搜索到
344
篇与
的结果
-
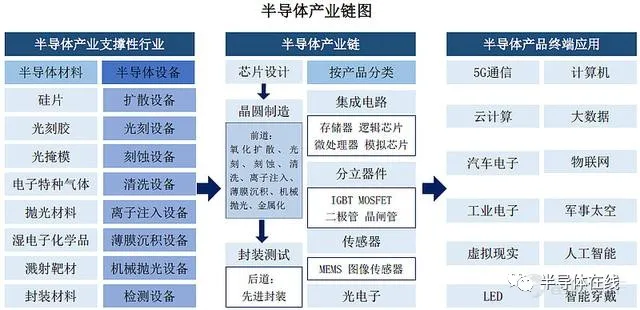
 半导体产业链详细梳理 半导体在线2021年09月22日16:24现在的全球半导体行业,处于新一轮景气周期上行阶段。而国内的半导体产业,不仅受到全球性大周期的影响,还有一条非常硬核的逻辑,就是国产替代。中国虽已经成为全球最大的半导体消费国,但我国的芯片自给率低,2020年我国集成电路自给率仅为15.9%,国产替代仍有很大的替代空间。从需求端来看,受益于“万物互联+国产替代”以及新能源汽车的助攻,芯片需求全面拉升;供给端受疫情冲击以及制裁下扩产速度减慢。跟传统周期性行业类似,半导体也存在着产能、库存和需求的不可能三角。由于从投资到产能释放的前置时间较长,如此扩大了芯片的缺口。年初开始,晶圆大厂们纷纷公布了一大波超预期的资本开支计划。下图为半导体产业从材料到应用终端流程图:如图:芯片产业链主要包括设计、制造、封装与测试三大环节与半导体设备及材料两大支柱产业。本文将按照该框架梳理整个芯片行业产业链。芯片设计包括工具软件、设计公司芯片制造包括制造厂、制造设备、材料与辅料芯片封测包括封测厂、封测设备、辅材打个通俗的比喻,芯片设计环节就像房地产的图纸设计,圆晶代工就是施工建房,封测就是将毛坯房变为精装房。一、芯片设计芯片设计是产业链中重要的一环,影响后续芯片产品的功能、性能和成本,对研发实力要求较高。根据不同的下游应用,可分为四类:集成电路:存储器、逻辑芯片(CPU、GPU)、微处理器(MPU)、模拟芯片分立器件(含功率半导体):MOSFET、IGBT、二极管、晶闸管传感器:MEMS、图像传感器光电器件(一)集成电路兆易创新:国内闪存芯片存储器及MCU微控制器设计双龙头。在全球NORFlash的市场占有率为6%,已跃居全球第三。公司作为国内MCU微控制器市场的龙头公司,2020年销售接近2亿颗,2021年公司业绩将伴随着工控等领域的快速放量,迎来快速发展的时期。北京君正:收购北京矽成,成为国内稀缺的汽车存储芯片领军企业。北京矽成在全球车用DRAM存储芯片市占率15%,全球排名第二。收益于汽车电动化与智能化对车用存储芯片数量和容量要求的提升,实现量价齐升。微处理器芯片业务收益于智能终端硬件需求的爆发。公告拟定增募集资金拓展车载LED照明芯片。国科微:我国固态存储芯片技术领先代表,最新产品达到国际平均水平、深耕智能安防监控芯片,积极布局AI智能监控芯片。圣邦股份:国内模拟芯片龙头,电源管理芯片及信号链芯片受益于5G、工业驱动、人工智能和汽车升级,叠加国产替代,空间广阔。思瑞浦:业务与圣邦股份高度重合,国产信号链类模拟芯片龙头企业。公司的信号链模拟芯片为5G射频模拟芯片的主要组成部分,综合性能已达国际标准。卓胜微:射频前端领域处于国产领先地位,5G通信技术的发展带动射频前端市场需求的快速增长,公司产品在客户端持续渗透。晶丰明源:在LED照明驱动芯片市场处于龙头地位,技术和市场均处于领先水平,出货量全球第一。晶丰明源今年也发了6次涨价函,原因是原材料价格上涨和产能紧张。明微电子:深耕LED驱动业务,显示与照明业务齐头并进,技术研发能力处于行业领先地位。与晶丰明源比主要为LED显示驱动芯片。2020年显示驱动芯片厂商中排名第三,市占率为13%。中颖电子:公司主要产品包括微控制芯片及OLED显示驱动芯片,受益于下游智能家电领域产品需求量和智能化水平的提高,国产替代空间广阔。景嘉微:A股极其稀缺的图形处理器芯片标的,主要应用于军事装备,在国内机载图显领域占据大部分市场份额,正由军用向信创及民用市场拓展。乐鑫科技:全球物联网WiFi-MCU芯片龙头企业,市场份额全球第一,占比超30%。产品下游主要是智能家居、电子消费产品、传感设备及工业控制等,充分受益下游物联网市场发展。富瀚微:安防芯片设计龙头。2020年原本的安防芯片龙头海思受到美国的制裁被动退出市场,公司在下游客户供应链切换过程中抢占先机,实现海思产品80%的替代。2020年公司在安防前端ISP芯片领域市场份额达到60%-70%。同时公司基于视频处理能力进入汽车摄像头市场,渗透率不断提升,提供新增长动能。全志科技:老牌智能终端处理器SOC芯片设计企业。(SOC即片上系统,可以简单的理解为把系统做在一块芯片上,是未来工业界将采用的最主要的产品开发方式。)其产品主要布局物联网,智能家居等领域,京东的智能音箱以及小米的智能扫地机器人就是搭载全志科技的soc芯片。瑞芯微:专注SOC设计,发力电源管理领域。5G 终端对电池续航能力的要求同步提升,进而对电源和功耗的管理提出了更高要求。公司快充芯片与普通的电源管理芯片相比,在占用体积、能量转换效率和散热量等方面均有较大程度的优化,性能和可靠性指标均处于市场领先水平。上海贝岭:重点发展消费类和工控类芯片设计业务,主要目标市场为电表、手机、液晶电视及平板显示、机顶盒等各类工业及消费电子产品。合并南京微盟提高电源管理芯片的市占率。(二)功率半导体新洁能:专业从事MOSFET、IGBT等半导体芯片和功率器件的研发设计及销售。IGBT是目前增速最快的功率器件细分市场,公司产品线完整,成为公司的营收增长新动力。同时公司重视第三代半导体功率器件研发,积极研发新能源汽车用功率半导体。(三)传感器韦尔股份:国内图像传感器设计龙头,业务位于全球前三,国内第一。2019年成功收购了两个影像传感器CIS设计公司豪威和思比科,设计业务收入超过世界第十的芯片设计上市公司。二、芯片制造 在市场需求、国家政策、资本投入的驱动下,全球晶圆代工产业逐渐向中国大陆转移,中国大陆成为全球增速最快的晶圆代工厂。2016-2020年全球新增投产晶圆厂中在投产在中国大陆的比重达到42%,其他分散在全球各国国家。晶圆制造原理为根据设计版图进行掩膜制作,形成模版,在晶圆上批量制造集成电路,芯片通过多次重复运用掺杂、沉积、光刻等工艺,最终在晶圆上实现高集成度的复杂电路。(一)制造厂不少纯设计厂向IDM转型,具备设计、研发、生产能力,我们将这一类的企业归为制造厂一类。1、集成电路中芯国际:无可争议的国产芯片代工龙头,技术与规模均为国内第一,代表集成电路国产替代的最先进制造水平,市占率全球第四。受到制裁之后研发预计会停滞数年,先进制程的生产规模扩张也会同步停滞。紫光国微:智能安全芯片及国内特种 IC 双龙头,“万能芯片”、车规芯片多点开花。子公司国微电子产品线齐全、技术实力强,是国内特种 IC 龙头企业。子公司紫光同芯国内智能卡芯片龙头,市场渗透率进一步提高。子公司紫光同创为国内民用FPGA领军企业,打破了海外寡头垄断,国产替代空间大。富满电子:主营为LED控制及驱动类芯片、电源管理类芯片,同时具有“设计+封测”一体化供应能力。公司已在小间距&Mini LED 控制驱动核心技术领域取得突破,在快充芯片领域也实现率先突破,技术实力国内领先。积极布局 MOSFET 领域,有望充分受益功率半导体国产替代。2、功率半导体泛指处理电力的芯片,其主要功能是将繁杂不一的电力,处理为终端产品所需的规格。比如电流从电动车的电池输出后,通过不同的功率芯片处理,既可以驱动电机,又可以驱动空调和音响。MOSFET:即场效晶体管。主要应用于电脑功率电源、家用电器等,占全球功率器件市场超4成比重IGBT:应用涵盖从工业电源、变频器、新能源汽车、新能源发电到轨道交通、国家电网等一系列领域。华润微:国内功率半导体IDM龙头之一,是国内营业收入最大,产品系列最全的MOSFET厂商。拟与国家集成电路产业投资基金二期及重庆永微电子共同成立润西微电子,建成后预计达到月产3万片12寸中高端功率半导体晶圆生产能力。斯达半导:国内IGBT半导体龙头,全球IGBT模块市场排名第七,是国内唯一进前十的企业,市场优势地位显著。从纯设计厂向IDM转型,以保证产能供应,产品主要用于工控与电器领域。