、成本、工艺制程和良率各方面综合衡量,ReRAM存储器在目前已有的新型存储器中具备明显优势。ReRAM国内外发展现状 在商业化上,Crossbar、昕原半导体、松下、Adesto、Elpida、东芝、索尼、美光、海力士、富士通等厂商都在开展ReRAM的研究和生产,其中专注IP授权的Crossbar对于ReRAM的基础技术研发走在了前列。Crossbar研发了两种存储架构——1T1R和3D堆叠式架构,3D堆叠技术可实现存储级内存,内置选择器允许多种存储阵列配置,单个晶体管可以驱动数千个存储单元,可以组织成超密集的3D交叉点阵列,可堆叠并能够扩展到10nm以下,从而为单个裸片上的TB级存储铺平了道路。 在代工厂方面,中芯国际(SMIC)、台积电(TSMC)和联电(UMC)都已经将ReRAM纳入自己未来的发展版图中。根据公开信息,已量产的海外ReRAM存储器主要有Adesto的130nm CBRAM和松下的180nm ReRAM。松下(Panasonic)在2013年开始出货ReRAM,成为了世界第一家出货ReRAM的公司。接着,松下与富士通联合推出了第二代ReRAM技术,基于180nm工艺。而Adesto 一直在缓慢地出货低密度 CBRAM。国内,昕原半导体在Crossbar的基础上实现了技术核心升级和工艺制程的改进,实现28nm量产,并且已建成自己的首条量产线,拥有了垂直一体化存储器设计加制造的能力。兆易创新和Rambus宣布合作建立合资企业合肥睿科微(Reliance Memory),进行ReRAM技术的商业化,但目前还无量产消息。 ReRAM迎来四大发展机遇:AIoT、智能汽车、数据中心、AI计算1.AIoTAIoT指人工智能技术与物联网在实际应用中的落地融合。根据艾瑞咨询数据,2019 年中国 AIoT 产业总产值为3808 亿元,预计2022年将达7509亿元,年复合增长率达25.4%。AIoT需要数据的实时交互,因此不仅要求存储器低功耗,也需要高读写和低延迟。目前的NOR Flash存储密度低、容量小、功耗高,无法实现高写入速度。而ReRAM在保证读性能的情况下,写入速度可提升1000倍,同时可实现更高存储密度和十分低的功耗,未来将会是取代NOR Flash成为万物智联时代存储器的最佳选择。随着人与物交互信息越来越多,很多私人信息会被存储记录,物联网在带来生活便利的同时,也带来了潜在的数据安全隐患,针对物联网的攻击甚至可以通过设备传递到现实生活中带来难以想象的破坏。AIoT应用越来越多要求具备安全属性。然而,目前普遍的安全芯片+Nor Flash方案存在成本高、空间受限等痛点。PUF(Physically Unclonable Function,物理不可克隆函数)+新型存储器芯片有望成为解决智能设备存储与安全问题的主流方案。PUF是一种利用芯片在半导体生产过程中的工艺波动性来生成芯片唯一函数,能够做到一芯一密,可称之为“芯片指纹”。目前,昕原半导体设计了基于ReRAM存储器的PUF芯片,可以同时具备存储加安全两个功能。2.智能汽车汽车电子根据功能可分为车身控制系统(ECU)、安全系统、娱乐设备、底盘控制、高级驾驶辅助系统(ADAS)等,都需要半导体器件实现相关功能,包括存储器、传感器、光电器件、射频器件、功率器件等。根据Counterpoint Research预测,未来单车存储容量将达到2TB-11TB,一辆L4/L5级自动驾驶汽车至少需要74GB DRAM和1TB NAND。据IHS预测,全球汽车存储IC市场规模2025年约为83亿美元。智能汽车对存储器的要求不仅在于温度和可靠性。控制系统需要智能化实时决策;ADAS系统时刻产生大量图像数据;娱乐系统需要更加智能来提升用户体验;能耗对于智能汽车也是关键性因素……这些都要求存储器具备大量的数据实时吞吐能力,保证存储稳定性和高能效比。传统的NOR Flash无法满足未来智能汽车对读写速度(特别是XIP程序执行效率)的要求;NAND Flash难以实现XIP片上的程序执行并且极慢;DRAM和SRAM容量有限,断电数据会丢失。新型存储器中,ReRAM不仅满足高读写速度和存储密度的要求,同时延迟可降低1000倍,可满足未来智能驾驶高实时数据吞吐量。安全性方面,ReRAM具备宽温和可靠性。未来有望出现高性能、高集成度、高稳定性和低功耗的车规ReRAM存储器。3.数据中心AI时代,数据呈现爆发式增长,越来越多的数据将在云端进行处理,根据思科预测,2021年全球将有1327EB数据存储在数据中心,6年复合增长率率高达41%。根据《2019-2020年中国IDC产业发展研究报告》预测,2022年中国数据中心市场规模将超过3200亿元。数据量的爆发催生对存储器新的增量市场和性能要求,据SUMCO预测,数据中心对SSD存储的需求将在2019年到2023年之间实现46%的复合增长。但目前数据中心存储器性能发展速度无法跟上计算需求,并且功耗仍是数据中心成本最高的因素之一。传统机械硬盘虽然寿命长成本低,但是读写速度极低且发热和噪声明显。DRAM虽速度较快但为易失性存储器,断电无法保存数据且成本极高,无法作为大量存储数据使用。而NAND读写速度仍较慢,另一方面功耗较高,性能和容量与工艺制程强相关。现有存储器无法跟上未来对数据高读写速度,低延迟,低功耗的需求。ReRAM相较NAND可提升100倍的读写性能,同时保持更低的功耗和高存储密度,有望解决未来数据中心高能效比,低延迟的需求,实现更高性能的AI数据中心。 4.AI计算(存算一体)人工智能是目前技术发展的重要趋势,根据沙利文咨询数据,2016-2024年人工智能的年均增长率达到33.98%,预计2024年将超过6157亿美元。而我国人工智能产业规模预计2024年将逼近8000亿元,约占全球总体产业规模的20%,复合增长率达到48.97%,大大超过全球平均水平。算力、算法、数据量是人工智能发展的三大基础要素,它们决定了AI计算的性能,这其中的两点都与存储相关:数据由存储器承载,数据量决定了AI计算模型的准确度;算力方面,未来对芯片计算性能和延迟性都提出了更高要求。目前的冯诺依曼架构,存储单元和计算单元独立分开,搬移数据的过程需要消耗大量时间和能量,并且由于处理器和存储器的工艺路线不同,存储器的数据访问速度难以跟上CPU的数据处理速度,性能已远远落后于处理器。所以,冯诺依曼架构在数据处理速度和能效比等方面存在天然限制,这被称为“存储墙”。存算一体架构通过将存储单元和计算单元融为一体,消除了数据访存带来的延迟和功耗,可以突破“存储墙”,实现更高的算力和更高的能效比。 图9:存算一体突破存储墙(云岫资本整理)目前存算一体有两种实现方式,第一种是基于易失性存储器DRAM和SRAM,但由于存储器制造工艺和逻辑计算单元的制造工艺不同,无法实现良好的融合,目前只能实现近存计算,仍存在存储墙问题,甚至因为互连问题可能还会带来性能损失。并且,因为SRAM和DRAM是易失性存储器,需要持续供电来保存数据,仍存在功耗和可靠性的问题。第二种是结合非易失性新型存储器,可以利用欧姆定律和基尔霍夫定律在阵列内完成矩阵乘法运算,而无需向芯片内移入和移出权重。新型存储器是通过阻值变化来存储数据,而存储器加载的电压等于电阻和电流的乘积,相当于每个单元可以实现一个乘法运算,再汇总相加便可以实现矩阵乘法,所以新型存储器天然具备存储和计算的属性。在这种情况下,同一单元就可以完成数据存储和计算,消除了数据访存带来的延迟和功耗,是真正意义上的存算一体。新型存储器中,ReRAM具有高集成密度、高开关比、高计算精度、高能效比和制造兼容CMOS工艺等优良特性,被认为是实现存算一体的最佳选择之一。、图10:新型存储器实现存算一体(Nature Nanotechnology) IDM模式是ReRAM厂商的最佳选择存储行业中,纯芯片设计公司难以摆脱对代工厂的依赖,不仅生产周期长、成本高,而且无法根据生产工艺做出适配性设计;而纯代工企业利润较低无法享受更多新技术红利。