拟定增募资35亿元购买光刻、显影、蚀刻等设备盖厂,设计产能36万片功率半导体,用于高压特色功率芯片和碳化硅,以尽快推出车规级SiC芯片,以完善车用电源市场的产品布局。士兰微:国内功率半导体IDM龙头之一,主要集中于MEMS传感器、高压集成电路、半导体功率器件这三个主要技术方向。捷捷微电:晶闸管龙头企业,产品性能达到国际领先水平。业务范围涵盖芯片设计、晶圆制造及封装测试等全业务环节。今年7月公告拟扩建功率半导体6英寸晶圆及器件封测项目,产品从晶闸管与防护器件等领域,扩展至IGBT模块。此外公司车规级封测产业项目落地,产业链逐步完善。扬杰科技:公司是国内领先的功率半导体 IDM 厂商,具备完善的芯片设计、晶圆制造、封装检测能力。国内功率二极管龙头,并逐步往 MOSFET、IGBT、第三代半导体功率器件等高端产品延伸。应用领域涵盖电源、家电、照明、安防、仪表、通信、工控及汽车电子等多个领域。公司产品在光伏领域应用占比较高,营收约占 15%。闻泰科技:耗资181亿收购来的安世半导体是全球功率半导体龙头,产品主攻消费电子与汽车领域。其主要产品为逻辑器件、分立器件和MOSFET器件,是一家集设计、制造、封装测试为一体的半导体跨国公司。三大业务均位于全球领先地位,逻辑器件排名第二、二极管和晶体管排名第一、车功率MOSFET排名第二。立昂微:茁壮成长的半导体硅片+功率器件领先企业,主攻肖特基二极管芯片。三安光电:国内LED芯片龙头。总投资160亿元的湖南三安半导体基地一期项目今年6月正式投产,这是国内首条、全球第三条碳化硅IDM生产线。3、传感器赛微电子:原名耐威科技 MEMS芯片晶圆制造。2016年赛微通过收购瑞典Silex,获得全球领先工艺IP,切入MEMS纯代工赛道成为MEMS全球代工领头羊。公司目前可生产微流体、微超声、微镜、光开关等多种器件。(二)材料与辅料半导体制造过程相当复杂,先进制程多达500多道工序,需要用到大量材料。因此半导体材料也是整个产业链中细分领域最多的,具有很高的技术和资本壁垒。其中,硅片(晶圆)价值占比最高,超过1/3,其次为电子特种气体占比13%,光掩模、光刻胶及辅助材料各占比12%左右,其余材料占比均低于10%。半导体材料成本占比分类:1、硅片硅片是集成电路制作中最为重要的原材料,市场规模最大。当前全球50%以上的硅材料产能集中在日本,前五大厂商份额超过90%,国内规模最大的是沪硅产业。沪硅产业:纯正的半导体硅片公司,产能、技术国内领先。率先实现300mm硅片规模化生产,打破了大硅片零国产化僵局,但产能利用率低,尚未实现规模效应。由于折旧费用高300mm硅片毛利率为-34.82%,国内三家硅片厂商中毛利率最低,尚未实现盈利。中环股份:中环以光伏硅片为主,占比接近90%,半导体硅片仅占总收入7%。虽然规模不大,但是中环半导体硅片产能提升很快。12英寸20年产能为7万片/月,21~23年将持续放量,产能预计将超过60万片/月。光伏和新能源布局可以实现协同,未来大硅片产能释放,具备龙头溢价空间。立昂微:立昂微硅片产品尺寸较小,且具备抛光片-外延片-功率器件的一体化优势,因此毛利率最高超过40%。15万片/月的12寸硅片预计今年底建设完成。除了半导体硅片,还有功率器件和射频芯片业务。2、电子特种气体半导体生产中几乎每个环节都要用到电子特气,且其很大程度上决定了最终产品性能的好坏。同时所用气体的品种多、质量要求高,因此被称为半导体制造的“血液”。虽然国产化率还不高,但国产替代速度比较快。南大光电:其自主研发的氢类气体磷烷、砷烷,是电子特气中技术壁垒最高的两种,打破了国外技术封锁和垄断,不仅在 LED 行业市场份额持续增长,在集成电路行业也快速实现了产品进口替代,得到了广大客户的高度认可,目前占据国内市场份额达 75%以上。同时公司MO源产品实现了国内进口替代,是全球主要的 MO 源生产商。MO源系列产品是制备LED、新一代太阳能电池、相变存储器、半导体激光器、射频集成电路芯片等的核心原材料。华特气体:公司研发出的20种进口替代产品已实现规模化生产。特气体也通过了全球最大光刻机供应商ASML公司的产品认证,并为中芯国际、华虹宏力等一线企业供货。雅克科技:是半导体材料中的平台型企业,类似北方华创在设备中的地位。业务包括半导体化学材料,电子特气,光刻胶。产品覆盖半导体薄膜、光刻、沉积、刻蚀、清洗等核心环节。前驱体、SOD,打破海外垄断。2020年收购LG化学彩色光刻胶,获得了彩色光刻胶和TFT光刻胶等成熟技术和量产能力,有效弥补国内彩色光刻胶生产的空白。3、光刻胶光刻胶技术壁垒高,价值含量高,被成为半导体材料中的“明珠”。高端光刻胶市场基本被日本企业所把持,使用量最高的KrF光刻胶和ArF光刻胶国产化率低于5%,进口替代空大。华懋科技:主营为安全气囊材料,通过持有徐州博康29%的股权,进军半导体光刻胶产业。徐州博康的光刻胶单体业务占全球市场份额的 5%,并已存储了全球 80%的光刻胶单体产品技术,成为中国唯一的高端光刻胶单体材料研发和规模化生产企业。目前已成功开发出 10+个高端光刻胶产品系列,半导体光刻胶一体化优势显著。彤程新材:主营为特种橡胶助剂,通过控股北京科华进入半导体光刻胶市场。北京科华是唯一列入全球光刻胶八强的中国光刻胶公司,同时也是国内销售额最高的光刻胶公司。中国i线产品国产替代基本上靠北京科华贡献,同时也是唯一可以批量供应KrF光刻胶给8寸和12寸客户的本土光刻胶公司,产品达到世界一流水准,打入中芯国际、长江存储、华虹半导体等国内厂商。晶瑞股份:晶瑞股份的产品包括超净高纯试剂、光刻胶、 功能性材料、锂电池材料和基础化工材料等。光刻胶领域:子公司苏州瑞红作为国内光刻胶领域的先驱,规模生产光刻胶 30 年,产品技术水平和销售额处于国内领先地位。i 线光刻胶已取得了中芯国际天津、扬杰科技的供货订单;高端KrF(248nm)光刻胶完成中试,建成了中试示范线。南大光电:公司成功自主研发出国内首支通过客户认证的 ArF 光刻胶产品,两次通过客户认证。公司目前已经建成 25 吨生产线(5 吨干式和 20 吨湿式),在光刻胶国产化的大趋势下,光刻胶业务将带动公司业绩迈入新的成长空间。4、CMP抛光材料CMP抛光材料、靶材国产化程度最高,部分产品技术标准已到达世界一流水平,本土公司已实现批量供货。抛光液和抛光垫是CMP抛光的主要材料,属于高价值易耗品,毛利高,认证时间长,客户黏性强,竞争格局也相对较好。产品价值上,抛光液高一些,占总材料成本49%,抛光垫占33%,其他材料合计不到20%。安集科技:国内抛光液龙头,目前安集科技在国内没有对手。国内市场份额超过20%,仅次于卡博特。抛光液的技术含量很高,且由于其专用性,绑定大客户后未来增速也很有保证。鼎龙股份:国内抛光垫龙头,主要是做打印复印耗材的,近年来开始布局半导体材料,抛光垫去年开始放量。成为长江存储的一供,对中芯国际也持续放量。5、高纯湿电子化学品超净高纯试剂是指主体成分纯度高于99.99%的化学试剂,主要用于芯片的清洗、蚀刻等制造领域。江化微:国内湿电子化学品龙头,打破国外企业限制壁垒,逐渐实现中低端市场的国产化替代。其超净高纯试剂、光刻胶配套试剂产品具备为平板显示、半导体、光伏等领域提供全系列湿电子化学品能力。晶瑞股份:超净高纯试剂占其营收的20%。超纯双氧水、超纯氨水及在建的高纯硫酸等主导产品已达到G5等级,其它高纯化学品均普遍在G3、G4等级。6、靶材江丰电子:国内高纯溅射靶材行业龙头,目前已可量产用于90-7nm半导体芯片的钽、铜、钛、铝靶材,其中钽靶材在台积电7nm芯片中已量产,5nm技术节点产品也已进入验证阶段。(三)制造设备半导体景气周期有着“设备先行、制造接力、材料缺货”的传导规律。中国大陆迎来投资建厂热潮,对半导体设备的需求也水涨船高。