因此,目前世界前十大半导体公司中的4家存储公司,全部为IDM模式,拥有存储芯片设计加制造的全套能力。对于以ReRAM为代表的新型存储器而言,IDM模式不仅工艺和产能自主可控,同时可以不断进行迭代优化,通过高良率和高性能迅速筑起行业壁垒,是存储器行业发展最佳的商业模式。 新型存储器是中国实现存储领域弯道超车的最佳机会目前中国存储器市场国产化率极低,传统存储器先进技术均掌握在美国、韩国和日本手中,中国在最新产品性能上落后5-10年。三星、海力士和美光垄断了以DRAM为代表的易失性存储器市场,而以NAND为代表的非易失性存储器也被三星、铠侠、闪迪、美光和海力士垄断。而在ReRAM等新型存储器的发展上,中国与其他国家站在同一起跑线,都有机会出现下一个三星和海力士。在这中国存储产业突围的关键时期,一系列相关政策陆续出台,重点支持存储行业。国家“十四五”规划纲要中,在加强原创性引领性科技攻关方面,“先进存储技术升级”被列入“科技前沿领域攻关”重点领域;在加快推动数字产业化方面,《纲要》提到,培育壮大人工智能、大数据、区块链、云计算、网络安全等新兴数字产业,提升通信设备、核心电子元器件、关键软件等产业水平。图11:“十四五”规划纲要专栏2 科技前沿领域攻关2021年3月,临港新片区发布集成电路产业专项规划(2021-2025),提到要“在阻变存储器(ReRAM)等新兴领域实现增量发展”。图12:节选自《临港新片区集成电路产业专项规划(2021-2025)》目前,很多曾在世界顶尖企业担任高管的产业专家纷纷回国创业,不仅带来了先进技术和经验,也吸引了一批有志之士共同打造中国芯。天时地利人和之下,中国新型存储器未来可期! 参考资料:[1]Jim Handy. Objective Analysis White Paper : NEW MEMORIES FOR EFFICIENT COMPUTING Reducing Energy Consumption in Battery and Large-Scale Systems,2018.[2]Yu, Shimeng. Resistive Random Access Memory (RRAM)[J]. Synthesis Lectures on Emerging Engineering Technologies, 2016, 2(5):1-79.[3]刘明.半导体存储器技术[J].科技导报,2019, 037(003):62-65.[4]刘森, 刘琦. 阻变存储器发展现状[J]. 国防科技, 2016, 37(6).[5]国元证券.电子行业研究报告:存储芯片投资地图.[6]方正证券.汽车半导体系列专题报告——电车之忆:汽车存储芯片分布[7]Mahendra Pakala. AI时代推动存储器的创新与发展[J]. 中国电子商情(基础电子), 2019(10).—END—来自微信
ReRAM将如何影响未来的存储格局? 助力科技创业者的半导体行业观察2021年04月20日08:59存储器是现代信息系统最关键的组件之一,已经形成主要由DRAM与NAND Flash构成的超千亿美元的市场。随着万物智联时代的到来,人工智能、智能汽车等新兴应用场景对存储提出了更高的性能要求,促使新型存储器迅速发展,影响未来存储器市场格局。我国正在大力发展存储产业,除了在传统存储器上努力实现追赶,也在提前布局新型存储器,这将是未来存储产业生态的重要部分。新型存储器究竟指什么,有哪些技术原理,竞争格局如何,未来发展前景会是怎样?本期「云岫研究」,我们聚焦于新型存储器中的阻变存储器 (ReRAM或RRAM,Resistive RAM),并通过分析其技术、应用场景与模式,得出如下判断:1.万物智联时代,需要速度、功耗、容量等性能更强的新型存储器;2.对比四大新型存储器,ReRAM在密度、工艺制程、成本和良率上具备明显优势;3.AIoT、智能汽车、数据中心、AI计算(存算一体)将是ReRAM的重要发展机遇;4.IDM模式是ReRAM厂商的最佳选择;5.新型存储器是中国实现存储领域弯道超车的最佳机会。 存储器是半导体最大细分市场新型存储器是未来选择 存储器是半导体产业的风向标和最大细分市场,约占半导体产业的三分之一。智能时代的到来,将引起存储行业的新一轮爆发。据YOLE统计,2019年以来,存储器成为半导体增速最快的细分行业,总体市场空间将从2019年的1110亿美元增长至2025年的1850亿美元,年复合增长率为9%。细分市场中,新型存储器市场增速最快,将从5亿美元增长到40亿美元,年复合增长率达到42%,发展潜力巨大。图1:全球存储器市场规模及增速(资料来源:YOLE) 存储器可以按照断电是否能保存数据分为两类。图2:存储器分类(云岫资本整理)第一类易失性存储器是以动态随机存取存储器(DRAM)和静态随机存取存储器(SRAM)代表的易失性存储器,二者均具备高读写速度。其中SRAM速度高于DRAM,但密度低于DRAM,这是因为一个DRAM存储单元仅需一个晶体管和一个小电容,而每个SRAM单元需要四到六个晶体管。其共同的缺点是容量较低且成本高,一般分别用作主存和缓存。第二类非易失性存储器包括以NOR FLASH和NAND FLASH为代表的传统存储器和四种新型存储器。NOR FLASH的容量较小且写入速度极低,但读速较快,具备芯片内执行的特点,适合低容量、快速随机读取访问的场景;NAND FLASH的容量大成本较低,但读写速度极低,一般用于大容量的数据存储。除FRAM以外的新型存储器均是通过阻值高低变化实现“0”“1”数据存储,四种新型存储器均具备非易失性,断电后仍可以保存数据,相比传统存储器在读写速度、功耗、寿命等方面各有优势。 存储器的发展取决于应用场景的变化。图3:存储的过去、现在与未来——场景应用决定市场趋势(云岫资本整理)20世纪70年代起,DRAM进入商用市场,并以其极高的读写速度成为存储领域最大分支市场;功能手机出现后,迎来NOR Flash市场的爆发;进入PC时代,人们对于存储容量的需求越来越大,低成本、高容量的NAND Flash成为最佳选择。智能化时代里,万物智联,存储行业市场空间将进一步加大,对数据存储在速度、功耗、容量、可靠性层面也将提出更高要求。而DRAM虽然速度快,但功耗大、容量低、成本高,且断电无法保存数据,使用场景受限;NOR Flash和NAND Flash读写速度低,存储密度受限于工艺制程。市场亟待能够满足新场景的存储器产品,性能有着突破性进展的新型存储器即将迎来爆发期。对比四种新型存储器ReRAM在密度、工艺制程、成本和良率上具备明显优势 目前,新型存储器主要有4种:相变存储器(PCM),以Intel和Micron联合研发的3D Xpoint为代表;铁电存储器(FeRAM),代表公司有Ramtron和Symetrix;磁性存储器(MRAM),代表公司是美国Everspin;阻变存储器(ReRAM),代表公司有松下、Crossbar和昕原半导体。表1:4种新型存储器参数对比(资料来源:Objective Analysis) 1.相变存储器(PCM或PCRAM,Phase-change RAM)PCM的原理是通过改变温度,让相变材料在低电阻结晶(导电)状态与高电阻非结晶(非导电)状态间转换。图4:PCM原理(资料来源:Intel)PCM虽然读写速度比NAND Flash有所提高,但其RESET后的冷却过程需要高热导率,会带来更高功耗,且由于其存储原理是利用温度实现相变材料的阻值变化,所以对温度十分敏感,无法用在宽温场景。其次,为了使相变材料兼容CMOS工艺,PCM必须采取多层结构,因此存储密度过低,在容量上无法替代NAND Flash。除此之外,成本和良率也是瓶颈之一。Intel和Samsung于2006年生产了第一款商用PCM芯片。2015年,Intel和Micron合作开发了名为3D XPoint的存储技术,该技术也是PCM的一种。