今年上半年,半导体设备的同比出货量相比去年增长了50%,设备制造商接单不暇。由于半导体设备技术壁垒高,研发难度大、周期长,是整个产业中最关键的环节之一。因此要实现我国半导体产业链的自主可控,半导体设备至关重要。半导体设备价值含量高,投资占晶圆厂建设投资 75-80%,当前我国内半导体设备自制率仍较低,2020年国产化率约为16%。但部分领域国内厂商打破空白,技术不断追赶。北方华创:国产半导体设备的绝对龙头,平台属性强。体量大;研发实力强属于国内一线;市占率领先,刻蚀设备国内市占率7%。产品线丰富,产品涵盖热处理、刻蚀、薄膜沉积(PVD、CVD)、清洗等设备。硅片设备-热处理设备-光刻设备-刻蚀设备-离子注入设备-薄膜沉积设备-抛光设备-清洗设备-检测设备1、硅片设备硅片制造是芯片生产的第一道环节,单晶硅生长炉是生产单晶硅的主要半导体设备。晶盛机电:国内晶体硅生长设备龙头,应用横跨半导体光伏两大产业,国内高端市场占有率第一。技术领先,实现大硅片多项技术突破。同时向切片、抛光、外延等设备拓展,目前已经完成技术认证。甚至还出了第三代碳化硅半导体设备,已交付客户使用。2、热处理设备热处理设备即高温炉,主要是对硅片进行氧化、扩散、退火等工艺处理。供应商主要是国外厂商,国内龙头厂商北方华创在热处理设备的各个细分领域均有成熟的产品线,市占率也在逐年上升。北方华创热处理设备在长江存储的占比已经超过了30%。3、光刻设备光刻是将设计好的电路图从光刻版转印到晶圆表面的光刻胶上,便于后续通过刻蚀和离子注入等工艺实现设计电路。光刻是晶圆生产的核心环节,设备包括光刻机和涂胶显影设备。光刻机是晶圆加工设备中技术壁垒最高的设备,该市场为荷兰企业ASML(阿斯麦)所垄断,目前国内具备光刻机生产能力的企业主要是上海微电子。芯源微:涂胶显影机行业龙头,成功打破了国外厂商垄断成为唯一的本土厂商,产品已经陆续通过了下游晶圆厂线的工艺验证,市占率5%。公司近年也开始切入湿法清洗设备领域,跟盛美股份,至纯科技和北方华创等展开竞争。4、刻蚀设备刻蚀设备在晶圆厂设备支出中仅次于光刻设备,且刻蚀设备数量更多,可替代比例更高,目前我国的刻蚀设备是比较先进的。中微公司:刻蚀设备龙头企业,介质刻蚀机已打入 5nm 制程,技术接近世界级水准,国内市占率达13%。北方华创:技术节点达到28nm,刻蚀设备国内市占率7%5、离子注入设备硅片刻蚀后,需要将一些特殊的杂质离子注入到硅衬底去,这就是离子注入机。国内离子注入标的稀缺,仅凯世通和中科信。万业企业:公司主营房地产业务,2018年收购凯世通切入半导体离子注入设备。产品已进入产线验证阶段,并于去年取得4台订单。6、薄膜沉积设备薄膜沉积工艺,分为物理气相沉积(PVD)、化学气相沉积(CVD)和外延三大类。北方华创的PVD设备已经用于28nm生产线中,14nm工艺设备也已实现重大进展,国产化率约 30%。7、抛光设备晶圆制造的后期,需要对硅片表面进行平坦化处理,这就用到了抛光机。该领域的龙头是华海清科,技术领先,合计市占率达 20%。首发申请获上交所上市委员会通过,将于上交所科创板上市。8、清洗设备清洗设备目前国产化率最高,达到20%。随着工艺流程延长且复杂,每个晶片在整个制造过程中需要至少超过200道清洗步骤。是正在申报科创板IPO的盛美股份,深耕半导体清洗设备十余年,,国内企业中市占率最高,产品进入中芯国际、长江存储、SK海力士等企业供应链。盛美股份:科创板IPO正式提交注册的盛美股份是半导体清洗设备龙头,技术优势领跑同行业。占据国内80%的市场份额,其余20%则由北方华创、芯源微和至纯科技三家公司瓜分。至纯科技:公司目前湿法清洗设备订单充足,排产计划已经到了2022年。设备可实现28nm湿法工艺全覆盖,可以满足国内绝大部分晶圆厂的要求,单片清洗设备预计会在下半年批量交付。9、检测设备检测设备主要用于检测芯片性能与缺陷,贯穿于半导体制造过程中的每一步主要工艺,按不同环节分为前道测试和后道测试设备。前道测试设备主要用于晶圆加工环节,属于质量检测,壁垒更高。目前国内企业竞争力较弱,国产化率低于5%,处于技术、产品突破阶段。精测电子:以半导体前道检测设备为主,同时布局后道,形成半导体测试领域全覆盖。其自动检测设备基本实现国产化,且已在国内一线客户实现批量重复订单。赛腾股份:深耕自动化组装、自动化检测设备,通过收购日本Optima进入半导体检测设备领域。Optima在晶圆缺陷检测设备上有成熟的产品线,该技术储备对国内来说是稀缺的,由此占据了发展先机。三、芯片封装测试中国凭借低廉的劳动力,首先承接了对劳动力需求较大,技术要求较低的半导体封测业务。目前大陆的芯片封装、测试整体上已经达到国际先进水平,产业链条(封测厂、装备、材料)比较完整。(一)封测装备检测设备的后道测试设备主要用于晶圆加工后的封测环节,主要为电学检测。设备主要分为测试机(ATE)、分选机、探针台,三者中,测试机市场最大,价值量更高。伴随三大封测厂商的扩产计划,会直接增加对国产后道测试设备的需求。长川科技:国产半导体测试设备综合龙,头分选机为主、测试机为辅,多赛道布局。产品具备竞争力,主要性能指标已达国内领先、接近国外先进技术水平。华峰测控:测试机设备龙头,已可实现国产替代。技术国内领先,接近世界一流水平,进入了封测龙头供应链。测试机在半导体检测设备中价值占比高,华峰测控的毛利达到80%,领先同行,盈利能力强。但同时受制于单一赛道,成长速度受限。(二)封测材料康强电子:国内半导体封装材料龙头,是我国规模最大引线框架生产企业。(三)封测厂我国是封测大国,拥有 “封测三杰”——长电科技、通富微电、华天科技,此前都宣布了各自的扩产计划。长电科技:国内封测企业的龙头,全球排名第三,市占率达14.4%。高端封装技术与国际第一梯队齐头并进,公司在收购星科金朋后进一步发展了SiP、晶圆级和2.5D/3D等先进封装技术,并实现大规模量产远超传统封装的产量和销量。通富微电:全球第六的封测厂,市占率7%。聚焦大客户战略,长期布局存储、微处理器等产品的先进封装技术。日前开发了国内第一款 SiP 电源模块的封装技术,该技术可应用于包括 5G 在内的各种基站和网络电源,目前已实现批量生产。华天科技:通过自建及收购拥有多个国内外多个厂区,低端、中端、高端全方位布局来自微信
半导体产业链详细梳理 半导体在线2021年09月22日16:24现在的全球半导体行业,处于新一轮景气周期上行阶段。而国内的半导体产业,不仅受到全球性大周期的影响,还有一条非常硬核的逻辑,就是国产替代。中国虽已经成为全球最大的半导体消费国,但我国的芯片自给率低,2020年我国集成电路自给率仅为15.9%,国产替代仍有很大的替代空间。从需求端来看,受益于“万物互联+国产替代”以及新能源汽车的助攻,芯片需求全面拉升;供给端受疫情冲击以及制裁下扩产速度减慢。跟传统周期性行业类似,半导体也存在着产能、库存和需求的不可能三角。由于从投资到产能释放的前置时间较长,如此扩大了芯片的缺口。年初开始,晶圆大厂们纷纷公布了一大波超预期的资本开支计划。下图为半导体产业从材料到应用终端流程图:如图:芯片产业链主要包括设计、制造、封装与测试三大环节与半导体设备及材料两大支柱产业。本文将按照该框架梳理整个芯片行业产业链。芯片设计包括工具软件、设计公司芯片制造包括制造厂、制造设备、材料与辅料芯片封测包括封测厂、封测设备、辅材打个通俗的比喻,芯片设计环节就像房地产的图纸设计,圆晶代工就是施工建房,封测就是将毛坯房变为精装房。一、芯片设计芯片设计是产业链中重要的一环,影响后续芯片产品的功能、性能和成本,对研发实力要求较高。根据不同的下游应用,可分为四类:集成电路:存储器、逻辑芯片(CPU、GPU)、微处理器(MPU)、模拟芯片分立器件(含功率半导体):MOSFET、IGBT、二极管、晶闸管传感器:MEMS、图像传感器光电器件(一)集成电路兆易创新:国内闪存芯片存储器及MCU微控制器设计双龙头。