2018年双方结束了联合开发工作,2021年3月,Micron宣布停止所有基于3D XPoint技术产品的进一步开发。 2.铁电存储器 (FRAM或FeRAM,Ferroelectric RAM)FRAM并非使用铁电材料,只是由于存储机制类似铁磁存储的滞后行为,因此得名。FRAM晶体材料的电压-电流关系具有可用于存储的特征滞后回路。图5:FRAM原理(资料来源:Objective Analysis)FRAM优势在于读写速度快、寿命良好,但其存储单元基于双晶体管,双电阻器单元,单元尺寸至少是DRAM的两倍,存储密度受限,成本较高。并且它的读取是破坏性的,每次读取后必须通过后续写入来抵消,以将该位的内容恢复到其原始状态。材料方面,目前铁电晶体材料PZT(锆钛酸铅)和SBT(钽酸锶铋)都存在疲劳退化、污染环境等问题,尚未找到完美商业化的材料。目前,Ramtron(归属于Cypress)和Symetrix两家公司正主导FRAM的开发。 3.磁性存储器 (MRAM,Magnetic RAM)目前主流的MRAM技术是STT MRAM,使用隧道层的“巨磁阻效应”来读取位单元,当该层两侧的磁性方向一致时为低电阻,当磁性方向相反时,电阻会变得很高。图6:MRAM原理(资料来源:Avalanche Technology)STT MRAM虽然性能较好,但临界电流密度和功耗仍需进一步降低,目前MRAM的存储单元尺寸仍较大且不支持堆叠,工艺较为复杂,大规模制造难以保证均一性,存储容量和良率爬坡缓慢。在工艺取得进一步突破之前,MRAM产品主要适用于容量要求低的特殊应用领域,以及新兴的IoT嵌入式存储领域。商业上,Everspin与Global Foundries合作,UMC与Avalanche Technology合作,推广STT-MRAM。 4.阻变存储器 (ReRAM或RRAM,Resistive RAM)阻变存储器全称是电阻式随机存取存储器,是以非导性材料的电阻在外加电场作用下,在高阻态和低阻态之间实现可逆转换为基础的非易失性存储器。ReRAM包括许多不同的技术类别,比如氧空缺存储器(OxRAM,Oxygen Vacancy Memories)、导电桥存储器 (CBRAM,Conductive Bridge Memories)、金属离子存储器(Metal Ion Memories)以及纳米碳管 (Carbon Nano-tubes)。图7:ReRAM原理(资料来源:Objective Analysis) ReRAM的单元面积极小,可做到4F²,读写速度是NAND FLASH的1000倍,同时功耗下降15倍。ReRAM工艺也更为简单。以Crossbar和昕原半导体为例,其采用对CMOS友善的材料,能够使用标准的CMOS工艺与设备,对产线无污染,整体制造成本低,可以很容易地让半导体代工厂具备ReRAM的生产制造能力,这对于量产和商业化推动有很大优势。 图8:Crossbar的电阻切换机制和新型3D堆叠ReRAM(资料来源:Crossbar官网)上图是Crossbar的ReRAM结构设计,大致分为顶部电极,开关介质和底部电极三层结构,其电阻切换机制是:两个电极之间施加电压时,切换材料中将形成纳米细丝,通过细丝连接上下两个电极,改变转换层的电阻,细丝相连代表存储值“1”,细丝断裂代表存储值“0”。由于电阻切换机制基于金属导丝,因此Crossbar ReRAM单元非常稳定,能够承受从-40°C到125°C的温度波动,写周期为1M +,在85°C的温度下可保存10年。从密度、能效比、成本、工艺制程和良率各方面综合衡量,ReRAM存储器在目前已有的新型存储器中具备明显优势。ReRAM国内外发展现状 在商业化上,Crossbar、昕原半导体、松下、Adesto、Elpida、东芝、索尼、美光、海力士、富士通等厂商都在开展ReRAM的研究和生产,其中专注IP授权的Crossbar对于ReRAM的基础技术研发走在了前列。Crossbar研发了两种存储架构——1T1R和3D堆叠式架构,3D堆叠技术可实现存储级内存,内置选择器允许多种存储阵列配置,单个晶体管可以驱动数千个存储单元,可以组织成超密集的3D交叉点阵列,可堆叠并能够扩展到10nm以下,从而为单个裸片上的TB级存储铺平了道路。 在代工厂方面,中芯国际(SMIC)、台积电(TSMC)和联电(UMC)都已经将ReRAM纳入自己未来的发展版图中。根据公开信息,已量产的海外ReRAM存储器主要有Adesto的130nm CBRAM和松下的180nm ReRAM。松下(Panasonic)在2013年开始出货ReRAM,成为了世界第一家出货ReRAM的公司。接着,松下与富士通联合推出了第二代ReRAM技术,基于180nm工艺。而Adesto 一直在缓慢地出货低密度 CBRAM。国内,昕原半导体在Crossbar的基础上实现了技术核心升级和工艺制程的改进,实现28nm量产,并且已建成自己的首条量产线,拥有了垂直一体化存储器设计加制造的能力。兆易创新和Rambus宣布合作建立合资企业合肥睿科微(Reliance Memory),进行ReRAM技术的商业化,但目前还无量产消息。 ReRAM迎来四大发展机遇:AIoT、智能汽车、数据中心、AI计算1.AIoTAIoT指人工智能技术与物联网在实际应用中的落地融合。根据艾瑞咨询数据,2019 年中国 AIoT 产业总产值为3808 亿元,预计2022年将达7509亿元,年复合增长率达25.4%。AIoT需要数据的实时交互,因此不仅要求存储器低功耗,也需要高读写和低延迟。目前的NOR Flash存储密度低、容量小、功耗高,无法实现高写入速度。而ReRAM在保证读性能的情况下,写入速度可提升1000倍,同时可实现更高存储密度和十分低的功耗,未来将会是取代NOR Flash成为万物智联时代存储器的最佳选择。随着人与物交互信息越来越多,很多私人信息会被存储记录,物联网在带来生活便利的同时,也带来了潜在的数据安全隐患,针对物联网的攻击甚至可以通过设备传递到现实生活中带来难以想象的破坏。AIoT应用越来越多要求具备安全属性。然而,目前普遍的安全芯片+Nor Flash方案存在成本高、空间受限等痛点。PUF(Physically Unclonable Function,物理不可克隆函数)+新型存储器芯片有望成为解决智能设备存储与安全问题的主流方案。PUF是一种利用芯片在半导体生产过程中的工艺波动性来生成芯片唯一函数,能够做到一芯一密,可称之为“芯片指纹”。目前,昕原半导体设计了基于ReRAM存储器的PUF芯片,可以同时具备存储加安全两个功能。2.智能汽车汽车电子根据功能可分为车身控制系统(ECU)、安全系统、娱乐设备、底盘控制、高级驾驶辅助系统(ADAS)等,都需要半导体器件实现相关功能,包括存储器、传感器、光电器件、射频器件、功率器件等。根据Counterpoint Research预测,未来单车存储容量将达到2TB-11TB,一辆L4/L5级自动驾驶汽车至少需要74GB DRAM和1TB NAND。据IHS预测,全球汽车存储IC市场规模2025年约为83亿美元。智能汽车对存储器的要求不仅在于温度和可靠性。控制系统需要智能化实时决策;ADAS系统时刻产生大量图像数据;娱乐系统需要更加智能来提升用户体验;能耗对于智能汽车也是关键性因素……这些都要求存储器具备大量的数据实时吞吐能力,保证存储稳定性和高能效比。传统的NOR Flash无法满足未来智能汽车对读写速度(特别是XIP程序执行效率)的要求;NAND Flash难以实现XIP片上的程序执行并且极慢;DRAM和SRAM容量有限,断电数据会丢失。新型存储器中,ReRAM不仅满足高读写速度和存储密度的要求,同时延迟可降低1000倍,可满足未来智能驾驶高实时数据吞吐量。安全性方面,ReRAM具备宽温和可靠性。未来有望出现高性能、高集成度、高稳定性和低功耗的车规ReRAM存储器。3.数据中心AI时代,数据呈现爆发式增长,越来越多的数据将在云端进行处理,根据思科预测,2021年全球将有1327EB数据存储在数据中心,6年复合增长率率高达41%。根据《2019-2020年中国IDC产业发展研究报告》预测,2022年中国数据中心市场规模将超过3200亿元。数据量的爆发催生对存储器新的增量市场和性能要求,据SUMCO预测,数据中心对SSD存储的需求将在2019年到2023年之间实现46%的复合增长。但目前数据中心存储器性能发展速度无法跟上计算需求,并且功耗仍是数据中心成本最高的因素之一。传统机械硬盘虽然寿命长成本低,但是读写速度极低且发热和噪声明显。DRAM虽速度较快但为易失性存储器,断电无法保存数据且成本极高,无法作为大量存储数据使用。而NAND读写速度仍较慢,另一方面功耗较高,性能和容量与工艺制程强相关。现有存储器无法跟上未来对数据高读写速度,低延迟,低功耗的需求。ReRAM相较NAND可提升100倍的读写性能,同时保持更低的功耗和高存储密度,有望解决未来数据中心高能效比,低延迟的需求,实现更高性能的AI数据中心。 4.AI计算(存算一体)人工智能是目前技术发展的重要趋势,根据沙利文咨询数据,2016-2024年人工智能的年均增长率达到33.98%,预计2024年将超过6157亿美元。而我国人工智能产业规模预计2024年将逼近8000亿元,约占全球总体产业规模的20%,复合增长率达到48.97%,大大超过全球平均水平。算力、算法、数据量是人工智能发展的三大基础要素,它们决定了AI计算的性能,这其中的两点都与存储相关:数据由存储器承载,数据量决定了AI计算模型的准确度;算力方面,未来对芯片计算性能和延迟性都提出了更高要求。目前的冯诺依曼架构,存储单元和计算单元独立分开,搬移数据的过程需要消耗大量时间和能量,并且由于处理器和存储器的工艺路线不同,存储器的数据访问速度难以跟上CPU的数据处理速度,性能已远远落后于处理器。所以,冯诺依曼架构在数据处理速度和能效比等方面存在天然限制,这被称为“存储墙”。存算一体架构通过将存储单元和计算单元融为一体,消除了数据访存带来的延迟和功耗,可以突破“存储墙”,实现更高的算力和更高的能效比。 图9:存算一体突破存储墙(云岫资本整理)目前存算一体有两种实现方式,第一种是基于易失性存储器DRAM和SRAM,但由于存储器制造工艺和逻辑计算单元的制造工艺不同,无法实现良好的融合,目前只能实现近存计算,仍存在存储墙问题,甚至因为互连问题可能还会带来性能损失。并且,因为SRAM和DRAM是易失性存储器,需要持续供电来保存数据,仍存在功耗和可靠性的问题。第二种是结合非易失性新型存储器,可以利用欧姆定律和基尔霍夫定律在阵列内完成矩阵乘法运算,而无需向芯片内移入和移出权重。新型存储器是通过阻值变化来存储数据,而存储器加载的电压等于电阻和电流的乘积,相当于每个单元可以实现一个乘法运算,再汇总相加便可以实现矩阵乘法,所以新型存储器天然具备存储和计算的属性。在这种情况下,同一单元就可以完成数据存储和计算,消除了数据访存带来的延迟和功耗,是真正意义上的存算一体。新型存储器中,ReRAM具有高集成密度、高开关比、高计算精度、高能效比和制造兼容CMOS工艺等优良特性,被认为是实现存算一体的最佳选择之一。、图10:新型存储器实现存算一体(Nature Nanotechnology) IDM模式是ReRAM厂商的最佳选择存储行业中,纯芯片设计公司难以摆脱对代工厂的依赖,不仅生产周期长、成本高,而且无法根据生产工艺做出适配性设计;而纯代工企业利润较低无法享受更多新技术红利。因此,目前世界前十大半导体公司中的4家存储公司,全部为IDM模式,拥有存储芯片设计加制造的全套能力。对于以ReRAM为代表的新型存储器而言,IDM模式不仅工艺和产能自主可控,同时可以不断进行迭代优化,通过高良率和高性能迅速筑起行业壁垒,是存储器行业发展最佳的商业模式。 新型存储器是中国实现存储领域弯道超车的最佳机会目前中国存储器市场国产化率极低,传统存储器先进技术均掌握在美国、韩国和日本手中,中国在最新产品性能上落后5-10年。三星、海力士和美光垄断了以DRAM为代表的易失性存储器市场,而以NAND为代表的非易失性存储器也被三星、铠侠、闪迪、美光和海力士垄断。而在ReRAM等新型存储器的发展上,中国与其他国家站在同一起跑线,都有机会出现下一个三星和海力士。在这中国存储产业突围的关键时期,一系列相关政策陆续出台,重点支持存储行业。国家“十四五”规划纲要中,在加强原创性引领性科技攻关方面,“先进存储技术升级”被列入“科技前沿领域攻关”重点领域;在加快推动数字产业化方面,《纲要》提到,培育壮大人工智能、大数据、区块链、云计算、网络安全等新兴数字产业,提升通信设备、核心电子元器件、关键软件等产业水平。图11:“十四五”规划纲要专栏2 科技前沿领域攻关2021年3月,临港新片区发布集成电路产业专项规划(2021-2025),提到要“在阻变存储器(ReRAM)等新兴领域实现增量发展”。图12:节选自《临港新片区集成电路产业专项规划(2021-2025)》目前,很多曾在世界顶尖企业担任高管的产业专家纷纷回国创业,不仅带来了先进技术和经验,也吸引了一批有志之士共同打造中国芯。天时地利人和之下,中国新型存储器未来可期! 参考资料:[1]Jim Handy. Objective Analysis White Paper : NEW MEMORIES FOR EFFICIENT COMPUTING Reducing Energy Consumption in Battery and Large-Scale Systems,2018.[2]Yu, Shimeng. Resistive Random Access Memory (RRAM)[J]. Synthesis Lectures on Emerging Engineering Technologies, 2016, 2(5):1-79.[3]刘明.半导体存储器技术[J].科技导报,2019, 037(003):62-65.[4]刘森, 刘琦. 阻变存储器发展现状[J]. 国防科技, 2016, 37(6).[5]国元证券.电子行业研究报告:存储芯片投资地图.[6]方正证券.汽车半导体系列专题报告——电车之忆:汽车存储芯片分布[7]Mahendra Pakala. AI时代推动存储器的创新与发展[J]. 中国电子商情(基础电子), 2019(10).—END—来自微信 -
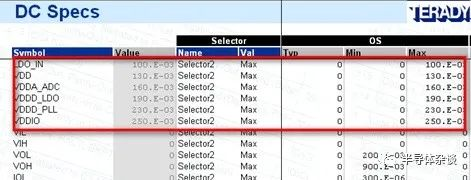
Power_Short测试 原创李家锋半导体杂谈2020年12月18日08:08Power short测试也是OS测试的一种,它测量的是电源pin short。为什么测量的是short,而不是open呢?如果电源pin出现open和short这两种情况,那么哪一种后果更严重呢?可想而知是short对芯片的影响更大,轻则使芯片不能正常工作,严重的还可能导致机台损坏,而open导致机台受损的概率非常小。因此相对于open,测试short显得格外重要。 那么再说一下测试power short的原理,其实很简单。只要给power pin一个电压测量电流即可,但有两点需要注意下。一点是给电压的大小,一点是存在多个电源pin的情况。我们先说给电压的大小,这时候我们给一个小电压即可(大的电压可能导致芯片工作产生大的电流),那么电压给多少合适呢?一般情况下0.05V~0.3V之间即可,具体根据情况而定。第二点就是如果存在多个电源pin,要给相同的电压么?一般不这么做,原因和OS_FUNC测试IO pin的一样,pin 与pin之间short如果给相同电压测不出来(思考下为什么)。因此做法是不同的电源pin给不同电压,如下图所示为多个电源pin测量power short给的电压值。对于电流的limit,一般是根据客户提供的spec写。如果客户没有明确的spec,也可拿golden芯片根据实际测量的结果去定,一般情况下为±1mA。来自微信