在全球NORFlash的市场占有率为6%,已跃居全球第三。公司作为国内MCU微控制器市场的龙头公司,2020年销售接近2亿颗,2021年公司业绩将伴随着工控等领域的快速放量,迎来快速发展的时期。北京君正:收购北京矽成,成为国内稀缺的汽车存储芯片领军企业。北京矽成在全球车用DRAM存储芯片市占率15%,全球排名第二。收益于汽车电动化与智能化对车用存储芯片数量和容量要求的提升,实现量价齐升。微处理器芯片业务收益于智能终端硬件需求的爆发。公告拟定增募集资金拓展车载LED照明芯片。国科微:我国固态存储芯片技术领先代表,最新产品达到国际平均水平、深耕智能安防监控芯片,积极布局AI智能监控芯片。圣邦股份:国内模拟芯片龙头,电源管理芯片及信号链芯片受益于5G、工业驱动、人工智能和汽车升级,叠加国产替代,空间广阔。思瑞浦:业务与圣邦股份高度重合,国产信号链类模拟芯片龙头企业。公司的信号链模拟芯片为5G射频模拟芯片的主要组成部分,综合性能已达国际标准。卓胜微:射频前端领域处于国产领先地位,5G通信技术的发展带动射频前端市场需求的快速增长,公司产品在客户端持续渗透。晶丰明源:在LED照明驱动芯片市场处于龙头地位,技术和市场均处于领先水平,出货量全球第一。晶丰明源今年也发了6次涨价函,原因是原材料价格上涨和产能紧张。明微电子:深耕LED驱动业务,显示与照明业务齐头并进,技术研发能力处于行业领先地位。与晶丰明源比主要为LED显示驱动芯片。2020年显示驱动芯片厂商中排名第三,市占率为13%。中颖电子:公司主要产品包括微控制芯片及OLED显示驱动芯片,受益于下游智能家电领域产品需求量和智能化水平的提高,国产替代空间广阔。景嘉微:A股极其稀缺的图形处理器芯片标的,主要应用于军事装备,在国内机载图显领域占据大部分市场份额,正由军用向信创及民用市场拓展。乐鑫科技:全球物联网WiFi-MCU芯片龙头企业,市场份额全球第一,占比超30%。产品下游主要是智能家居、电子消费产品、传感设备及工业控制等,充分受益下游物联网市场发展。富瀚微:安防芯片设计龙头。2020年原本的安防芯片龙头海思受到美国的制裁被动退出市场,公司在下游客户供应链切换过程中抢占先机,实现海思产品80%的替代。2020年公司在安防前端ISP芯片领域市场份额达到60%-70%。同时公司基于视频处理能力进入汽车摄像头市场,渗透率不断提升,提供新增长动能。全志科技:老牌智能终端处理器SOC芯片设计企业。(SOC即片上系统,可以简单的理解为把系统做在一块芯片上,是未来工业界将采用的最主要的产品开发方式。)其产品主要布局物联网,智能家居等领域,京东的智能音箱以及小米的智能扫地机器人就是搭载全志科技的soc芯片。瑞芯微:专注SOC设计,发力电源管理领域。5G 终端对电池续航能力的要求同步提升,进而对电源和功耗的管理提出了更高要求。公司快充芯片与普通的电源管理芯片相比,在占用体积、能量转换效率和散热量等方面均有较大程度的优化,性能和可靠性指标均处于市场领先水平。上海贝岭:重点发展消费类和工控类芯片设计业务,主要目标市场为电表、手机、液晶电视及平板显示、机顶盒等各类工业及消费电子产品。合并南京微盟提高电源管理芯片的市占率。(二)功率半导体新洁能:专业从事MOSFET、IGBT等半导体芯片和功率器件的研发设计及销售。IGBT是目前增速最快的功率器件细分市场,公司产品线完整,成为公司的营收增长新动力。同时公司重视第三代半导体功率器件研发,积极研发新能源汽车用功率半导体。(三)传感器韦尔股份:国内图像传感器设计龙头,业务位于全球前三,国内第一。2019年成功收购了两个影像传感器CIS设计公司豪威和思比科,设计业务收入超过世界第十的芯片设计上市公司。二、芯片制造 在市场需求、国家政策、资本投入的驱动下,全球晶圆代工产业逐渐向中国大陆转移,中国大陆成为全球增速最快的晶圆代工厂。2016-2020年全球新增投产晶圆厂中在投产在中国大陆的比重达到42%,其他分散在全球各国国家。晶圆制造原理为根据设计版图进行掩膜制作,形成模版,在晶圆上批量制造集成电路,芯片通过多次重复运用掺杂、沉积、光刻等工艺,最终在晶圆上实现高集成度的复杂电路。(一)制造厂不少纯设计厂向IDM转型,具备设计、研发、生产能力,我们将这一类的企业归为制造厂一类。1、集成电路中芯国际:无可争议的国产芯片代工龙头,技术与规模均为国内第一,代表集成电路国产替代的最先进制造水平,市占率全球第四。受到制裁之后研发预计会停滞数年,先进制程的生产规模扩张也会同步停滞。紫光国微:智能安全芯片及国内特种 IC 双龙头,“万能芯片”、车规芯片多点开花。子公司国微电子产品线齐全、技术实力强,是国内特种 IC 龙头企业。子公司紫光同芯国内智能卡芯片龙头,市场渗透率进一步提高。子公司紫光同创为国内民用FPGA领军企业,打破了海外寡头垄断,国产替代空间大。富满电子:主营为LED控制及驱动类芯片、电源管理类芯片,同时具有“设计+封测”一体化供应能力。公司已在小间距&Mini LED 控制驱动核心技术领域取得突破,在快充芯片领域也实现率先突破,技术实力国内领先。积极布局 MOSFET 领域,有望充分受益功率半导体国产替代。2、功率半导体泛指处理电力的芯片,其主要功能是将繁杂不一的电力,处理为终端产品所需的规格。比如电流从电动车的电池输出后,通过不同的功率芯片处理,既可以驱动电机,又可以驱动空调和音响。MOSFET:即场效晶体管。主要应用于电脑功率电源、家用电器等,占全球功率器件市场超4成比重IGBT:应用涵盖从工业电源、变频器、新能源汽车、新能源发电到轨道交通、国家电网等一系列领域。华润微:国内功率半导体IDM龙头之一,是国内营业收入最大,产品系列最全的MOSFET厂商。拟与国家集成电路产业投资基金二期及重庆永微电子共同成立润西微电子,建成后预计达到月产3万片12寸中高端功率半导体晶圆生产能力。斯达半导:国内IGBT半导体龙头,全球IGBT模块市场排名第七,是国内唯一进前十的企业,市场优势地位显著。从纯设计厂向IDM转型,以保证产能供应,产品主要用于工控与电器领域。拟定增募资35亿元购买光刻、显影、蚀刻等设备盖厂,设计产能36万片功率半导体,用于高压特色功率芯片和碳化硅,以尽快推出车规级SiC芯片,以完善车用电源市场的产品布局。士兰微:国内功率半导体IDM龙头之一,主要集中于MEMS传感器、高压集成电路、半导体功率器件这三个主要技术方向。捷捷微电:晶闸管龙头企业,产品性能达到国际领先水平。业务范围涵盖芯片设计、晶圆制造及封装测试等全业务环节。今年7月公告拟扩建功率半导体6英寸晶圆及器件封测项目,产品从晶闸管与防护器件等领域,扩展至IGBT模块。此外公司车规级封测产业项目落地,产业链逐步完善。扬杰科技:公司是国内领先的功率半导体 IDM 厂商,具备完善的芯片设计、晶圆制造、封装检测能力。国内功率二极管龙头,并逐步往 MOSFET、IGBT、第三代半导体功率器件等高端产品延伸。应用领域涵盖电源、家电、照明、安防、仪表、通信、工控及汽车电子等多个领域。公司产品在光伏领域应用占比较高,营收约占 15%。闻泰科技:耗资181亿收购来的安世半导体是全球功率半导体龙头,产品主攻消费电子与汽车领域。其主要产品为逻辑器件、分立器件和MOSFET器件,是一家集设计、制造、封装测试为一体的半导体跨国公司。三大业务均位于全球领先地位,逻辑器件排名第二、二极管和晶体管排名第一、车功率MOSFET排名第二。立昂微:茁壮成长的半导体硅片+功率器件领先企业,主攻肖特基二极管芯片。三安光电:国内LED芯片龙头。总投资160亿元的湖南三安半导体基地一期项目今年6月正式投产,这是国内首条、全球第三条碳化硅IDM生产线。3、传感器赛微电子:原名耐威科技 MEMS芯片晶圆制造。2016年赛微通过收购瑞典Silex,获得全球领先工艺IP,切入MEMS纯代工赛道成为MEMS全球代工领头羊。公司目前可生产微流体、微超声、微镜、光开关等多种器件。(二)材料与辅料半导体制造过程相当复杂,先进制程多达500多道工序,需要用到大量材料。因此半导体材料也是整个产业链中细分领域最多的,具有很高的技术和资本壁垒。其中,硅片(晶圆)价值占比最高,超过1/3,其次为电子特种气体占比13%,光掩模、光刻胶及辅助材料各占比12%左右,其余材料占比均低于10%。半导体材料成本占比分类:1、硅片硅片是集成电路制作中最为重要的原材料,市场规模最大。当前全球50%以上的硅材料产能集中在日本,前五大厂商份额超过90%,国内规模最大的是沪硅产业。沪硅产业:纯正的半导体硅片公司,产能、技术国内领先。率先实现300mm硅片规模化生产,打破了大硅片零国产化僵局,但产能利用率低,尚未实现规模效应。由于折旧费用高300mm硅片毛利率为-34.82%,国内三家硅片厂商中毛利率最低,尚未实现盈利。中环股份:中环以光伏硅片为主,占比接近90%,半导体硅片仅占总收入7%。虽然规模不大,但是中环半导体硅片产能提升很快。12英寸20年产能为7万片/月,21~23年将持续放量,产能预计将超过60万片/月。光伏和新能源布局可以实现协同,未来大硅片产能释放,具备龙头溢价空间。立昂微:立昂微硅片产品尺寸较小,且具备抛光片-外延片-功率器件的一体化优势,因此毛利率最高超过40%。15万片/月的12寸硅片预计今年底建设完成。除了半导体硅片,还有功率器件和射频芯片业务。2、电子特种气体半导体生产中几乎每个环节都要用到电子特气,且其很大程度上决定了最终产品性能的好坏。同时所用气体的品种多、质量要求高,因此被称为半导体制造的“血液”。虽然国产化率还不高,但国产替代速度比较快。南大光电:其自主研发的氢类气体磷烷、砷烷,是电子特气中技术壁垒最高的两种,打破了国外技术封锁和垄断,不仅在 LED 行业市场份额持续增长,在集成电路行业也快速实现了产品进口替代,得到了广大客户的高度认可,目前占据国内市场份额达 75%以上。同时公司MO源产品实现了国内进口替代,是全球主要的 MO 源生产商。MO源系列产品是制备LED、新一代太阳能电池、相变存储器、半导体激光器、射频集成电路芯片等的核心原材料。华特气体:公司研发出的20种进口替代产品已实现规模化生产。特气体也通过了全球最大光刻机供应商ASML公司的产品认证,并为中芯国际、华虹宏力等一线企业供货。雅克科技:是半导体材料中的平台型企业,类似北方华创在设备中的地位。业务包括半导体化学材料,电子特气,光刻胶。产品覆盖半导体薄膜、光刻、沉积、刻蚀、清洗等核心环节。前驱体、SOD,打破海外垄断。2020年收购LG化学彩色光刻胶,获得了彩色光刻胶和TFT光刻胶等成熟技术和量产能力,有效弥补国内彩色光刻胶生产的空白。3、光刻胶光刻胶技术壁垒高,价值含量高,被成为半导体材料中的“明珠”。高端光刻胶市场基本被日本企业所把持,使用量最高的KrF光刻胶和ArF光刻胶国产化率低于5%,进口替代空大。华懋科技:主营为安全气囊材料,通过持有徐州博康29%的股权,进军半导体光刻胶产业。徐州博康的光刻胶单体业务占全球市场份额的 5%,并已存储了全球 80%的光刻胶单体产品技术,成为中国唯一的高端光刻胶单体材料研发和规模化生产企业。目前已成功开发出 10+个高端光刻胶产品系列,半导体光刻胶一体化优势显著。彤程新材:主营为特种橡胶助剂,通过控股北京科华进入半导体光刻胶市场。北京科华是唯一列入全球光刻胶八强的中国光刻胶公司,同时也是国内销售额最高的光刻胶公司。中国i线产品国产替代基本上靠北京科华贡献,同时也是唯一可以批量供应KrF光刻胶给8寸和12寸客户的本土光刻胶公司,产品达到世界一流水准,打入中芯国际、长江存储、华虹半导体等国内厂商。晶瑞股份:晶瑞股份的产品包括超净高纯试剂、光刻胶、 功能性材料、锂电池材料和基础化工材料等。光刻胶领域:子公司苏州瑞红作为国内光刻胶领域的先驱,规模生产光刻胶 30 年,产品技术水平和销售额处于国内领先地位。i 线光刻胶已取得了中芯国际天津、扬杰科技的供货订单;高端KrF(248nm)光刻胶完成中试,建成了中试示范线。南大光电:公司成功自主研发出国内首支通过客户认证的 ArF 光刻胶产品,两次通过客户认证。公司目前已经建成 25 吨生产线(5 吨干式和 20 吨湿式),在光刻胶国产化的大趋势下,光刻胶业务将带动公司业绩迈入新的成长空间。4、CMP抛光材料CMP抛光材料、靶材国产化程度最高,部分产品技术标准已到达世界一流水平,本土公司已实现批量供货。抛光液和抛光垫是CMP抛光的主要材料,属于高价值易耗品,毛利高,认证时间长,客户黏性强,竞争格局也相对较好。产品价值上,抛光液高一些,占总材料成本49%,抛光垫占33%,其他材料合计不到20%。安集科技:国内抛光液龙头,目前安集科技在国内没有对手。国内市场份额超过20%,仅次于卡博特。抛光液的技术含量很高,且由于其专用性,绑定大客户后未来增速也很有保证。鼎龙股份:国内抛光垫龙头,主要是做打印复印耗材的,近年来开始布局半导体材料,抛光垫去年开始放量。成为长江存储的一供,对中芯国际也持续放量。5、高纯湿电子化学品超净高纯试剂是指主体成分纯度高于99.99%的化学试剂,主要用于芯片的清洗、蚀刻等制造领域。江化微:国内湿电子化学品龙头,打破国外企业限制壁垒,逐渐实现中低端市场的国产化替代。其超净高纯试剂、光刻胶配套试剂产品具备为平板显示、半导体、光伏等领域提供全系列湿电子化学品能力。晶瑞股份:超净高纯试剂占其营收的20%。超纯双氧水、超纯氨水及在建的高纯硫酸等主导产品已达到G5等级,其它高纯化学品均普遍在G3、G4等级。6、靶材江丰电子:国内高纯溅射靶材行业龙头,目前已可量产用于90-7nm半导体芯片的钽、铜、钛、铝靶材,其中钽靶材在台积电7nm芯片中已量产,5nm技术节点产品也已进入验证阶段。(三)制造设备半导体景气周期有着“设备先行、制造接力、材料缺货”的传导规律。中国大陆迎来投资建厂热潮,对半导体设备的需求也水涨船高。今年上半年,半导体设备的同比出货量相比去年增长了50%,设备制造商接单不暇。由于半导体设备技术壁垒高,研发难度大、周期长,是整个产业中最关键的环节之一。因此要实现我国半导体产业链的自主可控,半导体设备至关重要。半导体设备价值含量高,投资占晶圆厂建设投资 75-80%,当前我国内半导体设备自制率仍较低,2020年国产化率约为16%。但部分领域国内厂商打破空白,技术不断追赶。北方华创:国产半导体设备的绝对龙头,平台属性强。体量大;研发实力强属于国内一线;市占率领先,刻蚀设备国内市占率7%。产品线丰富,产品涵盖热处理、刻蚀、薄膜沉积(PVD、CVD)、清洗等设备。硅片设备-热处理设备-光刻设备-刻蚀设备-离子注入设备-薄膜沉积设备-抛光设备-清洗设备-检测设备1、硅片设备硅片制造是芯片生产的第一道环节,单晶硅生长炉是生产单晶硅的主要半导体设备。晶盛机电:国内晶体硅生长设备龙头,应用横跨半导体光伏两大产业,国内高端市场占有率第一。技术领先,实现大硅片多项技术突破。同时向切片、抛光、外延等设备拓展,目前已经完成技术认证。甚至还出了第三代碳化硅半导体设备,已交付客户使用。2、热处理设备热处理设备即高温炉,主要是对硅片进行氧化、扩散、退火等工艺处理。供应商主要是国外厂商,国内龙头厂商北方华创在热处理设备的各个细分领域均有成熟的产品线,市占率也在逐年上升。北方华创热处理设备在长江存储的占比已经超过了30%。3、光刻设备光刻是将设计好的电路图从光刻版转印到晶圆表面的光刻胶上,便于后续通过刻蚀和离子注入等工艺实现设计电路。光刻是晶圆生产的核心环节,设备包括光刻机和涂胶显影设备。