-
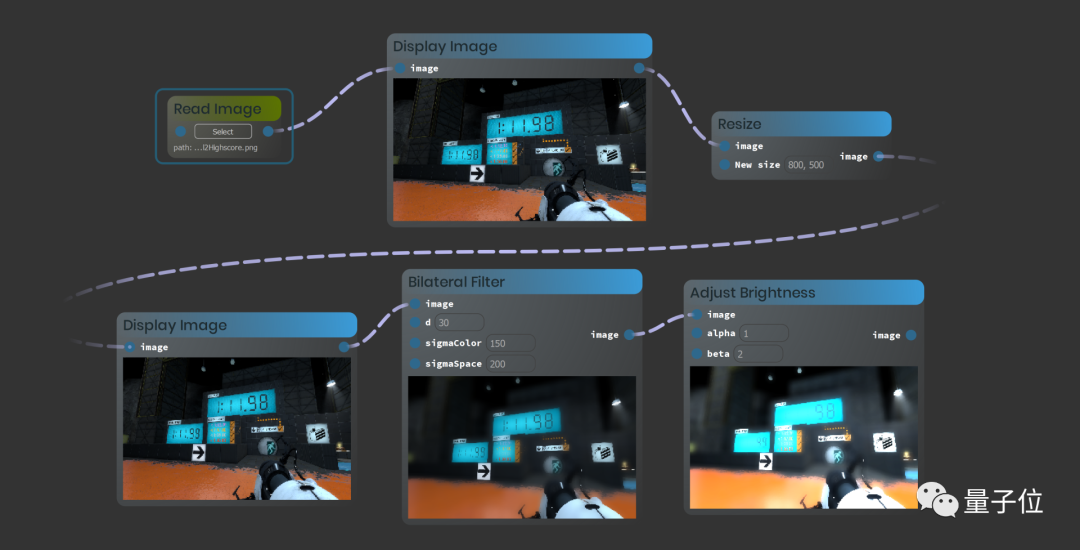
大一新生开源 Python 脚本可视化工具,火了! Python数据科学2021年01月25日14:05普普通通黑底白字地敲代码太枯燥?那么,把 Python 脚本可视化怎么样?就像这样,从输入图片、调整尺寸到双边滤波,每一步都能看得清清楚楚明明白白。输入一个矩阵,无论是对它进行转置、求共轭还是乘方,都能得到及时的反馈。这样一个 Python 脚本可视化工具,名叫 Ryven,出自一位名叫 Leon Thomm 的大一新生之手。如果你也想试用一番,不妨接着往下看。如何使用使用之前,简单准备一下开发环境:Python3(推荐 3.8 以上)PySide2(推荐 2.14 以上)运行该项目中的 Ryven.py,即可打开编辑器。作者提到,在 Ryven 中,有许多不同的脚本。每个脚本都包含变量、流(或图)以及日志。右键单击就可以轻松操作。不过,想要使用这些节点,需要先导入节点软件包。点击 file,选择 import Nodes,导入 *.rpc 文件即可。这个工具的另外一个特点是,包含了两种不同的算法模式。数据流:每次数据更改(节点数据输出也就更改了)都会向前传播,并在所有连接的节点中触发更新。如下图,滑动滑块,会立即触发右侧节点中结果的更新。执行流:数据不会在更改时立即向前传播,而是只会在某个节点请求输出数据时,在受影响的节点中触发更新。另外,作者还给自己列了一个 to do list,比如加入语法高亮功能、自动代码补全功能,完善视觉体验等等。可视化编程是不是还挺有趣的?不过,作者小哥也指出,可视化编程的目的不是取代文本编程,并且,文本编程中实现的许多工作没有可视化的必要。关于作者作者 Leon Thomm,目前是苏黎世联邦理工学院的大一学生,自称 “业余程序员”,致力于人机交互和可视化编程。根据他的个人简介,早在进入大学前,他已经具备丰富的软件开发经历。传送门项目地址:https://github.com/leon-thomm/Ryven来自微信
-
答应我,调试 Python 代码,不要再用 Print 了! Python数据科学2021年01月27日14:27相信大部分人学习Python,肯定会用print()这个内置函数,来调试代码的。那么在一个大型的项目中,如果你也是使用print来调试你的Python代码,你就会发现你的终端有多个输出。那么你便不得不去分辨,每一行的输出是哪些代码的运行结果。举个例子,运行下面这个程序。num1 = 30num2 = 40 print(num1)print(num2)输出结果。3040这些输出中哪一个是num1?哪一个又是num2呢?找出两个输出可能不是很困难,但是如果有五个以上的不同输出呢?尝试查找与输出相关的代码可能会很耗时。当然你可以在打印语句中添加文本,使其更容易理解:num1 = 30num2 = 40 print("num1" num1)print("num2" num1)输出结果。num1 30num2 40这个结果就很容易理解了,但是需要时间去写相关的信息。这时就该「Icecream」上场了~什么是Icecream?Icecream是一个Python第三方库,可通过最少的代码使打印调试更清晰明了。使用pip安装Icecream库。pip install icecream下面,让我们通过打印Python函数的输出来进行尝试。from icecream import ic def plus_five(num): return num + 5 ic(plus_five(4)) ic(plus_five(5))输出结果如下。ic| plus_five(4): 9ic| plus_five(5): 10通过使用icecream,我们不仅可以看到函数输出,还可以看到函数及其参数!检查执行情况如果你想要找到执行代码的位置,可以通过执行如下所示的操作,来查找执行了哪个语句。def hello(user:bool): if user: print("I'm user") else: print("I'm not user") hello(user=True)输出结果。I'm user使用icecream则无需多余的文本信息,就可以轻松地完成上述的操作。from icecream import ic def hello(user:bool): if user: ic() else: ic() hello(user=True) 输出结果如下。ic| ice_1.py:5 in hello() at 02:34:41.391从输出结果看,函数hello中的第5行的代码已被执行,而第7行的代码未执行。自定义前缀如果您想在打印语句中插入自定义前缀(例如代码执行时间),icecream也是能实现的。from datetime import datetime from icecream import ic import time from datetime import datetime def time_format(): return f'{datetime.now()}|> ' ic.configureOutput(prefix=time_format) for _ in range(3): time.sleep(1) ic('Hello') 输出结果如下。2021-01-24 10:38:23.509304|> 'Hello'2021-01-24 10:38:24.545628|> 'Hello'2021-01-24 10:38:25.550777|> 'Hello'可以看到代码的执行时间,就显示在输出的前面。获取更多的信息除了知道和输出相关的代码之外,你可能还想知道代码执行的行和代码文件。在ic.configureOutput()中,设置includeecontext的参数值为True即可。from icecream import ic def plus_five(num): return num + 5 ic.configureOutput(includeContext=True) ic(plus_five(4)) ic(plus_five(5))输出结果如下。ic| ice_test.py:7 in - plus_five(4): 9ic| ice_test.py:8 in - plus_five(5): 10这里我们就知道了,第一个输出是由函数plus_five在文件icecream_example.py的第7行执行的。第二个输出则是由函数plus_five在代码文件的第8行执行的。上述两个操作都用到了ic.configureOutput()函数。通过查看源码,可知有四个可供设置的参数。prefix,自定义输出前缀outputFunction,更改输出函数argToStringFunction,自定义参数序列化字符串includeContext,显示文件名、代码行、函数信息删除Icecream代码最后你可以将icecream仅用于调试,而将print用于其他目的(例如漂亮的打印)。from icecream import ic def plus_five(num): return num + 5 ic.configureOutput(includeContext=True) ic(plus_five(4)) ic(plus_five(5)) for i in range(10): print(f'****** Training model {i} ******') 输出结果。ic| ice_1.py:7 in - plus_five(4): 9ic| ice_1.py:8 in - plus_five(5): 10 Training model 0 ** Training model 1 ** Training model 2 ** Training model 3 ** Training model 4 ** Training model 5 ** Training model 6 ** Training model 7 ** Training model 8 ** Training model 9 **由于你可以区分调试打印和漂亮打印,因此搜索和删除所有ic调试语句非常容易。删除所有调试代码后,你的Python代码就整洁了。总结到此,你就应该就学会了如何使用icecream去打印调试。更多功能可以访问「GitHub」,了解详情~https://github.com/gruns/icecream来自微信