光刻机是晶圆加工设备中技术壁垒最高的设备,该市场为荷兰企业ASML(阿斯麦)所垄断,目前国内具备光刻机生产能力的企业主要是上海微电子。芯源微:涂胶显影机行业龙头,成功打破了国外厂商垄断成为唯一的本土厂商,产品已经陆续通过了下游晶圆厂线的工艺验证,市占率5%。公司近年也开始切入湿法清洗设备领域,跟盛美股份,至纯科技和北方华创等展开竞争。4、刻蚀设备刻蚀设备在晶圆厂设备支出中仅次于光刻设备,且刻蚀设备数量更多,可替代比例更高,目前我国的刻蚀设备是比较先进的。中微公司:刻蚀设备龙头企业,介质刻蚀机已打入 5nm 制程,技术接近世界级水准,国内市占率达13%。北方华创:技术节点达到28nm,刻蚀设备国内市占率7%5、离子注入设备硅片刻蚀后,需要将一些特殊的杂质离子注入到硅衬底去,这就是离子注入机。国内离子注入标的稀缺,仅凯世通和中科信。万业企业:公司主营房地产业务,2018年收购凯世通切入半导体离子注入设备。产品已进入产线验证阶段,并于去年取得4台订单。6、薄膜沉积设备薄膜沉积工艺,分为物理气相沉积(PVD)、化学气相沉积(CVD)和外延三大类。北方华创的PVD设备已经用于28nm生产线中,14nm工艺设备也已实现重大进展,国产化率约 30%。7、抛光设备晶圆制造的后期,需要对硅片表面进行平坦化处理,这就用到了抛光机。该领域的龙头是华海清科,技术领先,合计市占率达 20%。首发申请获上交所上市委员会通过,将于上交所科创板上市。8、清洗设备清洗设备目前国产化率最高,达到20%。随着工艺流程延长且复杂,每个晶片在整个制造过程中需要至少超过200道清洗步骤。是正在申报科创板IPO的盛美股份,深耕半导体清洗设备十余年,,国内企业中市占率最高,产品进入中芯国际、长江存储、SK海力士等企业供应链。盛美股份:科创板IPO正式提交注册的盛美股份是半导体清洗设备龙头,技术优势领跑同行业。占据国内80%的市场份额,其余20%则由北方华创、芯源微和至纯科技三家公司瓜分。至纯科技:公司目前湿法清洗设备订单充足,排产计划已经到了2022年。设备可实现28nm湿法工艺全覆盖,可以满足国内绝大部分晶圆厂的要求,单片清洗设备预计会在下半年批量交付。9、检测设备检测设备主要用于检测芯片性能与缺陷,贯穿于半导体制造过程中的每一步主要工艺,按不同环节分为前道测试和后道测试设备。前道测试设备主要用于晶圆加工环节,属于质量检测,壁垒更高。目前国内企业竞争力较弱,国产化率低于5%,处于技术、产品突破阶段。精测电子:以半导体前道检测设备为主,同时布局后道,形成半导体测试领域全覆盖。其自动检测设备基本实现国产化,且已在国内一线客户实现批量重复订单。赛腾股份:深耕自动化组装、自动化检测设备,通过收购日本Optima进入半导体检测设备领域。Optima在晶圆缺陷检测设备上有成熟的产品线,该技术储备对国内来说是稀缺的,由此占据了发展先机。三、芯片封装测试中国凭借低廉的劳动力,首先承接了对劳动力需求较大,技术要求较低的半导体封测业务。目前大陆的芯片封装、测试整体上已经达到国际先进水平,产业链条(封测厂、装备、材料)比较完整。(一)封测装备检测设备的后道测试设备主要用于晶圆加工后的封测环节,主要为电学检测。设备主要分为测试机(ATE)、分选机、探针台,三者中,测试机市场最大,价值量更高。伴随三大封测厂商的扩产计划,会直接增加对国产后道测试设备的需求。长川科技:国产半导体测试设备综合龙,头分选机为主、测试机为辅,多赛道布局。产品具备竞争力,主要性能指标已达国内领先、接近国外先进技术水平。华峰测控:测试机设备龙头,已可实现国产替代。技术国内领先,接近世界一流水平,进入了封测龙头供应链。测试机在半导体检测设备中价值占比高,华峰测控的毛利达到80%,领先同行,盈利能力强。但同时受制于单一赛道,成长速度受限。(二)封测材料康强电子:国内半导体封装材料龙头,是我国规模最大引线框架生产企业。(三)封测厂我国是封测大国,拥有 “封测三杰”——长电科技、通富微电、华天科技,此前都宣布了各自的扩产计划。长电科技:国内封测企业的龙头,全球排名第三,市占率达14.4%。高端封装技术与国际第一梯队齐头并进,公司在收购星科金朋后进一步发展了SiP、晶圆级和2.5D/3D等先进封装技术,并实现大规模量产远超传统封装的产量和销量。通富微电:全球第六的封测厂,市占率7%。聚焦大客户战略,长期布局存储、微处理器等产品的先进封装技术。日前开发了国内第一款 SiP 电源模块的封装技术,该技术可应用于包括 5G 在内的各种基站和网络电源,目前已实现批量生产。华天科技:通过自建及收购拥有多个国内外多个厂区,低端、中端、高端全方位布局来自微信 -
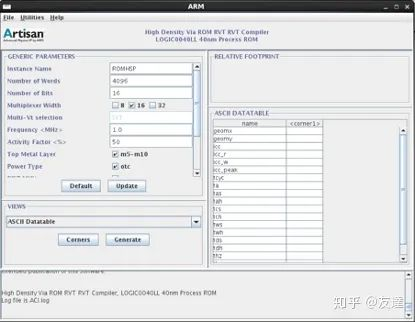
科普:Memory Compiler生成的Register file和SRAM有何区别? IP与S0C设计2021年09月03日04:01前两期,我们分别对OTP和MTP,RAM和ROM进行了比较。这一次,我们来谈谈Memory Compiler,以及通过它生成的Register file和SRAM。什么是Memory Compiler ?Memory Compiler,内存编译器。顾名思义,是用来生成不同容量memory的工具,输入参数,我们就可以得到生成的文件。生成的文件包括:前端设计verilog模型、逻辑综合的时序库、后端需要的电路网表和LEF/GDS版图文件、其他DFT验证相关的、datasheet手册等等。Memory Compiler由供应商提供,往往是不通用的,界面也不尽相同。同一个厂商的不同工艺下,Memory Compiler不同。相同工艺,不同厂商,Memory Compiler也不同。内存编译器通常是供应商的知识产权,其功能是根据客户的需求生成各种类型的memory。一般的Memory Compiler提供五个ram脚本(rf_sp,sram_sp,rf_tp,sram_dp,rom)。这意味着可以生成1 Port Register file、Single Port SRAM、2 Port Register file、Dual Port SRAM以及ROM。不同的厂商或许还拥有特殊工艺。一般来说,MC只生成常用的memory,特殊的往往需要定制或者组合。考虑到面积和性能,又可以划分为High Speed和High Density等等。图源知乎:SMIC 的Memory Compiler,由Artisan公司提供Memory Compiler使用介绍在使用Memory Compiler时,请务必确保你的RAM从头到位的规格与设定都相同,否则会造成一些不可避免的错误。首先在RTL代码阶段,要用到RAM就要用到verilog代码,此时不需要着急产生其他后阶段的必要数据,因为RTL代码阶段只需要行为级模型即可。当进入门级代码后,RAM compiler就要产生其他的相关数据了,同时要考虑RAM版图的位置与方向。由于重大的设计不会一蹴而就,所以有两个重点,第一个是每次使用RAM compiler时都一定要让它产生特性设置文档,避免忘记自己做过的设定。第二件事是对应的文件名要定义好,否则RAM的方向不同但是又用到了相同的文件名,就会把原始数据覆盖掉。RTL阶段在RTL阶段主要只是产生verilog行为级和设置文件。因为在RTL阶段不需要考虑RAM的位置信息。Memory Compiler提供多种选择,在这个阶段,选择生成RF或是SRAM,以及确定端口数量。如果容量比较大的话,相同设置下,单端口比双端口面积要小,速度也要快,功耗要低。综合与布局布线阶段为了避免重新启用Memory Compiler与以前设置有出入,所以最好一次性将Memory Compiler能够产生的相关数据一并输出。在这里,Memory Compiler还需要产生3种数据。 .LIB 该数据是RAM的时序信息文件 .VCLEF 布局布线工具需要使用的物理信息文件 .SPEC RAM的注释文件在布局布线前,需要考虑RAM的长与宽,估计它的位置与方向,尽量让功能想关的模块靠近一些。将产生的.LIB文件转换成.DB文件,就可以把Memory Compiler生成的RAM加入到代码中进行综合了。在综合工具的脚本中的serch_path下加入RAM的DB文件地址即可。以上为Memory Compiler大致的使用流程,不同的工具在细节上或许有所区别,但大体流程如此。苏州腾芯微电子的Memory Compiler界面接下来,我们来聊一聊,生成的memory——Register file和SRAM。Register file与SRAM的比较首先,厘清一下概念上的问题,Register file和很多的registers不是同一个概念。我们在IC设计里谈到register时,常常是指D触发器,而Register file是一种memory。那么,同为Memory Compiler生成,RF和SRAM有什么区别呢?在比较中,不同规格相比较显然不够客观,也不能让我们更清晰地认识到它们的差异。在比较前,我们需要先把端口的概念搞清楚: 1 port / single port:单端口,读写同端口,需要WE控制输入输出 2 port:双端口,读写分开,输入输出端口固定,可以不用WE控制 dual port:同样是双端口,但读写端口不固定,且都可读可写 RF 的端口示意图SRAM 的端口示意图所以我们应当把1P RF和SP SRAM,2P RF和DP SRAM比较,才有意义。1 Port Register file 和 Single Port SRAM同为单端口,从外部端口看,难以区分1P RF和SP SRAM的区别,但是我们可以从以下几个方面,来进行区分。首先我们以Memory Size:512*32的1P RF和SP SRAM为例。此为1P RF此为SP SRAM从datasheet直观上来看,SRAM比Register file多了OEN(输出使能)。除此之外,Register file和SRAM两者相比,SRAM的最大容量比RF要大。相同配置下,RF的面积更大,功耗更低。在mem比较小的情况下用RF划算,并且同样的mem,RF的长宽比会更小,方便后端floorplan。大容量的时候,SRAM的速度是有优势的。并且SRAM速度快,面积小。同样大小的RF,面积就很大了,速度也慢下来了。所以简单来说,小容量选RF,大容量选SRAM。2P Register file 和 Dual Port SRAM比起1P RF与SP SRAM的比较,2P RF与DP SRAM的差异较为直观。2P RF有一个输入数据总线,一个输出的数据总线。DP SRAM有两个数据输入总线,两个数据输出总线。换句话说,2P RF是一组信号,读写端口固定;而DP SRAM则有两组信号,读写不分开。且两组信号,每组都有自己的地址,输入数据总线,输出数据总线,时钟,读/写控制。这两组可以分别往存储单元写,或从存储单元读出。读可以一直读,写时数据可能存储单元数据更新,数据也可能输出端口。DP SRAM就好像2个SP SRAM共用存储单元。具体的应用,需要结合设计人员和项目自身的需求来选用。小容量,地址少的用RF。有两个外设要同时读写SRAM的,就要用DP SRAM。涉及到具体的选取,则需要由设计人员自己做判断了。以下为读写时序图:图源:数字IC自修室来自微信
-
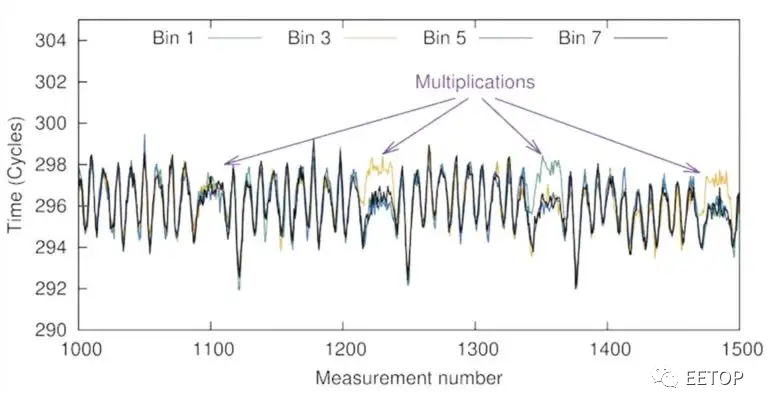
SoC硬漏洞 EET0P编译EET0P2021年08月06日04:32来源:EETOP编译整理自semiwiki 我经常看到有关计算机系统被黑客入侵、某某CPU被爆出漏洞等的文章。那么有哪些最佳实践可以让您的新的或现有的电子系统更能抵御攻击,并且不易受到攻击?Gajinder Panesar 和 Tim Ramsdale 分别是来自 Siemens EDA 和 Agile Analog 的两位专家,他们联手撰写了一份 15 页的白皮书,“ SoC 漏洞和模拟威胁的演进格局” 。接下来我们分享一些从阅读本文中学到的要点。(关注EETOP公众号,后台输入关键词:漏洞 ,获取白皮书)漏洞 一个安全前提是仅依靠软件更新来修补漏洞是不够的,因此应考虑将安全性作为硬件设计的一部分。甚至还有一个名为OpenTitan的开源项目,可帮助您为硅信任根(RoT) 芯片构建透明、高质量的参考设计和集成指南。使用基于硬件的 RoT,只能运行与已知签名进行比较的固件,从而阻止加载任何被黑固件的尝试。 黑客们变得越来越有创造力和足智多能,通过硬件测量来检查RSA算法中的密钥,,并注意到操作执行方式的微小变化,也就是侧通道攻击。下面显示的是紫色箭头的四个乘法部分,那么负尖峰是算法中的平方和模块化还原的一部分。侧道攻击 可以通过检查以下几件事来揭示安全线索:缓存活动执行管道电磁 (EM)值电压变化电流变化 侧道攻击的另一个例子是黑客试图猜测其中一个关键字节,并且在下图的350 附近他们找到了一个正确的关键字节。攻击输出与子密钥猜测的样本数 黑客攻击的目标包括 5G 基础设施、边缘服务器、物联网设备、云计算、自动驾驶汽车、工业机器人。黑客正在使用统计方法来衡量电子设备,为安全漏洞提供线索。一种对策是让硬件设计团队添加随机电噪声。正如德国安全公司LevelDown所记录的那样,黑客使用的另一种技术是在特定时间点故意干扰电源,然后将存储的位翻转到不安全状态。甚至一些较旧的处理器也存在黑客使用非法操作码的漏洞,从而使处理器处于易受攻击的状态。温度是另一种技术,攻击者可以在高于或低于指定温度的温度下运行 SoC,以改变内部状态,甚至从物理不可克隆功能 (PUF) 中提取私钥。攻击者可能利用电源轨的电压变化,以减慢或加快逻辑,导致内部比特翻转,并达到非法状态。如果黑客可以物理访问您的电子系统,他们通过改变占空比或引入毛刺直接控制时钟输入将改变内部逻辑。 ChipWhisperer是一家拥有开源系统的公司,使用侧信道功率分析和故障注入来暴露嵌入式系统的弱点。使用电磁(EM)辐射进行故障注入是ChipShouter公司使用的一种技术,但它们必须与内部时钟边缘精确定时,以创造一个可重复的故障。即使是在去掉盖子的IC封装上使用激光,也能迫使一个SoC出现内部错误。 漏洞对策 时钟毛刺:内部生成的比较源。 电源毛刺:断电检测器 温度攻击:温度传感器 在白皮书中,他们提供了一种名为Tessent Embedded Analytics的产品,它将硬件监视器嵌入到您的 SoC 中,然后与基于消息的架构进行通信。添加来自Agile Analog 的硬件安全 IP 可以检查时钟、电压和温度:来自 Agile Analog 的监视器这些监视器可以感知漏洞利用,然后嵌入式分析可以报告并决定适当的安全响应。嵌入式分析和安全 IP 的组合如图所示:嵌入式分析和安全 IP总结SoC 设计的强大功能和优势正受到黑客的攻击,因此设计社区有责任采取主动措施来加强其新产品的安全级别。西门子 EDA 和 Agile Analog 创建了一个嵌入式数字和模拟硬件框架,用于检测网络威胁,并实时采取适当行动。来自微信
-
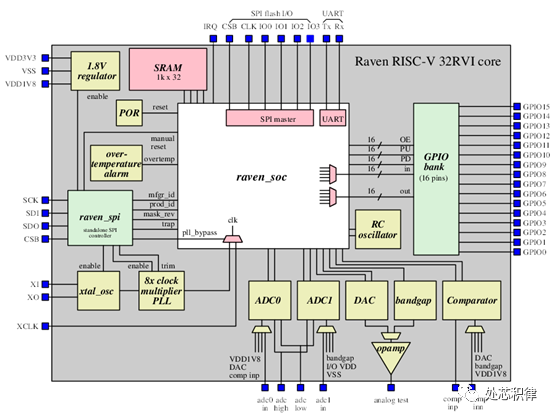