-
存储器芯片行业研究宝典 硬科技精品投行的驭势资本2021年01月22日19:01储存器中国存储器芯片行业定义及分类DRAM、NOR Flash、NAND Flash三类存储器之间的应用已产生隔离,难以相互代替,市场自成体系。存储器芯片定义及分类存储器芯片是半导体存储产品的核心,是电子系统中负责数据存储的核心硬件单元,其存储量与读取速度直接影响电子设备性能。半导体存储按照掉电后是否保存数据,分为易失性存储和非易失性存储。易失性存储主要以随机存取器RAM为主,使用量最大的为动态随机存储DRAM。非易失性存储中最常见的为NOR Flash与NAND Flash,其中NOR Flash因其读取速度快且可擦除写入,被作为代码存储的主要器件,NAND Flash在高容量时具有成本优势,且读写速度比传统的光学、磁性存储器快,是现在主流的大容量数据存储器件。中国存储器芯片行业制程分析当前中国NOR Flash芯片技术基本成熟,但在DRAM、NAND Flash芯片领域,仍与国际领先水平有着一代以上的技术差异。中国存储器芯片行业市场现状存储器芯片传统应用市场规模稳定,近年来,随着技术的发展,不断有新下游应用拉动行业发展。新应用市场数据存储需求汽车电子系统开始支持GUI、语音识别、高级数据处理功能产生大量数据存储需求。口令存储需求随着汽车智能化发展,搭载更多即时启动应用,而及时启动最佳解决方案为NOR Flash。产业链存储芯片产业是国家战略产业,直接关系到电子信息产业的发展,中国正逐渐在全产业链各个环节中实现对进口产品的替代。存储器芯片产业链介绍中国半导体产业链由上游为半导体支撑产业,中游为存储芯片行业,下游市场参与者由众多电子整机厂组成。存储器芯片是集成电路价值量最大的产品之一,存储芯片产业是国家战略产业,直接关系到电子信息产业的发展,中国正逐渐在全产业链各个环节中实现对进口产品的替代。产业链上游分析大基金二期注册成立,以长江存储为代表的存储器芯片厂商是重点投资对象,其产业链上游的半导体材料与设备是投资热点。存储器芯片行业产业链上游分析大基金二期重点布局半导体产业链上游,半导体材料与半导体设备行业有望在未来实现进口替代。2016年成立的大基金一期接近尾声,其重点投资领域为集成电路制造,重点解决中国晶圆代工产能不足、技术落后的问题。2019年10月,大基金二期注册成立,以长江存储为代表的存储器芯片厂商是重点投资对象,其产业链上游的半导体材料与设备是基金投资的热点之一。半导体材料技术垄断:美国、日本、韩国、德国等国家占据主导地位中国半导体材料的市场规模占全球比重逐年上涨整体表现为企业数量少、市场规模小、技术水平低以及产业布局分散的特征半导体设备总体国产化率较低,属于产业链薄弱环节,国产替代空间巨大中国晶圆厂建设与扩产招标过程中,半导体设备国产化率从逐渐提高存储器芯片发展扩产为中国半导体设备厂商提供了更多的发展机遇,中国将进入半导体设备国产化窗口期产业链中游分析全球范围内,美、韩两国存储器芯片厂商居头部,技术领先,议价能力强,近年来中方企业技术逐渐实现赶超,预计未来将实现国产替代。设计环节(占成本30%)1、中国IC设计行业缺乏自主设计流程的能力,还不具备COT设计能力,主要依靠工艺技术的进步和EDA工具的进步。2、除兆易创新外,中国存储器芯片厂商多为IDM模式发展。制造环节(占成本40%)1、当前在高端制程,中国厂商难以实现国产替代。2、3D NAND Flash领域:三星86层技术成熟,当前长江存储64层产品已小范围量产,目前在调试设备跨86层。3、实现128层技术弯道超越。4、DRAM领域:当前中国全面落后于国际头部企业。封测环节(占成本30%)1、中国集成电路封测水平居全球领先水平,已完全实现国产替代。2、存储器芯片封测行业属于劳动密集型、技术密集型企业。3、封测水平反向推动产业链中游芯片制造业的发展。产业链下游分析三大主流存储器芯片近年来下游市场规模逐年扩大,旺盛的下游需求推动存储器芯片行业的发展。电子整机搭载内存容量不断扩大•PC市场:需求从装机标配4GB过渡到了8GB、16GB甚至是32GB,市场需求量进一步扩大。•移动端:以智能手机为主要代表的移动端以内存容量作为产品属性提升的空间,当手机内存的标配从1GB、2GB转变到6GB、8GB时,其对DRAM的需求量也有了极大的增长,再加上智能手机的快速普及与其巨大的市场保有量,抢占了一大部分DRAM资源。SSD和智能手机市场NAND Flash需求的增长已经弥补了其他消费类电子市场需求的相对平淡。•智能手机:2019年全球智能型手机出货14.9亿台,苹果、三星、华为、OPPO、vivo等头部智能手机品牌旗舰机纷纷以64GB、128GB、256GB为主打容量,再加上平板、车载、智能盒子等细分市场需求eMMC/eMCP等嵌入式产品消耗了42%的NAND Flash产能。•SSD市场:数据中心、服务器等领域对数据分析、处理、响应速度的要求不断提高,谷歌、Facebook、百度、阿里巴巴、腾讯、华为等对SSD需求强劲。消费类市场,超极本、二合一等轻薄笔记本对SSD搭载率不断增加,去年消费类市场SSD出货超1.5亿台,再叠加工业、金融、车载等领域SSD需求,全球SSD共消耗近50%NAND Flash产能NOR Flash下游需求中,除了传统电脑、智慧型手机、网路通讯与消费性电子产品外,近年来最新且成长最大的需求在于智慧型手机的AMOLED屏幕,及LCD驱动IC和TDDI(Touch Display Driver IC)方案。•智能手机:智能手机的AMOLED屏幕需要大量消耗NOR Flash颗粒•随着物联网、可穿戴设备、智慧城市、智慧应用、智能家居、智能汽车、无人机等厂商使用NOR Flash作为储存装置和微控制器搭配开发,NOR Flash需求将呈现爆发性增长。市场规模存储器芯片应用广泛,随着5G、物联网技术为中国半导体行业发展赋能,未来市场规模将进一步扩大。近五年来,受PC及移动端电子设备内存容量不断扩大,以TWS为代表的可穿戴设备新型消费级市场快速扩张,以及大数据云计算技术不断释放对企业级存储的需求等多方因素的影响,中国存储器芯片行业整体不断发展,市场规模(以销售额计)从2014年的45.2亿美元增长到了2019年123.8亿美元,年复合增长率高达28.6%。由于当前存储器芯片应用广泛,同时下游消费电子市场份额逐年扩大,且未来5G及物联网技术将进一步为中国存储器芯片的整体发展赋能,预计未来中国存储器芯片还将继续保持稳定增长的态势。到2024年,中国存储器芯片市场份额有望突破522.6亿美元,占全球市场的14%。市场规模预测逻辑中国电子整机制造业反向驱动上游存储器芯片发展,中国存储器芯片市场增速高于全球增速。储存器中国存储器芯片行业驱动因素国产替代大环境助推中国存储器芯片厂商有天然地缘优势,未来对进口的依赖将会进一步减弱,国产替代率将进一步提高。存储器芯片国产替代率逐渐提高近十年来,中国电子工业占全球的比重持续增加,全球80%的电子整机制造在中国大陆完成。受制于中国相对落后的半导体水平,中国集成电路进口持续维持高位。过去五年来,中国集成电路进口数量始终维持上涨的趋势。2018年,中国集成电路进口金额与进口数量分别高达3,120.6亿美元,4,175.7亿只。受制于中国集成电路行业起步较晚,行业技术水平整体落后于西方发达国家,短时间内集成电路进口数量与进口金额仍将维持高位。美国限制对中国的科技技术出口,长期将加速半导体国产化进程。目前,中国在生产代工、设备、存储器、计算、模拟及数模转换芯片、射频前端、EDA软件等领域缺口较大,存在进口替代机会。存储器芯片品牌化程度较弱存储器芯片产品具有典型的大宗商品属性,差异化竞争较小,不同企业生产的产品技术指标基本相同,标准化程度较高,因此品牌化程度较弱,用户粘性低。从电子整机下游消费者角度考量:消费者通常只会考虑存储芯片的容量,如手机存储量是64G还是128G,对存储器芯片品牌不会有过多关注。从存储器芯片厂角度考量:行业壁垒高,头部企业通常体量大、投资高、规模庞大,下游整机厂在选配存储器芯片时,在产品性能、物理属性等技术性能接近的情况下,报价通常作为第一考量因素。从电子整机厂角度考量:尤其是消费类电子整机出货量通常以亿为计量单位,存储器芯片作为核心存储硬件单元,需求量与其倍数相关,巨量需求下,性价比直接决定品牌的市场份额。因此,对于存储器芯片行业,只要技术参数上达到产品需求,不同品牌的可替代率很高,这为中国存储器芯片品牌的发展提供了弯道超车的可能。物联网技术的发展物联网技术的发展使得设备的网络接入量与整体数据存储量呈现爆发式增长,直接拉动存储器芯片行业的发展。物联网是NOR Flash发展的核心推动力物联网技术的发展使近年来NOR Flash呈现市场复苏。通常,物联网接入设备的系统与手机、计算机等相比更简单,处理数据更少,对存储空间的要求较少,一般在几兆到几百兆之间。此时物联网接入设备采用NOR Flash替代传统计算机、手机等设备以DRAM和NAND Flash为核心的内存处理方案是性价比最高的选择,这使得物联网技术赋能的新设备仍能维持在当前价格水平,逐渐提高在整体产品市场的渗透率。物联网技术发展对存储器芯片行业推动作用物联网将更多常见设备接入互联网,如冰箱、空调、洗衣机、电视等。移动端电子产品及可穿戴设备市场规模的不断增大。存储空间增大提升单颗芯片售价。物联网、云计算等新增应用叠加5G基建产生巨量数据,需要更强算力更大存储量服务器支持。物联网技术赋予电子产品更强功能,需要更大内存空间支持。中国存储器芯片行业风险因素分析如现阶段全球疫情得不到有效控制,下游整机产能下降,势必对上游存储芯片行业造成产能难以爬坡与库存周期延长的负面影响。“黑天鹅”影响全年消费2020年一季度是电子消费产品发布新品旺季,在“新冠疫情”与“全球油价下跌”两只黑天鹅冲击下,2月中国制造业PMI降至35.7%,为近十五年来最低。因电子产品产业链覆盖面广,参与者众多,受不同环节、不同零部件复工复产进度不均的影响,大部分电子整机OEM厂年后产量爬坡受阻,以代工厂富士康为例,大陆生产受阻致使其母公司营收环比下降40%,创下八年新低。消费电子终端市场新品上市后产能供应不足,且市场消费信心不足。据中国信息通信研究院数据,2月中国手机市场总出货量638.4万部,同比下降56%,国产品牌手机出货量1,310.8万部,同比下降14.7%,5G手机238万部,占比37.3%,包括华为、小米、OPPO、vivo等品牌厂均受到了不同程度的影响,且未来几个月还将受到海外“疫情”的影响。整机厂产能下降对上游半导体行业景气程度产生消极影响受疫情影响,各地节后复工情况步调不一致,整机厂面临一系列疫情带来的制约因素:•供应链上下游延迟复工,或将延期投产;•物流速度降低,甚至可能出现停运;•产品入关检查的时间和财务成本或增加,为海外销售带来更高挑战。全球20%晶圆代工产能落地中国,其主要原因是靠近下游客户。虽然中国消费电子产品全链条制造资源的丰富和完善程度全球领先,仍需警惕整机厂行业寒冬期对产业链的冲击。“新冠疫情”本年度对存储器芯片产业影响全球电子产品市场消费信心下降韩国受疫情影响较重,存储器芯片出货量或将受到影响欧美日受疫情影响严重,半导体材料及设备供应受到影响制造业三大周期:产品周期、资本开支/产能周期、库存周期。产品周期是所有周期的根本,也是最长的周期。在存储芯片领域,产品周期代表的是最核心最根本的影响因素,即下游需求驱动力。如PC、手机、TWS耳机是半导体行业发展过程中的产品周期,手机周期也根据技术迭代带来的产品周期进一步细分为3G、4G、5G。1、如疫情得不到有效控制,下游整机产能下降,势必对上游存储芯片行业造成产能难以爬坡与库存周期延长的负面影响。2、同时,存储芯片如未能在二季度实现产能顺利爬坡,也会造成库存周转困难,影响产品周期健康有序向上发展的势头。储存器中国存储器芯片行业相关政策法规存储器芯片作为重要的分立器件细分应用领域,其行业的稳定发展与中国分立器件的整体发展密切相关。集成电路在电子信息产业的地位促使国家近二十年来不断出台政策鼓励行业发展,其中最直接的政策是2011年《国务院关于印发进一步鼓励软件产业和集成电路产业发展若干政策的通知》中明确对IC设计和软件企业实施所得税“两免三减半”优惠政策,该政策一直延续至今。2019年5月22日,财政部、税务总局发布公告,为支持IC设计和软件产业发展,依法成立且符合条件的IC设计企业和软件企业,在2018年12月31日前自获利年度起计算优惠期,第一年至第二年免征企业所得税,第三年至第五年按照25%的法定税率减半征收企业所得税,并享受至期满为止。此前,国常会就决定延续集成电路企业所得税优惠政策,会议决定,在已对集成电路生产企业或项目按规定的不同条件分别实行企业所得税“两免三减半”或“五免五减半”的基础上,继续实施2011年明确的所得税“两免三减半”优惠政策。中国存储器芯片行业发展趋势存储芯片迎来黄金发展期全球存储器市场从去年的供过于求演变到下半年及明年的供不应求,存储芯片价格上涨将超10%。5G手机增加存储器用量未来几年全球5G手机激活市场会从2019年的近1,000万台,爆增到2020年的1.6-2.0亿及2021年的4.0-5.0亿台,而每台5G手机都需配备8GB或以上的mobile DRAM及128-256GB的NAND闪存。与4G手机配备64-128GB的NAND Flash相比,预计手机用NAND Flash于2020-2021年增长率超30%。云服务器市场需求量的复苏受疫情影响,春节期间云端服务器客户量急剧上涨。在线医疗、在线娱乐、在线教育、在线买菜等云业务的普及使得服务器数量及服务器内存用量急剧增长。近年来,云端服务器用户大幅增长,服务器用DRAM占整体DRAM用量比例逐年上涨。由于英特尔在推出14nm++ Cooper Lake及10nm+ Ice Lake CPU数据通路自6拓展为8,数据处理效率更高,可以搭载更多内存单元,服务器内存芯片的用量将显著增加,据专家预测,2021年服务器用DRAM芯片用量占整体DRAM用量比例将达38%。中国存储芯片国产替代还有较大的发展空间全球内存及闪存产品在国际竞争市场上,基本均被韩国、日本、美国等国垄断。在DRAM领域,三星、海力士及美光为行业龙头,在NAND领域,三星、东芝、新帝,海力士以及美光、英特尔共同掌握全球话语权。当前,中国已初步完成在存储芯片领域的战略布局,但由于中国起步晚,且受到技术封锁,市场份额较少,距离全面国产替代还有较大的发展空间。存储芯片良好的发展态势将为中国在这一领域的发展提供源源不断的需求保障。IP创新与自主制造存储器的IP集中度低,面对国际技术封锁,当前中国厂商主要通过合作授权与自主研发相结合的方式获得IP版权。IP创新与自主制造是存储器芯片的两个发展方向对于存储器芯片,由于存储器芯片制程的难点在于IP和制造,头部厂商的主流经营模式为IDM模式,受制于欧美日韩对中国半导体行业的限制,中方获得IP的主要方式为合作授权与自主研发相结合的方式。DRAM的IP领域由于在DRAM领域中国厂商总体起步较晚,专利积累相对薄弱。但由于DRAM总体来说技术发展相对成熟,国际领先企业在研发领域资本投入已有所减少,这为中国厂商继续提高资本投入已实现国产替代提供了良好的机会。