如何用云服务器搭建一个芯片SOC环境 ICbug猎人处芯积律2021年08月01日07:52今天这篇文章将介绍如何在云端服务器安装EDA软件并且搭建SOC环境。EDA是一个很大的概念,我们这里讲的是芯片设计中的EDA软件。芯片设计的EDA软件包括设计输入工具如composer,设计仿真工具如VCS/Verdi,综合工具如Design Compile,布局布线工具如Design Planner,物理验证工具Dracula,模拟电路仿真器SPICE等。举例的这些EDA工都是收费软件。目前也有一些开源的EDA工具可以用,如仿真用的Iverilog/ Verilator,看波形用的gtkwave,综合用的YoSys等。Efabless曾经用这些纯开源的EDA软件开发并流片过一款芯片。这款芯片结构如下该芯片的资料在这里:https://github.com/efabless/raven-picorv32。这个链接里面包含了该芯片的开源软件,代码,测试等资料,作为一款SOC开源项目大家有兴趣可以去看看。刚才提到的开源EDA Iverilog和Gtkwave的安装方法比较简单,直接敲下面的命令即可:sudo apt-get install iverilog sudo apt-get install gtkwave对于Verilator的安装我们等会在搭建SOC环境的时候介绍,其他开源EDA的安装方法这里不再介绍,有兴趣的可以在网上搜索。Verdi/VCS/simvision/irun等需要授权的EDA软件也可以在云服务器上安装,但是需要license支持才能用。虽然网上也有破解版本,但是个人不推荐使用。如果是企业用户且员工比较少的情况下可以向各个地方的集成电路设计服务机构(如苏州ICC)申请各家EDA的license,能够得到比较大的支持。下面我们介绍搭建一个SOC项目并用相关EDA工具进行仿真。Opentitan是一个开源项目,他是由RISCV搭建的一款简单芯片,其系统架构如下这颗芯片主要构成有1个riscv核,512kB的eflash,64kB的SRAM,16kB的ROM,安全加密模块,32个IO端口,一个UART,一个GPIO,一个SPI。目前I2C还没加进去,据说后面会加进去。从opentitan提供的资料来看,该项目包括了开源的软件,硬件代码,还提供了三套仿真测试环境,分别是verilator仿真环境,FPGA测试环境以及需要VCS的仿真环境。学习人员可以根据自己需要选择不同的运行环境。我们提供的SOC环境搭建步骤在opentitan 的开源网站都能找到,如果有不清楚的地方可以在下面这个链接处查找。https://docs.opentitan.org/doc/ug/getting_started/搭建环境的第一步是创建工具的路径。 sudo mkdir/tools sudo chown $(id -un) /tools第二步是克隆opentitan的库,这样就将SOC的源代码和相关资料拷贝到你的云服务器上。working-area 是你创建的工作路径。cd git clone https://github.com/lowRISC/opentitan.git代码资料会被存在 /opentitan 下面,我们后面介绍的$REPO_TOP 指的就是 /opentitan 这个路径。第三步安装相关软件sudo apt install autoconf bison build-essentialclang-format cmake curl \doxygenflex g++ git golang libelf1 libelf-dev libftdi1-2 libftdi1-dev \ibncurses5 libssl-dev libusb-1.0-0 lsb-release make ninja-build perl \pkgconfpython3 python3-pip python3-setuptools python3-wheel python3-yaml \srecordtree xsltproc zlib1g-dev xz-utils第四步 芯片环境中有用到python3相关的脚本,而云服务器没有安装python3的相关组件,因此需要我们自己安装。apt install python-pippip install --upgrade setuptoolspython -m pip install --upgrade pipsudo apt install djangopip3 install --upgrade pippip3 install django-haystackpip3 install setuptools-scmpip3 install django-haystack装完这些软件后再按照下面步骤安装python3相关的脚本软件。cd $REPO_TOPpip3 install --user -r python-requirements.txt第五步是安装riscv的编译工具链,官网提供了两种方法,一个直接下载,另外一个需要自己编译工具链,对于初学者来讲,建议选择第一种。cd $REPO_TOP./util/get-toolchain.py通过上面五步,我们已经将芯片的源代码和工具链软件都准备好了。在上述文中也讲到,opentatian可以用开源的EDA工具进行仿真,也可以用VCS等需要授权的软件进行仿真。在这里我们选择开源的verilator仿真工具进行仿真。为此需要按照以下步骤安装verilator仿真工具。export VERILATOR_VERSION=4.104git clonehttps://github.com/verilator/verilator.gitcd verilatorgit checkout v$VERILATOR_VERSIONautoconf./configure--prefix=/tools/verilator/$VERILATOR_VERSIONmakemake install做完这些我们就可以去跑仿真了。第六步build环境cd $REPO_TOPfusesoc --cores-root . run --flag=fileset_top--target=sim --setup --build lowrisc:systems:chip_earlgrey_verilator./meson_init.shninja -C build-out all第七步输入以下指令进行跑仿真。cd $REPO_TOPbuild/lowrisc_systems_chip_earlgrey_verilator_0.1/sim-verilator/Vchip_earlgrey_verilator\ --meminit=rom,build-bin/sw/device/boot_rom/boot_rom_sim_verilator.scr.39.vmem--meminit=flash,build-bin/sw/device/examples/hello_world/hello_world_sim_verilator.elf\--meminit=otp,build-bin/sw/device/otp_img/otp_img_sim_verilator.vmem 这个时候我们可以在工作界面上看到类似以下log 为了看运行的结果用screen /dev/pts/4进行查看。由于开源软件运行的效率会比较低,跑仿真的时间会比较久,所以需要耐心等待一下。 如果想看信号波形,在上面跑仿真的命令里面加—trace,即可生成波形。然后用gtkwave sim.fst 查看波形,其效果如下。写在最后,opentitan这个项目的开发流程还是比较全的,对于芯片从业者是一个很好的学习资源,特别是里面验证的介绍很多公司都可以借鉴。经常看到很多芯片初从业人员没有什么项目经验,如果能够吃透这个项目那你在找工作的时候是非常有竞争力的。通过这篇文章我希望能够将做芯片这件看起来门槛很高的事情简单化,让更多的大学生甚至中学生都能参与其中,让更多的人更早的去了解知道计算机的工作原理。来自微信
-