在此基础上中国厂商加快IP自主研发,降低成本的同时提高产品性能,从而在议价能力及定价弹性达到国际领先水平。NAND FLASH的IP领域NAND Flash的IP方面,3D NAND Flash堆叠技术自2D平面技术升级而来,由于3D堆叠技术为近年来出现的新技术,中国头部企业长江存储与国际大厂的技术差距相对较小。但在IP储备领域,中国厂商仍处于弱势地位,三星、东芝、闪迪、海力士等存储器芯片巨头厂商仍具有压倒性优势。制造领域在半导体产业向中国转移的大趋势下,国际大厂纷纷在大陆地区设厂或增大中国大陆建厂规模。据SEMI数据显示,近四年来全球投产晶圆厂超60座,其中26座位于中国大陆,占全球晶圆厂比例超40%。制造业是集成电路的核心环节,制造环节向大陆的迁移直接促进中国存储器芯片产业的发展。随着大量晶圆厂在中国的建成,中国存储器芯片将迎来先进制程技术的突破与成熟。储存器中国存储器芯片行业竞争格局当前中国基本实现NOR Flash芯片的进口替代,但在DRAM、NAND Flash芯片领域,仍与国际领先水平有不小差距。中国存储器芯片行业国产替代潜力大全球存储器芯片市场规模大且竞争激烈,当前中国已基本实现NOR Flash芯片的进口替代,但在DRAM、NAND Flash芯片领先制程领域,仍与国际领先水平有不小差距。DRAM发展道阻且长中国大陆是全球DRAM最大市场,但自给率几乎为0。现阶段,半导体产业中心已转移到中国大陆,中国大陆已是全球最大和增速最快的市场,但大陆半导体产业起步晚,自给率仅为15%左右。DRAM作为半导体和存储器最大细分市场,2018年占据全球半导体和存储器总产值的比例分别为22%和58%,中国大陆作为最大市场,销售额全球占比约为43%,但几乎完全依赖进口,自制率远低于半导体全行业水平。NAND Flash发展初步取得成果三星、海力士、东芝、西部数据、美光、英特尔等巨头在产能上持续投入。2018年,64层、72层的3D NAND闪存已成业界主力产品,2019年开始量产92层、96层的产品,到2020年,大厂们即将进入128层3D NAND闪存的量产。长江存储64层三维闪存产品的量产有望使中国存储芯片自产率从8%提升至40%。在美日韩大厂垄断下,长江存储的64层3D NAND闪存量产消息别具意义。储存器中国存储器芯片行业投资企业推荐武汉新芯武汉新芯为存储器芯片龙头企业,专注于NOR Flash与晶圆级XtackingTM技术,是紫光集团旗下核心企业。主营业务武汉新芯集成电路制造有限公司(以下简称“武汉新芯”),于2006年在武汉成立,是一家领先的集成电路研发与制造企业。专注于NOR Flash与晶圆级XtackingTM技术,致力于为全球客户提供高品质的创新产品及技术服务。作为紫光集团旗下核心企业,武汉新芯将整合集团和产业链合作伙伴的资源,并充分利用自身优势,努力为其全球客户提供高性能、高可靠性、低功耗、高性价比的产品和解决方案。公司产品•NOR FALSH代工武汉新芯自2008年开始向客户提供专业的300MM晶圆代工服务,在NOR Flash领域已经积累了十多年的制造经验,是中国乃至世界领先的NOR Flash晶圆制造商之一。•XtackingTM武汉新芯自主研发、国际先进的晶圆级三维集成技术平台XtackingTM。公司是国内首家采用硅通孔技术(TSV)来生产图像传感器的制造商,已积累了多年的大规模量产经验,产品集高性能、低功耗、高集成度的优点于一体,广泛应用于中国智能手机市场。投资亮点技术领先XtackingTM技术平台已推出硅通孔技术(TSV)、混合键合( Hybrid Bonding)和多片晶圆堆叠技术(Multi-Wafer Stacking),为客户提供极具灵活性和创新性的晶圆级三维集成技术解决方案。质量可靠武汉新芯一直严格遵守质量管控和环境、安全、健康管理体系,并获得如汽车行业质量管理体系IATF16949、质量管理体系ISO9001等国际体系认证。战略定位进口替代武汉新芯建设的12英寸芯片项目在2008年正式投产,产品良率达到世界领先水平,结束了中国中部无“芯”的历史。在NOR Flash领域,武汉新芯达到世界领先水平。IDM2017年武汉新芯开始聚焦IDM发展战略,发布了集产品设计、晶圆制造与产品销售于一体的自主品牌,致力于开发高性价比的SPI NOR Flash产品长江存储长江存储是一家专注于3D NAND闪存芯片设计、生产和销售的IDM存储器公司,致力于成为全球领先的NAND闪存解决方案提供商。企业概况长江存储科技有限责任公司(以下简称“长江存储”),总部位于武汉,是一家专注于3D NAND闪存设计制造一体化的IDM集成电路企业,同时也提供完整的存储器解决方案。长江存储为全球合作伙伴供应3D NAND闪存晶圆及颗粒,嵌入式存储芯片以及消费级、企业级固态硬盘等产品和解决方案,广泛应用于移动通信、消费数码、计算机、服务器及数据中心等领域。投资亮点长江存储进入到3D FLASH领域之前,中国一直没有大规模存储芯片的生产,未来,随着云计算、大数据的发展,人类对数据存储要求是越来越高,三维闪存存储芯片是高端芯片一个重要领域,其量产也标志着中国离国际先进水平又大大跨近一步,把中国产品水平跟海外的先进水平缩短到了一代。主营业务长江存储专注于3D NAND闪存晶圆及颗粒,嵌入式存储芯片以及消费级、企业级固态硬盘等产品和解决方案,广泛应用于移动通信、消费数码、计算机、服务器及数据中心等领域。领先产品•2017年10月,长江存储通过自主研发和国际合作相结合的方式,成功设计制造了中国首款3D NAND闪存•2019年9月,搭载长江存储自主创新Xtacking架构的64层TLC 3D NAND闪存正式量产•目前,长江存储正跨越96层制程弯道追赶国际领先128层制程发展战略•长江存储实行纵向一体化的经营模式,具备识别客户需求、进行产品设计、准备原辅材料、封测、销售及持续服务全产业链经营能力。可基于客户需求实现定制化芯片制造长江存储64层三维闪存是全球首款基于Xtacking架构设计并实现量产的闪存产品,拥有同代产品中最高存储密度。•创新的Xtacking技术只需一个处理步骤就可通过数十亿根垂直互联通道(VIA)将两片晶圆键合,相比传统三维闪存架构可带来更快的传输速度、更高的存储密度和更短的产品上市周期。长鑫存储长鑫存储专业从事DRAM存储器芯片的研发、生产和销售,目前已建成第一座12英寸晶圆厂并投产。企业简介合肥长鑫存储技术有限公司(以下简称“长鑫存储”),事业开始于2016年。长鑫存储专业从事动态随机存取存储芯片(DRAM)的研发、生产和销售,目前已建成第一座12英寸晶圆厂并投产。DRAM产品广泛应用于移动终端、电脑、服务器、人工智能、虚拟现实和物联网等领域,市场需求巨大并持续增长产品介绍长鑫存储的8Gb LPDDR4规格的DRAM芯片已经投片,相较于上一代DDR3内存芯片,DDR4内存芯片拥有更快的数据传输速率、更稳定的性能和更低的能耗。长鑫存储自主研发的DDR4内存芯片满足市场主流需求,可应用于PC、笔记本电脑、服务器、消费电子类产品等领域。高速数据传输多领域应用支持可靠性保障主流市场需求匹配多产品组合战略定位12寸晶圆制造母公司兆易创新宣布与合肥市产业投资控股集团签署合作协议,以长鑫存储为载体研发19纳米制程的12寸晶圆DRAM,总预算为人民币180亿元。国产替代预计将在全球DRAM市场占得约8%的市场份额填补国产DRAM存储器在本国市场的空白投资亮点自主研发长鑫存储聚集了集成电路行业的领袖,研发、设计及制造的专家,以及国际化的经营管理团队,不断创新,积极培养本地优秀人才,是具有尖端技术开发能力和工艺制造能力的“中国创造”模范企业。技术领先长鑫存储也是全球第四家DRAM产品采用20纳米以下工艺的厂商。另外三家是目前DRAM存储的三大巨头,三星、SK海力士、美光。这三家的DRAM全球市占率超过95%。参考文献来自:头豹、驭势资本研究所END来自微信